| 【mysql哪些事儿】distinct 和 group by用法总结 | 您所在的位置:网站首页 › by用法总结 › 【mysql哪些事儿】distinct 和 group by用法总结 |
【mysql哪些事儿】distinct 和 group by用法总结
|
需求是这样的,因为公司现在统计这一块做的不是十分完善,所以每天老板那边会需要根据各种条件的数据统计,因为用户达到了千万级别,所以每次统计查询其消费数据的时候,数据量,都需要手动导出数据来,将这些数据拼接起来,然后做成excel表格的形式,上报给boss。 原来一直是另一个同事做,但是昨天同事不在,所以任务就落在了我的身上。经过和其他同事请教,发现这里面很多问题需要注意。第一,这些数据设计到5张表,每张表的数据量都特别大,所以如果联表查询的话,那么执行效率会很慢,所以建议单表查询,然后再将数据合并。第二,这些数据需要及时的保存和处理,以备下次使用。 好久不写sql,这次又学习了一遍。
一、distinct 去重
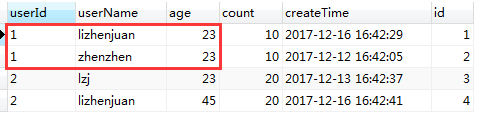
在mysql中,有时候需要查询某个字段不重复的记录,这个月可以使用关键字distince关键字来过滤重复的记录。在实际的生活中,经常也会使用count(distinctId)来返回不重复字段的条数。 查询语句: -- 根据用户名称来去重 SELECT DISTINCT t.userName FROM t_user t执行结果如下: (2)作用于多列 -- 根据用户名称和年龄两个字段去重 -- 会过滤用户名称和ID都重复的字段,(只有username和age都相同的才会被过滤为一条) SELECT DISTINCT t.userName,t.age FROM t_user t (3)注意事项distinct必须放在查询字段的开头,例如: SELECT t.userName,DISTINCT t.age FROM t_user t 会报错。如果要查询不重复的记录,还可以使用group by进行分组。 (4)count(distinct userName) 可以返回不重复记录的条数 -- 返回不重复记录的条数 SELECT count( DISTINCT t.userName) FROM t_user t 二、group by语句
group by 是按照一个或者多个字段进行分组,字段值相同的为一组。可以作用于单个字段分组,也可以用于多个字段分组。 适用场景: 如果要用到group by,一般用到的就是“每这个字”,例如现在说明有个这样的表:每个班级有多少人,就需要用到分组这个关键字。
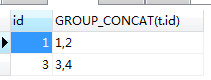
(1)group +group_concat() group_concat(字段名)可以作为一个输出字段来使用, 表示分组之后,根据分组结果,使用group_concat()来放置每一组的某字段的值的集合 -- group_concat()函数 -- 按照userID分组,然后查找每组内对应的记录ID SELECT t.id,GROUP_CONCAT(t.id) from t_user t GROUP BY t.userId(2) group by + 集合函数 通过group_concat()的启发,我们既然可以统计出每个分组的某字段的值的集合,那么我们也可以通过集合函数来对这个"值的集合"做一些操作 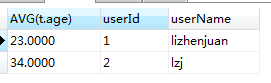 -- 根据userId分组,然后统计每组userid的数目
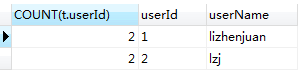
SELECT COUNT(t.userId),t.userId,t.userName FROM t_user t GROUP BY t.userId
-- 根据userId分组,然后统计每组userid的数目
SELECT COUNT(t.userId),t.userId,t.userName FROM t_user t GROUP BY t.userId
(3)group by 按照多个字段分组 group by按照多个字段进行分组,只有两个字段都符合条件时,才会分组成功。 例如A表的数据如下:
(4)where --group by---- having 使用 每个字段有其不同的作用。count()是属于聚合函数,聚合函数不能出现在where中。 where和group连用,但是效果和having是不同的,where必须放在group by前面,意思是先过滤,然后再次分组。 而having是必须在group by 之后连用,是分组后的过滤。
①常见的聚合函数 count(*):获取数量 sum():求和(这里要注意求和是忽略null值的,null与其他数值相加结果为null,所以可以通过ifnull(xxx,0)将null的值赋为0) avg():求平均数 max():求最大值 min():求最小值 这些函数和其他函数的区别是,这些函数一般作用于多条记录上。
②当使用where ,group by ,having之后的执行顺序如下 例如: select city, count(*),age from dbo.user where departmentID=2 group by city,age having age >40 第一执行where子句查询复合条件的数据, 第二使用group by子句对数据进行分组,第三对group by子句形成的组进行聚合函数计算每一组的值,第四用having子句去掉不符合条件的组。having子句限制的是组,而不是行。 where中不能够使用聚合函数,但是having子句中可以。例如: 每个用户,count 总量大于30的记录 -- 查询总count > 30 SELECT t.id,t.userId,t.userName,t.age ,SUM(count) FROM t_user t GROUP BY t.userId HAVING SUM(count)>30显示每个地区的总人口数和总面积.仅显示那些面积超过1000000的地区。 SELECT region, SUM(population), SUM(area) FROM bbc GROUP BY region HAVING SUM(area)>1000000 在这里,我们不能用where来筛选超过1000000的地区,因为表中不存在这样一条记录。(where子句中不能使用聚集函数) 相反,HAVING子句可以让我们筛选成组后的各组数据③ 整个sql的执行顺序如下 select--->where ---> group by ---->having ---->order by 参考文档: sql中where、group by、having的用法和区别 sql中的 where 、group by 和 having 用法解析(having使用讲解特别详细)
小结 总结实践,再学习,再总结,不断提升,注重细节。
|

【本文地址】