| C语言基础数据类型的隐式转换、截断和解析问题 | 您所在的位置:网站首页 › c语言赋值规则是什么 › C语言基础数据类型的隐式转换、截断和解析问题 |
C语言基础数据类型的隐式转换、截断和解析问题
|
基础数据类型的隐式转换
隐式转换发生在不同的数据类型之间的运算。之所以有隐式转换,是为了确保数据的准确性。为什么不往最高级的数据类型上转呢?是为了节省资源和时间。 如下规则: 1、少字节往多字节转换。
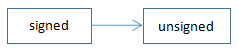 signed默认不用写,也就是平时写的char、int实质上就是signed char、signed int。为什么signed会转成unsigned呢?大概是因为unsigned能表示更大的数值,比如unsigned char的最大值是255,而char才127。3、整型往浮点型转换。 signed默认不用写,也就是平时写的char、int实质上就是signed char、signed int。为什么signed会转成unsigned呢?大概是因为unsigned能表示更大的数值,比如unsigned char的最大值是255,而char才127。3、整型往浮点型转换。 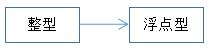 char、short、int、long、long long——>float、double。这种转换主要看的是最大字节的浮点类型是哪个就转哪个,常量小数是按double来算的。比如int类型+float类型,那么就会当float来计算,而不是double,即使后面要赋值到double类型。 从下面的例子可以看出,double = float+int的表达式,float+int计算完的结果也是float;double = double+int的结果是double的。所以并不是所以有关浮点型的计算都是以double去计算的,而是根据实际最大字节的浮点类型。
float f = 1234567890;
float f2 = 1234567936;//为了和f做个数值比较,也就是1234567890转成float的时候的实际值。
float f3 = 1234568036;//1234567936+100
float f4 = 1234568136;//1234567936+200
double d = 200.1;
int i = 100;
double result = f + i;
double result2 = d + f;
printf("i = %d\nf = %f\nf2 = %f\nf3 = %f\nf4 = %f\nf + i = %f\nd + f = %f", i, f, f2, f3, f4, result, result2);
system("pause");
return 0; char、short、int、long、long long——>float、double。这种转换主要看的是最大字节的浮点类型是哪个就转哪个,常量小数是按double来算的。比如int类型+float类型,那么就会当float来计算,而不是double,即使后面要赋值到double类型。 从下面的例子可以看出,double = float+int的表达式,float+int计算完的结果也是float;double = double+int的结果是double的。所以并不是所以有关浮点型的计算都是以double去计算的,而是根据实际最大字节的浮点类型。
float f = 1234567890;
float f2 = 1234567936;//为了和f做个数值比较,也就是1234567890转成float的时候的实际值。
float f3 = 1234568036;//1234567936+100
float f4 = 1234568136;//1234567936+200
double d = 200.1;
int i = 100;
double result = f + i;
double result2 = d + f;
printf("i = %d\nf = %f\nf2 = %f\nf3 = %f\nf4 = %f\nf + i = %f\nd + f = %f", i, f, f2, f3, f4, result, result2);
system("pause");
return 0;
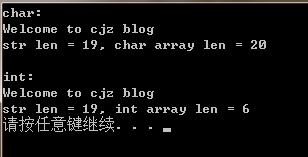
数据截断是发生在多字节的数据类型赋值给少字节的,如int赋值给char,double赋值给float,浮点的赋值给整型的。数据截断会导致二进制数据丢失,可能造成数据精度丢失,甚至数据错乱。 整型的截断很简单,就是把多余的高位去掉。 int i = -1111;//十六进制为0xfffffBA9 char c = i;//赋值后c的十六进制就是0xA9 unsigned char uc = i;//uc也是0xA9 printf("%d, %d", c, uc);//由于c和uc是signed和unsigned类型,所以%d输出的时候分别是-87和169。这样明显的数据错乱了 system("pause"); return 0;浮点型的就要考虑被赋值的类型的最大值的范围了,double到float,如果double的十进制数的位数超出了float的范围,那就造成了数据精度的丢失。浮点型到整型就可以理解成,丢掉浮点型的小数点后面的数据得到一个整数,然后这整数再复制到整型里面,浮点型到整型肯定会造成数据精度的丢失的,因为小数已经没了,而且如果整数部分超出整型的最大范围,那就数据错乱了。 解析下面主要讲整型和字符串(%s)的解析方式。至于浮点型的可以自行查阅相关浮点数的存储方式,CSDN播客上也有很多这种的,然后按照整型的方式去做。 整型 应该大部分的人都知道signed类型的最高位是符号位,而unsigned没有符号位,但很多人都只记住了最高位是符号位,却忘了后面,所以很容易让人把(char)-1的二进制误解0x81。而实际上是当符号位是1时,计算方式为-1 * (反码+1);符号位是0时,原码就是真实数值,所以-1的二进制表示方式应该是0x81的反码是0x7e,+1就是0x7f,再加上符号位就是0xff。 而我换了种方式去理解signed,就是signed类型的最高位代表的数值 * 负的该位的二进制数值(-0或-1)+除去最高位的二进制数值。例如二进制都是0xff的char和unsigned char类型,char就可以把0xff看成 -110x80 + 0x7f= -1,unsigned char就是0xff=255。但char赋值到short、int等二进制的表示就不一样了,会变成0xffff、0xffffffff,因为int表示-1的二进制就是0xffffffff,其它也是同样的原理。字符串(%s) 在C语音里是没有字符串的数据类型的,都只是用char数组当做字符串,你用short、int做当字符串也行,只是char做字符串方便访问每个字节,方便处理,不像其它语言的有封装好的string类。C语音的字符串必须要知道的一个知识点,那就是C语音的字符串必须以’\0’或者数值0结束,常量字符串会自带’\0’,并且’\0’和数值0并不计算到字符串长度里,但数组长度必须要大于字符串长,否则有可能会出现操作非法内存的错误提示。如果在已有数组范围内提前遇到’\0’或数值0就会提前接受,所以不要在不必要的位置加’\0’或数值0。如果在已有的数值范围内不以’\0’或数值0结束,那就有可能会出现操作非法内存的错误提示,因为一直判断都没遇到结束符,所以就继续往后找,运气好的,在数组范围外的地址上遇到数值0,而且不是非法地址,就不会出错。下面用代码模拟strlen函数和printf("%s")的功能: size_t myStrlen(const char *str) { const char *originalP = str; while (*str++) ; return str - originalP - 1; } void myPrintStr(const char *str) { while (*str) putchar(*str++); } int main(void) { char str[] = "Welcome to cjz blog";//实际大小是字符串长度+1('\0') int *istr = (int *)malloc((sizeof(str) / sizeof(int) + 1) * sizeof(int)); memcpy(istr, str, sizeof(str)); printf("char:\n"); myPrintStr(str); printf("\nstr len = %d, char array len = %d\n\n", myStrlen(str), sizeof(str)); printf("int:\n"); myPrintStr(istr); printf("\nstr len = %d, int array len = %d\n", myStrlen(istr), (sizeof(str) / sizeof(int) + 1)); free(istr); system("pause"); return 0; }
|
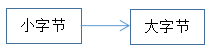 char ——> short——>int——>long——>long long,float——>double。这样的排序应该是为了兼容性排出来的。因为在8位、16位芯片里,int和short都是2个字节,long是4个字节。但在32位、64位里,short是2个字节,int是4个字节,long是4个字节。
char ——> short——>int——>long——>long long,float——>double。这样的排序应该是为了兼容性排出来的。因为在8位、16位芯片里,int和short都是2个字节,long是4个字节。但在32位、64位里,short是2个字节,int是4个字节,long是4个字节。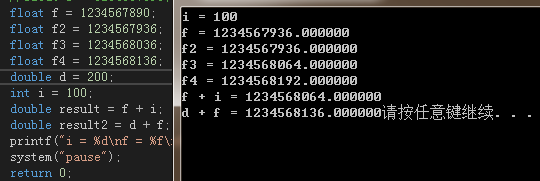
【本文地址】
公司简介
联系我们