| 《Cython系列》2. 编译并运行 Cython 代码的几种方式 | 您所在的位置:网站首页 › cpython与cython › 《Cython系列》2. 编译并运行 Cython 代码的几种方式 |
《Cython系列》2. 编译并运行 Cython 代码的几种方式
|
楔子
Python 和 C、C++ 之间一个最重要的差异就是 Python 是解释型语言,而 C、C++ 是编译型语言。如果开发 Python 程序,那么在修改代码之后可以立刻运行,而 C、C++ 则需要一个编译步骤。编译一个规模比较大的 C、C++ 程序,那么可能会花费我们几个小时甚至几天的时间;而使用Python则可以让我们进行更敏捷的开发,从而更具有生产效率。 而 Cython 同 C、C++ 类似,在源代码运行之前也需要一个编译的步骤,不过这个编译可以是隐式的,也可以是显式的。而自动编译 Cython 的一个很棒的特性就是它使用起来和纯 Python 是差不多的,无论是显式还是隐式,我们都可以将 Python 的一部分(计算密集)使用 Cython 重写,因此 Cython 的编译需求可以达到最小化。因为没有必要将所有的代码都用 Cython 编写,而是将那些需要优化的代码使用 Cython 编写即可。 在这一篇博客中,我们将会介绍编译 Cython 代码的几种方式,并结合 Python 使用。因为我们说 Cython 是为 Python 提供扩展模块,最终还是要通过 Python 解释器来调用的。 而编译Cython有以下几个选择: Cython 代码可以在 IPython 解释器中进行编译,并交互式运行。 Cython 代码可以在导入的时候自动编译。 Cython 代码可以通过类似于 Python 的 disutils 模块的编译工具进行独立编译。 Cython代码可以被继承到标准的编译系统,例如:make、CMake、SCons。这些选择可以让我们在几个特定的场景应用 Cython,从一端的快速交互式探索到另一端的快速构建。 但无论是哪一种编译方式,从传递 Cython 代码到生成 Python 可以导入和使用的扩展模块都需要经历两个步骤。在我们讨论每种编译方式的细节之前,了解一下这两个步骤到底在做些什么是很有帮助的。 Cython编译 Pipeline因为 Cython 是 Python 的超集,所以 Python 解释器无法直接运行 Cython 的代码,那么如何才能将 Cython 代码变成 Python 解释器可以识别的有效代码呢?答案是通过 Cython 编译 Pipeline。 Pipeline 的职责就是将 Cython 代码转换成 Python 解释器可以直接导入并使用的 Python 扩展模块,这个 Pipeline 可以在不受用户干预的情况下自动运行(使 Cython 感觉像 Python 一样),也可以在需要更多控制时由用户显式的运行。 Pipeline 由两步组成:第一步是由 cython 编译器负责将 Cython 转换成经过优化并且依赖当前平台的 C、C++ 代码;第二步是使用标准的 C、C++ 编译器将第一步得到的 C、C++ 代码进行编译并生成标准的扩展模块,并且这个扩展模块是依赖特定的平台的。如果是在 Linux 或者 Mac OS,那么得到的扩展模块的后缀名为 .so,如果是在 Windows 平台,那么得到的扩展模块的后缀名为 .pyd(扩展模块 .pyd 本质上是一个 DLL 文件)。不管是什么平台,最终得到的都会是一个成熟的 Python 扩展模块,它是可以直接被 Python 解释器进行 import 的。 而工具在管理这几个步骤所面临的复杂性,我们都会在这一篇博客的结尾进行描述。尽管在编译 Pipeline 运行的时候我们很少去关注究竟发生了什么,但是将这些过程记在脑海总归是好的。 Cython编译器是一种 源到源 的编译器,并且生成的扩展模块也是经过高度优化的,因此 Cython 生成的 C 代码编译得到的扩展模块 比 手写的 C 代码编译得到的扩展模块 运行的要快并不是一件稀奇的事情。因为 Cython 生成的 C 代码是经过高度精炼,所以大部分情况下比手写所使用的算法更优,而且 Cython 生成的 C 代码支持所有的通用 C 编译器,生成的扩展模块同时支持许多不同的 Python 版本。 所以 Cython 和 C 扩展本质上干的事情是一样的,都是将符合 Python/C API 的 C 代码编译成 Python 扩展模块,只不过写 Cython 的话我们不需要直接面对 C,cython 编译器会自动将 Cython 代码翻译成 C 代码,然后我们再将其编译成扩展模块。所以两者本质是一样的,只不过 C 比较复杂,而且难编程;但是 Cython 简单,语法本来就和 Python 很相似,所以我们选择编写 Cython,然后让 cython 编译器帮我们把 Cython 代码翻译成 C 的代码。而且重点是,cython 编译器是经过优化的,如果我们能写出很棒的 Cython 代码,那么 cython 编译器在编译之后就会得到同样高质量的 C 代码。 安装现在我们知道在编译 Pipeline 中有两个步骤,而实现这两个步骤需要我们确保机器上有 C、C++ 编译器以及 Cython 编译器,不同的平台有不同的选择。 C、C++编译器Linux 和 Mac OS 无需多说,因为它们都自带 gcc,但是注意:如果是 Linux 的话,我们还需要 yum install python3-devel(以 CentOS 为例)。至于 Windows,可以下载一个 Visual Studio,但是那个玩意会比较大,如果不想下载 vs 的话,那么可以选择安装一个 MinGW 并设置到环境变量中,至于下载方式可以去 https://sourceforge.net/projects/mingw/files/ 进行下载。 当然环境什么的,这里就不细说了,如果这一点都无法解决的话,根本就入不了 Cython 的大门。 安装 cython 编译器安装 cython 编译器的话,可以直接通过 pip install cython 即可。因此我们看到 cython 编译器只是 Python 的一个第三方包,因此运行 Cython 代码同样要借助 Python 解释器。 在终端中输入 cython -V,看看是否会提示 cython 的版本,如果正常显示,那么证明安装成功。
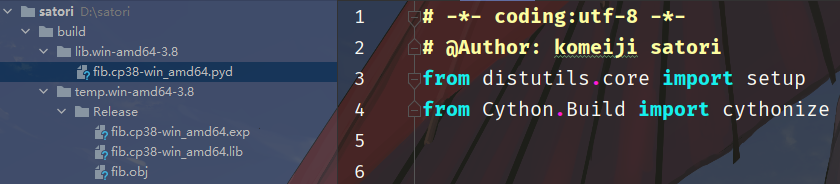
或者写代码查看: from Cython import __version__ print(__version__) # 0.29.14如果代码正常执行,那么证明安装成功。 disutilsPython 有一个标准库 disutils,可以用来构建、打包、分发 Python 工程。而其中一个对我们有用的特性就是它可以借助 C 编译器将 C 源码编译成扩展模块,并且这个模块是自带的、考虑了平台、架构、Python 版本等因素,因此我们在任意地方使用disutils都可以得到扩展模块。 注意:上面 disutils 只是帮我们完成了 Pipeline 的第二步,那第一步呢?第一步则是需要 cython 来完成。 以我们之前说的斐波那契数列为栗: # fib.pyx def fib(n): """这是一个扩展模块""" cdef int i cdef double a=0.0, b=1.0 for i in range(n): a, b = a + b, a return a然后我们对其进行编译: from distutils.core import setup from Cython.Build import cythonize # 我们说构建扩展模块的过程分为两步: 1. 将 Cython 代码翻译成 C 代码; 2. 根据 C 代码生成扩展模块 # 而第一步要由 cython 编译器完成, 通过 cythonize; 第二步要由 distutils 完成, 通过 distutils.core 下的 setup setup(ext_modules=cythonize("fib.pyx", language_level=3)) # 里面的 language_level=3 表示只需要兼容 python3 即可, 而默认是 2 和 3 都兼容 # 强烈建议加上这个参数, 因为目前为止我们只需要考虑 python3 即可 # cythonize 负责将 Cython 代码转成 C 代码, 这里我们可以传入单个文件, 也可以是多个文件组成的列表 # 或者一个glob模式, 会匹配满足模式的所有 Cython 文件; 然后 setup 根据 C 代码生成扩展模块这个文件叫做 1.py,这里只是做了准备,但是还没有进行编译。我们需要终端执行 python 1.py build 进行编译。
在我们执行命令之后,当前目录会多出一个 build 目录,里面的结构如下。重点是那个 fib.cp38-win_amd64.pyd 文件,该文件就是根据 fib.pyx 生成的扩展模块,至于其它的可以直接删掉了。我们把这个文件单独拿出来测试一下: import fib # 我们看到该 pyd 文件直接就被导入了, 至于中间的 cp38-win_amd64 指的是对应的解释器版本、操作系统等信息 print(fib) # try: # 我们在里面定义了一个 fib 函数, 在 fib.pyx 里面定义的函数在编译成扩展模块之后可以直接使用 print(fib.fib("xx")) except Exception: import traceback print(traceback.format_exc()) """ Traceback (most recent call last): File "D:/satori/1.py", line 7, in print(fib.fib("xx")) File "fib.pyx", line 6, in fib.fib for i in range(n): TypeError: an integer is required """ # 因为我们定义的是fib(int n), 而传入的不是整型, 所以直接报错 print(fib.fib(20)) # 6765.0 # 我们的注释 print(fib.fib.__doc__) # 这是一个扩展模块我们在 Linux 上再测试一下,代码以及编译方式都不需要改变,并且生成的动态库的位置也不变。 >>> import fib >>> fib >>> exit()我们看到依旧是可以导入的,只不过 Linux 上是 .so 的形式,Windows 上是 .pyd。因此我们可以看出,所谓 Python 的扩展模块,本质上就是当前操作系统上一个动态库,只不过生成该动态库对应的 C 源文件遵循标准的 Python/C API,所以它是可以被 Python 解释器识别、直接通过 import 语句进行导入的,就像导入普通的 py 文件一样。而对于其它的动态库,比如 Linux 中存在大量的动态库(.so文件),而它们则不一定是由遵循标准 Python/C API 的 C 文件生成的,所以此时再通过 import 进行导入的话解释器是无法识别的,如果 Python 想调用这样的动态库就需要使用 ctypes 模块了。 引入 C 源文件除此之外我们还可以嵌入 C、C++ 的代码,我们来看一下。 // cfib.h double cfib(int n); // 定义一个函数声明 //cfib.c double cfib(int n) { int i; double a=0.0, b=1.0, tmp; for (i=0; i |
【本文地址】