| 10.Pandas优化 | 您所在的位置:网站首页 › dn1500法兰 › 10.Pandas优化 |
10.Pandas优化
|
1.如何优化Pandas
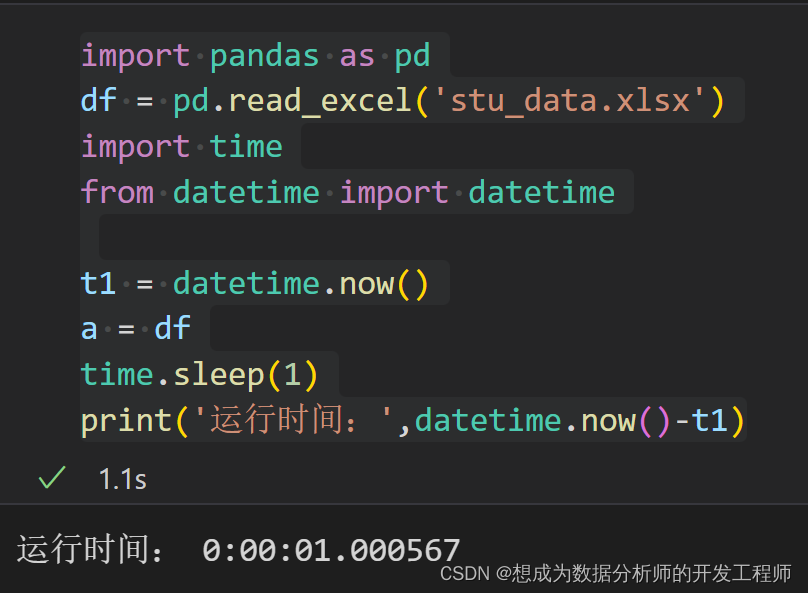
除非对相应的优化手段已经非常熟悉,否则代码的可读性应当被放在首位。过早优化是万 恶之源! pandas 为了易用性,确实牺牲了一些效率,但同时也预留了相应的优化路径。因此如果要进行优化,熟悉并优先使用 pandas 自身提供的优化套路至关重要。 尽量使用 pandas(或者 numpy)内置的函数进行运算,一般效率都会更高。 在可以用几种内部函数实现相同需求时,最好进行计算效率的比较,差距可能很大。 pandas 官方提供的讨论如何进行优化的文档: 优化文档 2.Pandas时间记录工具如何使用time和timeit去计算每行、每段代码的运行时间可以查看以下文章 time和timeit使用方法 使用python原生的方式计算时间 import pandas as pd df = pd.read_excel('stu_data.xlsx') import time from datetime import datetime t1 = datetime.now() a = df time.sleep(1) print('运行时间:',datetime.now()-t1)
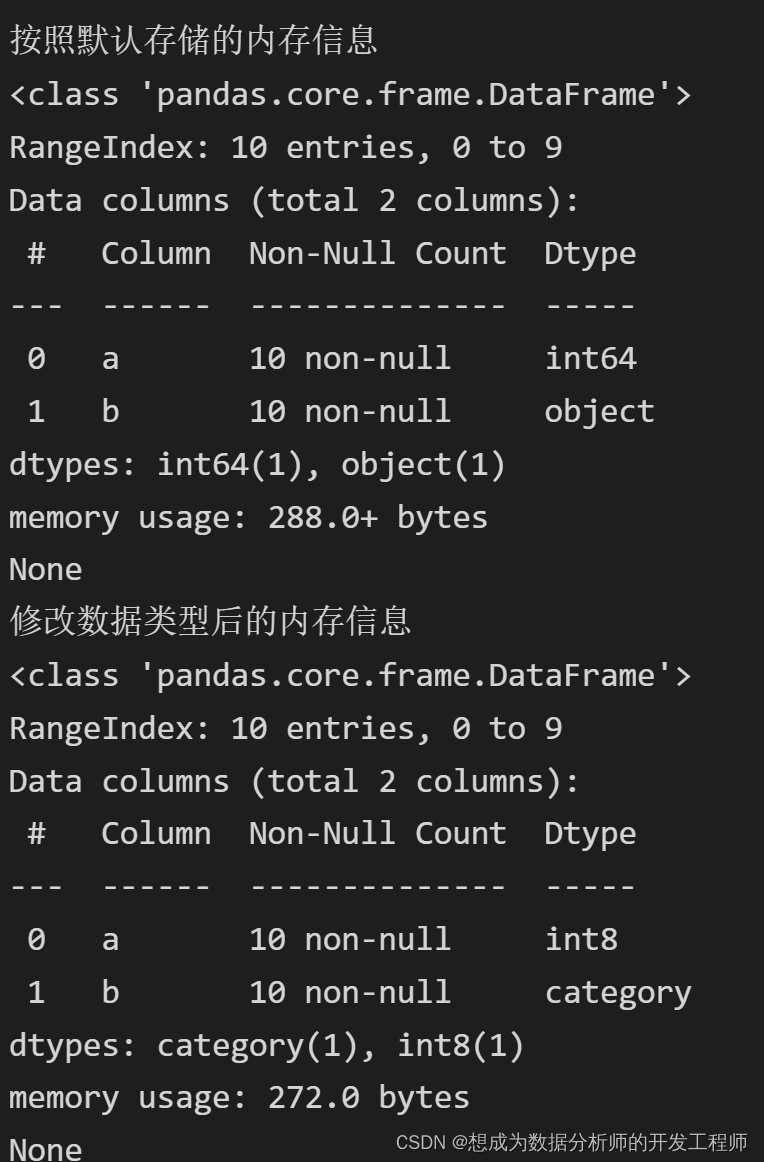
超大数据文件在使用 pandas 进行处理时可能需要考虑两个问题: 读取速度,内存用量。 一般情况会考虑读入部分数据进行代码编写和调试,然后再对完整数据进行处理。在数据读入和处理时需要加快处理速度,减少资源占用。 一些基本原则 当明确知道数据列的取值范围时,读取数据时可以使用 dtype 参数来手动指定类型,如 np.uint8 或者 np.int16,否则默认的 np.int64 类型等内存开销明显非常大。 尽量少用类型模糊的 object,改用更明确的 category 等(用astype()转换)。 对类别取值较少,但案例数极多的变量,读入后尽量转换为数值代码进行处理。 方式1:导入后进行类型转换 import pandas as pd # 方式1:导入后进行类型转换 df = pd.DataFrame({"a" : [0,1, 2, 3, 4, 5,6, 7, 8, 9], "b" : ["祖安狂人","祖安狂人","冰晶凤凰","冰晶凤凰","祖安狂人","祖安狂人","祖安狂人","冰晶凤凰", "冰晶凤凰","祖安狂人"]}) print('按照默认存储的内存信息') print(df.info()) # 类型转换 df['a'] = pd.to_numeric(df['a'], downcast='integer') df['b'] = df['b'].astype('category') # 必要时修改成str占用更小内存 # df['b'] = df['b'].astype('str') print('修改数据类型后的内存信息') print(df.info())
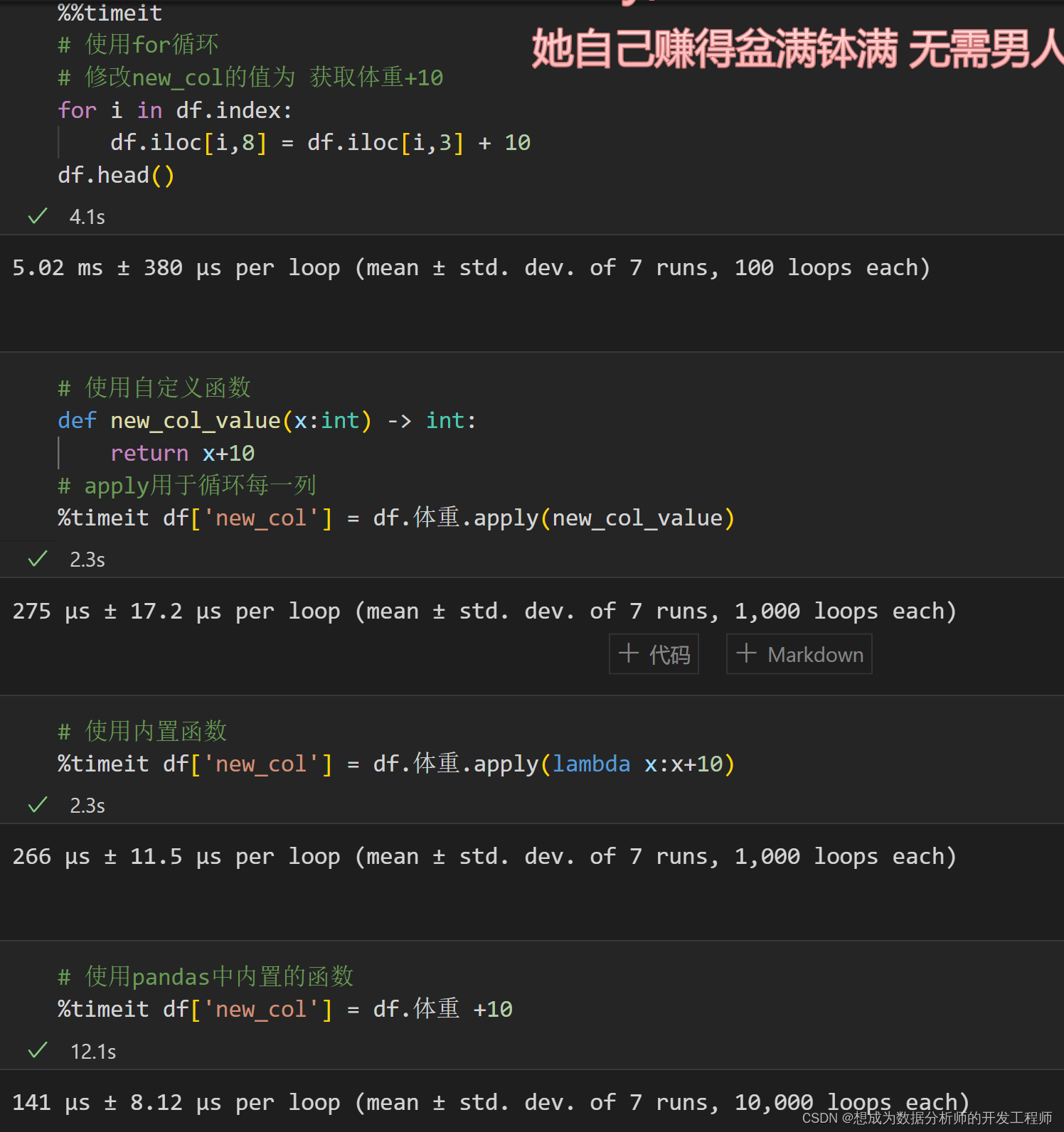
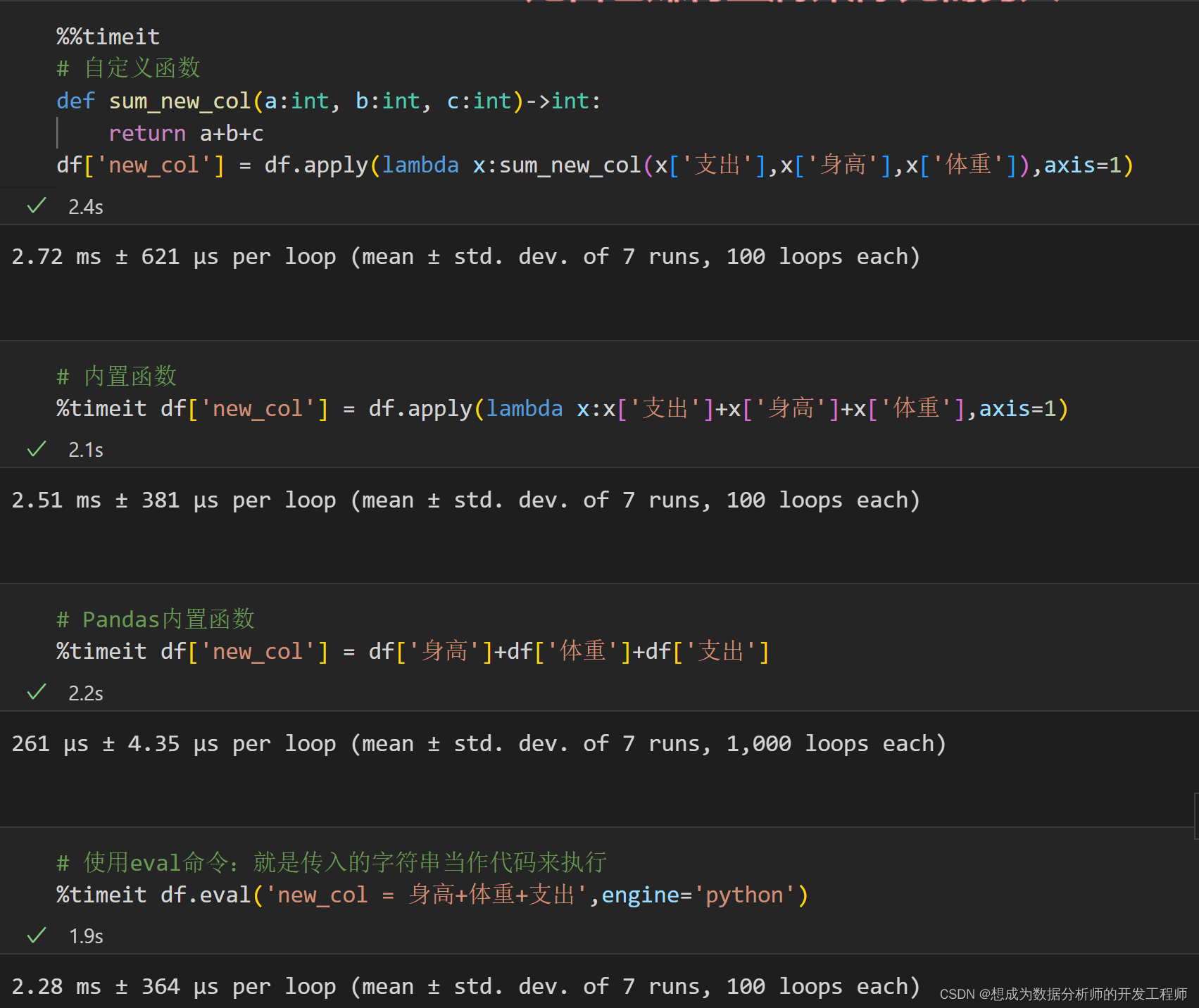
代码基本优化 尽量不要在 pandas 中使用循环 如果循环很难避免,尽量在循环体中使用 numpy 做计算。 使用for循环、内置函数、自定义函数的耗费时间对比
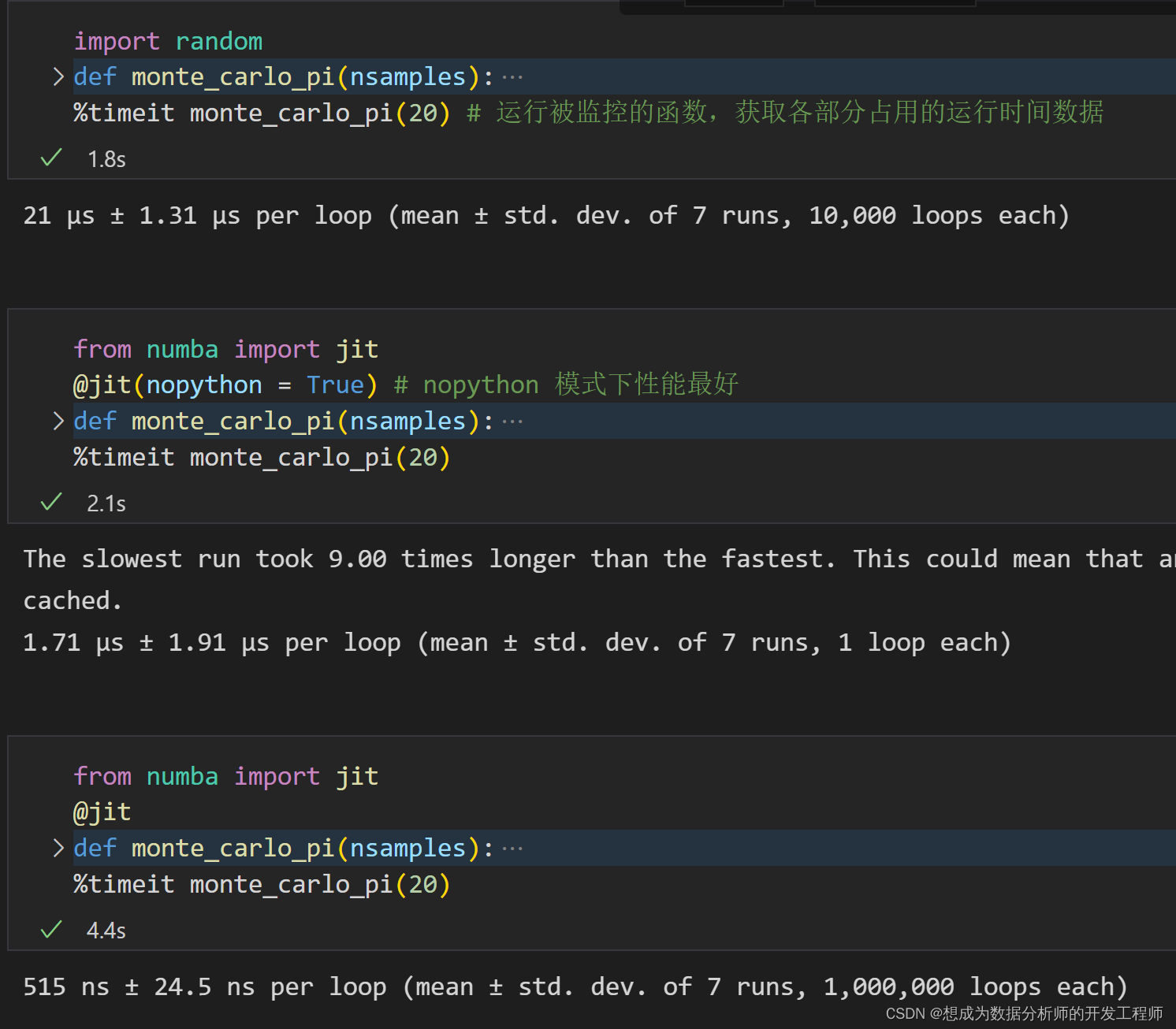
大部分外挂包都是基于 linux 环境,windows 下能用的不多。大部分外挂包还处于测试阶段,功能上并未完善。 numba 对编写的自定义函数进行编译,以提高运行效率。 A Just-In-Time Compiler for Numerical Functions in Python 具体使用的是 C++编写的 LLVM(Low Level Virtual Machine) compiler 实际上主要是针对numpy 库进行优化编译,并不仅限于 pandas |
 用 line_profiler做深入分析
用 line_profiler做深入分析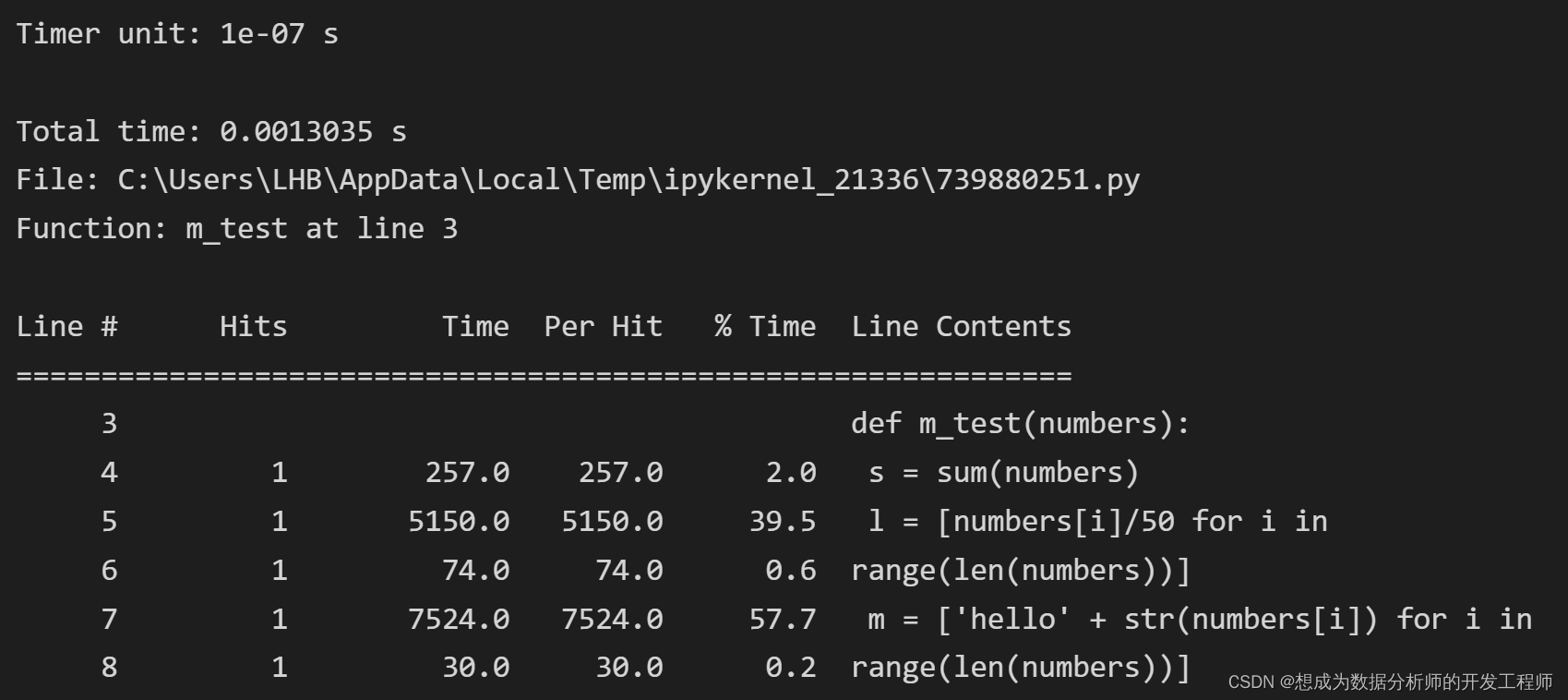
 方式2:对文件进行分段读取
方式2:对文件进行分段读取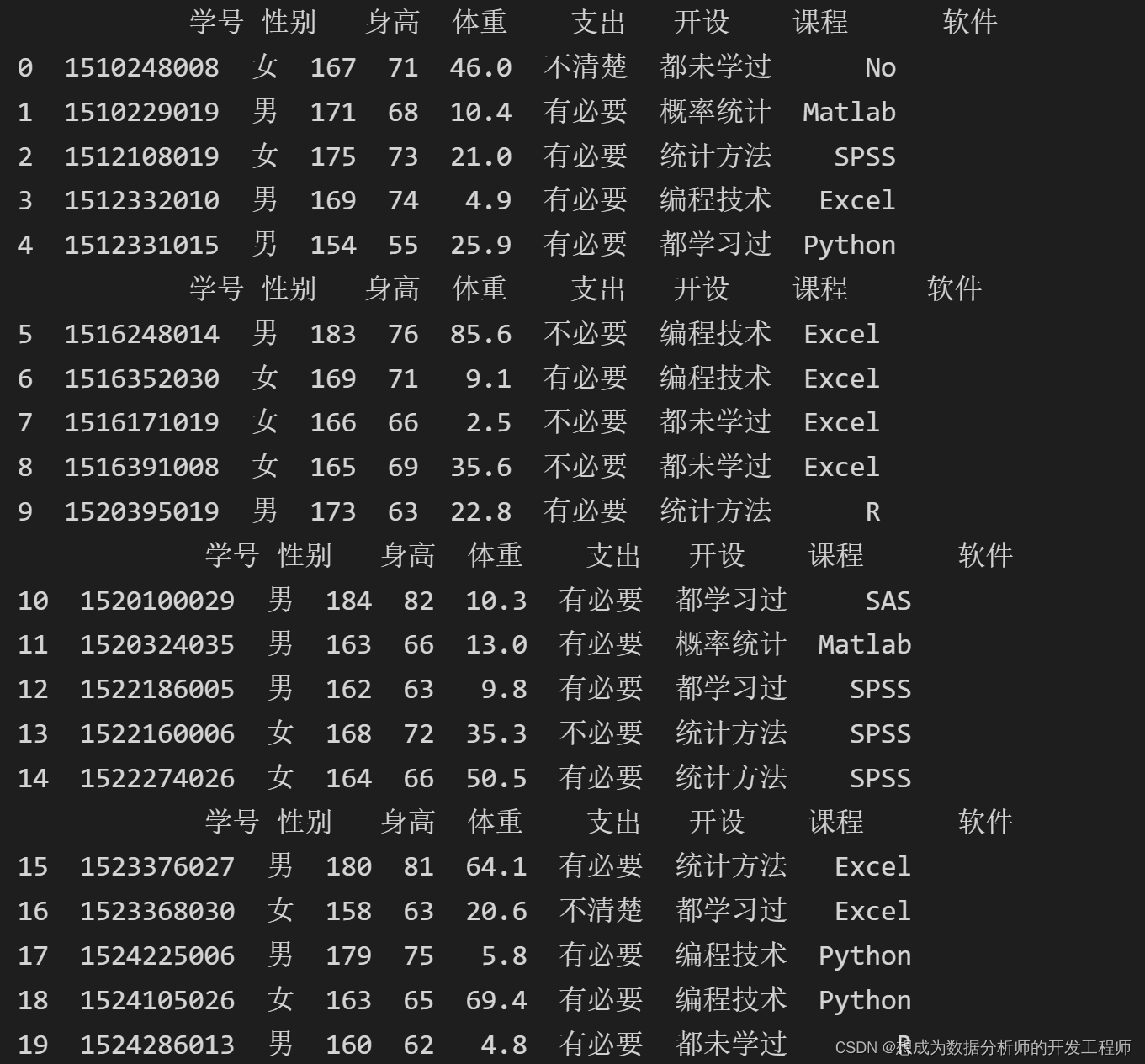 方式3:使用 iterator 参数和 get_chunk()组合
方式3:使用 iterator 参数和 get_chunk()组合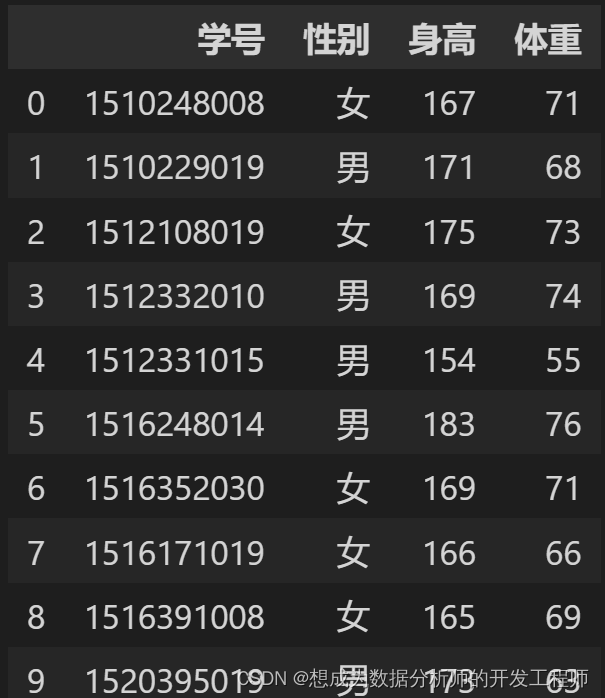
 swifter 对 apply 函数进行并行操作是专门针对 pandas 进行优化的工具包
swifter 对 apply 函数进行并行操作是专门针对 pandas 进行优化的工具包 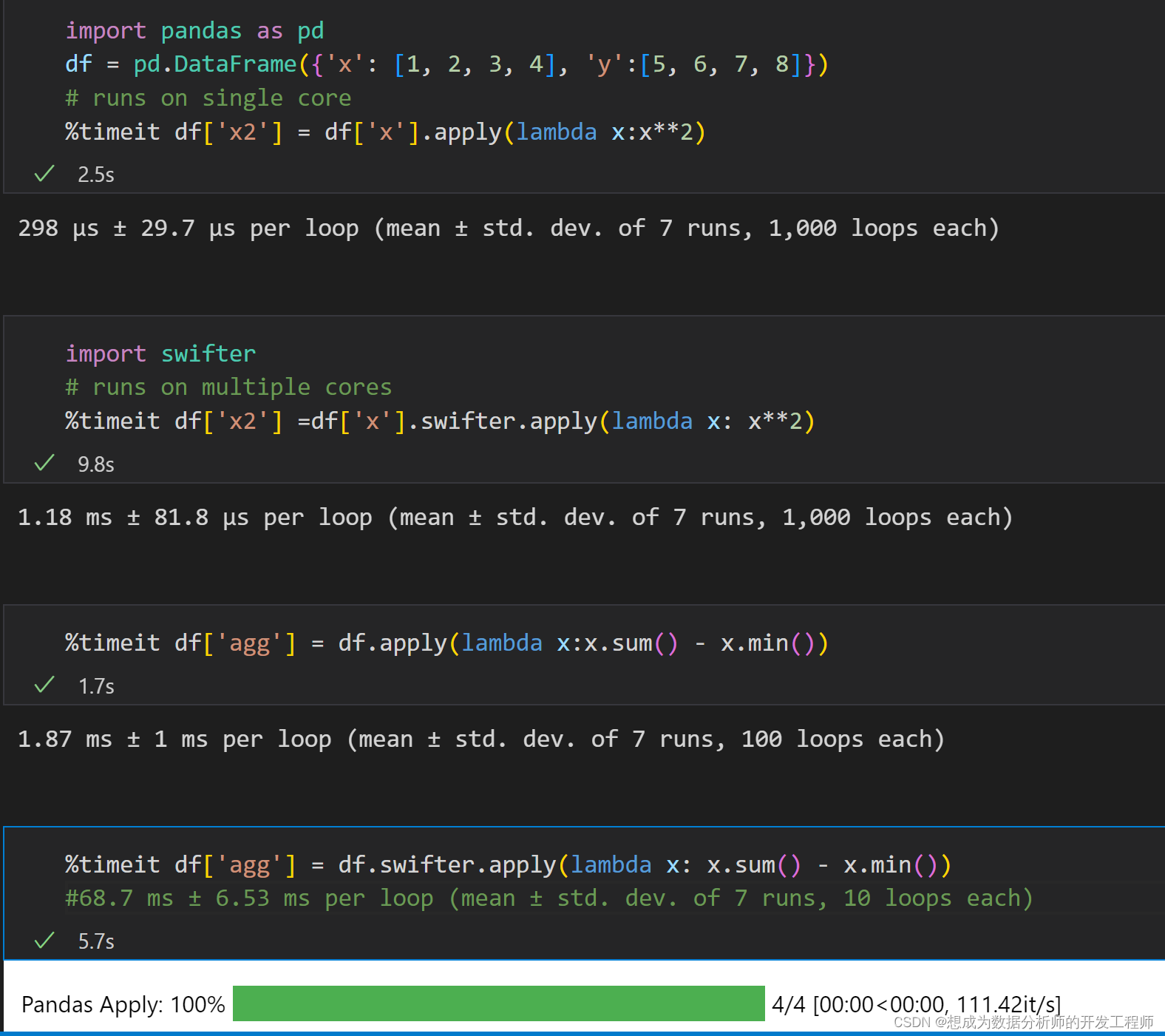
【本文地址】