| NVIDIA CUDA引领GPU并行计算新时代 | 您所在的位置:网站首页 › cuda版本与显卡型号 › NVIDIA CUDA引领GPU并行计算新时代 |
NVIDIA CUDA引领GPU并行计算新时代
|
1前言回顶部
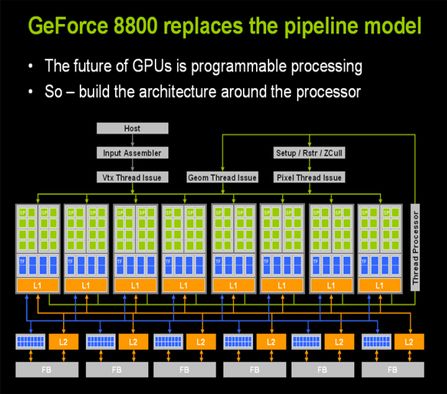
显卡的发展可以说是非常的快,人们对于视觉化上的要求也越来越高,随着用户对于图像处理上面的要求不断超出处理器的计算能力。另一方面CPU处理能力也不断强大,但在进入3D时代后,人们发现庞大的3D图像处理数据计算使得CPU越来越不堪重荷,并且远远超出其计算能力。图形计算需求日益增多,作为计算机的显示芯片也飞速发展。随后人们发现显示芯片的计算能力也无法满足快速增长的图形计算需求时,图形,图像计算等计算的功能被脱离出来单独成为一块芯片设计,这就是现在的图形计算处理器——GPU(Graphics Processing Unit),也就是显卡。 1999年8月,NVIDIA终于正式发表了具有跨世纪意义的产品NV10——GeForce 256。GeForce256是业界第一款256bit的GPU,也是全球第一个集成T&L(几何加速/转换)、动态光影、三角形设置/剪辑和四像素渲染等3D加速功能的图形引擎。通过T&L技术,显卡不再是简单像素填充机以及多边形生成器,它还将参与图形的几何计算从而将CPU从繁重的3D管道几何运算中解放出来。在这代产品中,NVIDIA推出了两个全新的名词——GPU以GeForce。所以从某种意义上说,GeForce 256开创了一个全新的3D图形时代,NVIDIA终于从追随者走向了领导者。再到后来GeForce 3开始引出可编程特性,能将图形硬件的流水线作为流处理器来解释,基于GPU的通用计算也开始出现。 到了Nvidia GeForce6800这一代GPU,功能相对以前更加丰富、灵活。顶点程序可以直接访问纹理,支持动态分支;象素着色器开始支持分支操作,包括循环和子函数调用,TMU支持64位浮点纹理的过滤和混合,ROP(象素输出单元)支持MRT(多目标渲染)等。象素和顶点可编程性得到了大大的扩展,访问方式更为灵活,这些对于通用计算而言更是重要突破。 真正意义的变革,是G80的出现,真正的改变随着DX10到来发生质的改变,基于DX10统一渲染架构下,显卡已经抛弃了以前传统的渲染管线,取而代之的是统一流处理器,除了用作图像渲染外,流处理器自身有着强大的运算能力。我们知道CPU主要采用串行的计算方式,由于串行运算的局限性,CPU也正在向并行计算发展,比如目前主流的双核、四核CPU,如果我们把这个概念放到现在的GPU身上,核心的一个流处理相当于一个“核”,GPU的“核”数量已经不再停留在单位数,而是几十甚至是上百个。下面看看G80的架构图:
G80中拥有128个单独的ALU,因此非常适合并行计算,而且数值计算的速度远远优于CPU。 2GPU与CPU的区别回顶部
早期的3D游戏,显卡只是为屏幕上显示像素提供一个缓存,所有的图形处理都是由CPU单独完成。图形渲染适合并行处理,擅长于执行串行工作的CPU实际上难以胜任这项任务。直到1995年,PC机领域第一款GPU 3dfx Voodoo出来以后,游戏的速度、画质才取得了一个飞跃。GPU的功能更新很迅速,平均每一年多便有新一代的GPU诞生,运算速度也越来越快。 综上所述,GPU并行处理的理论性能要远高于CPU。同时,我们也可以通过上面这组NVIDIA统计的近两年来GPU与CPU之间浮点运算能力提升对比表格来看一下。 Intel Core2Due G80 Chip运算能力比较 24 GFLOPS 520 GFLOPSGPU快21.6倍 虽然我们看到CPU和GPU在运算能力上面的巨大差距,但是我们要看看他们设计之初所负责的工作。CPU设计之初所负责的是如何把一条一条的数据处理玩,CPU的内部结构可以分为控制单元、逻辑单元和存储单元三大部分,三个部分相互协调,便可以进行分析,判断、运算并控制计算机各部分协调工作。其中运算器主要完成各种算术运算(如加、减、乘、除)和逻辑运算( 如逻辑加、逻辑乘和非运算); 而控制器不具有运算功能,它只是读取各种指令,并对指令进行分析,作出相应的控制。通常,在CPU中还有若干个寄存器,它们可直接参与运算并存放运算的中间结果。CPU的工作原理就像一个工厂对产品的加工过程:进入工厂的原料(程序指令),经过物资分配部门(控制单元)的调度分配,被送往生产线(逻辑运算单元),生产出成品(处理后的数据)后,再存储在仓库(存储单元)中,最后等着拿到市场上去卖(交由应用程序使用)。在这个过程中,从控制单元开始,CPU就开始了正式的工作,中间的过程是通过逻辑运算单元来进行运算处理,交到存储单元代表工作的结束。数据从输入设备流经内存,等待CPU的处理。 而GPU却从最初的设计就能够执行并行指令,从一个GPU核心收到一组多边形数据,到完成所有处理并输出图像可以做到完全独立。由于最初GPU就采用了大量的执行单元,这些执行单元可以轻松的加载并行处理,而不像CPU那样的单线程处理。另外,现代的GPU也可以在每个指令周期执行更多的单一指令。例如,在某些特定环境下,Tesla架构可以同时执行MAD+MUL or MAD+SFU。
可以看到GPU越来越强大,GPU为显示图像做了优化之外,在计算上已经超越了通用的CPU。如此强大的芯片如果只是作为显卡就太浪费了,因此NVidia推出CUDA,让显卡可以用于图像计算以外的目的,也就是超于游戏,使得GPU能够发挥其强大的运算能力。 一年前NVIDIA发布CUDA,这是一种专门针对GPU的C语言开发工具。与以往采用图形API接口指挥GPU完成各种运算处理功能不同,CUDA的出现使研究人员和工程师可以在熟悉的C语言环境下,自由地输入代码调用GPU的并行处理架构。这使得原先需要花费数天数周才能出结果的运算大大缩短到数几小时,甚至几分钟之内。 CUDA是用于GPU计算的开发环境,它是一个全新的软硬件架构,可以将GPU视为一个并行数据计算的设备,对所进行的计算进行分配和管理。在CUDA的架构中,这些计算不再像过去所谓的GPGPU架构那样必须将计算映射到图形API(OpenGL和Direct 3D)中,因此对于开发者来说,CUDA的开发门槛大大降低了。CUDA的GPU编程语言基于标准的C语言,因此任何有C语言基础的用户都很容易地开发CUDA的应用程序。 那么,如何使得CPU与GPU之间很好的进行程序之间的衔接呢?以GPGPU的概念来看,显卡仍然需要以传统的DirectX和OpenGL这样的API来实现,对于编程人员来说,这样的方法非常繁琐,而CUDA正是以GPGPU这个概念衍生而来的新的应用程序接口,不过CUDA则提供了一个更加简便的方案——C语言。我们回顾一下CUDA的发展历史。 3CUDA技术的发展历史回顶部CUDA技术的发展历史实际上,CUDA是在2006年的11月与G80这款产品一同诞生的,在2007年2月NVIDIA首次发布了CUDA的公测版,而在2007年6月,CUDA 1.0版与Tesla系列正式登场,到了07年底,CUDA 1.1测试版放出。在CUDA 1.1测试版当中,NVIDIA为其增加了一些新的功能。
在CUDA 1.1版本发布后,NVIDIA也适时的推出了适合CUDA的驱动程序。当时NVIDIA就已经表示,只要GeForce 8系列或更高版本的显卡产品搭载169.XX版本以上的驱动就可以支持CUDA功能了。这是一个非常重要的举措,因为这就意味着,在今后任意一台拥有GeForce 8以上的显卡都能够支持CUDA了,而无需必须用有一台专业的Tesla产品才能够实现CUDA加速。此外,CUDA 1.1版本还增加了异步执行与数据复制(仅限于G84、G86、G92或更新的产品)、异步数据传输、显存、支持64bit Windows操作系统以及多GPU SLI对CUDA的支持等等功能。 而最新的版本则是在GeForce GTX 200系列产品发布时同步推出的CUDA 2.0版本,而CUDA 2.0测试版则是在今年春天的早些时间推出的。在CUDA 2.0版本当中,增加了如下内容:支持双精度运算(仅支持GT200系列产品)、支持Windows VISTA操作系统(包括32bit和64bit)、支持MacOS X操作系统、分析调试器、3D纹理支持以及优化数据传输等。
让我们来关注一下双精度的问题吧,它的执行效率在新一代的硬件中要比单精度执行效率要慢上数倍,以GTX280为例,不使用FP32格式下它的最终效率要慢4倍左右,NVIDIA决定通过定义来支持FP64的格式,这是更严酷的考验(一个双精度单元需要占用多核中的其中一核)。 真实的性能可能会更低,因为在内存与寄存器上都是针对于32bit进行优化的,不过话说回来,双精度的应用对于图形软件来说并不是特别的重要,GT200支持这一特性也可能只是为了在规格上看起来会更好看一些,而且现在流行的4核处理器执行起双精度来并不慢。但是大家不用太过于失望就算双精度的执行速度比单精度的要慢10倍甚至更多,支持双精度依然对于混合型的精度处理是很有用的。任何一种对于精度操作的技术无不是先做好单精度再转攻双精度的,至少现在碰到双精度的时候显卡不需要再把数据传给CPU等待它的处理之后再传递回来,从这一层面来说支持双精度还是有它的好处的。 还有一点不得不提的是,CUDA 2.0并不是只支持GPU的,它的编译器可以选择它CUDA的代码转成多线程的SSE代码让CPU来执行,这种作法并不只是为了在DEBUG的时候方便,在实际中也是有用途的,CUDA是NVIDIA公司的产品,但是并不是所有的电脑上装的都是NVIDIA的显卡,编程人员可能有时会为了商业需求需要写两种不同的代码,但是现在的话CUDA 2.0就可以支持进行转换,虽然在CPU上有些代码会比GPU执行起来慢得多。 CUDA的发布影响颇为深远,这是一种专门针对GPU的C语言开发工具。与以往采用图形API接口指挥GPU完成各种运算处理功能不同,CUDA的出现使研究人员和工程师可以在熟悉的C语言环境下,自由地输入代码调用GPU的并行处理架构。这使得原先需要花费数天数周才能出结果的运算大大缩短到数几小时,甚至几分钟之内。
CUDA发布2.0后目前支持的硬件方面分为3个级别,面向娱乐消费方面的GeForce,面向专业图形设计市场的Quadro,还有面向GPU计算的产品,它不具备图形输出的功能,面向不同的应用领域,NVIDIA方面推出不同的产品。这方面也可以看出CUDA的应用方面之广。未来NVIDIA方面还会完善CUDA,现在就NVIDIA的数据已经有8000万的支持CUDA的GPU已经销售出去了,这样看来CUDA的应用就有了其存在的支持,你的GPU不单单只是作为一个图形处理芯片,只要有支持CUDA的软件开发,那么对于一般的消费者来说,就是等着享受就是了。下面我们介绍一下CUDA的功能。 CUDA(Compute Unified Device Architecture)是一个新的基础架构,这个架构可以使用GPU来解决商业、工业以及科学方面的复杂计算问题。它是一个完整的GPGPU解决方案,提供了硬件的直接访问接口,而不必像传统方式一样必须依赖图形API接口来实现GPU的访问。在架构上采用了一种全新的计算体系结构来使用GPU提供的硬件资源,从而给大规模的数据计算应用提供了一种比CPU更加强大的计算能力。CUDA采用C语言作为编程语言提供大量的高性能计算指令开发能力,使开发者能够在GPU的强大计算能力的基础上建立起一种效率更高的密集数据计算解决方案。 从CUDA体系结构的组成来说,包含了三个部分:开发库、运行期环境和驱动。开发库是基于CUDA技术所提供的应用开发库。目前CUDA的1.1版提供了两个标准的数学运算库——CUFFT(离散快速傅立叶变换)和CUBLAS(离散基本线性计算)的实现。这两个数学运算库所解决的是典型的大规模的并行计算问题,也是在密集数据计算中非常常见的计算类型。开发人员在开发库的基础上可以快速、方便的建立起自己的计算应用。此外,开发人员也可以在CUDA的技术基础上实现出更多的开发库。 运行期环境提供了应用开发接口和运行期组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。基于CUDA开发的程序代码在实际执行中分为两种,一种是运行在CPU上的宿主代码(Host Code),一种是运行在GPU上的设备代码(Device Code)。不同类型的代码由于其运行的物理位置不同,能够访问到的资源不同,因此对应的运行期组件也分为公共组件、宿主组件和设备组件三个部分,基本上囊括了所有在GPGPU开发中所需要的功能和能够使用到的资源接口,开发人员可以通过运行期环境的编程接口实现各种类型的计算。 由于目前存在着多种GPU版本的NVIDIA显卡,不同版本的GPU之间都有不同的差异,因此驱动部分基本上可以理解为是CUDA-enable的GPU的设备抽象层,提供硬件设备的抽象访问接口。CUDA提供运行期环境也是通过这一层来实现各种功能的。目前基于CUDA开发的应用必须有NVIDIA CUDA-enable的硬件支持,NVIDIA公司GPU运算事业部总经理Andy Keane在一次活动中表示:一个充满生命力的技术平台应该是开放的,CUDA未来也会向这个方向发展。由于CUDA的体系结构中有硬件抽象层的存在,因此今后也有可能发展成为一个通用的GPGPU标准接口,兼容不同厂商的GPU产品。 目前普通消费者能在市面上看见支持CUDA的GPU产品从笔记本到高性能多GPU的系统中。也就是普通的用户,我们使用的普通笔记本到台式级电脑,只要拥有一块NVIDIA的GeForce 8以上级别的显卡都能够支持CUDA。 4CUDA是深入介绍回顶部 GPGPU与GPU计算 人们为了让GPU发挥其强大的计算能力,也就是不单单只是图形计算,人们在2002年就开始研究如何利用GPU完成我们通常意思上的数据运算,这就是成为GPGPU(General-Purpose computing on Graphics Processing Units,基于GPU的通用计算)。首先我来基本了解一下GPU的运算基础。
上面的是我们GPU的处理数据的流程图,图形数据从CPU传输过来,进入GPU后进行处理,上颜色处理花纹等等的运算,处理后输出,如果要利用GPU来做通用计算,这就必须要把经过处理,这其实是很困难的事情。如果程序员想要调用GPU硬件资源,只能通过OpenGL或者Direct3D两种API接口。OpenGL或Direct3D严重的限制了GPU性能在3D图形处理意外的应用领域。因为开发人员并不了解如何调用GPU的线程以及内核。 在2003年第一次出现了一个利用GPU进行并行运算。在起先的尝试当中使用的方法非常原始,并且不少GPU的硬件功能也被限制,例如rasterizing和Z -缓冲技术。但是出现“Shader”之后,大家开始尝试矩阵计算。早在2003年一个SIGGRAPH当中的部门开辟了GPU运算新篇章——GPGPU。 这段时间最受大家所知道的编辑其就是Brook,开创了GPU在非图形领域的先河。是Brook首次让C语言能够实现这一功能,让开发人员无需了解OpenGL或者Direct3D就能够对GPU资源进行调用。开发人员可以通过一个.br文件进行编码和扩展,产生的代码能够被DirectX、OpenGL、或x86系统的代码链接库支持。当然其也有其具有的弊端。但是这也使得NVIDIA和ATI把眼光吸引到如何利用GPU做通用计算这点上。 在2004年,NVIDIA就专门请了相关硬件方面的设计师以及软件方面的设计师对于GPU进行重新的完全不同的以前的设计,它既适用于图形,也是适用于计算的。 伴随着随着统一渲染架构的诞生,也就是进入G80开始,GPU本身的计算方式由基于矢量计算转为了基于标量的并行计算。当摆脱了架构和计算方式所带来的限制之后,GPU所能处理的问题由图形领域扩展到了通用计算领域。而在开发领域,需要有一种灵活的开发方式,能够让用户直接使用GPU的计算能力,而CUDA正是为此而诞生。 Nvidia CUDA技术是当今世界上唯一针对Nvidia GPU(图形处理器)的C语言环境,该技术充分挖掘出Nvidia GPU巨大的计算能力。凭借CUDA技术,开发人员能够利用Nvidia GPU攻克极其复杂的密集型计算难题。现在,世界各地已经部署了数以百万计的支持CUDA 的GPU,数以千计的软件开发人员正在使用免费的CUDA软件工具来加快视频、音频编码、石油天然气勘探、产品设计、医学成像和科学研究等应用。 说了CUDA这么多,我们深入一点探讨CUDA到底是什么。它是我们需要的新颖的硬件和编程模型,能够让GPU的强大计算能力发挥,并将GPU暴露为一种真正通用的数据并行计算设备。 CUDA(Compute Unified Device Architecture)用于GPU计算的开发环境,它是一个全新的软硬件架构,这个架构可以使用GPU来解决商业、工业以及科学方面的复杂计算问题。是NVIDIA为自家的GPU编写了一套编译器及相关的库文件。它是一个完整的GPGPU解决方案,提供了硬件的直接访问接口,而不必像传统方式一样必须依赖图形API(OpenGL和Direct 3D)接口来实现GPU的访问。因此对于开发者来说,CUDA的开发门槛大大降低了。CUDA的GPU编程语言基于标准的C语言,因此任何有C语言基础的用户都很容易的开发CUDA应用程序。
CUDA是业界的首款并行运算语言,而且其非常普及化,目前有高达8千万的PC用户可以支持该语言。
CUDA在执行的时候是让host里面的一个一个的kernel按照线程网格(Grid)的概念在显卡硬件(GPU)上执行。每一个线程网格又可以包含多个线程块(block),每一个线程块中又可以包含多个线程(thread)。 用马路上的汽车来比喻,马路上面有很多辆汽车,但是如果同时开的话,那么肯定会出现塞车现象的。CUDA就好比一个指挥马路的警察。每一个汽车分成不同的路线kernel_1,kernel_2……kernel_M),然后每个子任务的司机(Grid),就负责自己的路线(Block),最后才是汽车(Thread)去执行完成。 通过CUDA编程时,将GPU看作可以并行执行非常多个线程的计算设备(compute device)。它作为主CPU的协处理器或者主机(host)来运作:换句话说,在主机上运行的应用程序中数据并行的、计算密集的部分卸载到此设备上。 经过了CUDA对线程、线程块的定义和管理,在支持CUDA的GPU内部实际上已经成为了一个迷你网格计算系统。在内存访问方面,整个GPU可以支配的存储空间被分成了寄存器(Register)、全局内存(External DRAM)、共享内存(Parallel Data Cache)三大部分。其中寄存器和共享内存集成在GPU内部,拥有极高的速度,但容量很小。共享内存可以被同个线程块内的线程所共享,而全局内存则是我们熟知的显存,它在GPU外部,容量很大但速度较慢。经过多个级别的内存访问结构设计,CUDA已经可以提供让人满意的内存访问机制,而不是像传统GPGPU那样需要开发者自行定义。 在CUDA的帮助下普通程序员只要学习一点点额外的GPU架构知识,就能立刻用熟悉的C语言释放GPU恐怖的浮点运算能力,通过CUDA所能调度的运算力已经非常逼近万亿次浮点运算(GeForce 280GTX单卡浮点运算能力为933GF LOPS)。而在此之前要获得万亿次的计算能力至少需要购买价值几十万元的小型机。
基于CUDA开发的程序代码在实际执行中分为两种,一种是运行在CPU上的宿主代码(Host Code),一种是运行在GPU上的设备代码(Device Code)。 CUDA其实是CPU和GPU协作运算数据,所有CUDA也会看到CPU和GPU的部分,比较串行的部分放到CPU上面,比较并行的部分放到GPU上面运算。 ◆采用CUDA技术相比传统的GPGPU计算的优势: CUDA的编程接口采用了标准的C语言程序进行扩展,有利于CUDA的学习每个线程之间CUDA为他们提供了16kb的共享内存,可用于设置缓存,同时还拥有更高的带宽纹理系统内存和显存之间更有效地进行数据传输无需图形API接口进行连接现行内存寻址、聚集和驱散,写入任意地址硬件支持整数和bit操作◆CUDA技术目前的一些限制: 无法循环函数最小Block为32个线程CUDA架构仅限于NVIDIA产品5面向未来:CUDA应用方向回顶部面向未来:CUDA应用方向 由于GPU的特点是处理密集型数据和并行数据计算,因此CUDA非常适合需要大规模并行计算的领域。目前CUDA除了可以用C语言开发,也已经提供FORTRAN的应用接口,未来可以预计CUDA会支持C++、Java、Python等各类语言。虽然现在更多的应用在游戏、图形动画、科学计算、地质、生物、物理模拟等领域,但是由于GPU本身的通用特性和CUDA提供的方便的开发环境,我们可以放开思维的束缚,想象几种可能的应用场景:
搜索引擎中的排序、文本分类等相关算法的应用 ●数据库、数据挖掘 ● 电信、金融、证券数据分析 ●数理统计分析 ● 生物医药工程 ● 导航识别 ● 军事模拟 ● 无线射频模拟 ● 图像语音识别 这些领域内的计算都是属于大规模的数据密集型计算,未来我们可以预测,在CUDA的驱动下,GPU能够在这些领域建立一个属于自己的新时代。 而对于CUDA的开发者来说,开发CUDA的软件也非常简单。开发者只要会运用C语言编程,就能够顺利的学会CUDA。因为CUDA就是基于C语言为基础的,CUDA可以支持多种运行在Windows XP和Linux操作系统下的C开发系统诸如Microsoft Visual C++等。CUDA工具集的核其实心是一个C语言编译器,CUDA开发环境的具体内容包括: · nvcc C语言编译器 · 适用于GPU(图形处理器)的CUDA FFT和BLAS库 · 分析器 · 适用于GPU(图形处理器)的gdb调试器(在2008年3月推出alpha版) · CUDA运行时(CUDA runtime)驱动程序(目前在标准的NVIDIA GPU驱动中也提供) · CUDA编程手册 除了编译器外,NVIDIA提供了一些非常实用的函数库。目前有两个数字计算库包含在已经发布的软件包里面,分别是CUDA FFT和CUDA BLAS子程序库。CUDA FFT是快速傅立叶变换(Fast Fourier Transform, FFT)的子程序库,快速傅立叶变换是信号处理之类应用的基本算法。BLAS是基本线性代数的子程序库,提供了高效率的线性代数计算子程序。CUDA FFT和BLAS都是针对GPU高度优化的高性能数学函数库,在CUDA程序中可以方便调用,节省大量的代码编写时间。 另外,CUDA所有软件包都可以从NVIDIA公司的网站上免费下载。NVIDIA还专门建立了一个针对CUDA的名为CUDA Zone社区,网址是 http://www.nvidia.com/object/cuda_home.html。它包含各种程序、文档的下载,并且有几个针对开发者的论坛,里面有专人为各位开发者进行服务,解答各种疑问。 6CUDA应用:BadaBoom视频压缩回顶部BadaBoom视频压缩 一直以来,视频编码的转化都是令用户非常头疼的一件事,一款顶级的处理器在转换容量巨人的视频文件的时候,慢如蜗牛的速度令人难以忍受,这也主要受目前CPU性能的制约。目前,NVIDIA与许多软件开发商在推广支持GPU加速的视频压缩软件,Badaboom就是一款支持GPU加速的视频转换软件,可以把mpeg2的视频转换为ipod或者iphone这样的所使用的H.264视频格式,据称速度方面是目前CPU转化的10倍以上,为了验证其真实性,我们就做了一次相关的评测。
显卡已经抛弃了以前传统的渲染管线,取而代之的是统一流处理器,除了用作图像渲染外,流处理器自身有着强大的运算能力。我们知道CPU主要采用串行的计算方式,由于串行运算的局限性,CPU也正在向并行计算发展,比如目前主流的双核、四核CPU,如果我们把这个概念放到现在的GPU身上,核心的一个流处理相当于一个“核”,GPU的“核”数量已经不再停留在单位数,而是几十甚至是上百个,像9600GSO这样的显卡都已经有48“核”,而低端的9400GT都有16个“核”。在GPU群核并行处理的巨大优势下,NVIDIA开发的CUDA技术可以实现众多GPU计算功能,包括并行数据高速缓存器,让最新一代的多个NVIDIA GPU流处理器之间能够在执行复杂计算任务时互相协作,实现高速运算,BadaBOOM Media Convertor就是一个利用GPU实现高速编码的软件,非常实用。
从这次评测看出,对于Badaboom这类采用CUDA技术的软件,具备更多的显示核心效率就会越高,9400GT——》9500GT——》9600GT都呈递倍增长,9600GT——》9800GTX+之间差距没有前面的幅度大,应该和软件的性能有关,在压缩更大的视频文件时,更多核心的显卡所具有的优势会更为明显。目前NVIDIA的最高端显示芯片GTX280已经拥有240个核心,对于日后CUDA的发展以及应用,NVIDIA在硬件上已经做好准备,我们期待CUDA技术带来更多生活应用的解决方案。 7CUDA应用:实时的裸眼立体医疗成像回顶部CUDA应用举例:实时的裸眼立体医疗成像系统 在成像技术中,一个非常有趣的领域就是裸眼立体成像技术,它无需特殊眼镜就能显示三维立体图像。这种有趣的技术不仅有着娱乐方面的应用潜力,也可作为多种专业应用程序的实用技术。东京大学信息科学与技术研究生院机械信息系的Takeyoshi Dohi教授与他的同事研究了NVDIA的CUDA并行计算平台之后认为,医疗成像是这种平台非常有前途的应用领域之一。 自2000年以来,这所大学的研究小组已经开发出一种系统,通过CT或MRI扫描实时获得的活体截面图被视为体纹理,这种系统不仅能够通过体绘制再现为三维图像,还可作为立体视频显示,供IV系统使用。该系统为实时、立体、活体成像带来了革命性的变化。但是,它的计算量极其庞大,仅体绘制本身就会带来极高的处理工作量,况且此后还需要进一步处理来实现立体成像。对于每一个图像帧,都有众多角度需同时显示。将此乘以视频中的帧数,您会看到令人震惊的庞大计算数量,且必须在很短的时间内高度精确地完成这样的计算。
在2001年的研究中,使用了一台Pentium III 800 MHz PC来处理一些512 x 512解析度的图片,实时体绘制和立体再现要花费10秒钟以上的时间才能生成一帧。为了加速处理,研究小组尝试使用配备60块CPU的UltraSPARC III 900 MHz机器,这是当时性能最高的计算机。但可以得到的最佳结果也不过是每秒钟五帧。从实用的角度考虑,这样的速度还不够快。 研究人员使用NVIDIA GPU GeForce 8800 GTX开发了一个原型系统。在使用CUDA的GPU上运行2001年研究所用的数据集时,性能提升到每秒13至14帧。UltraSPARC系统的成本高达数千万日元,是GPU的上百倍,而GPU却交付了几乎等同于其三倍的性能,研究人员为此感到十分惊讶。不仅如此,根据小组的研究,NVIDIA的GPU比最新的多核CPU至少要快70倍。另外,测试显示,对于较大规模的体纹理数据,GPU的性能更为突出。 目前,这支研究小组正运用NVDIA最新的桌面端超级计算机Tesla D870,针对使用CUDA的Tesla优化目前的IV系统。这一举措有望使性能获得更大幅度的提升效果。 8CUDA应用:Photoshop CS4加速回顶部CUDA应用举例 Photoshop CS4支持GPU加速 Adobe Photoshop是业界最常用最强大的图像处理软件,从CS3版本开始,它支持3D图形处理。而最新的CS4版本是首个正式支持GPU加速功能图像处理软件,现在只要大家拥有一片GeForce或Quadro显卡,就可以体验实时高效的GPU加速操作,常用的处理包括图像缩放、图像旋转、图像移动等等。加速这些常用操作会令用户大大提升工作效率,让我们轻松愉快地沉醉于创作之中。 区域放大(AreaZoom)图片效果对比: 区域放大查看图片细节,这个操作是Photoshop用户经常用到的,可是往往会因为图片的像素过高,又或者操作系统的资源紧张,造成放大图片查看细节这个操作时动作极不流畅,而NVIDIA与Adobe 联手推出的Photoshop CS4,就能通过GPU来对这项操作进行加速,下面我们来对比具备GPU进行加速和不具备GPU加速的AreaZoom效果。 AreaZoom_GPU 上面的AreaZoom视频片段是采用了GPU加速,整体效果相当流畅,放大时的效果非常自然,并没有因为图片的像素过大而造成延迟。如果用CPU来进行这些操作,动作的延迟恐怕是难以避免的,下面我们来看看NO GPU的AreaZoom效果如何。 AreaZoom_NO GPU 两个视频效果对比显然易见,在没有GPU的帮助下,单靠CPU来对高像素图片进行区域放大操作,整体过渡并不算十分流畅。 此外,Premiere Pro CS4用户可以在Quadro专业级GPU的帮助下更好的利用RapiHD插件,该插件采用CUDA技术,可以更加有效的加速高清视频的解码过程。根据 NVIDIA称,如果把一个两小时播放时间的高清视频解码为H.264视频的话,CPU大约要花费28个小时,而RapiHD仅仅需要2.5-3小时。 9CUDA应用:金融业LIBOR 回顶部金融衍生品的场外交易是具有高风险、高压力的行为,而总部位于德克萨斯州奥斯汀市的SciComp公司,则拥有一款能够缩短开发时间并加速Monte Carlo定价模型性能的高科技衍生软件解决方案。增强型SciFinance®是该公司的旗舰产品,由NVIDIA® CUDA™驱动时,该产品可使衍生品定价模型的运算速度比使用串行代码时最多快100倍。更重要的是,这种加速无需任何附加工作或手动编程即可实现。在瞬息万变的市场里,稍有延迟或结果不精确就会造成价值数百万的损失,而这种加速无疑是一项重大的进步。
实现本次加速的关键就在于使用了图形处理器(GPU)来进行运算。GPU是一款群核(最新型号最多可达240个核心)并行处理器,能够以高于计算机CPU数倍的速度来运行并行应用程序。这种强大的并行计算能力在NVIDIA CUDA架构中能够被良好地释放出来。CUDA架构是一个基于业界标准C语言的编程环境,让开发人员能够编写出在极短的时间内解决复杂计算难题的软件程序。 SciComp公司执行副总裁Curt Randall表示:“在充满压力的场外交易衍生品交易中,用‘时间就是金钱’这句古老的名言来形容真是再贴切不过了。新合同的不断出现要求我们必须具备快速制作复杂数学定价模型的能力。这一过程过去采用容易出错的手动编写代码的方式来完成,通常需要花费数天到数周时间。而有了SciFinance之后,模型开发人员只需对半页或更少的模型技术规范进行少量更改,在几分钟内即可生成精确的定价模型C语言或C++源代码。” Randall 继续道:“对我们的客户来说,SciFinance无需额外编程即可生成GPU代码的新功能是一项能够改变行业游戏规则的技术。这些代码完全利用GPU并行架构的优势,能够使运行速度立即提升20到100倍。过去需要花费数分钟的定价模型现在只需几秒钟就可完成,使金融机构能够测试备选模型、增加场景分析并更好地了解他们所承担的潜在风险。最重要的是,他们不必成为并行编程概念的专家,SciFinance会负责此类工作。” 要利用CUDA架构,银行内部开发团队只需简单地使用SciFinance高级金融与数学语言描述衍生品模型即可。向模型技术规范加入关键字“CUDA”即可输出支持CUDA的源代码,这些源代码可在配有CUDA GPU的任何标准PC上运行。 银行以及避险基金等金融机构都会参与到衍生品交易,以规避财务风险。衍生品合同是一种金融工具,其价值以底层变量的波动为基础(例如,股票期权的价值由底层股票的波幅决定)。定价衍生品需要复杂的数学模型,通常需要运行上百万个场景。因此,快速而精确的运算是相当重要的。 NVIDIA®(英伟达™)公司GPU计算事业部总经理Andy Keane 表示:“SciComp是最先完全发挥GPU在计算金融领域巨大潜力的公司之一。图形处理器在这方面的强大能力确实让人难以置信,它所实现的性能提升并非小量递增而是提升了100倍。而且,以前数周的手动编程变成了即刻、实时的结果。我们期待着与SciComp继续紧密合作,为SciFinance所生成的定价模型带来更多有意义的改进,进而提高客户的商业业绩。” 10CUDA在专业音频处理上的应用回顶部GPU Impulse Reverb一定会在电脑音乐发展历史上记下一笔,它是目前第一款可以利用显卡来运算的效果器插件,这意味着你可以用它来得到高精度的卷积混响效果,而不费CPU一丝一毫之力!
GPU Impulse Reverb利用NVidia显卡的CUDA运算技术,可运行在NVIDIA的显卡上,推荐使用G80系列显卡(G8xxx及以上型号的显卡),并使用最新的支持CUDA的驱动。 GPU Impulse Reverb很简单,就是读取一个8-32bit的立体声wav文件,将它作为脉冲响应来运算卷积混响效果。 难道它的声音就比其它卷积混响效果器软件要好吗?目前还没有详细对比,但可以肯定的是:你完全解放了CPU资源(虽然GPU Impulse Reverb也需要消耗1%的CPU资源,但几乎可以忽略不计)理论上你可以得到音质更好的混响效果,因为卷积是一种非常复杂的算法,目前的卷积混响效果器软件都会在运算精度上有所妥协。 GPU Impulse Reverb只是实验的第一步,这虽然只是一小步,但确实是电脑音乐发展历史上的一大步!也许有人还记得一个叫bionicfx的公司宣称正在开发显卡运算效果器插件的事情吧?这应该是第一个公开宣称显卡在音频方面开发的公司了,他们宣布这个事情的日子是2004年8月29日,在过了4年之后,梦想才终于成真。 11CUDA应用:生命科学的研究回顶部我们一直在讨论,CUDA能否带来高性能计算、企业计算的革命,而革命其实已经在某些领域发生。最为著名的是在生命科学领域,NVIDIA GPU带来的几十上百倍的计算速度让很多研究工作从不可能变成了现实。例如,在癌症研究中重碳酸盐跟踪数据工作,便是很好的例子。
我们知道在人体中平衡酸碱度的重碳酸盐,可被癌变组织分解成二氧化碳,从而使癌变部位的酸度比周围部位高。研究人员说,重碳酸盐的这一特性可用来帮助检测癌症。核磁共振成像技术能追踪重碳酸盐在人体中发生的化学变化,因此能在早期帮助诊断癌症。参与研究的凯文·布林德尔教授说,核磁共振成像技术能帮助标出患者体内PH(酸碱度)值不正常的部位,从而确定病灶部位。 为了跟踪这些数据,如果使用原有CPU运算,以常见项目为例可能需要一周左右时间,而这还必须是高性能计算机多个CPU集群完成,如果使用普通PC,那这个研究根本没有意义。而GPU可以成百倍的速度来完成整个工作,相对现有HPC来说,占地面积极小(不可能让医院拥有一个HPC机房),一个8GPU的1U大小基于Tesla的服务器显然空间占用上更合理。同时,从运算速度和能耗来说,也绝对优于CPU为主的HPC。 12CUDA应用:地理信息系统回顶部从追踪911电话报警地点到研究二氧化碳浓度以便掌握杀虫剂的使用情况,地理信息系统(GIS)应用程序正在多个应用领域迅速发展。全球视觉计算技术的行业领袖NVIDIA®(英伟达™)公司以及Manifold公司于今日正式宣布,双方将展开紧密合作,利用屡获殊荣的NVIDIA CUDA™开发环境来加速应用程序在GPU(图形处理器)上的运算速度,使地理信息系统的功能更加强大。
Manifold.net产品部经理Dimitri Rotow表示:“地理信息系统数据集已经变得越来越复杂,并且常常会涉及到许多千兆字节的交互式地图。在这种压力下,我们推出了能够快速、高效并准确处理这些数据集的产品。有了CUDA的帮助,从前需要20分钟才能完成的运算现在只需30秒即可完成,而从前需要30到40秒钟完成的运算现在能够实现实时运算。我可以毫不夸张地说,至少在我们这个行业里,NVIDIA CUDA技术是自微处理器发明以来计算行业内所诞生的最具革命性的技术。” 地理信息系统数据集变得越来越复杂,其主要原因是收集的数据量更大并且需要进行更加详细的分析。卫星照片曾经是情报分析员才能看到的东西,而现在,任何连接到互联网的人都可以看到卫星照片。此外,“远程传感”卫星现在采用多个传感器来实现地球成像,这些传感器可从各种不同角度收集多种波长和分辨率的数据,而这些影像的合成工作则是一项艰巨的任务。例如,对考古学家来说,如果没有CUDA带来的GPU加速功能,地理信息系统用户就只能停留在忽略了精细地形文物的低分辨率水平。这种低分辨率意味着寻找地下城堡的轮廓(个别墙体除外)以及挖掘工作的实施都会很困难并且代价高昂。 Manifold于2007年5月开始使用CUDA,他们仅用了两个月的时间就完成了系统的代码重写工作,使得他们的系统能够利用GPU的并行处理能力。Manifold系统第8版是全球最强大、功能最全面的地理信息系统软件包,最近在加拿大渥太华举行的2008年地理技术大会上一举击败了包括AutoDesk、Gaia以及Magellan等在内的12个得到提名的杰出对手,赢得了2008年地理空间领袖奖。 Manifold的提名和颁奖辞为:“Manifold是首款利用强大并行超级计算技术、并在台式机上运行的地理信息系统,而这款台式机采用的是价格不到500美元却具备数百个流处理器的独立显卡。该系统创新地采用了价格低廉的消费级硬件,使地理信息系统的处理任务以及分析工作的运算速度比从前快了数百倍。” 13CUDA的应用:Folding@home(抗癌)应用回顶部什么是Folding@home? Folding@home是一个研究研究蛋白质折叠,误折,聚合及由此引起的相关疾病的分布式计算工程。我们使用联网式的计算方式和大量的分布式计算能力来模拟蛋白质折叠的过程,并指引我们近期对由折叠引起的疾病的一系列研究。(摘自Folding@home中文网) Folding@home客户端程序可以借助客户机的CPU、NVIDIA CUDA enable GPU的运算性能进行计算。目前Folding@home推出了支持CUDA的版本,我们可以利用GeForce GTX200系列的GPU科学计算能力进行运算。
在NVIDIA GPU加入了Folding@Home(下文简称FAH)后,NVIDIA GPU贡献的运算量在短短几个月内超越了几年来CPU贡献的总量。如果你用心加入FAH的团队,而不是把FAH当作一个看3D小球抖动的屏保的话,那么你会发现GPU对于FAH是多么的重要。在全世界FAH的排行榜上,你可以找到许多熟悉的面孔,也可以找到属于中国的团队。而FAH的运算,对于蛋白质折叠与人类癌症相关研究的贡献带来了质的改变。 14CUDA的应用:物理引擎PhysX回顶部物理加速游戏对比评测:Nurien Tech Demo Alpha v0.7
这个游戏的名称是Mstar,是由韩国新公司Nurien Software使用Epic公司的虚幻3引擎开发的一款舞蹈网络游戏。 Mstar将打击与舞蹈完美结合,人物的肢体语言极为丰富,由于支持PhysX,虚拟形象的局部特写制作得淋漓尽致,尤其是头发与裙子部分。玩家将得到更真实的体验。据有关消息报道,该游戏将于年底在国内推出。
评测方法: 采用自带的BenchMark进行测试。
在这个游戏中,支持PhysX的9600GT、9800GTX表现出非常出色,在打开PhsyX物理加速后,性能提升达到100%,相当惊人。 15CUDA走进高校,成为专业课程回顶部今年初,3月25日上午, 美国国家工程院院士、NVIDIA公司首席科学家David B.Kirk博士应邀到清华大学深圳研究生院作题为《NVIDIA CUDA科学之旅》的学术讲座。深圳研究生院副院长刘文煌教授出席讲座并致欢迎辞。院信息学部主任钟玉琢教授等师生,以及哈工大、北大等高校学生共170多人参加此次讲座。而就在本文完成的一周前,CUDA在清华的讲座规模又在扩大。11月17日-11月21日清华大学微电子学研究所邓仰东副教授与NVIDAI共同主办CUDA技术讲座。在2008年内,关于CUDA,CUDA PhysX的讲座,在全国高校内课时超过数百,影响人次数十万。 在美国,伊利诺伊大学厄本那—香槟分校因其在并行计算教育中的开拓性工作而被指定为CUDA卓越中心。伊利诺伊大学厄本那—香槟分校的理论和计算生物物理学小组是首批利用GPU(图形处理器)的并行架构来提高计算生物物理学研究速度的研究小组之一,他们已经成功地提高了NAMD/VMD的研究速度。 NAMD/VMD是一种流行的并行分子动力学应用,用于分析大型生物分子系统。NVIDIA®(英伟达™)也希望能够通过捐赠,帮助该大学的理论和计算生物物理学小组以及其他小组提高工作速度、更快地实现重大发现。 伊利诺伊大学Swanlund物理学教授兼理论和计算生物物理学小组(www.ks.uiuc.edu)组长Klaus Schulten博士表示:“能够与NVIDIA®(英伟达™)合作我们感到十分兴奋。我们期待着双方共同合作实现生物医药领域的突破性发展,更好地理解疾病,并找到更为有效的治疗方法。这次慷慨的捐赠对于理论和计算生物物理学小组年轻的程序员将是极大的激励,将会扩大我们的研究队伍,也赋予了他们在未来十年中实现计算机进步的必要工具。” 希望成为CUDA卓越中心的大学必须教授CUDA™课程,并且在多个实验室的研究中采用CUDA技术。 现在对于喜欢CUDA的朋友更可以浏览CUDA中文网站观看CUDA的在线讲座
CUDA引领未来并行计算
GPU超强的计算能力让它在通用计算领域大有可为,而CUDA则让它变成可能,简单易用的开发环境让CUDA主导起GPU计算的革命。 CUDA(Compute Unified Device Architecture)是一个新的基础架构,这个架构可以使用GPU来解决商业、工业以及科学方面的复杂计算问题。跟以往的GPGPU概念不同的是,CUDA是一个完整的解决方案,包含了API、C编译器等,能够利用显卡核心的片内L1 Cache共享数据,使数据不必经过内存-显存的反复传输,shader之间甚至可以互相通信。对数据的存储也不再约束于以往GPGPU的纹理方式,存取更加灵活,可以充分利用stream out特性。以上几点都将大大提高GPGPU应用的效率。例如,在游戏中我们可以使用CUDA来让GPU承担整个物理计算,而玩家将会获得另他们感到惊奇的性能和视觉效果。另外,用于产品开发和巨量数据分析的商业软件也可以通过它来使用一台工作站或者服务器完成以前需要大规模的计算系统才能完成的工作。这一技术突破使得客户可以任何地方进行实时分析与决策。同时,一些以前需要很先进的计算技术来达到的强大计算能力的科学应用程序,也不再受限在计算密度上;使用CUDA的计算可以在现有的空间里为平台提供更强大的计算性能。CUDA采用C语言作为编程语言提供大量的高性能计算指令开发能力,使开发者能够在GPU的强大计算能力的基础上建立起一种效率更高的密集数据计算解决方案。 CUDA工具包推出已有1年,它的推出马上受到了众多软件/游戏开发商以及科研机构和程序爱好者的欢迎,NVIDIA方面也将发布最新的CUDA 2.0版本。相信在未来,CUDA将会受到越来越多的领域的支持。目前,支持CUDA环境的GPU主要有采用统一渲染架构的显示核心。
CUDA的未来 首先我们从GPU的处理能力来看,现在的显卡和游戏是互相推动的发展,游戏需要更强劲的GPU,GPU为了满足游戏的需求也必须要不断的升级,可以预计未来GPU计算能力还会继续不断的增加。那么现在对于CUDA的开发者来说,CUDA学习还有CUDA的软件能够随着GPU的性能提升而获利。 目前已发布软件众多的CUDA技术的软件,比如鼎鼎大名的PhotoShop CS4,根据NVIDIA表示在未来一段时间里也将会有不少其他方面的CUDA软件将出现。 如你所见,视频功能的日渐丰富是当今计算机发展的主流趋势,这些软件通过GPU 的提升可以明显的得到更快、更连贯的显示效果。而这些性能的改变单靠提升CPU的运算性能,是无法完全实现的。可以说,CUDA将GPU强大的浮点运算能力转化为全新的应用方式更加简单,将成为PC机正在经历的一场全新变革;我们的数字生活也将会因CUDA开发GPU强大运算能力而步入全新的视觉时代。未来随着更多的软件开发人员加入CUDA开发GPU强大的运算能力,CUDA会带给我们更多的惊喜。未来CUDA带来一个新的GPU使用方式。 |
 步入DX10时代,shader(流处理器)单元数量成为衡量显卡级别的重要参数之一
步入DX10时代,shader(流处理器)单元数量成为衡量显卡级别的重要参数之一 GPU运算能力越来越快,甚至超越CPU
GPU运算能力越来越快,甚至超越CPU CPU和GPU的架构区别
CPU和GPU的架构区别
 公版Geforce GTX 280显卡
公版Geforce GTX 280显卡

 CUDA提供了硬件的直接访问接口,不必依赖图形API
CUDA提供了硬件的直接访问接口,不必依赖图形API
 CPU和GPU通过Global Memory交流数据
CPU和GPU通过Global Memory交流数据 某些领域应用CUDA后所获得的数据上的提升
某些领域应用CUDA后所获得的数据上的提升







 Mstar美女MM形象代言
Mstar美女MM形象代言

 Nvidia cuda zone中文站
Nvidia cuda zone中文站
 并行处理器在各个方面都有优势
并行处理器在各个方面都有优势【本文地址】