| Django DRF | 您所在的位置:网站首页 › bootstrappageinator共多少页 › Django DRF |
Django DRF
|
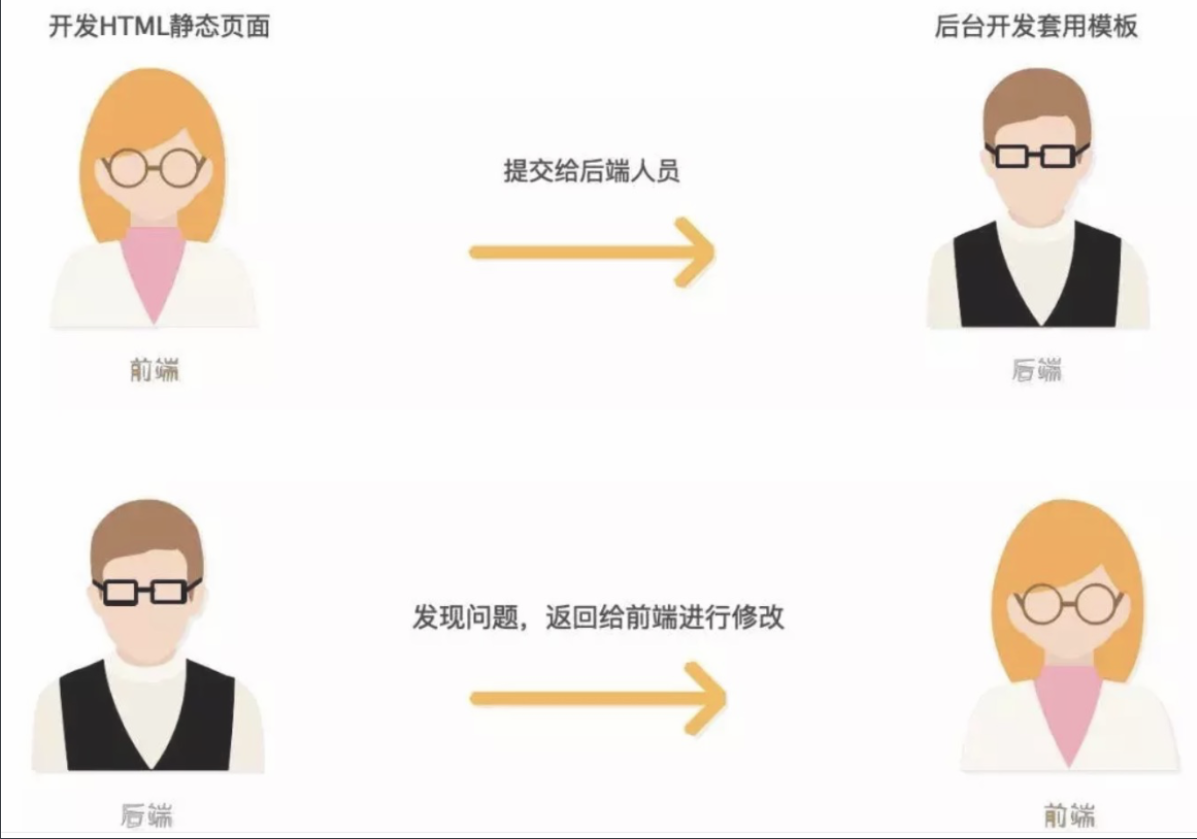
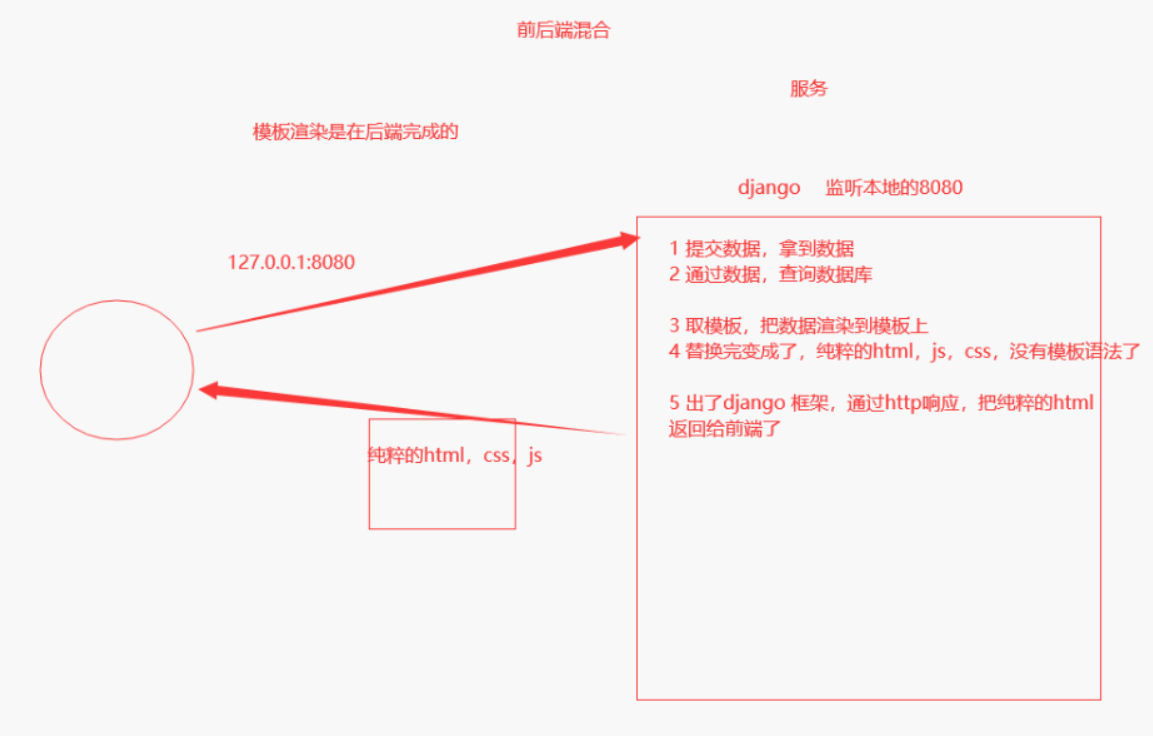
目录 一.Django DRF入门规范 1.web的两种应用模式 1)前后端不分离(传统的开发模式) 2)前后端分离 2.API接口 3.接口测试工具postman 4.restful的十条规范 5.序列化反序列化 6.基于django原生编写5个接口 7.drf下载与快速使用 8.CBV源码分析 9.基于APIView编写5个接口 单表时数据准备: 1)基于APIView+JsonResponse 2)基于APIView+Response 10.APIView的执行流程 总结(背) 11.Request对象源码分析(了解) 总结(背) 二.序列化组件(重点) 1.序列化组件简介 基于APIView+Response+serializers编写接口 2.序列化类 单表时数据准备 1)序列化多条(查询所有书) 2)序列化单条(查询一本书) 3.反序列化类 1)反序列化新增(新增一本书) 2)反序列化修改(修改一本书) 3)删除单条(删除一本书) 4.反序列化的数据校验功能 5.序列化类常用字段 6.序列化类常用字段参数 7.序列化高级用法之source(了解) 多表时数据准备 1)查询所有图书接口 定制序列化的字段名字(改名字不和数据库中的名字对应) 8.序列化高级用法之定制字段的两种方式(重点) 1)在SerializerMethodField定制 2)在表模型中定制 9.多表关联反序列化保存 1)新增一本图书接口 2)修改一本图书接口 10.反序列化校验字段的4层 11.模型类序列化器(ModelSerializer)使用 12.反序列化类校验部分源码分析(了解) 13.断言 三.drf的请求与响应 1.请求 1)Request类能解析的请求编码格式 2)Request类源码中有哪些属性和方法 2.响应 1)Response类能解析的响应编码格式 2)Response类源码中有哪些属性和方法 四.视图组件 1.视图组件 2.两个视图基类 1)基于APIView+ModelSerializer+Response写Book表5个接口>>第一层 2)基于GenericAPIView+ModelSerializer+Response写Book表的5个接口>>第二层 3.五个视图扩展类(不是视图类) 1)基于GenericAPIView+五个视图扩展类写Book表的5个接口>>第三层 4.九个视图子类 1)基于九个视图子类+ModelSerializer写Book表的5个接口>>第四层 5.视图集 1)基于ModelViewSet+ModelSerializer编写5个接口>>第五层 2)基于ReadOnlyModelViewSet编写2个只读(查所有/查单个)接口 3)ViewSetMixin源码分析 4)from rest_framework.viewsets import xxx 可以导的类 6.视图总结 五.路由组件 1.自动生成路由 2.action装饰器(重要) 六.认证权限频率 1.认证 1)登录接口 2)原生django的cookie+session认证底层原理 3)使用步骤 4)案例 数据准备 代码 2.权限 1)使用步骤 2)案例 3.频率 1)使用步骤 2)案例 七.过滤排序分页 1.过滤 1)内置过滤类(模糊匹配) 2)第三方djagno-filter实现过滤(精准匹配) 3)自定义过滤类来过滤 2.排序 1)内置排序 3.分页 1)基本分页:查几页 每页显示多少条※ 2)偏移分页:从第几条开始显示多少条 3)游标分页:只能选择上一页或下一页※ 4)基于APIView编写分页 4.三大认证源码分析 1)认证类源码分析 2)权限类源码分析 3)频率类源码分析 4)自定义频率类(了解) 5)SimpleRateThrottle源码分析 八.全局异常处理 1.异常处理操作 九.接口文档 十.jwt(重点) 1.前戏cookie、session、token发展史 2.jwt介绍和原理 3.jwt的构成 补充:base64编码与解码 4.jwt快速使用 1)快速使用 2)定制返回格式 3)jwt的认证类(限制登录后才能访问接口) 4)jwt快速使用验证 5.jwt源码执行流程(了解) restframework-jwt执行流程 1)签发(登录) 2)认证(认证类) 6.自定义user表签发和认证 1)签发(登录) 2)认证(认证类) 补充:token过期 3)验证 十一.simpleui的使用 1)使用步骤 2)大屏显示 十二.权限控制(acl、rbac) 十三.补充 1.django里auth的user表 密码是加密的,就算是同样的密码 密文也不一样 2.django的auth的user生成密文密码使用下面的模块中的函数去做的,当想实现一样的加密就可以导入该函数去做 3.用户表的密码忘了怎么办??? 4.双token认证 一.Django DRF入门规范 1.web的两种应用模式 django web框架 专门用来写web项目 1)前后端不分离(传统的开发模式)之前写的bbs项目、图书管理系统用的都是前后端混合开发出来的 后端程序员:不仅要写后端代码,还要写模板语法(xx.html上用{{}}python代码编写) 此处的.html不是前端页面 只是一个模板 全栈开发:前后端不分离时较多 在前端调试的时候要安装完整的一套后端开发工具,要把后端程序员完全启动起来,遇到问题需要后端开发来帮忙调试,我们发现前后端严重耦合,还要后端人员有一些HTML、JS等前端语言的了解,前端页面还嵌套了很多后端的代码,如果后端要换一种语言,那么可能需要重新做,这就导致了前后端的开发进度受到了影响,从而大大降低了开发效率 前端写好静态的html页面交付给后端开发。静态页面可以本地开发,无需考虑业务逻辑只需要实现View即可 后端使用模板引擎去套模板,同时内嵌一些后端提供的模板变量和一些逻辑操作 然后前后端集成对接,遇到问题前端返工后端返工,然后再集成对接直到成功为止
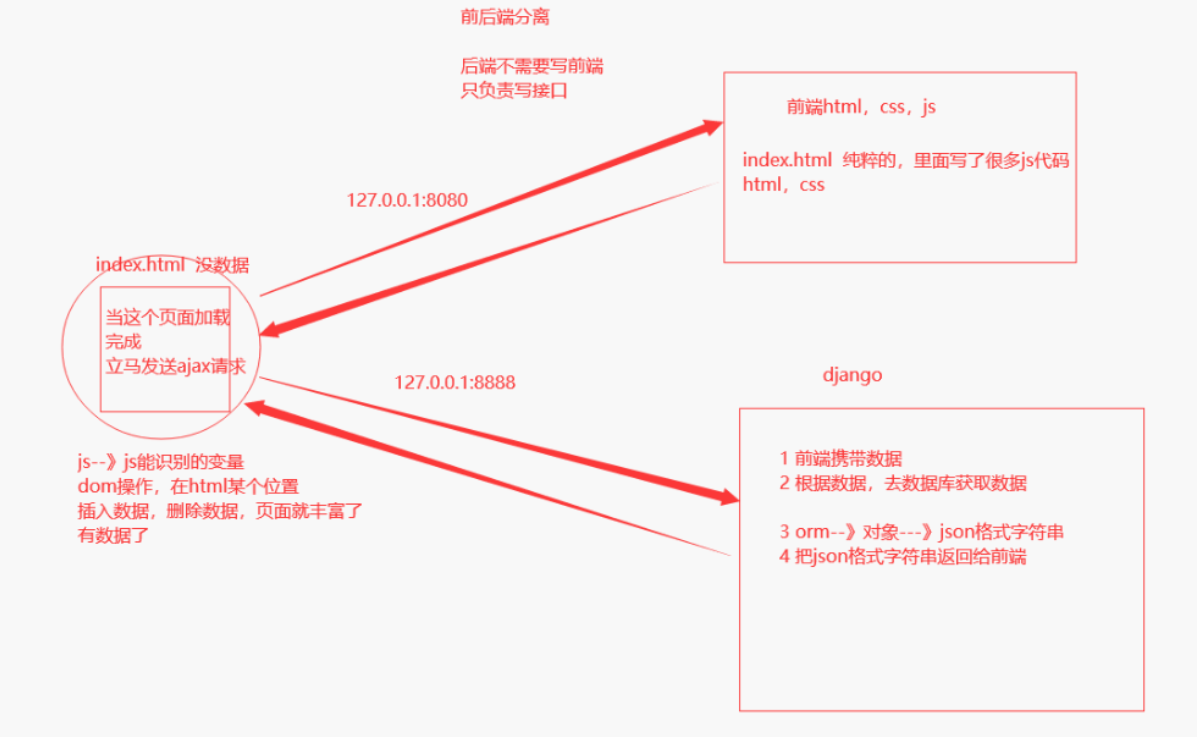
今后要写的都是前后端分离项目 后端程序员:不需要写前端,只需要写后端接口即可 全栈开发:还需掌握web后端、前端框架(vue、react) 前后端分离并不只是开发模式,而是web应用的一种架构模式。在开发阶段,前后端工程师约定好数据交互接口,实现并行开发和测试;在运行阶段前后端分离模式需要对web应用进行分离部署,前后端之前使用HTTP或者其他协议进行交互请求。 后端人员只需要负责写接口(API接口),使用postman接口测试工具测试 前端人员负责写前端,写的过程中用mock数据 最后:前后端联调项目
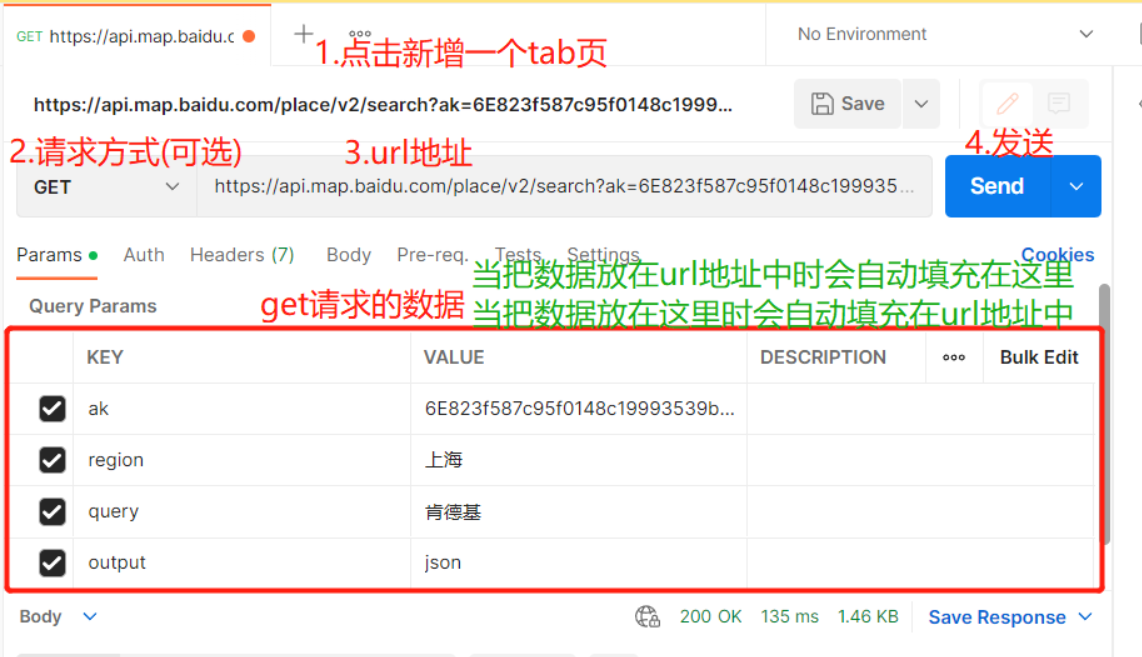
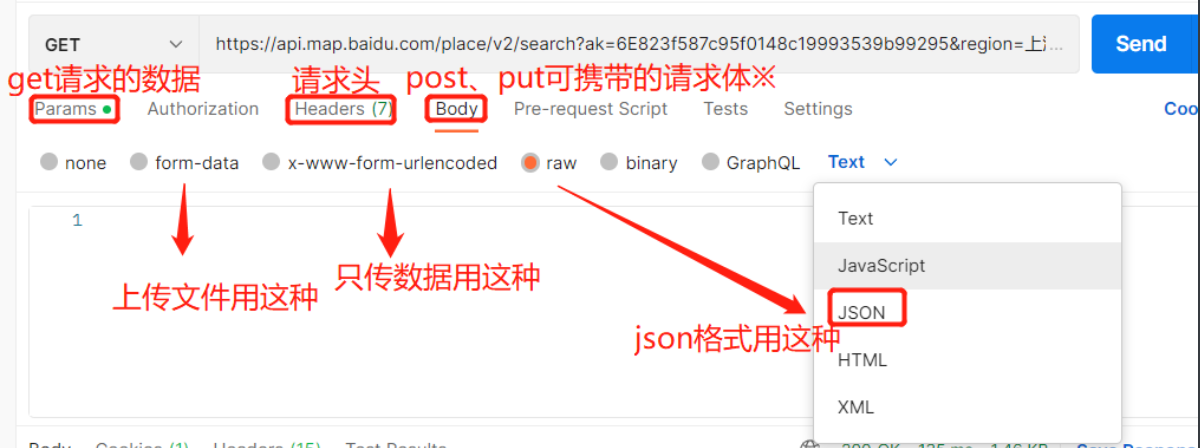
API(Application Programming Interface,应用程序编程接口) 1)为了在团队内部形成共识、防止个人习惯差异引起的混乱,我们需要找到一种大家都觉得很好的接口实现规范,而且这种规范能够让后端写的接口,用途一目了然,减少双方(前后端)之间的合作成本 2)通过网络,规定了前后台信息交互规则的url链接,也就是前后端信息交互的媒介 如BBS项目中通过某个路由访问某个接口 总结:API接口就是前后端信息交互的媒介 此时的前端不仅是网页,还有app、小程序等 后端是python、go、java写的web后端 作用:API接口是一组定义程序及协议的集合,通过API实现计算机软件之间的互相通信,API主要的功能是提供通用功能集。程序员通过调用API接口函数对应用程序进行开发可以减轻编程任务。API同时也是一种中间件,为不同平台提供数据共享。 API接口格式: url地址:长的像返回数据的url链接 请求方式:get、post、put、patch、delete 请求参数:?后面的json或xml格式的k=v数据类型 早期用xml 现在用json 后期会有更高级安全的交互格式 ak=6E823f587c95f0148c19993539b99295 region=上海 query=肯德基 output=json 响应结果:json或xml格式的数据 API接口案例: # xml格式 【早些年】 # https://api.map.baidu.com/place/v2/search?ak=6E823f587c95f0148c19993539b99295®ion=上海&query=肯德基&output=xml #json格式 【现在的主流】 https://api.map.baidu.com/place/v2/search?ak=6E823f587c95f0148c19993539b99295®ion=上海&query=肯德基&output=json { "status":0, "message":"ok", "result_type":"poi_type", "results":[ { "name":"肯德基(堡镇店)", "location":{ "lat":31.544448, "lng":121.63229 }, "address":"上海市崇明区石岛路617弄11号12号", "province":"上海市", "city":"上海市", "area":"崇明区", "detail":1, "uid":"213d741cd24ba80ee8e58280" }, ... ] } 3.接口测试工具postman当API接口写好后,后端人员需要先自己测试,由于浏览器只能发get请求,不能发post、delete请求,所以就要用接口测试工具postman 本质就是:模拟发送http请求 postman测试工具下载地址:https://www.postman.com/downloads/ 请求的操作:
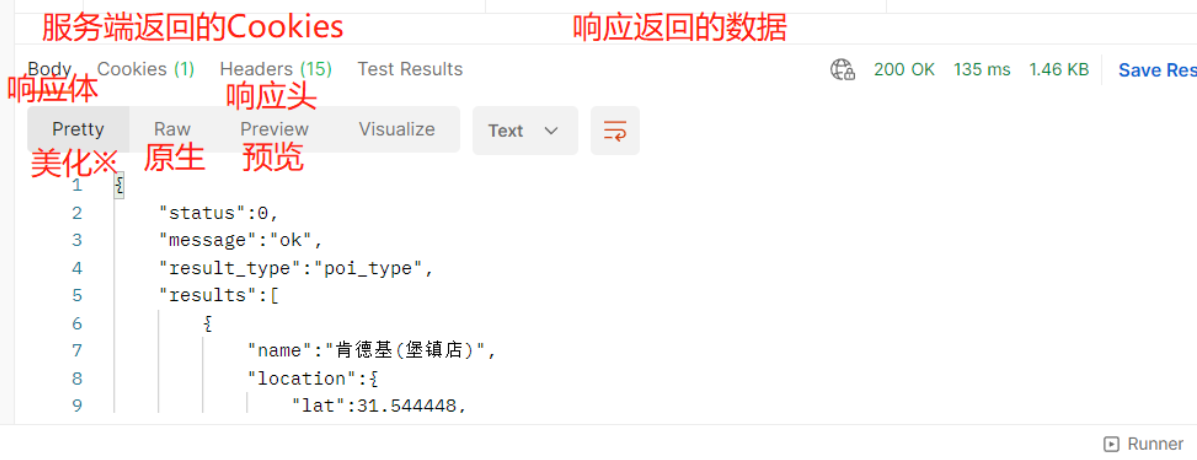
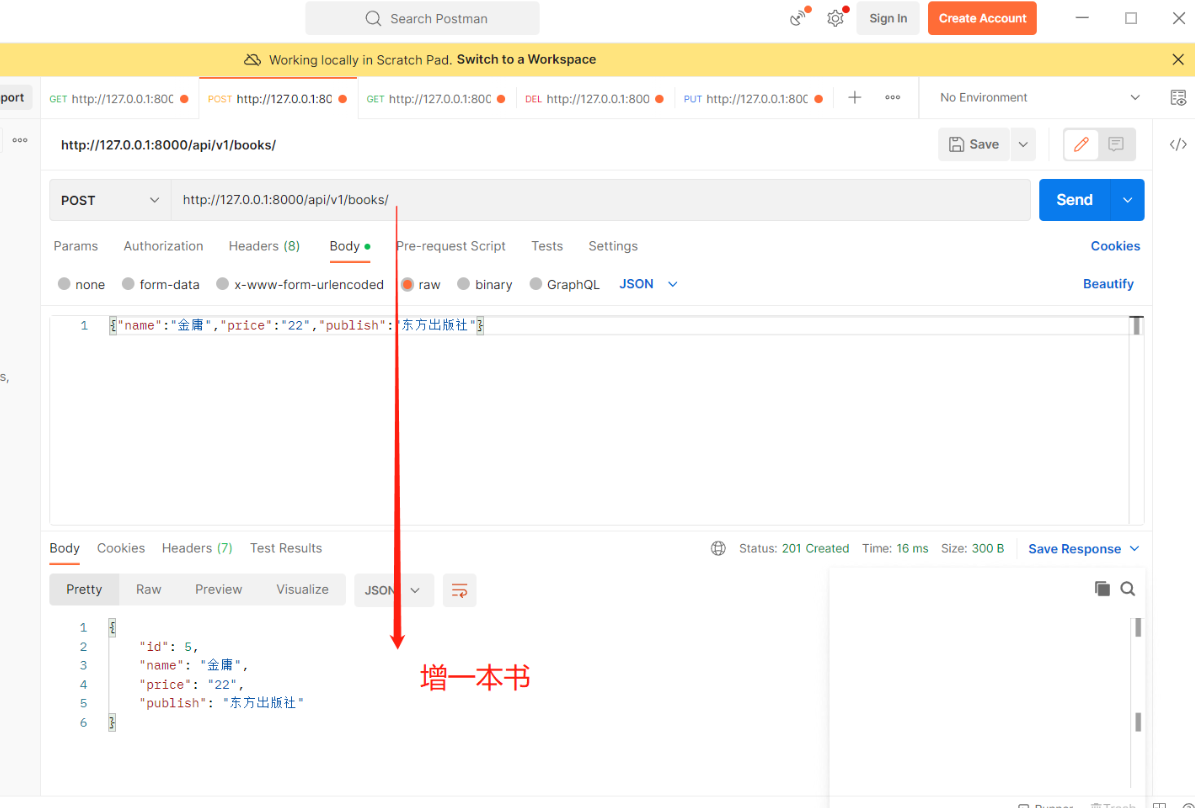
响应返回的操作:
REST全称是Representational State Transfer 表征性状态转移, 首次出现在2000年Roy Fielding的博士论文中 RESTful是一种定义Web API接口的设计风格,尤其适用于前后端分离的应用模式中 ①用https协议保障数据的安全:url链接一般都采用https(http+ssl/tsl)协议进行传输(提高数据交互过程中的安全性) ②接口地址中带api标识: #第一种:在域名前 https://api.zy.com/books #第二种:在路径中 ※常用※ https://www.zy.com/api/books③接口路径中带版本标识: 一开始登录接口只有用户名和密码,后来升级了加了个验证码,此时要保留老接口和新接口防止用户没有升级 # 老版本 https://api.zy.com/v1/login # 新版本 https://www.zy.com/api/v2/login④数据就是资源,在接口地址中均使用名词,尽量不要动词核心 接口一般都是完成前后台数据的交互,交互的数据称为资源。接口形式为: https://api.zy.com/books https://api.zy.com/users 特殊接口可以出现动词,因为这些接口一般没有一个明确的资源,或是动词就是接口的核心含义: https://api.zy.com/login ⑤操作资源由请求方式决定(method):资源操作一般都是增删改查,用请求方式来决定增删改查的动作 # get请求:获取所有书 https://api.baidu.com/books # post请求:新增一本书 https://api.baidu.com/books # get请求:根据主键1查单本书 https://api.baidu.com/books/1 # put请求:根据主键1修改书 https://api.baidu.com/books/1 # delete请求:根据主键1删除书 https://api.baidu.com/books/1⑥在请求url地址中带查询参数[过滤条件]: # 筛选书名是红楼梦且价格是99的书 https://api.baidu.com/books?name=红楼梦&price=99⑦携带响应状态码:成功发送的请求必有响应(可能会没有响应体,但一定有响应状态码) http状态码:http://tools.jb51.net/table/http_status_code 状体码 含义 说明 1XX 请求正在处理中 请求正在处理中 200/201 OK 操作成功,并返回数据 301/302 临时/永久重定向 临时/永久重定向 400 Bad Request 请求语法错误 403 Forbidden 请求没有权限的资源 404 Not Found 没有找到请求的资源 405 Method Not Allowed 请求动词使用错误 500 Internal Server Error 服务器(配置)内部错误一般公司里都是有自己的规范,在响应体中写状态码 {'code':100} ⑧返回的响应体数据中还要带正确/错误信息: ⑨服务器针对不同操作返回不同结果:需符合下列规范 大多公司一般不遵循 可以不按照该规范来 # GET 查询所有:返回资源对象的数组(列表) [{},{}] [{name:红楼梦, price:99}, {name:西游记, price:88}] # GET 查询单条:返回单个资源对象(字典) {} {name:红楼梦, price:99} # POST 新增:返回新增后的资源对象(字典) {} {name:三国演义, price:55} # PUT 修改:返回修改后的资源对象(字典) {} {name:三国演义, price:66} # DELETE 删除:返回一个空文档 返回空⑩响应数据中可带链接地址:在响应中也可以加入链接地址,例如图片资源等 5.序列化反序列化API接口开发最核心且常见的一个过程就是序列化,所谓序列化就是把数据转换格式。 序列化:把我们可以识别的数据转换成指定格式提供给别人我们给别人 在django中获取到的数据默认是模型对象(queryset),模型对象数据无法直接提供给前端,所以需要把模型对象数据进行序列化,变成json格式字符串数据再给前端。 反序列化:把别人提供的数据转换/还原成我们需要的格式别人给我们 前端js传过来的json格式字符串数据,进行反序列化成模型类对象,存到数据库中 从数据库往外出就是序列化(可以理解为read) 往里进就是反序列化(可以理解为write) 6.基于django原生编写5个接口 以后写的接口基本都是5个接口及其变形查所有、查单个、新增一个、修改一个、删除一个 # 基于books单表为例,写5个接口 1.在models.py中创建book表 class Book(models.Model): name = models.CharField(max_length=32) price = models.CharField(max_length=32) publish=models.CharField(max_length=32) 2.表迁移完直接双击db.sqlite3 #省时间这里直接用sqlite.3来做数据库 makemigrations migrate """ 使用pycharm打不开sqlite的问题 用快捷操作双击左侧图标发现没有产生表 -解决: -1 使用navicate打开 -2 使用pycharm正常连接,不要用快捷操作 """ 3.录入数据:随便录两条数据即可 4.写接口 # 遵循restful规范 在views.py中用cbv去写(后期都是cbv) 1)查询所有数据接口: .all()查出来后用JsonResponse序列化(只能序列化字典,如果是列表需要加参数safe=False) 2)新增一个数据接口: request.POST.get()取出前端传入body的数据(只能取form-data和urlencoded格式数据) 如果想取出json格式数据需要在request.body取出然后反序列化成字典再用 3)查询一个数据接口: 根据pk查到对象,序列化后返回给前端 4)修改一个数据接口: put提交的数据不能从request.POST中取,只能json.loads(request.body)解码编程字典,通过get取值获取数据不要忘记用对象.save()保存一下再用JsonResponse返回给前端 5)删除一个数据接口: 用pk直接删除返回一个空字典即可 """ # get请求:获取所有书 https://api.baidu.com/books # post请求:新增一本书 https://api.baidu.com/books # get请求:根据主键1查单本书 https://api.baidu.com/books/1 # put请求:根据主键1修改书 https://api.baidu.com/books/1 # delete请求:根据主键1删除书 https://api.baidu.com/books/1 根据以上规范研究可得需要写两个cbv(url中也要写两个 其中一个带转换器) """ #【models.py】 from django.db import models # 创建模型类(Book表) class Book(models.Model): name = models.CharField(max_length=32) price = models.CharField(max_length=32) publish = models.CharField(max_length=32) —————————————————————————————————————————————————————————————— # 【urls.py】 # cbv中要点一个as_view() path('api/v1/books/', views.BookView.as_view()), path('api/v1/books/', views.BookDetailView.as_view()) ———————————————————————————————————————————————————————————————— # 【views.py】 # 导入表关系 from .models import Book # 导入View(写cbv都要继承View) from django.views import View # 导入序列化模块 from django.http import JsonResponse import json class BookView(View): # 1.查询所有图书数据 def get(self, request): print(request) books = Book.objects.all() # queryset[数据对象,数据对象..] # 先把queryset转成列表,再使用JsonResponse序列化返回给前端 book_list = [] for i in books: book_list.append({'name': i.name, 'price': i.price, 'publish': i.publish}) # JsonResponse主要序列化字典,针对非字典的需要把safe参数改为False,json_dumps_params参数可让中文不编码 return JsonResponse(book_list, safe=False, json_dumps_params={'ensure_ascii': False}) # 2.新增一本图书数据 # 在Postman中POST请求里只能用form-data和x—www-form-urlencoded传数据 不能用json # 因为json格式编码提交的数据不能从request.POST中取 都是None,只能从request.body中取 def post(self, request): # 取出前端传入的数据 name = request.POST.get('name') price = request.POST.get('price') publish = request.POST.get('publish') # 把取出来的数据存到数据库中 book_obj = Book.objects.create(name=name, price=price, publish=publish) # 返回新增的对象字典 return JsonResponse( {'name': book_obj.name, 'price': book_obj.price, 'publish': book_obj.publish}) class BookDetailView(View): # 3.查询一本图书数据 def get(self, request, pk): book = Book.objects.filter(pk=pk).first() # 把book的模型类对象转成字典,再用JsonResponse序列化返回给前端 return JsonResponse({'id': book.pk, 'name': book.name, 'price': book.price, 'publish': book.publish}) # 4.修改一本图书数据 # request.POST只能取POST提交的form-data和x—www-form-urlencoded两种编码格式中的数据 def put(self, request, pk): # 查到要修改的图书对象 book = Book.objects.filter(pk=pk).first() # 取出前端要传入修改的数据(以下方法需优化判断如果用户没传就是None 不修改),修改完再保存 # book.name = request.POST.get('name') # book.price = request.POST.get('price') # book.publish = request.POST.get('publish') # book.save() # 上述代码出错的原因是request.POST获取不到put请求的数据 # 前端用json格式提交要修改的数据 自己保存 book_dict = json.loads(request.body) # print(book_dict) # {'name': '如何称为富婆', 'price': 10, 'publish': '上海出版社'} book.name = book_dict.get('name') book.price = book_dict.get('price') book.publish = book_dict.get('publish') book.save() return JsonResponse({'id': book.pk, 'name': book.name, 'price': book.price, 'publish': book.publish}) # 5.删除一本图书数据 def delete(self, request, pk): book = Book.objects.filter(pk=pk).delete() # data必须要给个数据 所以给一个空字典 return JsonResponse(data={}) 7.drf下载与快速使用drf全称:django rest framework 是一个建立在Django基础之上的Web应用开发框架,用drf可方便快速写出符合restful规范的接口 # 一般django都用最新版的上一个版本 # 注意:drf最新版支持到django3.x,不支持2.x(django2.x可以用最新版drf 只是安装时可能会有小问题) # 下载drf会自动把django更新到最新版本,但是django我们一般不用最新版所以下载完drf再下载一下原版本的django即可 pip3 install djangorestframework -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com/simple/快速使用 # 用drf快速编写5个接口(目前仅作了解) #【models.py】 from django.db import models # 创建模型类(Book表) class Book(models.Model): name = models.CharField(max_length=32) price = models.CharField(max_length=32) publish = models.CharField(max_length=32) —————————————————————————————————————————————————————————————— #【urls.py】 # 用drf写5个接口 from rest_framework.routers import SimpleRouter router = SimpleRouter() # 这里的路径不需要加/ 会自动加 router.register('api/v1/books', views.BookView, 'books') # 再起一个别名也叫books urlpatterns = [ path('admin/', admin.site.urls), ] # 让两个列表相加(会将自动生成的路由加到urlpatterns列表中) urlpatterns += router.urls —————————————————————————————————————————————————————————————— # app01下新建文件【serializer.py】 # 继承serializers中的ModelSerializer from rest_framework import serializers # 导入表关系 from .models import Book class BookSerializer(serializers.ModelSerializer): class Meta: model = Book fields = '__all__' —————————————————————————————————————————————————————————————— # 【views.py】 # 不再继承View而是ModelViewSet from rest_framework.viewsets import ModelViewSet # 导入表关系 from .models import Book # 导入新建的序列化类 from .serializer import BookSerializer # 用drf快速编写5个接口 class BookView(ModelViewSet): queryset = Book.objects.all() serializer_class = BookSerializer
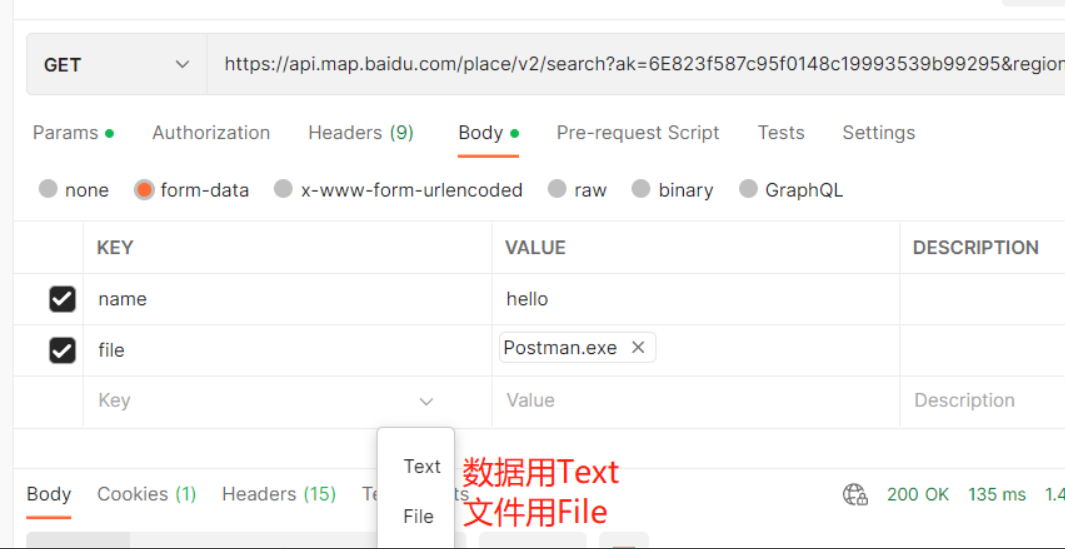
此处form-data、x-www-form-urlencoded、json三种都可以传数据:
此处form-data、x-www-form-urlencoded、json三种都可以传数据:
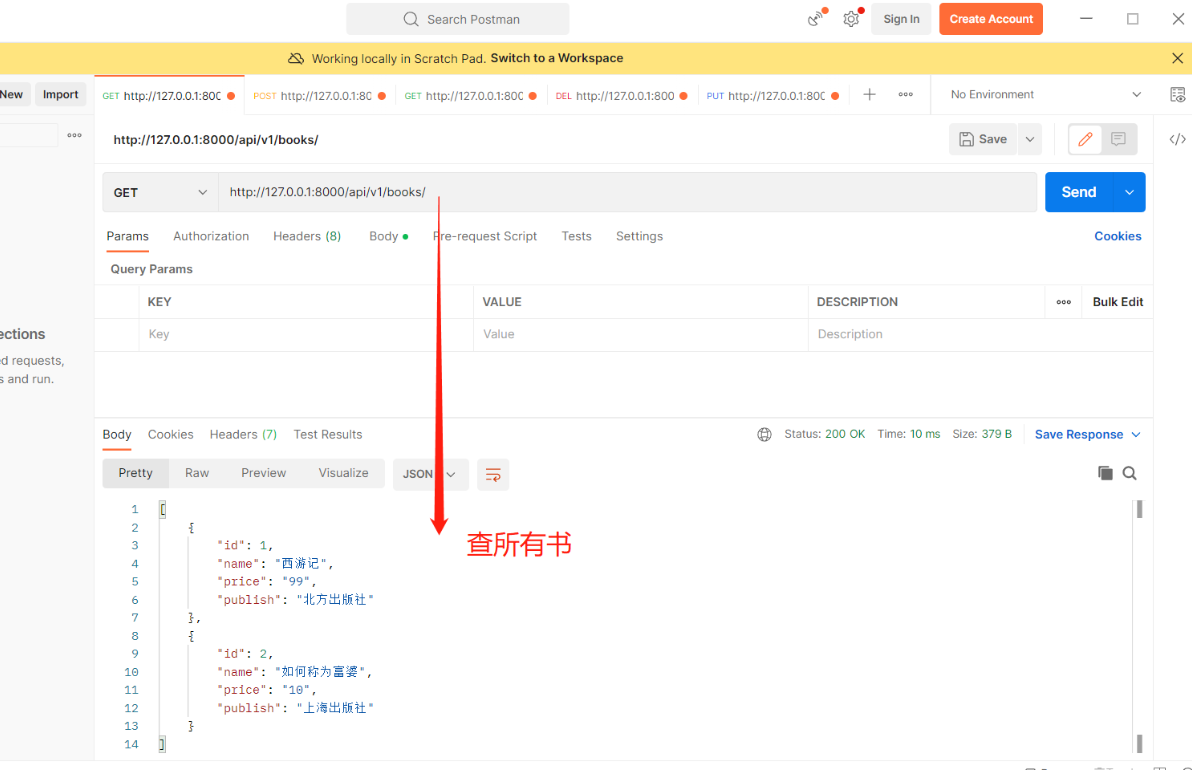
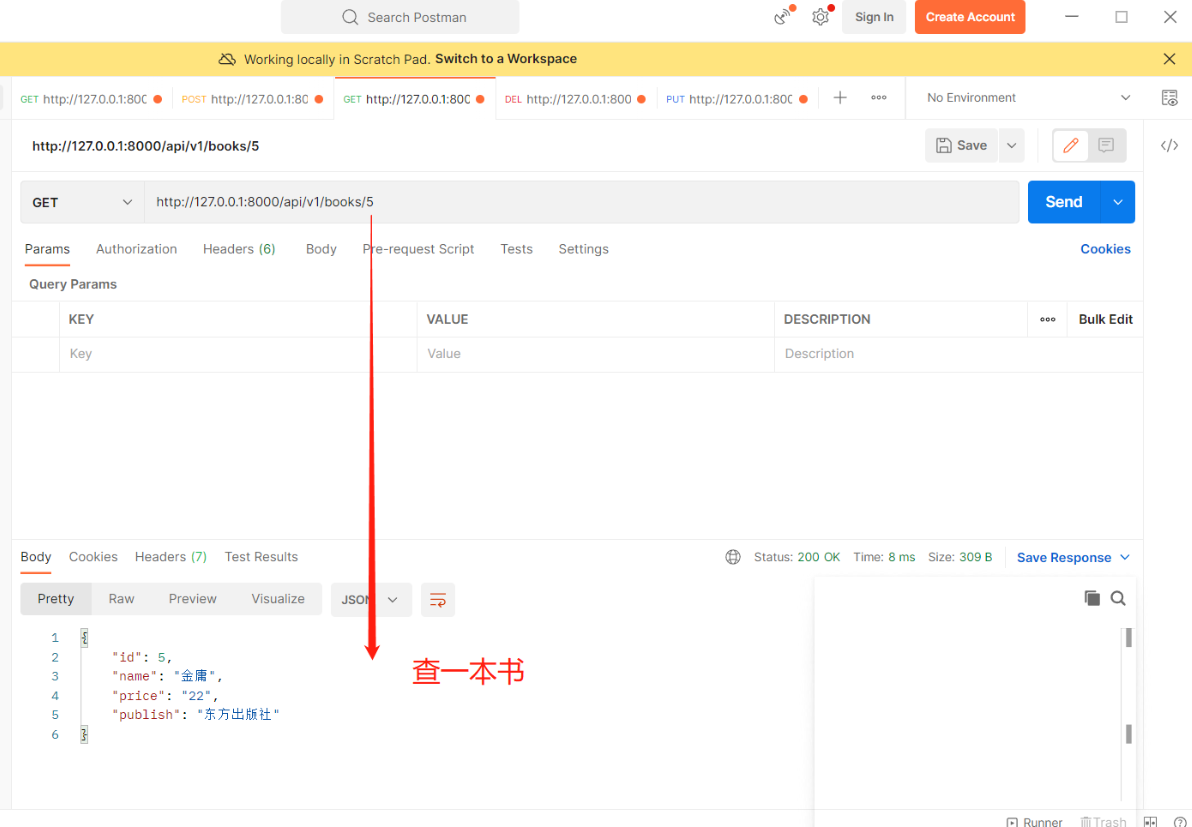
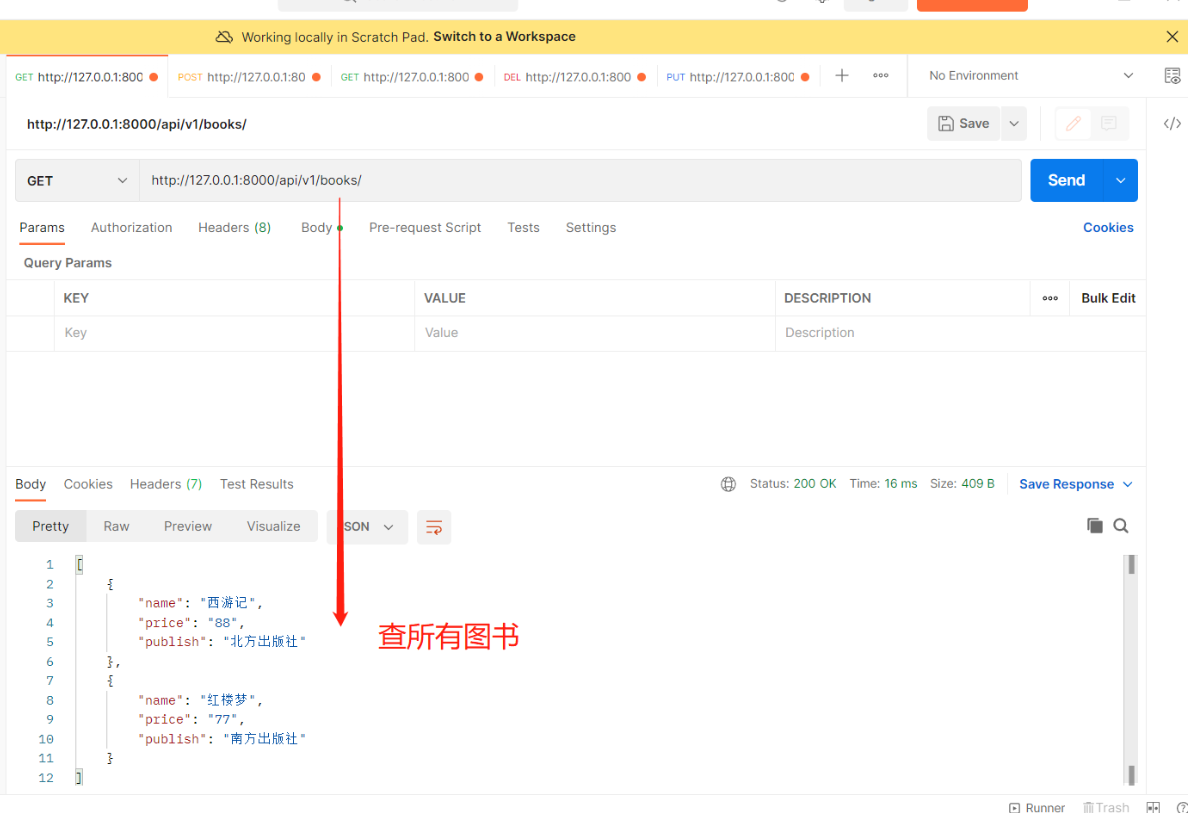
举一个接口例子即可:查询所有图书 # 【views.py】 # 导入APIView from rest_framework.views import APIView # 导入Book表 from .models import Book # 导入JsonResponse序列化模块 from django.http import JsonResponse # 基于APIView+JsonResponse编写接口 class BookView(APIView): # 查询所有图书数据 def get(self, request): books = Book.objects.all() # 结果是queryset[数据对象,数据对象..] # 先把queryset转成列表 再使用JsonResponse序列化返回给前端 book_list = [] for i in books: book_list.append({'name': i.name, 'price': i.price, 'publish': i.publish}) # JsonResponse主要是序列化字典的,其他类型需加参数safe=False return JsonResponse(book_list, safe=False) —————————————————————————————————————— # 【urls.py】 from app01 import views path('api/v1/books/', views.BookView.as_view()),
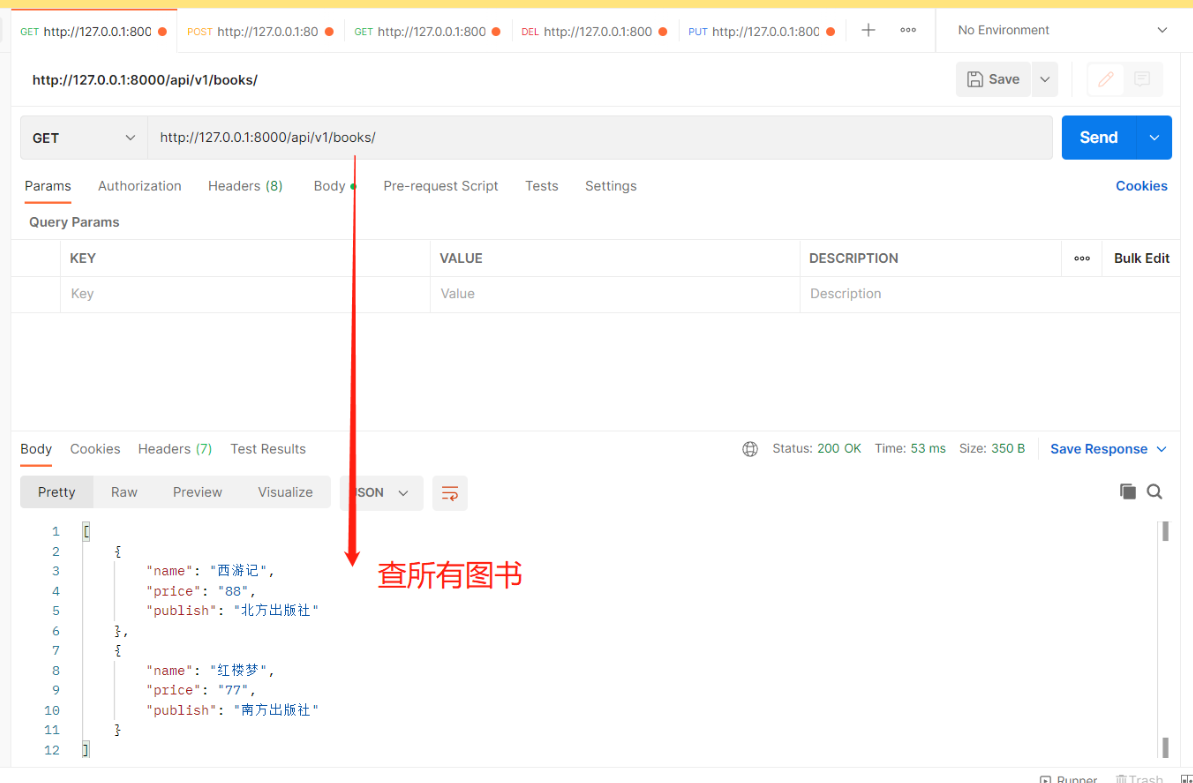
举一个接口例子即可:查询所有图书 # 【views.py】 # 导入APIView from rest_framework.views import APIView # 导入Book表 from .models import Book # 导入Response模块 from rest_framework.response import Response # 基于APIView+Response编写接口 class BookView(APIView): # 查询所有图书数据 def get(self, request): books = Book.objects.all() # 结果是queryset[数据对象,数据对象..] # 先把queryset转成列表 再使用Response序列化返回给前端 book_list = [] for i in books: book_list.append({'name': i.name, 'price': i.price, 'publish': i.publish}) # Response:无论列表还是字典都可以序列化 return Response(book_list) —————————————————————————————————————— # 【urls.py】 from app01 import views path('api/v1/books/', views.BookView.as_view()),
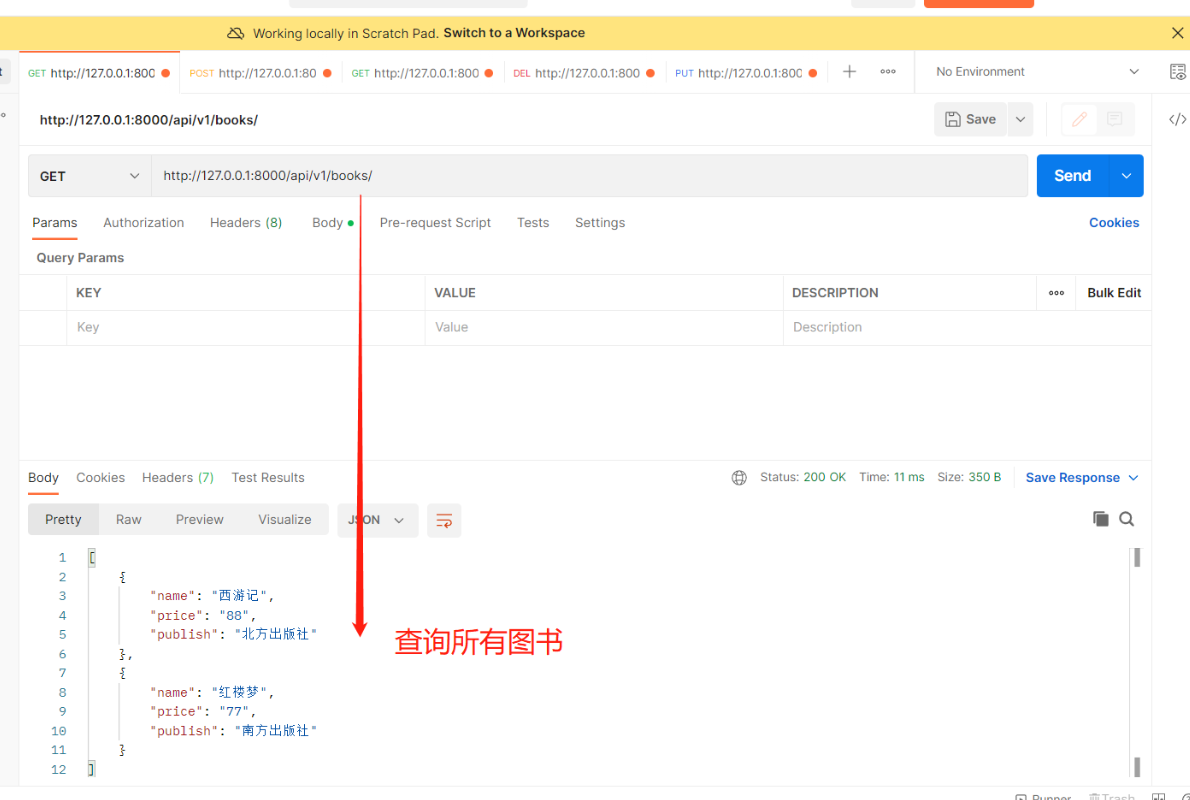
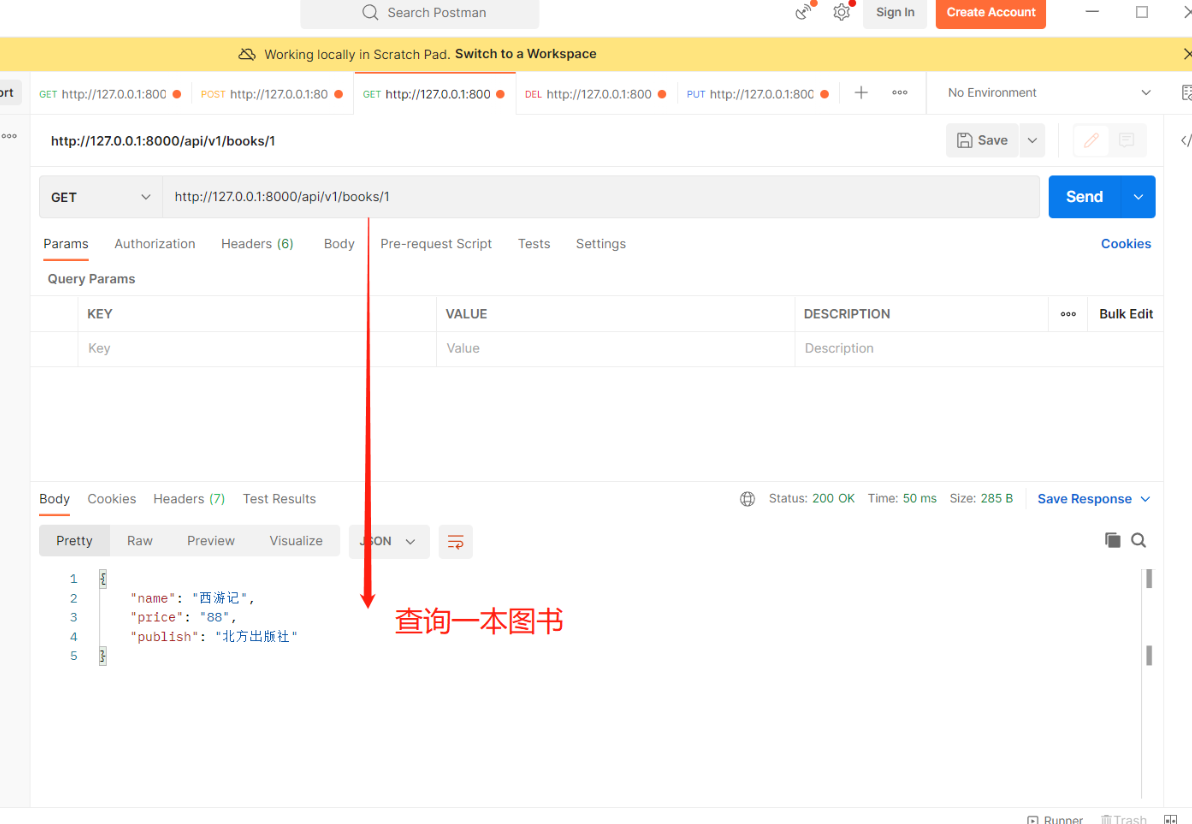
前后端通常使用json数据格式交互,在后端当我们想把一个对象返回给前端时发现json不能序列化对象,所以就有了序列化组件。通过自定义特定结构可以将对象返回给前端,同时还能对前端传入的数据进行数据校验等功能,其实就是【序列化】【反序列化】【反序列化的过程中做数据校验】 序列化组件是drf提供的类,自己写一个类然后继承该序列化类,使用其中某些方法即可完成上面的三种操作 drf提供了两个类:Serializer和ModelSerializer 基于APIView+Response+serializers编写接口 2.序列化类 单表时数据准备 1.在【models.py】中创建book表 class Book(models.Model): name = models.CharField(max_length=32) price = models.CharField(max_length=32) publish = models.CharField(max_length=32) 2.表迁移完直接双击db.sqlite3 #省时间这里直接用sqlite.3来做数据库 makemigrations migrate 3.录入数据:随便录两条数据即可首先需要定义一个序列化类! 继承Serializer或ModelSerializer类,写一个个字段,该字段表示要序列化和反序列化的字段 # 在app01中新建【serializer.py】 # 导入序列化类 from rest_framework import serializers # 里面还有一个ModelSerializer类 # 编写一个类继承序列化类 class BookSerializer(serializers.Serializer): # 要序列化/反序列化的字段 一般是和models下的类对应 name = serializers.CharField() price = serializers.CharField() publish = serializers.CharField() 1)序列化多条(查询所有书) #【views.py】 # 导入APIView from rest_framework.views import APIView # 导入Book表 from .models import Book # 导入Response模块 from rest_framework.response import Response # 导入刚刚编写的继承序列化类的类 from .serializer import BookSerializer class BookView(APIView): # 查询所有图书数据 def get(self, request): books = Book.objects.all() # 结果是queryset[数据对象,数据对象..] # instance 要序列化的数据books # many=True 只要是queryset对象就要加该参数,如果是单个对象则不用 ser = BookSerializer(instance=books, many=True) # Response:无论列表还是字典都可以序列化 data就是把指定的那些字段去转成字典或列表 return Response(ser.data) ———————————————————————————————————————— #【urls.py】 path('api/v1/books/', views.BookView.as_view()),
用了request.data就不用管前端的编码方式是什么 三种都可以传
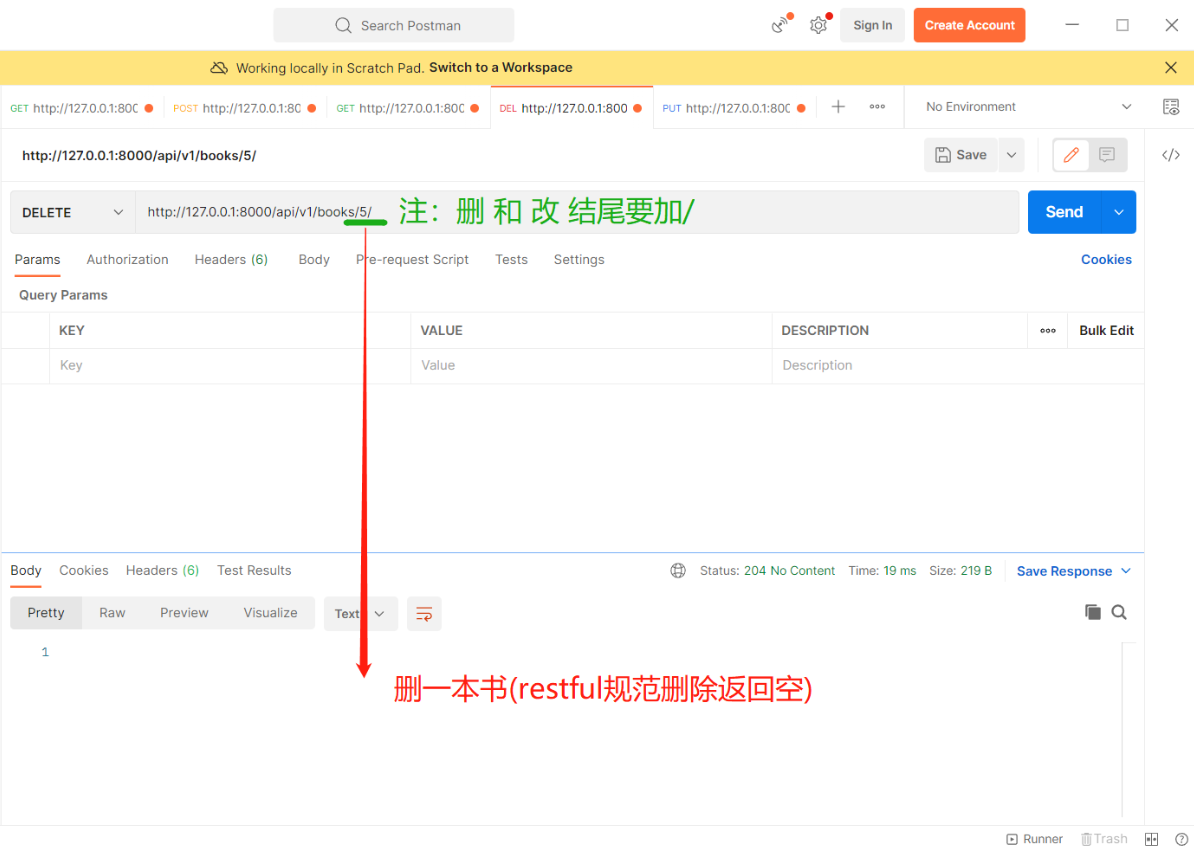
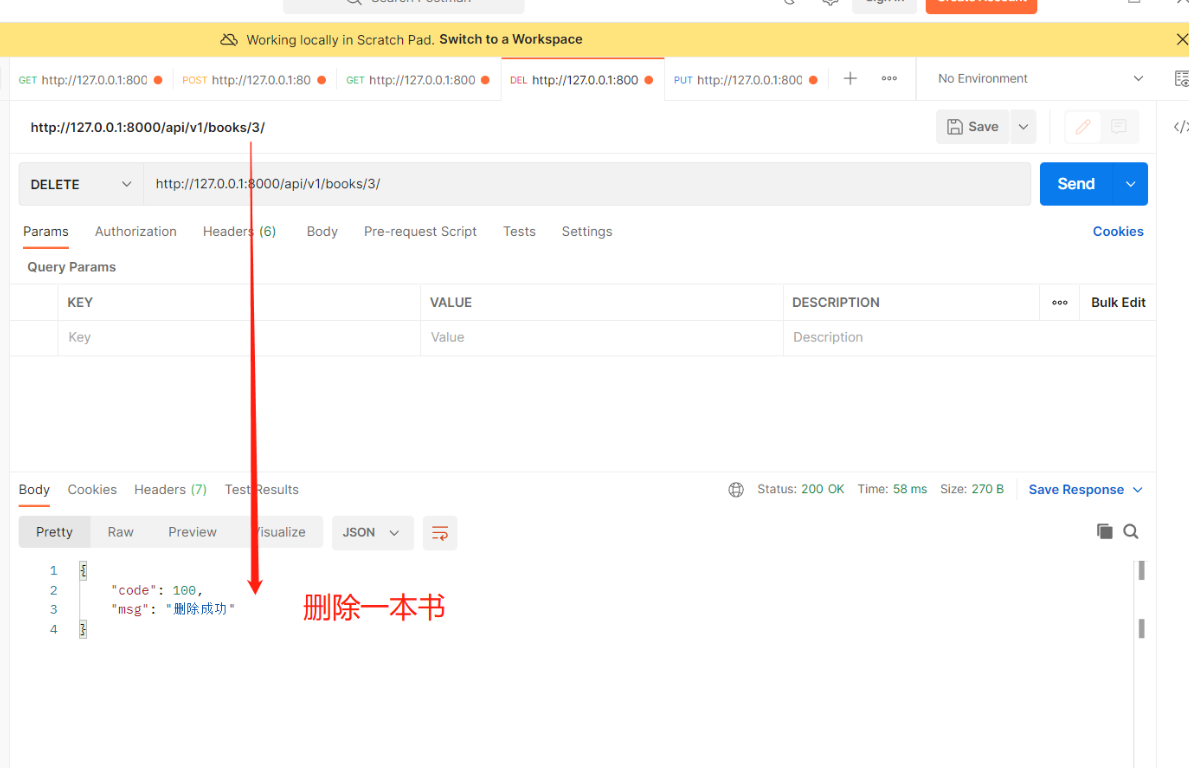
和序列化没关系 直接写即可 #【views.py】 # 导入APIView from rest_framework.views import APIView # 导入Book表 from .models import Book # 导入Response模块 from rest_framework.response import Response class BookDetailView(APIView): # 删除一本图书数据 def delete(self, request, pk): Book.objects.filter(pk=pk).delete() return Response({'code': 100, 'msg': '删除成功'})
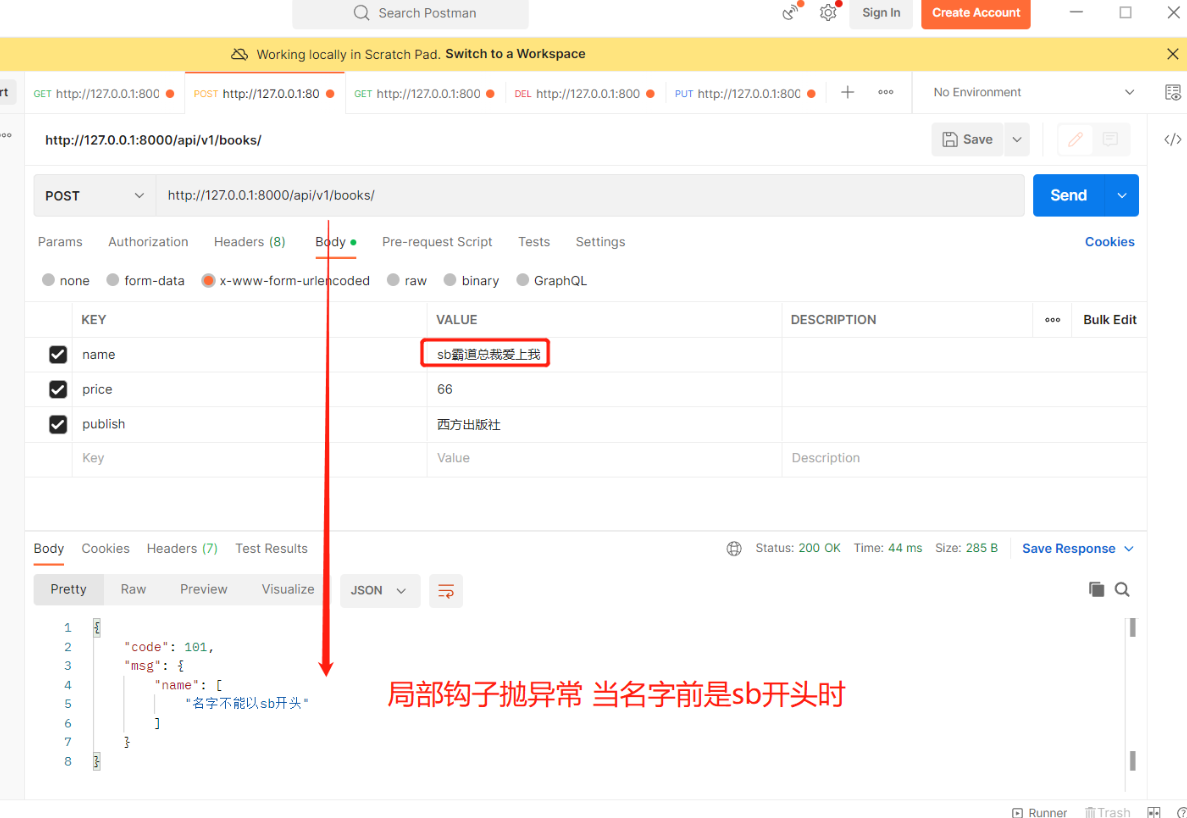
局部钩子:要求name前不能是sb开头 # 局部钩子: def validate_name(self,name): # 校验name是否合法 startswith()校验字符串开头是否为某个值 if name.startswith('sb'): # 校验不通过,主动抛异常 raise ValidationError('名字不能以sb开头') else: return name
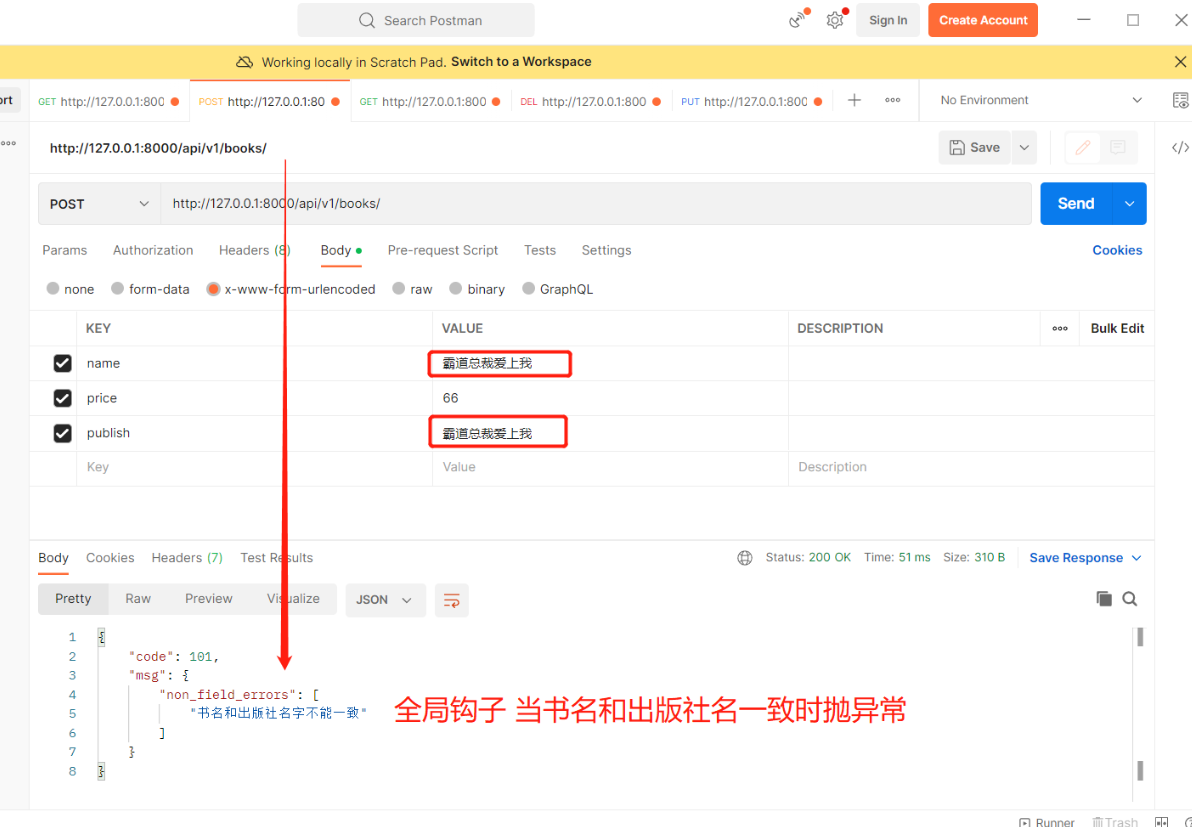
全局钩子:要求书名跟出版社名字不能一致 # 全局钩子 def validate(self, attrs): # attrs 校验后的数据 if attrs.get('name') == attrs.get('publish'): # 校验不通过,主动抛异常 raise ValidationError('书名和出版社名字不能一致') else: return attrs
选项参数:CharField及其子类都有的参数(如EmailField等)、IntegerField字段上的参数 参数名称 说明 max_length 最大长度 min_lenght 最小长度 allow_blank 是否允许为空 trim_whitespace 是否截断空白字符 max_value 最大值 min_value 最小值通用参数,放在哪个字段类上都可以: 参数名称 说明 ※ read_only 表明该字段仅用于序列化输出,默认False ※ write_only 表明该字段仅用于反序列化输入,默认False ※ required 表明该字段在反序列化时必须输入,默认True(可传可不传) ※ default 反序列化时如果没填自动使用默认值 ※ allow_null 表明该字段是否允许为空,默认False validators 单独再给该字段加额外校验规则(提前写个函数) error_messages 包含错误编号与错误信息的字典 label 用于HTML展示API页面时,显示的字段名称 help_text 用于HTML展示API页面时,显示的字段帮助提示信息 7.序列化高级用法之source(了解) 多表时数据准备 1)查询所有图书接口 1.在【models.py】中创建表Book、Author、Publish from django.db import models # 图书与作者表:多对多,需建立中间表但是可以用ManyToManyField字段自动生成,关联字段在查询多的一方(书) # 一对多还需要加级联删除on_delete=models.CASCADE # 图书与出版社:一对多,一个出版社对应多本书,关联字段在多(书)中 class Book(models.Model): name = models.CharField(max_length=32) price = models.CharField(max_length=32) authors = models.ManyToManyField(to='Author') # 多对多 publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE) # 一对多 class Author(models.Model): name = models.CharField(max_length=32) phone = models.CharField(max_length=11) class Publish(models.Model): name = models.CharField(max_length=32) addr = models.CharField(max_length=32) 2.表迁移完直接双击db.sqlite3 #省时间这里直接用sqlite.3来做数据库 makemigrations migrate 3.录入数据:随便录两条数据即可以查询所有图书接口为例: #app01中新建【serializer.py】写序列化类 # 导入序列化类 from rest_framework import serializers class BookSerializer(serializers.Serializer): # 需要序列化/反序列化的字段 不做反序列化校验里面可以不用写校验参数 name = serializers.CharField() price = serializers.CharField() #【views.py】 # 导入APIView from rest_framework.views import APIView # 导入三张表 from .models import Book, Author, Publish # 导入自己写的序列化类 from .serializer import BookSerializer # 导入Response模块 from rest_framework.response import Response class BookView(APIView): # 查询所有图书数据 def get(self, request): books = Book.objects.all() # 结果是queryset[数据对象,数据对象..] # instance:要序列化的数据books # many=True:多个对象就加 单个对象就不写 ser = BookSerializer(instance=books, many=True) # ser.data:把指定的字段去转成字典或列表 # Response:无论列表还是字典都可以序列化 return Response(ser.data)
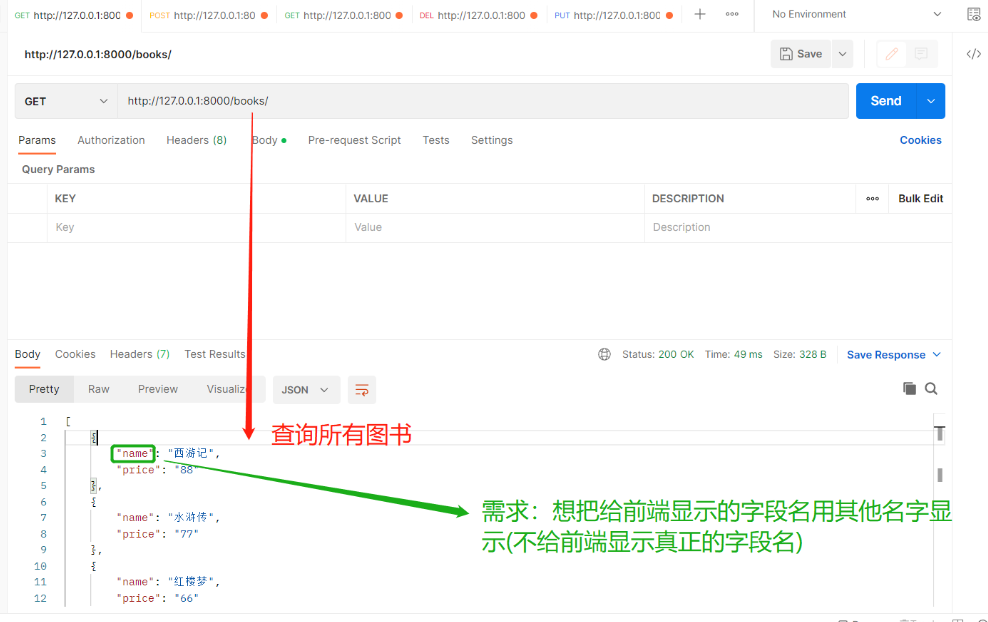
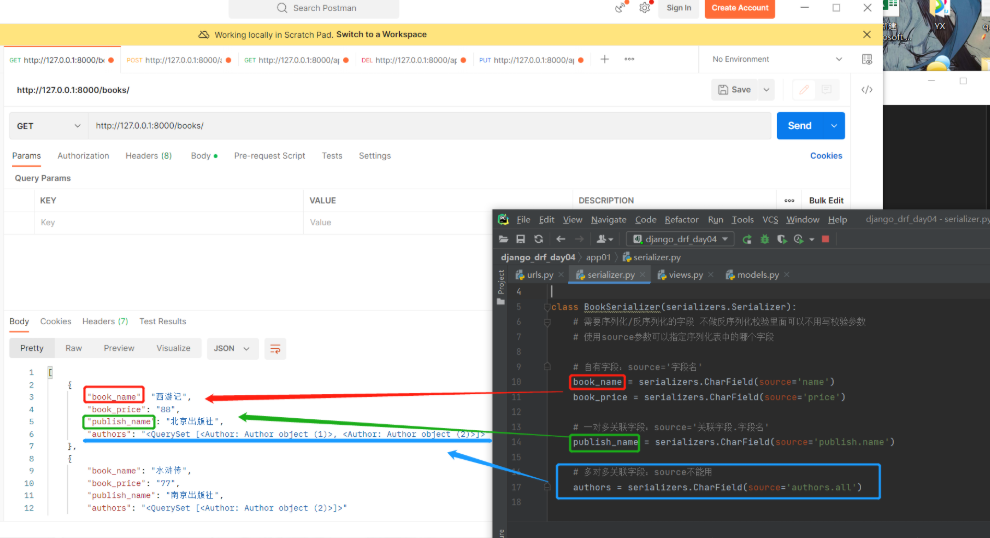
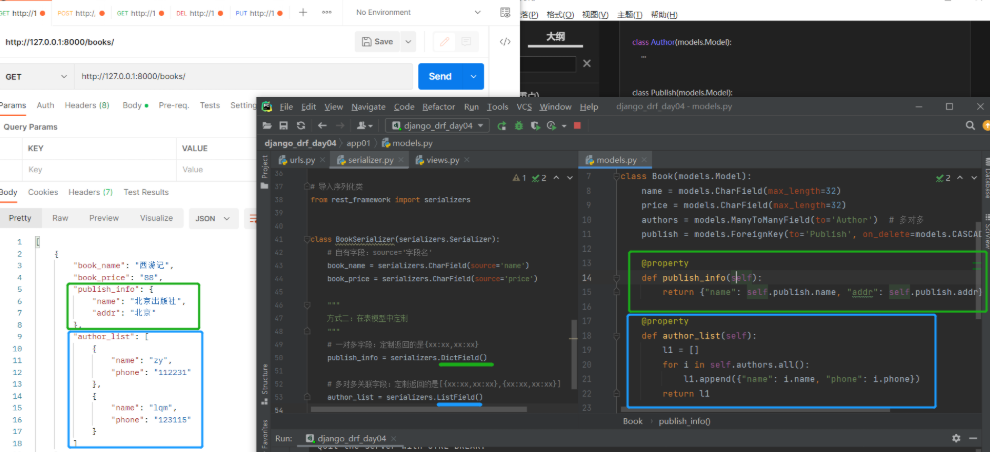
现有一个需求:给前端显示我真实字段名太危险,我想给他显示一个其他字段名,这就需要用到定制序列化字段名 定制序列化的字段名字(改名字不和数据库中的名字对应)使用source参数可以指定序列化表中的哪个字段注:两边的名字不能一样会报错 name = serializers.CharField(source='name')报错 多对多关联字段不能用 因为显示不出来 #【serializer.py】 # 导入序列化类 from rest_framework import serializers class BookSerializer(serializers.Serializer): # 需要序列化/反序列化的字段 不做反序列化校验里面可以不用写校验参数 # 使用source参数可以指定序列化表中的哪个字段 # 自有字段:source='字段名' book_name = serializers.CharField(source='name') book_price = serializers.CharField(source='price') # 一对多关联字段:source='关联字段.字段名' publish_name = serializers.CharField(source='publish.name') # 多对多关联字段:source无法实现 authors = serializers.CharField(source='authors.all')
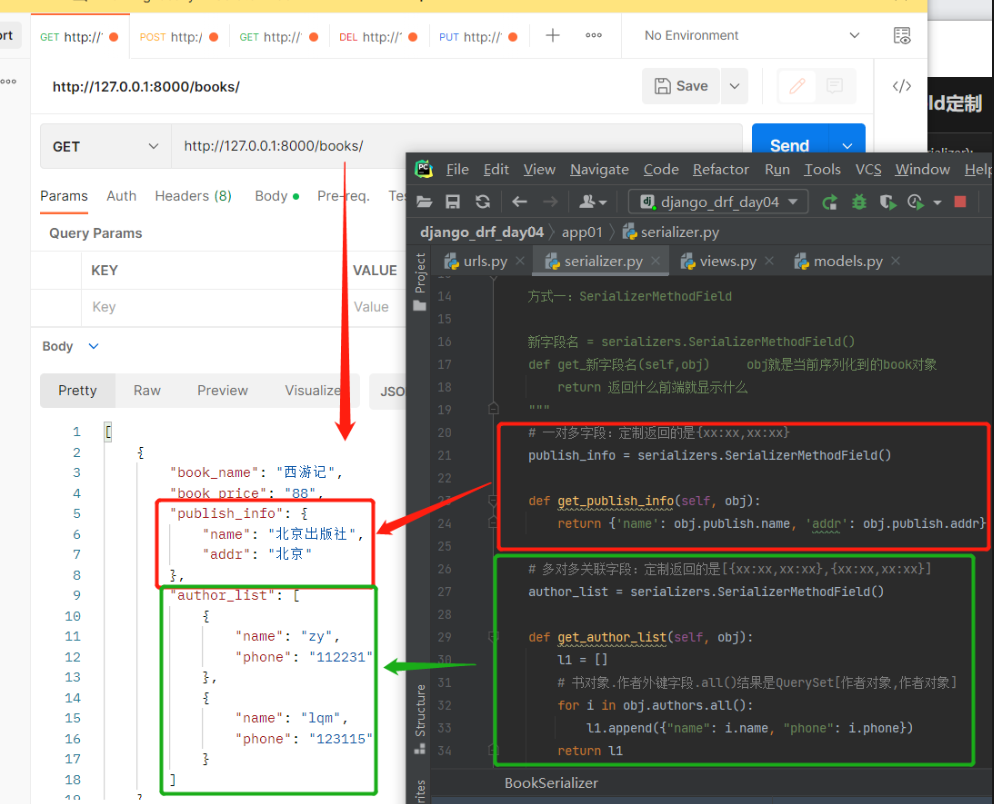
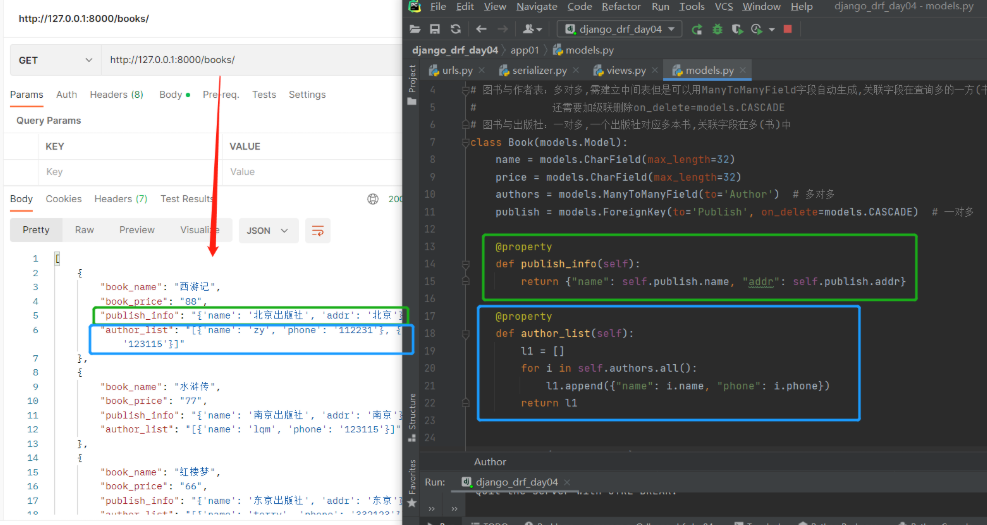
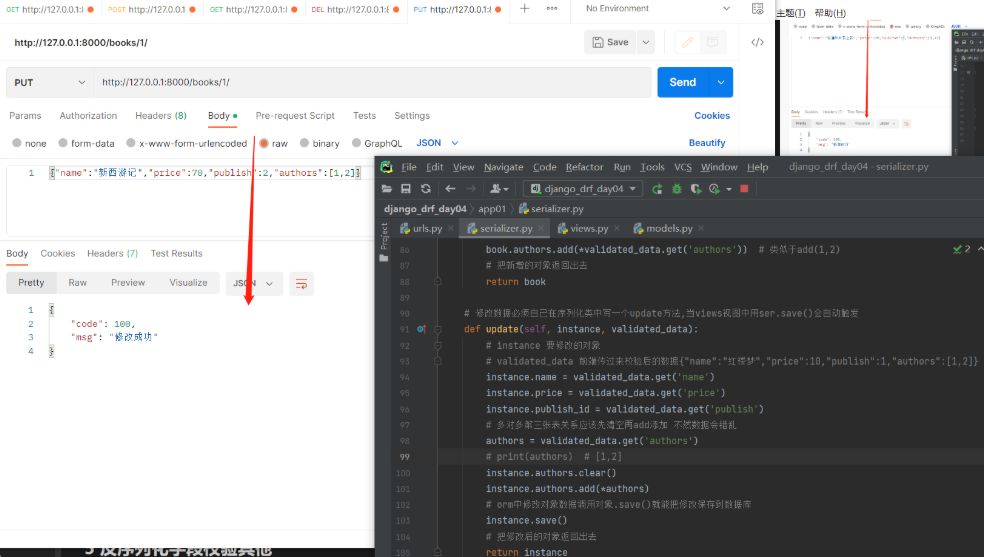
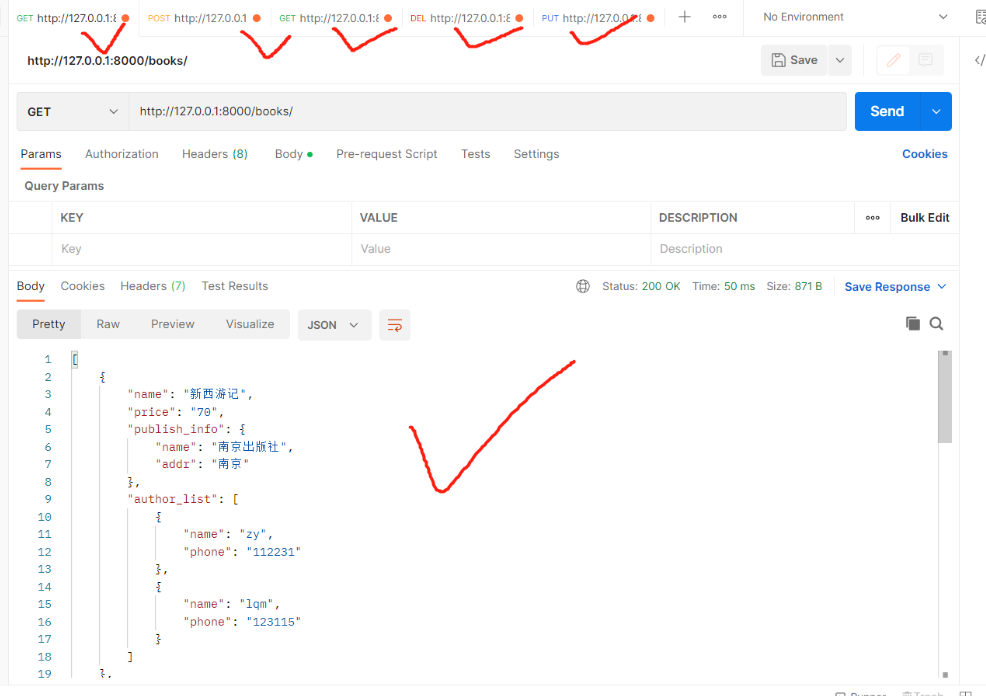
现需求升级了要求在前端页面显示如下样式: 自有字段正常显示,一对多显示字典,多对多显示列表套字典 { "book_name": "西游记", "book_price": "88", "publish_info": {"name": "北京出版社"",addr": "北京"}, "author_list": [{"name": "torry"",phone": "110"},{"name": "jarry","phone": "119"}] }以下两种方法均可实现 建议都掌握 1)在SerializerMethodField定制 该字段以后就不能用来做反序列化 # 方式一:SerializerMethodField 新字段名 = serializers.SerializerMethodField() def get_新字段名(self,obj) # obj就是当前序列化到的book对象 return 返回什么前端就显示什么 #【serializer.py】 class BookSerializer(serializers.Serializer): # 需要序列化/反序列化的字段 不做反序列化校验里面可以不用写校验参数 # 使用source参数可以指定序列化表中的哪个字段 # 自有字段:source='字段名' book_name = serializers.CharField(source='name') book_price = serializers.CharField(source='price') # 一对多字段:定制返回的是{xx:xx,xx:xx} publish_info = serializers.SerializerMethodField() def get_publish_info(self, obj): return {'name': obj.publish.name, 'addr': obj.publish.addr} # 多对多关联字段:定制返回的是[{xx:xx,xx:xx},{xx:xx,xx:xx}] author_list = serializers.SerializerMethodField() def get_author_list(self, obj): l1 = [] # 书对象.作者外键字段.all()结果是QuerySet[作者对象,作者对象] for i in obj.authors.all(): l1.append({"name": i.name, "phone": i.phone}) return l1
此时仔细看前端页面上的字典和列表套字典变成了字符串!!! 序列化类中不能用CharField()接收 应该用DictField() 或 ListField()接收!
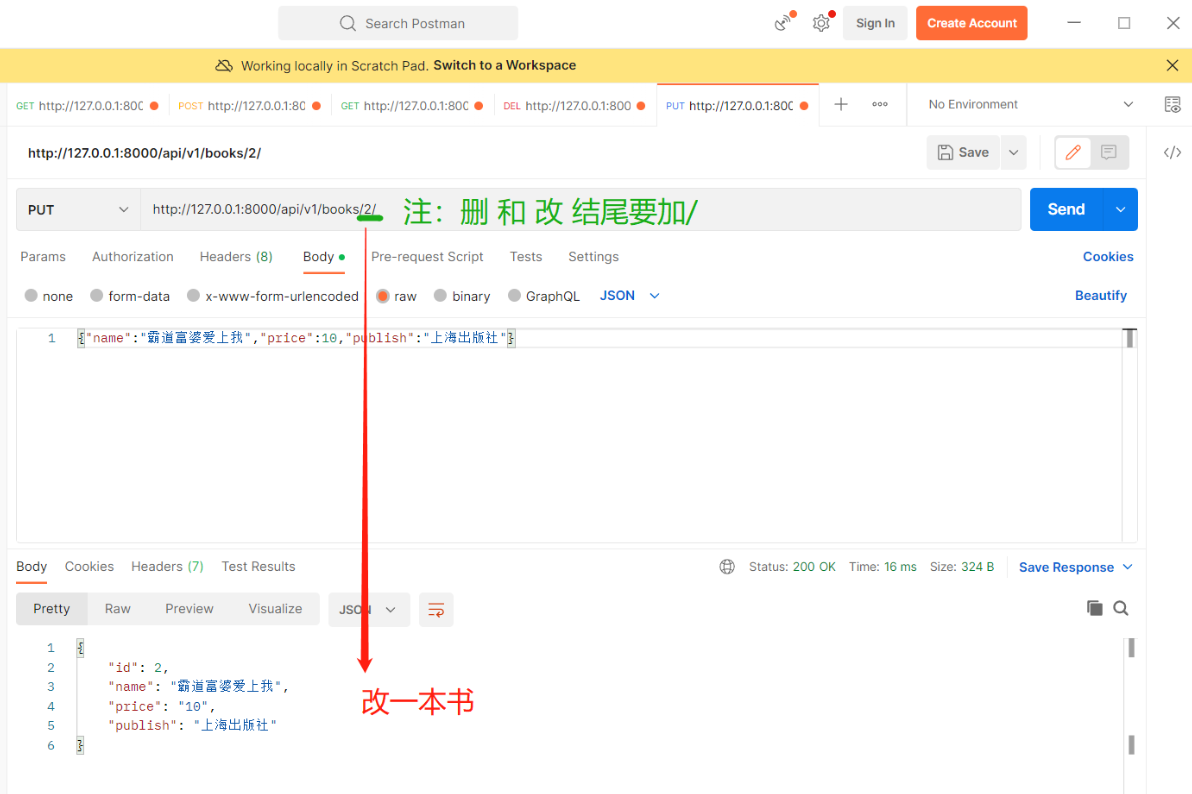
ModelSerializer继承了Serializer它可以帮我们完成很多额外操作: 跟模型强关联,instance关联了要修改的对象,字段名如果一样都可以序列化,用了该序列化类就不能随便序列化了 大部门情况下可以不用写create和update如何使用 1.serializer.py中定义一个类继承ModelSerializer 2.在该类中写'Class Meta:' 3.在Meta内部写'model=要序列化的表' 4.在Meta内部写'fields=要序列化的字段' #fields='__all__' 表示序列化所有(但不包含方法) 把所有字段映射到序列化类中就相当于把models中的字段在序列化类中又重写了一遍类似第6点的操作,只是没显示 #但是需注意:如果是映射过来的,也会把字段本身的规则一起映射过来,可能会导致写入校验失败。如果不想用映射过来的规则则需要自己真正重写一下字段选择不加规则或加自己的规则 类似第6点的操作 ----一般不用序列化所有 而是用指定字段---- #fields=['字段','字段','方法','方法'] 表示指定的字段和方法(此处需把【序列化字段】和前端传来的【反序列化字段】都写进来) 5.在Meta内部写'extra_kwargs={}'可以给字段类 定制反序列化时的属性限制,当反序列化时就会应用该属性 # 并给两个字段限制 只读(序列化) 和 只写(反序列化) 如: extra_kwargs = {'name': {'max_length': 8}, 'publish_info': {'read_only': True}, 'author_list': {'read_only': True}, 'publish': {'write_only': True}, 'authors': {'write_only': True}, } 6.在该序列化类中还可以重写某个字段,这样会优先用你重写的字段 # (可不写) class BookSerializer(serializers.ModelSerializer): class Meta: ... # 重写name字段并定制反序列化时长度不能超过4 name=serializers.CharField(max_length=4) ———————————————————————————————————— 7.用了ModelSerializer后就可以不用在序列化类中写create和update方法了,已经帮我们写好了,兼容性更好 #但是需要注意如果前端传来的是两个表中的数据 第一张表里没有第二章表里的字段则需要手动写create、update方法 8.反序列化的字段一定和表模型字段一一对应吗? 不一定, 9.序列化的字段一定和表模型的字段一一对应吗? 不一定,
此时发现我们的查、增、改都可以实现!
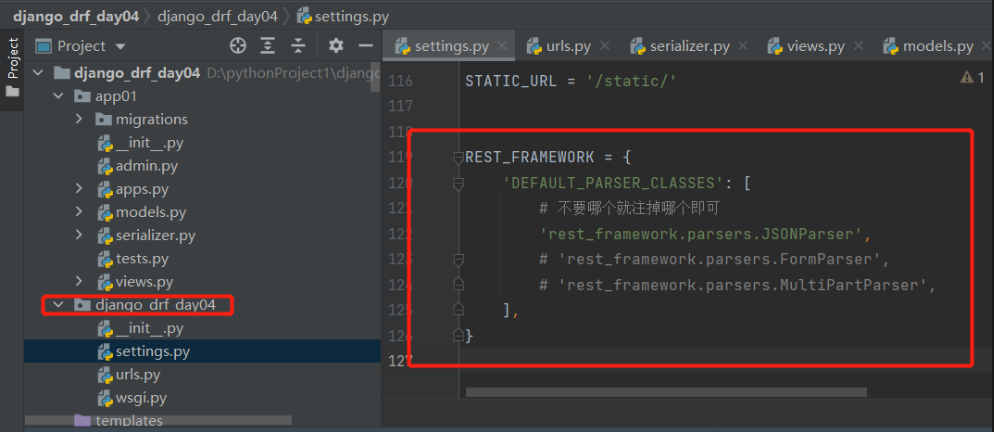
框架中的源码会大量使用断言!!! 断定结果是True,是就正常往下执行,不是就报错 assert name='张三' assert name=='张三' # 断定name是'张三' print('是则往下执行,不是就报错') —————————————————— name='张三' assert isinstance(name,str) # 断定name是字符串 print('是则往下执行,不是就报错') 三.drf的请求与响应 1.请求 1)Request类能解析的请求编码格式 # 导入APIView from rest_framework.views import APIView # 导入Response模块 from rest_framework.response import Response class BookView(APIView): # 新增一本图书接口 def post(self,request): # 前端提交过来的数据从request.data中取出 """ 如果是json格式编码,request.data就是普通dict字典 print(request.data) # {'name': '三国演义', 'price': 20} print(type(request.data)) # —————————————————————————— 如果是urlencoded、form-data编码格式,request.data就是django.http.request.QueryDict print(request.data) # print(type(request.data)) # """ return Response({'code': 100, 'msg': '新增成功'}) Request类能解析的请求编码格式: json、urlencoded、form-data需求:现在要求该接口只能接收json编码格式不能接收其他两种编码格式 方法一:(局部配置)在views.py视图类中用参数parser_classes=[ ]限制可以解析的请求编码格式 请求默认共有三个解析类: from rest_framework.parsers import JSONParser,FormParser,MultiPartParserJSONParser就是json编码格式 FormParser就是urlencoded编码格式 MultiPartParser就是form-data编码格式 # 导入APIView from rest_framework.views import APIView # 导入Response模块 from rest_framework.response import Response # 导入解析类 from rest_framework.parsers import JSONParser, FormParser, MultiPartParser class BookView(APIView): # 限制该接口只能接收json编码格式 parser_classes = [JSONParser] # 新增一本图书接口 def post(self, request): ... return Response({'code': 100, 'msg': '新增成功'})方法二:(全局配置)在配置文件中配置 一般不用django有个默认配置文件,每个项目也有配置文件 drf也有个默认配置文件,每个项目也有个配置文件 在drf项目配置文件中写下列代码 REST_FRAMEWORK = { 'DEFAULT_PARSER_CLASSES': [ # 限制不要哪个编码格式就注释掉 'rest_framework.parsers.JSONParser', 'rest_framework.parsers.FormParser', 'rest_framework.parsers.MultiPartParser', ], }
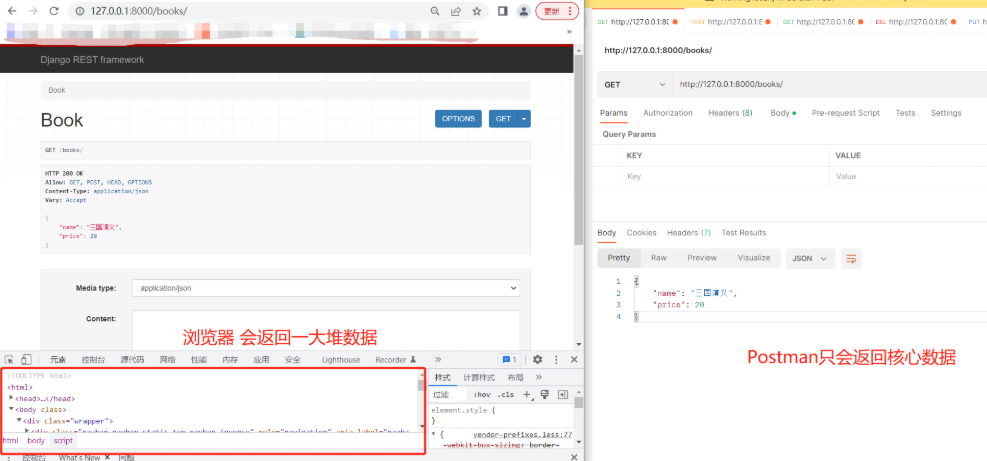
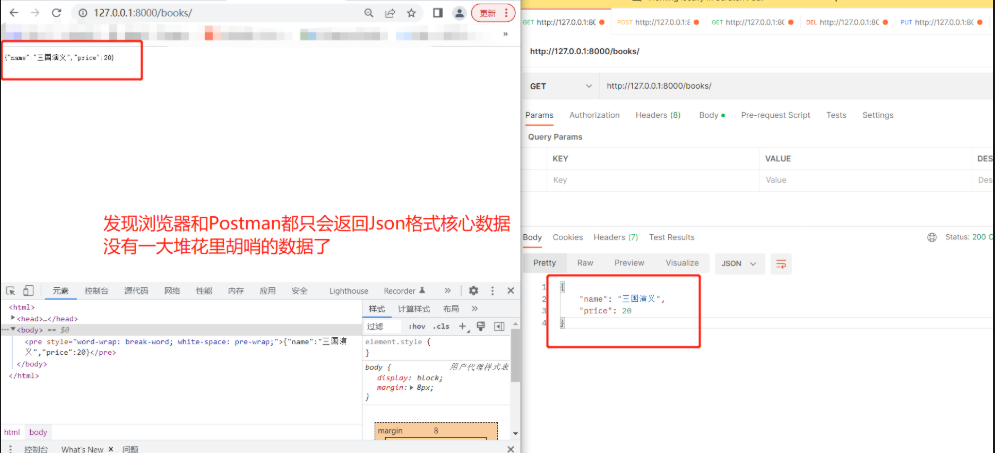
思考:全局配了1个,某个视图类想要3个,怎么配?(查找顺序) 只需要在视图类配置3个即可 因为:先从views.py视图类自身找,找不到再去项目的drf配置文件中找,再找不到就去drf默认的配置文件中找 2)Request类源码中有哪些属性和方法 data #无论是什么请求方式、编码格式,只要是在body中的数据都可以用request.data获取(取出来是字典) __getattr__ # (对象.一个名字 当名字不存在时会自动触发) query_params#get请求携带的参数可以在这里取,也可以不遵循规范直接request.POST详情见:一.Django DRF入门规范>>11.Request对象源码分析(了解) 2.响应注意事项: # 响应用get 请求才是post # drf 是djagno的一个app,所以要在settings.py中注册【'rest_framework'】 如果不注册的话用浏览器打开url地址会报错 # drf的响应,如果使用浏览器和postman访问同一个接口,返回格式是不一样的 -drf做了判断,如果是浏览器就好看一些,如果是postman只要json数据 # 导入APIView from rest_framework.views import APIView # 导入Response模块 from rest_framework.response import Response class BookView(APIView): # 返回所有图书接口 def get(self, request): return Response({'name': '三国演义', 'price': 20})
需求:现在要求该接口只能返回json编码格式不能返回另一种编码格式 方式一:(局部配置)在views.py视图类中用参数renderer_classes=[ ]限制可以解析的响应编码格式 响应默认共有两个解析类 from rest_framework.renderers import JSONRenderer,BrowsableAPIRendererJSONRenderer就是json格式 类似于Postman看到的结果 BrowsableAPIRenderer就是一大堆数据 类似于浏览器上看到的结果 # 导入APIView from rest_framework.views import APIView # 导入Response模块 from rest_framework.response import Response # 导入解析类 from rest_framework.renderers import JSONRenderer, BrowsableAPIRenderer class BookView(APIView): # 限制该接口只能返回json编码格式 renderer_classes = [JSONRenderer] # 返回所有图书接口 def get(self, request): ... return Response({'name': '三国演义', 'price': 20})
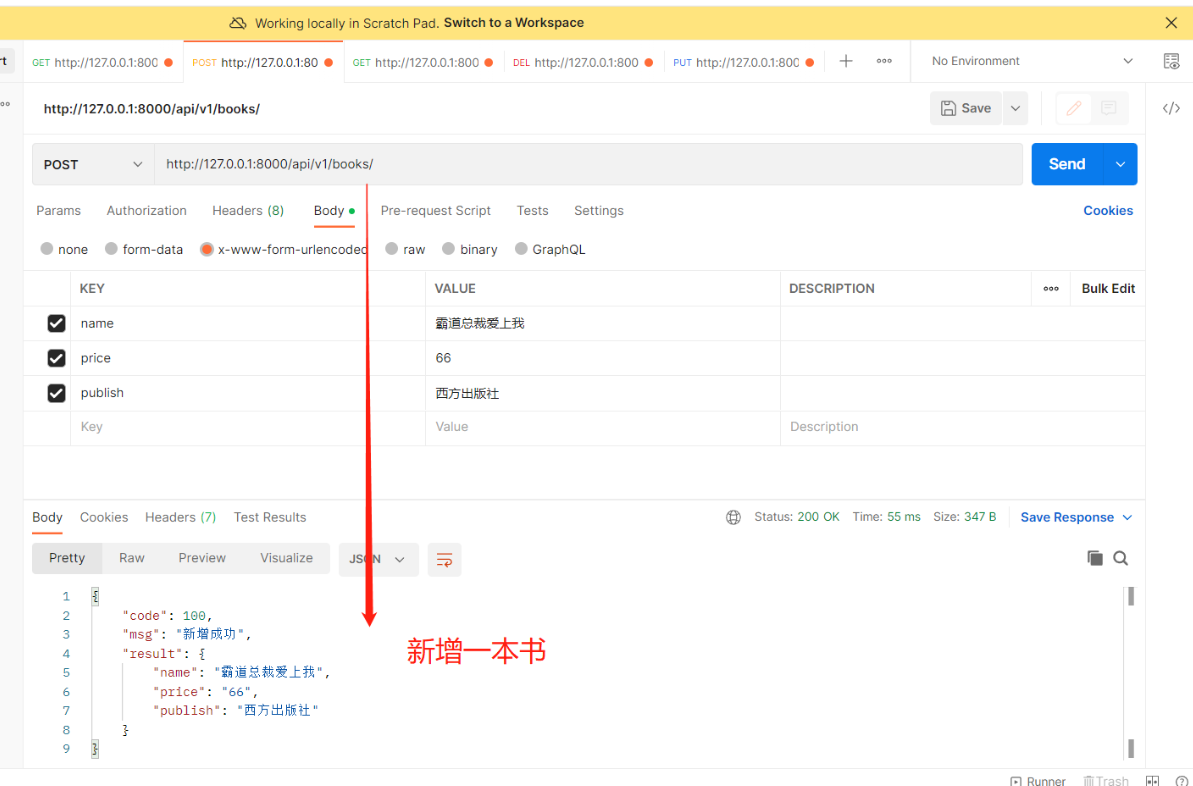
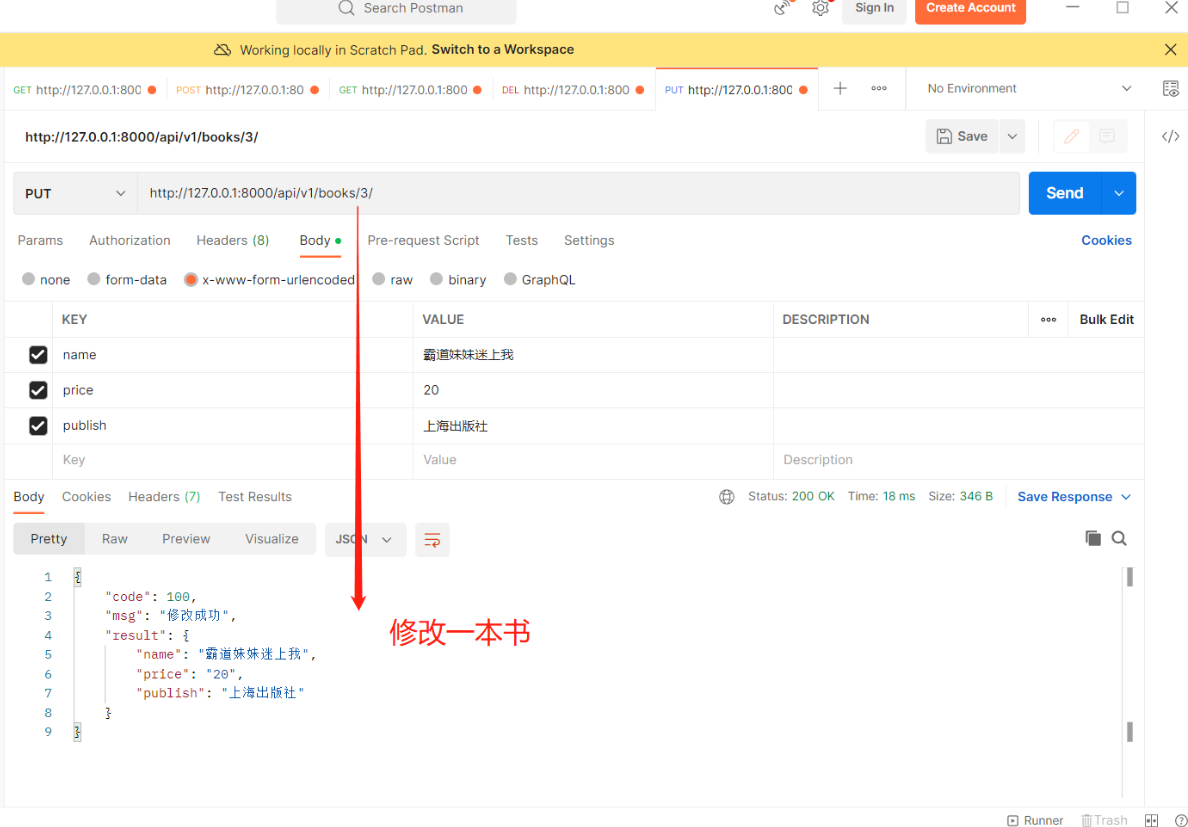
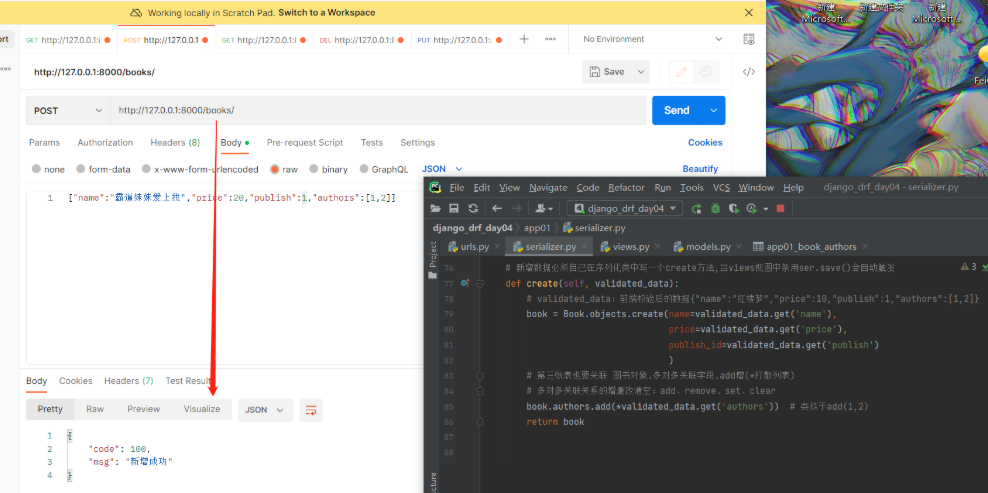
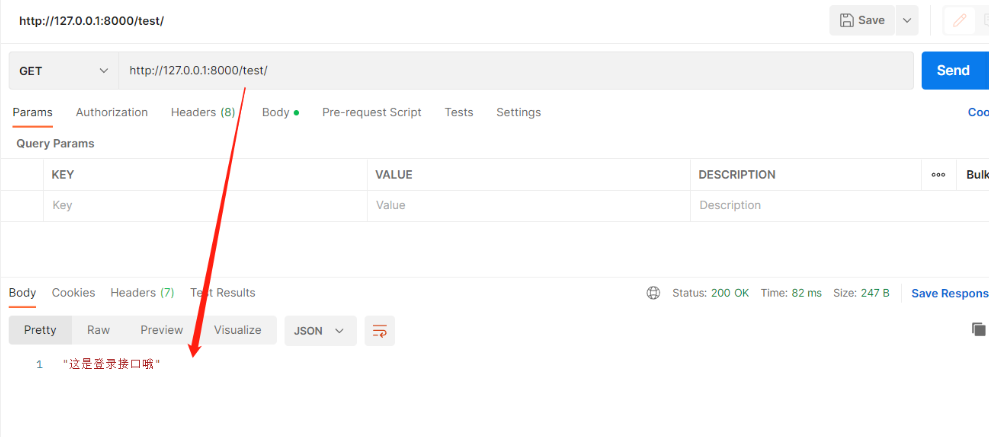
方式二:(全局配置)在配置文件中配置 一般不用在drf项目配置文件中写下列代码 REST_FRAMEWORK = { 'DEFAULT_RENDERER_CLASSES': [ # 限制不要哪个编码格式就注释掉 'rest_framework.renderers.JSONRenderer', 'rest_framework.renderers.BrowsableAPIRenderer', ], }思考:使用顺序(一般用内置的就可以,不用动) 优先使用视图类中的配置,其次使用项目配置文件中的配置,最后使用内置的 2)Response类源码中有哪些属性和方法 #源码分析 1.from rest_framework.response import Response 直接点Response查看源码 2.当视图类的方法返回时会用return Response(...),会走里面的__init__方法,研究__init__里可以传什么参数 def __init__(self, data=None, status=None, template_name=None, headers=None, exception=False, content_type=None): —————————————————— 1)data:※之前写的ser.data,可以是字典、列表、字符串(比JsonResponse更强大)。序列化后返回给前端,前端在响应体中看到的就是它。 2)status:※http响应的状态码,默认是200可以改: drf在status包下把所有http响应状态码都写了一遍 from rest_framework.status import HTTP_200_OK def get(self, request): return Response({'name':'三国演义'}, status=HTTP_200_OK) 3)template_name:修改响应模板的样子,BrowsableAPIRenderer(浏览器检查中的一大堆数据)定死的样子,后期公司会自己定制【了解即可】 4)headers:※http响应的响应头 def get(self, request): return Response({'name':'三国演义'}, headers={'xx':'yy'}) # 这样响应头中就添加了一条xx=yy的数据 # 跨域时会用到(前后端分离项目一定会用跨域) """ 提问:那么原生django如何往响应头中加数据 from django.shortcuts import render,HttpResponse,redirect from django.http import JsonResponse 以上四件套render、redirect、HttpResponse、JsonResponse都可以等于一个对象: def get(self, request): obj=HttpResponse('123') obj['xx']='yy' return obj 有了drf后直接用headers传就可以,不需要这么麻烦 """ 5)content_type:响应编码格式,一般不动 ———————————————————— # 重点:data,status,headers 四.视图组件 1.视图组件drf提供了一个顶层的视图类APIView,我们可以通过继承APIView写视图类 后期要写的代码可能重复代码会比较多,就可以使用面向对象的继承、封装 # APIView和View的区别(APIView的作用): 1.传入到视图方法中的是REST framework(drf)的新Request对象,而不是Django的Requeset对象 2.视图方法可以返回REST framework(drf)的新Response对象 3.任何APIException异常都会被捕获到,并且处理成合适的响应信息 4.在进行dispatch()分发前,会对请求进行身份认证、权限检查、流量控制(频率) 2.两个视图基类 1)APIView: from rest_framework.views import APIView #里面的类属性: render_classes # 响应格式 parser_classes # 能够解析的请求格式 authentication_classes # 认证类 throttle_classes # 频率类 permission_classes # 权限类 2)GenericAPIView:(继承了APIView,有了新的属性和方法)# 和数据库打交道尽量用它 '今后就基于该类去写5个接口' from rest_framework.generics import GenericAPIView #里面的类属性:※ queryset # 要序列化或反序列化的表模型数据 serializer_class # 使用的序列化类 lookup_field # 查询单挑的路由分组分出来的字段名 filter_backends # 过滤类的配置 pagination_class # 分页类的配置 #里面的类方法: self.get_queryset() # 获取所有要序列化的数据(后期可重写该方法,后期扩展性高) '你爹有的话,你不写就用你爹的, 你写了就用你的' self.get_object() # 根据pk获取单个数据,也叫获取单个的对象 self.get_serializer # 获取要使用的序列化类(后期可重写get_serializer_class) """ get_serializer_class()返回哪个序列化类 get_serializer就会用哪个去序列化 后期会有序列化类和反序列化类可以通过重写get_serializer_class去控制哪个去做序列化,哪个去做反序列化 """ self.filter_queryset # 过滤有关(后面细说) 1)基于APIView+ModelSerializer+Response写Book表5个接口>>第一层 多表时 1.【models.py】中创建Book、Author、Publish表 # 图书表与作者表:多对多,需建立第三章中间表(可用ManyToManyField自动生成第三张表),外键字段在查询频率多的一方 # 图书表与出版社表:一对多,外键字段在多(书)的一方,还要加级联删除on_delete=models.CASCADE class Book(models.Model): name = models.CharField(max_length=32) price = models.CharField(max_length=32) # 要在序列化类中配置只写时才显示 author = models.ManyToManyField(to='Author') publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE) # 定制返回给前端格式(在序列化类中配置只读时才显示) def author_list(self): return {'name': self.author.name, 'phone': self.author.phone} def publish_info(self): return {'name': self.publish.name, 'addr': self.publish.addr} class Author(models.Model): name = models.CharField(max_length=32) phone = models.CharField(max_length=11) class Publish(models.Model): name = models.CharField(max_length=32) addr = models.CharField(max_length=32) ———————————————————————————— 2.执行表迁移命令,为了省时间直接用sqlite.3做数据库 1)表迁移命令 - makemigrations - migrate 2)表迁移完双击左侧db.sqlite.3 ———————————————————————————— 3.录入几条数据 4.app01中新建【serializer.py】写序列化类 # 导入序列化类 from rest_framework import serializers # 导入Book表 from .models import Book class BookSerializer(serializers.ModelSerializer): # 跟表关联 class Meta: # 与Book表建立关系 model = Book # 序列化Book中的哪些字段和方法 fields = ['name', 'price', 'publish_info', 'author_list', 'publish', 'author'] # 定制序列化与反序列化的额外规则,并给方法字段限制只读,出版社和作者只写 extra_kwargs = {'name': {'max_length': 8}, 'publish_info': {'read_only': True}, 'author_list': {'read_only': True}, 'publish': {'write_only': True}, 'author': {'write_only': True} } 5.【views.py】 # 导入视图基类APIView from rest_framework.views import APIView # 导入Book表 from .models import Book # 导入自己写的序列化类 from .serializer import BookSerializer # 导入Response类 from rest_framework.response import Response class BookView(APIView): # 查询所有图书接口 def get(self, request): # 查询所有图书对象:结果是queryset[对象,对象] books = Book.objects.all() """ instance:要序列化的对象books many=True:如果是多个对象就加,单个对象不加 """ ser = BookSerializer(instance=books, many=True) """ ser.data:把指定字段去转成字典或列表 Response:无论字典还是列表都可以序列化给前端显示 """ return Response(ser.data) # 新增一本图书接口 def post(self, request): """ data: 前端提交过来的数据都在request.data中,把该数据给了data参数 """ ser = BookSerializer(data=request.data) # 判断如果数据全部符合反序列化要求则保存 if ser.is_valid(): ser.save() """ ser.data:把新增的字段数据去转成字典或列表(前提是序列化类中必须返回新增的对象) ModelSerializer已经帮我们写了create和update方法了 里面已经把新增的对象返回了 所以要想拿新增的对象并序列化成字典给前端显示就用ser.data """ return Response({'code': 100, 'msg': '新增成功', 'result': ser.data}) else: # 否则返回错误信息 return Response({'code': 101, 'msg': ser.errors}) class BookDetailView(APIView): # 查询一本图书接口 def get(self, request, pk): # 找到要查询的图书对象 book = Book.objects.filter(pk=pk).first() """ instance:要序列化的对象book """ ser = BookSerializer(instance=book) """ ser.data:把指定字段去转成字典或列表 Response:无论字典还是列表都可以序列化给前端显示 """ return Response(ser.data) # 修改一本图书接口 def put(self, request, pk): # 找到要修改的图书对象 book = Book.objects.filter(pk=pk).first() """ instance:要序列化的对象book data:前端提交过来的数据都在request.data中,把该数据给了data参数 """ ser = BookSerializer(instance=book, data=request.data) # 判断如果数据全部符合反序列化要求则保存 if ser.is_valid(): ser.save() """ ser.data:把修改的字段数据去转成字典或列表(前提是序列化类中必须返回修改的对象) ModelSerializer已经帮我们写了create和update方法了 里面已经把修改的对象返回了 所以要想拿修改的对象并序列化成字典给前端显示就用ser.data """ return Response({'code': 100, 'msg': '修改成功', 'result': ser.data}) else: # 否则返回错误信息 return Response({'code': 101, 'msg': ser.errors}) # 删除一本图书接口 def delete(self, request, pk): # 找到要删除的图书对象直接删除 Book.objects.filter(pk=pk).delete() return Response({'code': 100, 'msg': '删除成功'}) 6.【urls.py】 path('books/', views.BookView.as_view()), path('books//', views.BookDetailView.as_view()) 2)基于GenericAPIView+ModelSerializer+Response写Book表的5个接口>>第二层思考基于APIView发现Views.py视图层中只写了book的5个接口,那publish的5个接口怎么写? 答:把给book表的5个接口复制下来修改个别地方即可。但是会发现重复代码较多!所以想到通过继承好让代码精简一些。这样就用到了GenericAPIView类,该类继承了APIView,有了新的属性和方法今后就用该类去写5个接口 # 导入视图基类GenericAPIView from rest_framework.generics import GenericAPIView # 导入Book表 from .models import Book # 导入自己写的序列化类 from .serializer import BookSerializer # 导入Response类 from rest_framework.response import Response class BookView(GenericAPIView): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer # 查询所有图书接口 def get(self, request): # 获取所有要序列化的数据 objs = self.get_queryset() # 获取要使用的序列化类 instance:要序列化的对象 many=True:多个对象要加,单个对象不加 ser = self.get_serializer(instance=objs, many=True) return Response(ser.data) # 新增一本图书接口 def post(self, request): # 获取要使用的序列化类 前端提交过来的数据都在request.data中,把该数据给了data参数 ser = self.get_serializer(data=request.data) # 判断如果数据全部符合反序列化要求则保存 if ser.is_valid(): ser.save() return Response({'code': 100, 'msg': '新增成功', 'result': ser.data}) else: # 否则返回错误信息 return Response({'code': 101, 'msg': ser.errors}) class BookDetailView(GenericAPIView): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer # 查询一本图书接口 def get(self, request, pk): # 获取要序列化的单个数据(根据pk获取单个数据,不用传值,自动识别) obj = self.get_object() # 获取要使用的序列化类 instance:要序列化的对象 ser = self.get_serializer(instance=obj) return Response(ser.data) # 修改一本图书接口 def put(self, request, pk): # 获取要序列化的单个数据(根据pk获取单个数据,不用传值,自动识别) obj = self.get_object() # 获取要使用的序列化类 instance:要序列化的对象 data:前端提交过来的数据都在request.data中,把该数据给了data参数 ser = self.get_serializer(instance=obj, data=request.data) # 判断如果数据全部符合反序列化要求则保存 if ser.is_valid(): ser.save() return Response({'code': 100, 'msg': '修改成功', 'result': ser.data}) else: # 否则返回错误信息 return Response({'code': 101, 'msg': ser.errors}) # 删除一本图书接口 def delete(self, request, pk): # 获取要序列化的单个数据(根据pk获取单个数据,不用传值,自动识别) 删除可以直接.delete self.get_object().delete() return Response({'code': 100, 'msg': '删除成功'})思考:上面只写了Book的5个接口,如果再写Publish的5个接口(复制下来)发现两个表区别只是两个类属性不同,其他代码重复。所以继续封装 3.五个视图扩展类(不是视图类)drf还封装了5个视图扩展类(get所有,get一个,post新增,put修改,delete删除),这5个视图扩展类没有继承APIView及其子类所以不能单独使用,必须配合GenericAPIView一起使用! from rest_framework.mixins import CreateModelMixin,UpdateModelMixin,DestroyModelMixin,RetrieveModelMixin,ListModelMixin # mixins 混入:通过继承来实现多个功能 ———————————————————————— CreateModelMixin # 新增 UpdateModelMixin # 修改 DestroyModelMixin # 删除 RetrieveModelMixin # 查单条 ListModelMixin # 查所有 __________________________________________________________ # 查看这五个视图扩展类源码发现里面已经帮我们写好一些方法,且和我们自己在视图类中写的get,post,put,delete方法大致一样 1)基于GenericAPIView+五个视图扩展类写Book表的5个接口>>第三层 # 导入视图基类GenericAPIView from rest_framework.generics import GenericAPIView # 导入Book表 from .models import Book # 导入自己写的序列化类 from .serializer import BookSerializer # 导入五个视图扩展类 from rest_framework.mixins import CreateModelMixin,UpdateModelMixin,DestroyModelMixin,RetrieveModelMixin,ListModelMixin # 继承GenericAPIView和ListModelMixin,CreateModelMixin class BookView(GenericAPIView, ListModelMixin, CreateModelMixin): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer # 查询所有图书接口 def get(self, request): # 直接调用继承的ListModelMixin里的list方法并返回出去 return self.list(request) # 新增一本图书接口 def post(self, request): # 直接调用继承的CreateModelMixin里的create方法并返回出去 return self.create(request) # 继承GenericAPIView和RetrieveModelMixin,UpdateModelMixin,DestroyModelMixin class BookDetailView(GenericAPIView, RetrieveModelMixin, UpdateModelMixin, DestroyModelMixin): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer # 查询一本图书接口(把接收url中pk的参数改为*args和**kwargs) def get(self, request, *args, **kwargs): # 直接调用继承的RetrieveModelMixin里的retrieve方法并返回出去 不要忘记传pk return self.retrieve(request, *args, **kwargs) # 修改一本图书接口(把接收url中pk的参数改为*args和**kwargs) def put(self, request, *args, **kwargs): # 直接调用继承的UpdateModelMixin里的update方法并返回出去 不要忘记传pk return self.update(request, *args, **kwargs) # 删除一本图书接口(把接收url中pk的参数改为*args和**kwargs) def delete(self, request, *args, **kwargs): # 直接调用继承的DestroyModelMixin里的destroy方法并返回出去 不要忘记传pk return self.destroy(request, *args, **kwargs) 4.九个视图子类也就是视图类,不需要额外继承GenericAPIView,只需要继承九个视图子类中的某个就会有某个或某几个接口 from rest_framework.generics import ListAPIView, CreateAPIView, ListCreateAPIView, RetrieveAPIView, UpdateAPIView, DestroyAPIView, RetrieveUpdateAPIView, RetrieveDestroyAPIView, RetrieveUpdateDestroyAPIView ———————————————————————— """BookView""" ListAPIView # 查所有 CreateAPIView # 新增一个 ListCreateAPIView #查所有+新增一个 """BookDetailView""" RetrieveAPIView # 查单条 UpdateAPIView # 修改一个 DestroyAPIView # 删除一个 RetrieveUpdateAPIView # 查单条+修改一个 RetrieveDestroyAPIView # 查单条+删除一个 RetrieveUpdateDestroyAPIView # 查单条+修改一个+删除一个 '比如:如果又要查所有又要新增一个,就继承ListCreateAPIView类,其他同理' '没有修改一个+删除一个,猜测是因为只有查到了才能去修改或删除' 1)基于九个视图子类+ModelSerializer写Book表的5个接口>>第四层 # 导入九个视图子类(用哪些导哪些即可) from rest_framework.generics import ListAPIView, CreateAPIView, ListCreateAPIView, RetrieveAPIView, UpdateAPIView, DestroyAPIView, RetrieveUpdateAPIView, RetrieveDestroyAPIView, RetrieveUpdateDestroyAPIView # 导入Book表 from .models import Book # 导入自己写的序列化类 from .serializer import BookSerializer # 查所有+新增一个接口 class BookView(ListCreateAPIView): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer # 不用再写get和post方法,继承的类中已提前写好了 # 查单条+修改一个+删除一个接口 class BookDetailView(RetrieveUpdateDestroyAPIView): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer # 不用再写get、update、delete方法,继承的类中已提前写好了 ————————————————————————— 需求:如果只需要查所有+删除一个接口: # 查所有接口 class BookView(ListAPIView): queryset = Book.objects.all() serializer_class = BookSerializer # 删除一个接口 class BookDetailView(DestroyAPIView): queryset = Book.objects.all() serializer_class = BookSerializer思考:以上代码虽然看起来精简不少,但是还是要写两个接口(BookView、BookDetailView)并配置两个路由,可是这两个视图类的代码一样,还需要继续封装,可是会造成路由中会有两个get(查所有、查单条),这就用到了ModelViewSet,只要继承了它五个接口就都有了,但是路由却变了 5.视图集drf提供了两个视图类 ModelViewSet`,只要继承了该类5个接口增删改查都在里面,但是路由写法会变>>`as_view({' ': ' '}) 1.查所有: path('books/', views.BookView.as_view({'get': 'list'})), # 如果是get请求访问这个地址,就会执行视图类的list方法(父类中有),也就是给路由做映射 ———————————————————————— 2.查所有+新增一个: path('books/', views.BookView.as_view({'get': 'list', 'post': 'create'})), 3.查一个(#需要新开一个路由,但是还是BookView) path('books//', views.BookView.as_view({'get': 'retrieve'})), ———————————————————————— 4.查一个+修改一个+删除一个 path('books//', views.BookView.as_view({'get': 'retrieve', 'put': 'update', 'delete': 'destroy'})),ReadOnlyModelViewSet,继承了该类内部只有查询所有和查询一条,访问其他则会报错 1)基于ModelViewSet+ModelSerializer编写5个接口>>第五层 #【views.py】 # 导入视图类 from rest_framework.viewsets import ModelViewSet # 导入Book表 from .models import Book # 导入自己写的序列化类 from .serializer import BookSerializer class BookView(ModelViewSet): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer #【urls.py】 path('books/', views.BookView.as_view({'get': 'list', 'post': 'create'})), path('books//', views.BookView.as_view({'get': 'retrieve', 'put': 'update', 'delete': 'destroy'})), 2)基于ReadOnlyModelViewSet编写2个只读(查所有/查单个)接口 #【views.py】 # 导入视图类 from rest_framework.viewsets import ReadOnlyModelViewSet # 导入Book表 from .models import Book # 导入自己写的序列化类 from .serializer import BookSerializer class BookView(ReadOnlyModelViewSet): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer #【urls.py】 path('books/', views.BookView.as_view({'get': 'list'})), path('books//', views.BookView.as_view({'get': 'retrieve'})),此时如果还和之前一样访问新增一条、修改一条、删除一条则会报错,因为该类内部只有查所有、查一条! 3)ViewSetMixin源码分析为什么路由改变了写法?以ModelViewSet为入口研究 class ModelViewSet(mixins.CreateModelMixin, mixins.RetrieveModelMixin, mixins.UpdateModelMixin, mixins.DestroyModelMixin, mixins.ListModelMixin, GenericViewSet) "也就是:" ModelViewSet=CreateModelMixin+RetrieveModelMixin+UpdateModelMixin+DestroyModelMixin+mixins.ListModelMixin+GenericViewSet "以上就GenericViewSet暂时还没遇到过 所以研究GenericViewSet" class GenericViewSet(ViewSetMixin, generics.GenericAPIView) "也就是:" GenericViewSet=ViewSetMixin+GenericAPIView(视图基类) "以上就ViewSetMixin暂时还没遇到过 所以研究ViewSetMixin" 1.当请求来了>>路由匹配成功:假如get请求来了,路由匹配成功books,会执行 views.BookView.as_view({'get': 'list'})+() 2.读as_view看是怎么做的:# 这个as_view是ViewSetMixin的as_view ———————————————————————————— class ViewSetMixin: """ 源码中的注释告诉以后配置路由就变成了: view = MyViewSet.as_view({'get': 'list', 'post': 'create'}) """ @classonlymethod def as_view(cls, actions=None, **initkwargs): # 如果在路由中没有传actions直接抛异常:路由写法变了后,as_view中不传actions字典会报错 if not actions: raise TypeError("The `actions` argument must be provided when " "calling `.as_view()` on a ViewSet. For example " "`.as_view({'get': 'list'})`") ... def view(request, *args, **kwargs): self = cls(**initkwargs) if 'get' in actions and 'head' not in actions: actions['head'] = actions['get'] self.action_map = actions for method, action in actions.items(): handler = getattr(self, action) setattr(self, method, handler) return self.dispatch(request, *args, **kwargs) # 去除了csrf校验 return csrf_exempt(view) ———————————————————————————— 3.所以路由匹配成功执行views.BookView.as_view({'get': 'list'})+() 本质就是执行ViewSetMixin>>中的as_view>>中的view(),研究这个view(): def view(request, *args, **kwargs): #actions 是传入的字典>>{'get': 'list', 'post': 'create'} self.action_map = actions # 第一次循环时 method就是get action就是list # 第一次循环时 method就是post action就是create for method, action in actions.items(): # 反射:去视图类中反射action对应的方法(action第一次是list,去视图类中反射list方法) # handler就是视图类中的list方法 handler = getattr(self, action) # 反射修改:(method对应的get请求方法,handler对应的list方法)视图类的对象的get方法变成了list setattr(self, method, handler) return self.dispatch(request, *args, **kwargs) #dispatch是父类APIView的 4.所以经过分析,它只是把get请求变成了List,同理其他几个请求一样变成对应的方法总结: 1.只要继承ViewSetMixin的视图类(无论直接继承还是间接继承),路由写法就变了(重写了as_veiw) 2.变成需要传入字典映射的方法:{'get': 'list', 'post': 'create'} # 只要传入actions(上述字典),以后访问get就是访问list,访问post就是访问create,其他同理 3.其他执行跟之前一样并没什么区别,仅上述一个 4.以后视图类中的方法名'可以任意命名',只要在路由中的字典里'做好映射'即可#【重要】 ———————————————————————————————————— 如: 基于ViewSetMixin+APIView写视图类 #【views.py】 from rest_framework.viewsets import ViewSetMixin from rest_framework.views import APIView from rest_framework.response import Response class TestView(ViewSetMixin, APIView): def login(self, request): return Response('这是登录接口哦') #【urls.py】 path('test/',views.TestView.as_view({'get':'login'})),
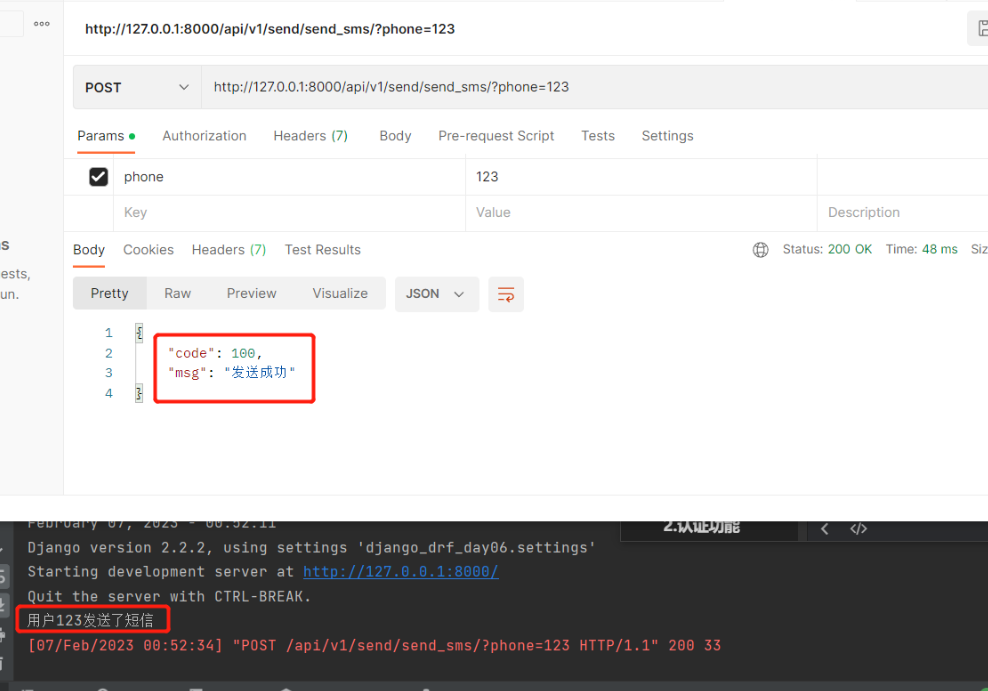
drf中只要继承了ViewSetMinxin类及其子类,路由就要换一种写法 # 所有的路由写法可能有以下三种情况: 1.传统写法:path('books/', views.BookView.as_view() 2.映射写法:path('books/', views.BookView.as_view({'get': 'list', 'post': 'create'})) 3.自动生成drf提供了两个路由类:SimpleRouter和DefaultRouter,以后只要继承了ModelViewSet类及其子类,就可以用这两个路由类来自动生成路由。一般都用SimpleRouter,另一个不知道也没关系 DefaultRouter比SimpleRouter多自动生成了: 1.API Root(根):访问根可以看到有哪些地址,如book、publish的 2.给第一个路由类产生的地址都起了别名 #一般不用DefaultRouter路由类 from rest_framework.routers import SimpleRouter 1.自动生成路由使用方式 不要忘记在settings.py中注册 'rest_framework' 否则无法在浏览器中打开 #【urls.py】 # 导入include from django.urls import include # 导入路由类 from rest_framework.routers import SimpleRouter # 实例化得到对象 router = SimpleRouter() # 注册路由(让路径和视图类建立一个关系,有几个视图类就建立几个关系) """ 第一个参数:路径(不用带斜杠) 第二个参数:视图类 第三个参数:别名(一般和路径相同) """ router.register('books', views.BookView, 'books') # 在urlpatterns内写路由(需导include) path('api/v1/', include(router.urls)),自动生成路由底层是如何实现的? 1.# 本质是自动做映射,能够自动的前提是:视图类中要有5个方法的某个或多个 get >>对应>> list get >>对应>> retrieve put >>对应>> update post >>对应>> create delete>>对应>> destory 2.# 那么继承谁才可以有这5个方法中的某个或某多个? 1)ModelViewSet 或 ReadOnlyModelViewSet # 可以自动生成 2)9个视图子类 配合ViewSetMixin(修改路由写法) # 才可以自动生成 3)GenericAPIView+5个视图扩展类 配合ViewSetMixin(修改路由写法) # 才可以自动生成 """ 注意:ViewSetMixin要在前面: class BookView(ViewSetMixin,ListCreateAPIView): pass """ 2.action装饰器(重要)@action是写在视图类的方法上,可以给视图类中定义的函数也添加路由 from rest_framework.decorators import action @action()括号内可携带的参数 """ 1.methods:指定请求方法,可以传多个 2.detail:只能传True和False -False,不带id的路径:send/send_sms/ -True,带id的路径:send/2/send_sms/ 3.url_path:生成send后路径的名字,不传默认以背装饰方法名命名 4.url_name:别名,反向解析使用,了解即可 """ @action(methods=['POST'], detail=False)使用方式 假设发送短信自动生成路由(伪代码,主要是验证各个请求自动生成路由) 1.写在视图类方法上 #【views.py】 # 导入视图集 from rest_framework.viewsets import ViewSet from rest_framework.response import Response # 导入装饰器 from rest_framework.decorators import action class SendView(ViewSet): @action(methods=['POST'], detail=False) def send_sms(self, request): # 获取get请求中携带的手机号 phone = request.query_params.get('phone') print('用户%s发送了短信' % phone) return Response({'code': 100, 'msg': '发送成功'}) ———————————————————————— #【urls.py】 # 导入include from django.urls import include # 导入路由类 from rest_framework.routers import SimpleRouter # 实例化得到对象 router = SimpleRouter() # 注册路由 第一个参数:路径(不用带斜杠) 第二个参数:视图类 第三个参数:别名(一般和路径相同) router.register('send', views.SendView, 'send') # 在urlpatterns中写路由 path('api/v1/', include(router.urls)), ———————————————————————— 输入路径:http://127.0.0.1:8000/api/v1/send/send_sms/?phone=123 """ api/v1/ 是路由中写的 send 是注册时的路径,会把send的get给list,post给create,put给update,delete给destory send_sms url_path参数没给值则默认以方法名命名 """
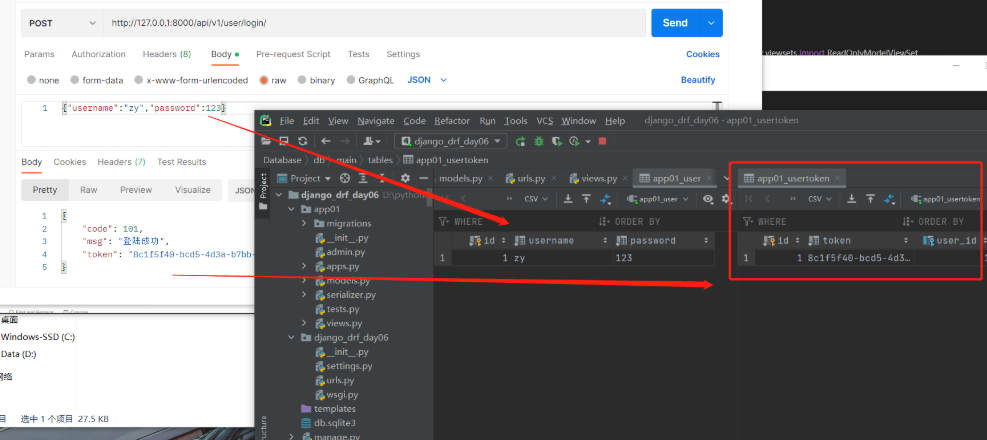
注:今后看到的drf路由写法,基本都是自动生成的,几乎不会在urlpatterns中写路由。 扩展知识: 1.不同的请求方式可以使用不同序列化类 2.不同action也可以使用不同序列化类(工作中才会用到) 以下是伪代码,仅用来了解不同的action也可以使用不同序列化类 class SendView(GenericViewSet): # 要序列化或反序列化的表模型数据 queryset = None # 要使用的序列化类 serializer_class = '序列化的类' # 通过重写get_serializer方法来根据请求方式的不同选择不同的序列化类 def get_serializer(self, *args, **kwargs): # 判断action是不是login1 if self.action == 'login1': return '序列化类1' else: return '序列化类2' @action(methods=['GET'], detail=True) def login1(self, request): # get # 序列化类 pass @action(methods=['GET'], detail=True) def login2(self, request): # get # 序列化类 pass 六.认证权限频率 1.认证需求:访问某个接口需要登录后才能访问 由于认证是基于登录的接口上面操作的,所以需先编写一个登录接口然后再写认证组件 1)登录接口User表:用户数据表、UserToken表:存储用户登录状态的表,当登录成功后会生成一个随机字符串放到UserToken表中,以后只要带着token过来就是登录了,不带就是没登录 #【modoels.py】 # User表与UserToken表是一对一关系 class User(models.Model): username = models.CharField(max_length=32) password = models.CharField(max_length=32) class UserToken(models.Model): token = models.CharField(max_length=32) user = models.OneToOneField(to='User', on_delete=models.CASCADE, null=True) #【views.py】 from .models import User, UserToken from rest_framework.viewsets import ViewSet from rest_framework.decorators import action from rest_framework.response import Response import uuid # 登录接口(自动生成路由) 由于登录功能不用序列化 所以继承ViewSet即可 class UserView(ViewSet): # 添加自动生成路由装饰器 @action(methods=['POST'], detail=False) def login(self, request): # 获取前端传过来的用户名和密码 username = request.data.get('username') password = request.data.get('password') # 获取数据 user = User.objects.filter(username=username, password=password).first() # 看是否有值来判断是否正确 if user: # uuid生成一个永不重复的随机字符串 token = str(uuid.uuid4()) # 在UserToken表中还需存储:如果从来没登录过就插入该字符串,如果登陆过就修改记录 # 根据传入的东西查找(反向查询有隐藏的表名小写字段),如能找到就使用defaults的数据更新,查不到则新增一条 UserToken.objects.update_or_create(user=user, defaults={'token': token}) return Response({'code': 101, 'msg': '登陆成功', 'token': token}) else: return Response({'code': 101, 'msg': '用户名或密码错误'}) #【urls.py】 from app01 import views # 导入include from django.urls import include # 导入路由类 from rest_framework.routers import SimpleRouter # 实例化得到对象 router = SimpleRouter() # 注册路由第一个参数:路径(不用带斜杠) 第二个参数:视图类 第三个参数:别名(一般和路径相同) router.register('user', views.UserView, 'user') # 在urlpatterns中注册, path('api/v1/', include(router.urls)),
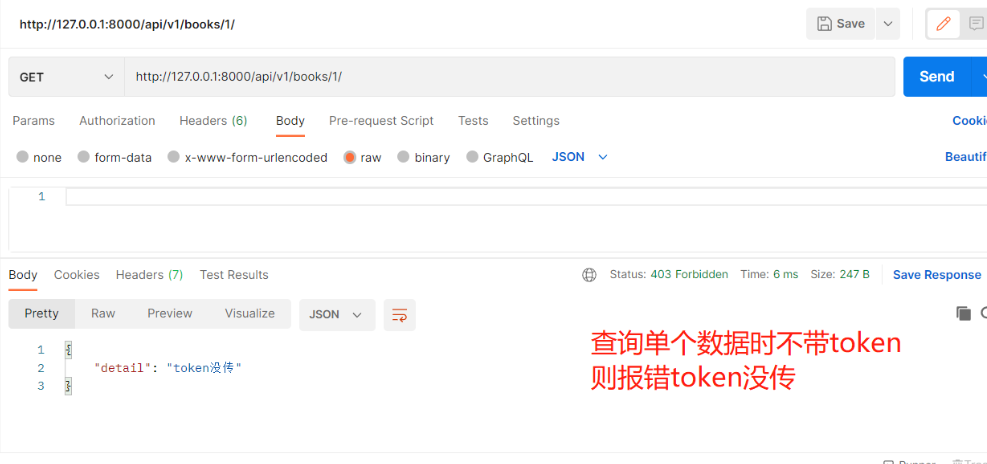
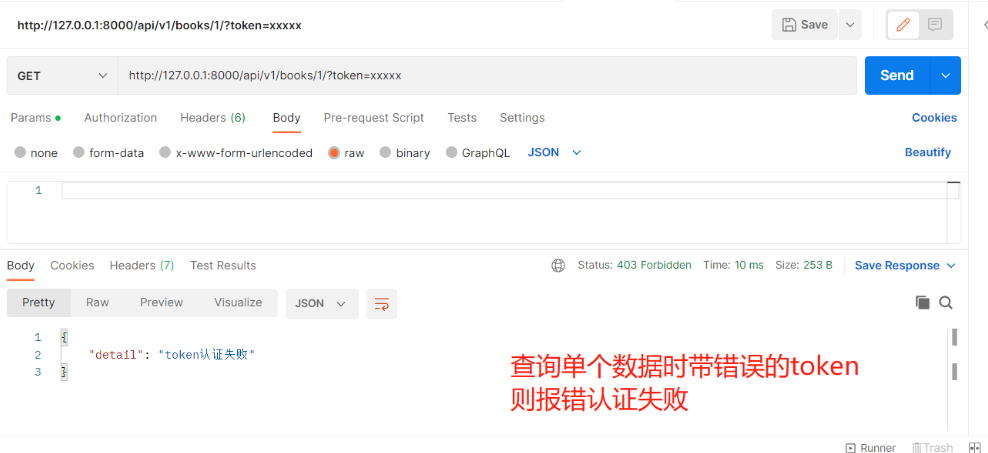
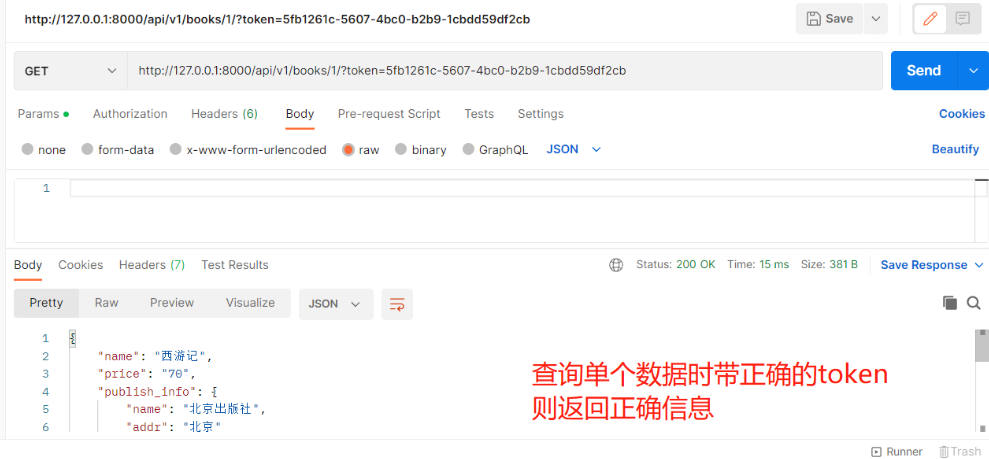
需求:查所有不需要登录就可以访问,查单个需要登录才能访问 数据准备 【models.py】 # 图书表与作者表:多对多,需建立第三章中间表(可用ManyToManyField自动生成第三张表),外键字段在查询频率多的一方 # 图书表与出版社表:一对多,外键字段在多(书)的一方,还要加级联删除on_delete=models.CASCADE class Book(models.Model): name = models.CharField(max_length=32) price = models.IntegerField() # 定制返回给前端格式(在序列化类中配置只写时才显示) authors = models.ManyToManyField(to='Author') publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE) # 定制返回给前端格式(在序列化类中配置只读时才显示) def author_list(self): l1 = [] for i in self.authors.all(): l1.append({'name': i.name, 'phone': i.phone}) return l1 def publish_info(self): return {'name': self.publish.name, 'addr': self.publish.addr} class Author(models.Model): name = models.CharField(max_length=32) phone = models.CharField(max_length=11) class Publish(models.Model): name = models.CharField(max_length=32) addr = models.CharField(max_length=32) ———————————————————————————— 2.执行表迁移命令,为了省时间直接用sqlite.3做数据库 1)表迁移命令 - makemigrations - migrate 2)表迁移完双击左侧db.sqlite.3 ———————————————————————————— 3.录入几条数据 4.写增删改查接口(以查询所有图书+查询单个图书为例) from rest_framework.generics import ListAPIView, RetrieveAPIView from rest_framework.viewsets import ViewSetMixin from .models import Book from .serializer import BookSerializer # 查询所有接口(自动生成路由) class BookView(ViewSetMixin, ListAPIView): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer # 查询单个接口(自动生成路由) class BookDetailView(ViewSetMixin, RetrieveAPIView): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer 5.app01中新建【serializer.py】写序列化类 # 导入序列化类 from rest_framework import serializers # 导入Book表 from .models import Book class BookSerializer(serializers.ModelSerializer): # 跟表关联 class Meta: # 与Book表建立关系 model = Book # 序列化Book中的哪些字段和方法 fields = ['name', 'price', 'publish_info', 'author_list', 'publish', 'author'] # 定制序列化与反序列化的额外规则,并给方法字段限制只读,出版社和作者只写 extra_kwargs = {'name': {'max_length': 8}, 'publish_info': {'read_only': True}, 'author_list': {'read_only': True}, 'publish': {'write_only': True}, 'author': {'write_only': True} } ———————————————————————————— 6.【urls.py】中自动生成路由 # 导入include from django.urls import include # 导入路由类 from rest_framework.routers import SimpleRouter # 实例化得到对象 router = SimpleRouter() # 注册路由 第一个参数:路径(不用带斜杠) 第二个参数:视图类 第三个参数:别名(一般和路径相同) router.register('books', views.BookView, 'books') # 在urlpatterns中注册, path('api/v1/', include(router.urls)), ———————————————————————————— 7.登录接口的代码 代码 1.【views.py】由于需求:查单个需要登录才能访问,所以在查单个中写认证 from rest_framework.generics import ListAPIView, RetrieveAPIView from rest_framework.viewsets import ViewSetMixin from .models import Book from .serializer import BookSerializer from .authenticate import LoginAuth # 查询所有接口(自动生成路由) class BookView(ViewSetMixin, ListAPIView): queryset = Book.objects.all() serializer_class = BookSerializer # 查询单个接口(自动生成路由) class BookDetailView(ViewSetMixin, RetrieveAPIView): queryset = Book.objects.all() serializer_class = BookSerializer # 由于需求是给查询单个加了限制:需要登录才能方法 # 要使用的认证类 authentication_classes = [LoginAuth] 2.app01下新建【authenticate.py】写认证类 from rest_framework.authentication import BaseAuthentication from .models import UserToken from rest_framework.exceptions import AuthenticationFailed # 写一个认证类 class LoginAuth(BaseAuthentication): # 重写authenticate方法 def authenticate(self, request): # 在这里实现登录认证,如果是登录的则继续往后走返回两个值,如果不是则抛异常 """ 看请求中是否携带token来判断是否登录 这里用放在地址栏中提交 用request.query_params.get来获取的伪代码验证 """ token = request.query_params.get('token', None) # 字典能取到就取,取不到就是None if token: # 如果有则取表中查,能查到就登录成功并返回两个值[当前登录用户,token] user_token = UserToken.objects.filter(token=token).first() if user_token: return user_token.user, token else: raise AuthenticationFailed('token认证失败') else: raise AuthenticationFailed('token没传')
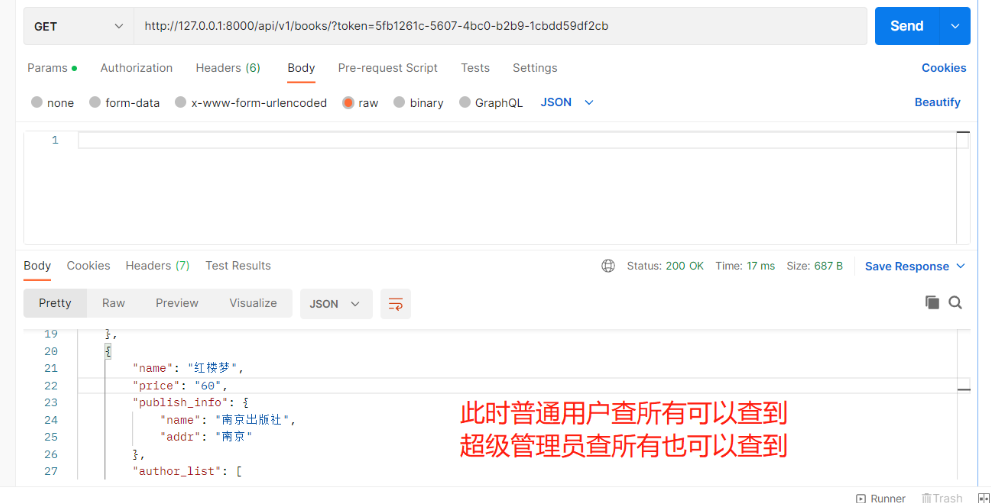
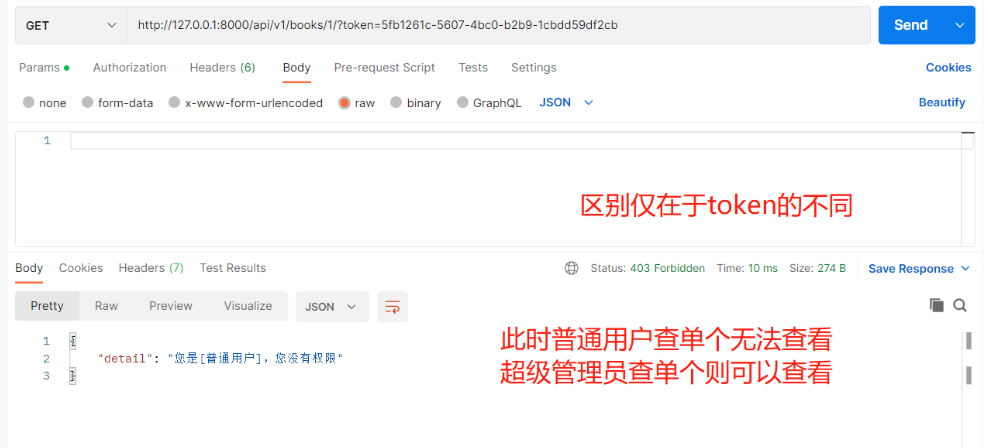
以上就实现了查询所有不需要认证,查询单个需要认证的需求!上述代码只是在写思路,并不是正确的业务逻辑 2.权限 # 权限一般有几种认证方式:(后面会详细了解) ACL:访问控制列表 rbac:基于角色的访问控制(公司内部系统会用) abac:rbac的升级版 添加了属性认证有时候发现即便登录成功了,可有些接口还是不能访问:因为没有权限 401 Unauthorized 未认证 403 Permission Denied 权限被禁止注意:权限是一个字段,在User表中要加入user_type字段来当作用户权限 user_type = models.IntegerField(choices=((1, '超级管理员'), (2, '普通用户')), default=2) # 不要忘记执行表迁移命令 1)使用步骤 1.在app01下新建一个某某.py文件,内部写一个权限类,继承BasePermission from rest_framework.permissions import BasePermission class CommonPermission(BasePermission): 2.重写has_permission方法,在该方法在中实现权限认证#在该方法中request.user就是当前登录用户 3.如有权限,返回True 4.没有权限,返回False,定制返回的中文: self.message='中文'# self.message 是给前端的提示信息 def has_permission(self, request, view): # 在这里实现权限认证,如果有权限return True,如果没有return False if request.user.user_type == 1: return True else: return False 5.局部使用,全局使用,局部禁用 【views.py】 -局部:只在某个视图类中使用#需注意【是当前视图类下管理的所有接口】 class BookDetailView(ViewSetMixin, RetrieveAPIView): permission_classes = [CommonPermission] —————————————————————— 【settings.py】 -全局:全局所有接口都生效#需注意【登录接口不需要!!】所以需要配合局部禁用一起使用 # 额外添加的drf自有配置 REST_FRAMEWORK = { 'DEFAULT_PERMISSION_CLASSES': ['app01.permissions.CommonPermission'], } -局部禁用:# 给登录接口中加局部禁用:当中括号为空则说明里面没有认证 即可实现局部禁用 class BookDetailView(ViewSetMixin, RetrieveAPIView): permission_classes = [] 2)案例需求:查单个和查所有都要登录才能访问 查所有:所有登录用户都能访问 查单个:需要超级管理员才能访问 # 给查单个和查所有都要登录才能访问添加认证 1.【settings.py】中添加全局认证 REST_FRAMEWORK = { 'DEFAULT_AUTHENTICATION_CLASSES': ['app01.authenticate.LoginAuth'] } 2.【views.py】中给登录接口添加局部禁用 class UserView(ViewSet): authentication_classes = [] ... # 查所有:所有登录用户都能访问 查单个:需要超级管理员才能访问 1.【models.py】中给User表添加一个字段用来做权限 user_type = models.IntegerField(choices=((1, '超级管理员'), (2, '普通用户')), default=2) —————————————————————————————— 2.app01下新建【permissions.py】写权限类 from rest_framework.permissions import BasePermission # 写一个权限类 class CommonPermission(BasePermission): # 重写has_permission方法 def has_permission(self, request, view): # 在这里实现权限认证,如果有权限return True,如果没有return False if request.user.user_type == 1: return True else: # 当没权限时给前端一个提示信息 # 如果表模型中用了choice,就可以用get_字段名_display() 拿到choice对应的中文 self.message = '您是[%s],您没有权限' % request.user.get_user_type_display() return False —————————————————————————————— 3.【views.py】给查询单个接口添加局部权限 permission_classes = [CommonPermission]
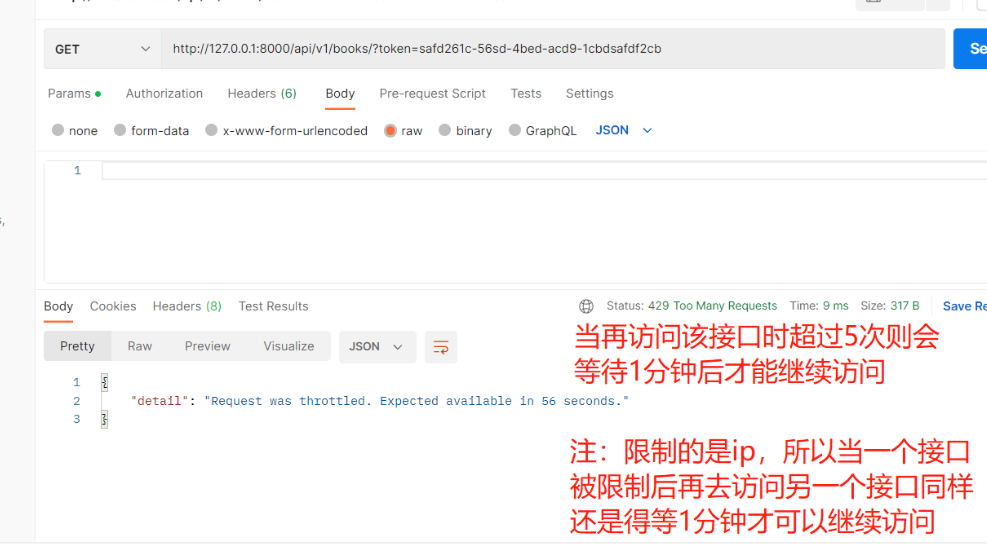
当权限都通过后,我们还可以限制某个接口的访问频率,防止有人恶意攻击网站。一般根据ip来限制 1)使用步骤 1.在app01下新建一个某某.py文件,内部写一个频率类:继承SimpleRateThrottle 2.重写get_cache_key方法,返回什么就以什么做限制。如:返回id,就用id做限制 3.写一个类属性:scope = 'book_5_m', 值随便写,但必须和配置文件对应 from rest_framework.throttling import SimpleRateThrottle class CommonThrottle(SimpleRateThrottle): # 类属性 scope = 'book_5_m' # 重写get_cache_key方法 def get_cache_key(self, request, view): # 该方法返回什么就以什么做频率限制【可返回ip或id】 # 获取客户端id:request.user.pk # 获取客户端的ip:request.META.get('REMOTE_ADDR') return request.META.get('REMOTE_ADDR') 4.配置文件中写 # 5/m:一分钟访问5次 3/h:一小时访问3次 REST_FRAMEWORK = { 'DEFAULT_THROTTLE_RATES': {'book_5_m': '5/m'}, # 3/h 3/s 3/d } 5.局部配置,全局配置,局部禁用 【views.py】 -局部:只在某个视图类中使用#需注意【是当前视图类下管理的所有接口】 class BookDetailView(ViewSetMixin, RetrieveAPIView): throttle_classes = [CommonThrottle] —————————————————————— 【settings.py】 -全局:全局所有接口都生效#需注意【登录接口不需要!!】所以需要配合局部禁用一起使用 # 额外添加的drf自有配置 REST_FRAMEWORK = { 'DEFAULT_THROTTLE_CLASSES': ['app01.throttling.CommonThrottle'], } -局部禁用:# 给登录接口中加局部禁用:当中括号为空则说明里面没有认证 即可实现局部禁用 class BookDetailView(ViewSetMixin, RetrieveAPIView): throttle_classes = [] 2)案例需求:查询所有接口,一分钟只能访问5次 1.app01下新建【throttling.py】写频率类 from rest_framework.throttling import SimpleRateThrottle class CommonThrottle(SimpleRateThrottle): # 类属性 scope = 'book_5_m' # 随便写但是必须和配置文件中对应 # 重写get_cache_key方法 def get_cache_key(self, request, view): # 该方法返回什么就以什么做频率限制【可返回ip或id】 # 获取客户端id:request.user.pk # 获取客户端的ip:request.META.get('REMOTE_ADDR') return request.META.get('REMOTE_ADDR') —————————————————————————————— 2.【settings.py】中给REST_FRAMEWORK = {}里添加以下配置 'DEFAULT_THROTTLE_RATES': {'book_5_m': '5/m'} —————————————————————————————— 3.【views.py】中给要添加频率访问的接口添加频率认证 throttle_classes = [CommonThrottle]
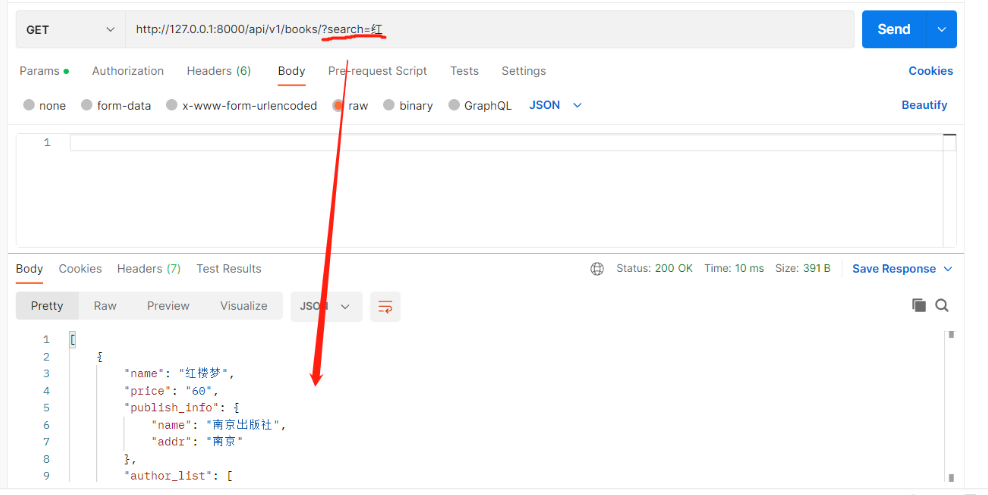
查询所有才涉及到过滤,其他接口都不需要 restful规范中有一条,请求地址中带过滤条件:分页、排序、过滤统称为过滤 1.过滤 1)内置过滤类(模糊匹配) 内置过滤类只能通过search写条件,如果配置了多个过滤字段,是或者的条件 # 必须继承GenericAPIView及其子类才能用这种配置过滤类的方式 from rest_framework.filters import SearchFilter class BookView(ViewSetMixin, ListAPIView): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer # 要使用的过滤类 filter_backends = [SearchFilter] # 配置过滤字段 # search_fields = ['name'] # 可以按名字模糊匹配 search_fields = ['name','price'] # 可以按名字模糊匹配或价格模糊匹配 "如果配置了多个过滤字段,是或者的条件" # 支持的查询方式 http://127.0.0.1:8000/api/v1/books/?search=红 # 如果是按名字和价格匹配,则只要name中或price中有红都能搜出来
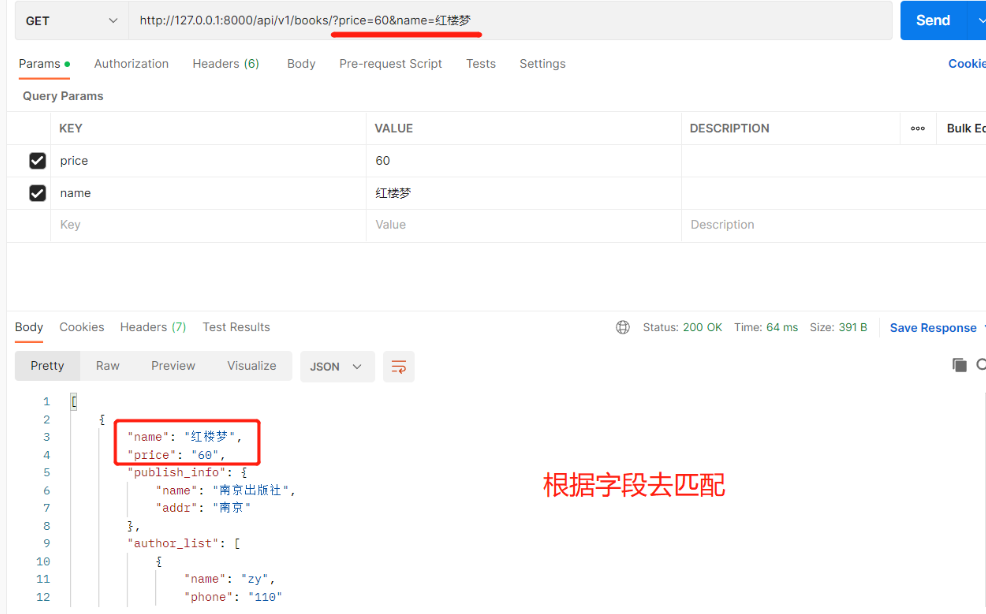
安装:django-filter需注意:会自动把我们的django升级到最新版本,只要重新下载原版本的django即可 from django_filters.rest_framework import DjangoFilterBackend class BookView(ViewSetMixin, ListAPIView): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer # 要使用的过滤类 filter_backends = [DjangoFilterBackend] # 配置过滤字段 filterset_fields = ['name','price']# 支持完整匹配 name=聊斋&price=33 # 支持的查询方式 http://127.0.0.1:8000/api/v1/books/?price=60 http://127.0.0.1:8000/api/v1/books/?price=60&name=红楼梦
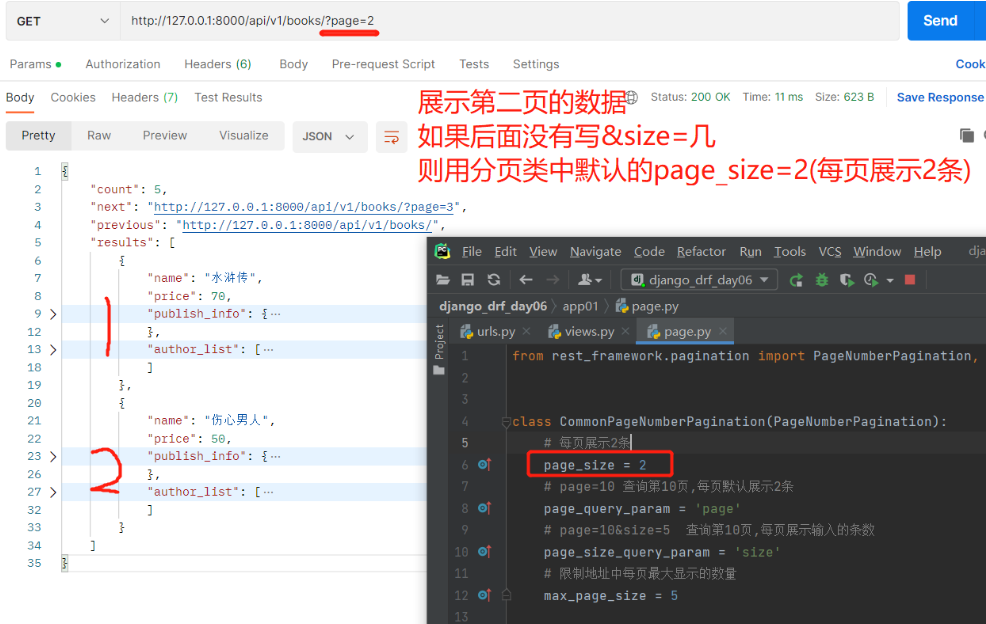
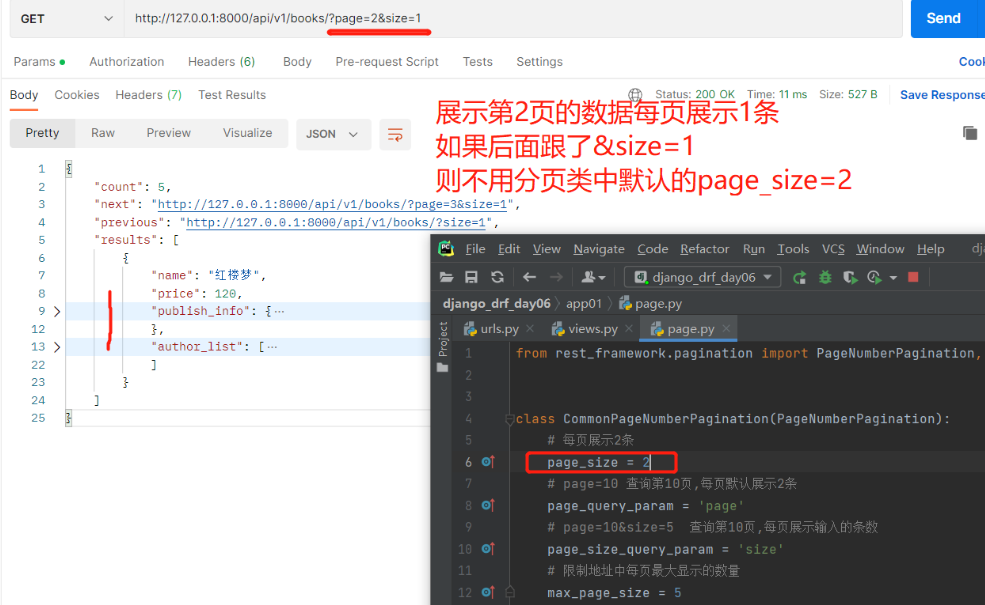
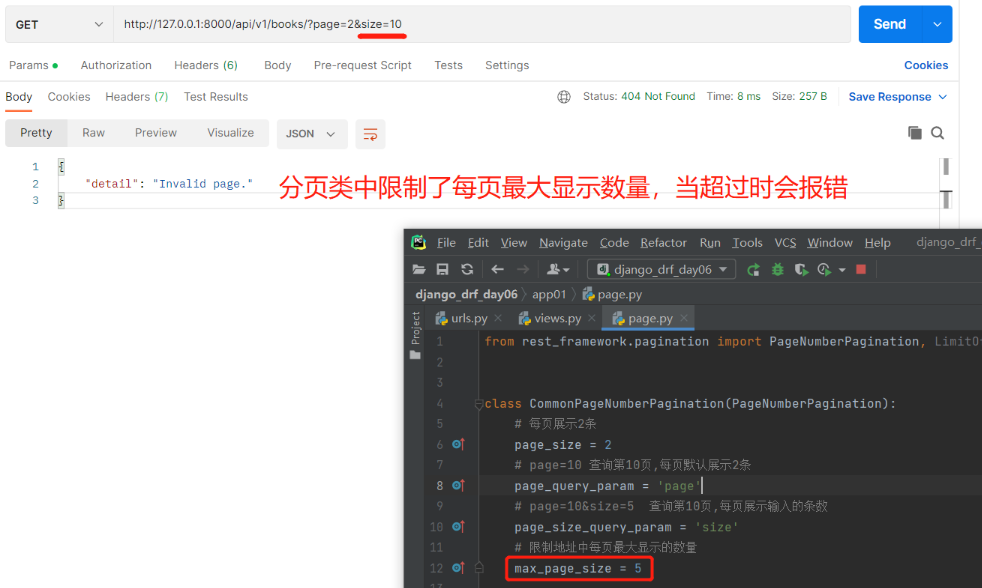
需求:查询价格大于100的所有图书 前端输入:http://127.0.0.1:8000/api/v1/books/?price_gt=100来过滤查询 1.在app01下新建一个myfilter.py文件,内部写一个过滤类,继承BaseFilterBackend重写filter_queryset方法 from rest_framework.filters import BaseFilterBackend class CommonFilter(BaseFilterBackend): def filter_queryset(self, request, queryset, view): # 在内部实现过滤,返回queryset对象就是过滤后的数据 # request.query_params 获取前端url上传的数据,('price_gt', None)有就获取,没有就是None price_gt = request.query_params.get('price_gt', None) # 如果前端传了值且有price_gt if price_gt: # 用queryset.filter过滤数据,大于用__gt,且前端传的是字符串需转整型 res = queryset.filter(price__gt=int(price_gt)) return res else: return queryset 3.配置在视图类上#(只有查所有接口才有过滤) class BookView(ViewSetMixin, ListAPIView): queryset = Book.objects.all() serializer_class = BookSerializer # 要使用的过滤类 filter_backends = [CommonFilter] # 可以定制多个(可加其他过滤条件等),从左往右依次执行 2.排序 1)内置排序 from rest_framework.filters import OrderingFilter # 查询所有,按照价格排序,必须继承GenericAPIView及其子类 class BookView(ViewSetMixin, GenericAPIView, ListModelMixin): queryset = Book.objects.all() serializer_class = BookSerializer # 要使用的排序类 filter_backends = [OrderingFilter,] # 可以定制多个(可加其他过滤条件等),从左往右依次执行 # 配置排序字段 ordering_fields = ['price',] # ordering_fields = ['price','id']# 可加两个值,先按照价格升序排,当价格一样就按id升序排 ———————————————————————————————— # 支持的查询方式 http://127.0.0.1:8000/books/?ordering=-price # 按照price降序 http://127.0.0.1:8000/books/?ordering=price # 按照price升序 # http://127.0.0.1:8000/books/?ordering=price,id # 先按价格升序排,价格一样再按id升序排 3.分页数据库中可能有成千上万条数据,当我们访问某张表的所有数据时数据量会非常大,对服务端的内存压力较大,所以一般我们都会一部分一部分获取数据也就是分页展示 drf内置了三个分页类,这些内置的分页类不能直接使用必须继承并定制一些参数后才能用 from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination PageNumberPagination LimitOffsetPagination CursorPagination 1)基本分页:查几页 每页显示多少条※ 1.app01下新建page.py文件,内部写一个分页类 继承PageNumberPagination,内部定制一些参数 from rest_framework.pagination import PageNumberPagination class CommonPageNumberPagination(PageNumberPagination): # 每页展示2条 page_size = 2 # page=10 查询第10页,每页默认展示2条 page_query_param = 'page' # page=10&size=5 查询第10页,每页展示输入的条数 page_size_query_param = 'size' # 限制地址中每页最大显示的数量 max_page_size = 5 —————————————————————————— 2.【views.py】中给查所有写要使用的分页类 from .page import CommonPageNumberPagination as PageNumberPagination class BookView(ViewSetMixin, ListAPIView): queryset = Book.objects.all() serializer_class = BookSerializer # 要使用的分页类 pagination_class = PageNumberPagination ———————————————————————————— # 支持的查询方式 http://127.0.0.1:8000/api/v1/books/?page=2 http://127.0.0.1:8000/api/v1/books/?page=2&size=1用Postman展示的样式
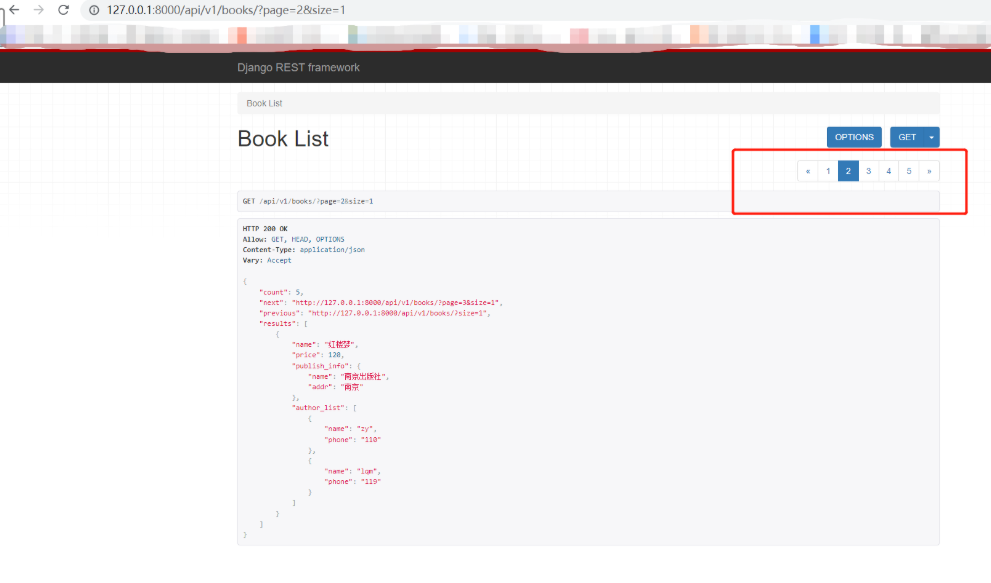
用浏览器展示的样式(会显示一个分页器) 不要忘记在settings中注册'rest_framework'
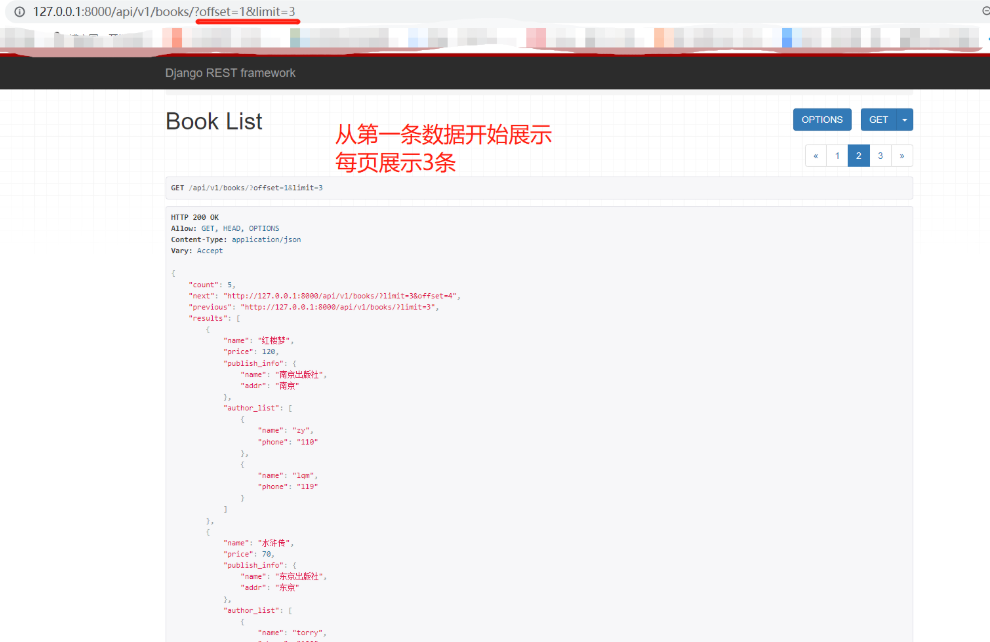
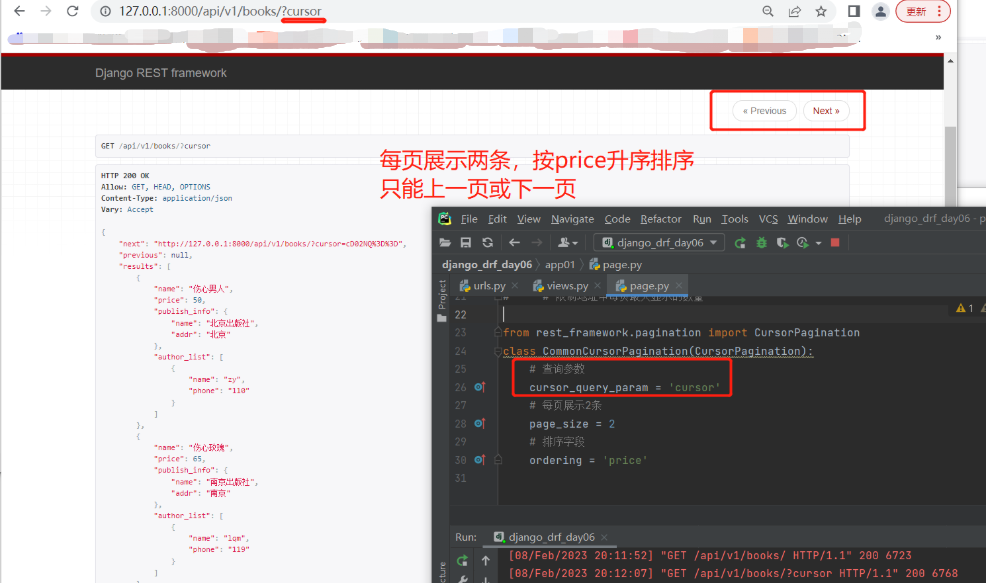
只能上一页或下一页,不能跳到中间但它的效率最高,大数据量分页用这种较好 1.app01下新建page.py文件,内部写一个分页类 继承CursorPagination,内部定制一些参数 from rest_framework.pagination import CursorPagination class CommonCursorPagination(CursorPagination): # 查询参数 cursor_query_param = 'cursor' # 每页展示2条 page_size = 2 # 排序字段 ordering = 'price' —————————————————————————— 2.【views.py】中给查所有写要使用的分页类 from .page import CommonCursorPagination as CursorPagination class BookView(ViewSetMixin, ListAPIView): queryset = Book.objects.all() serializer_class = BookSerializer # 要使用的分页类 pagination_class = CursorPagination ———————————————————————————— # 支持的查询方式 http://127.0.0.1:8000/api/v1/books/?cursor
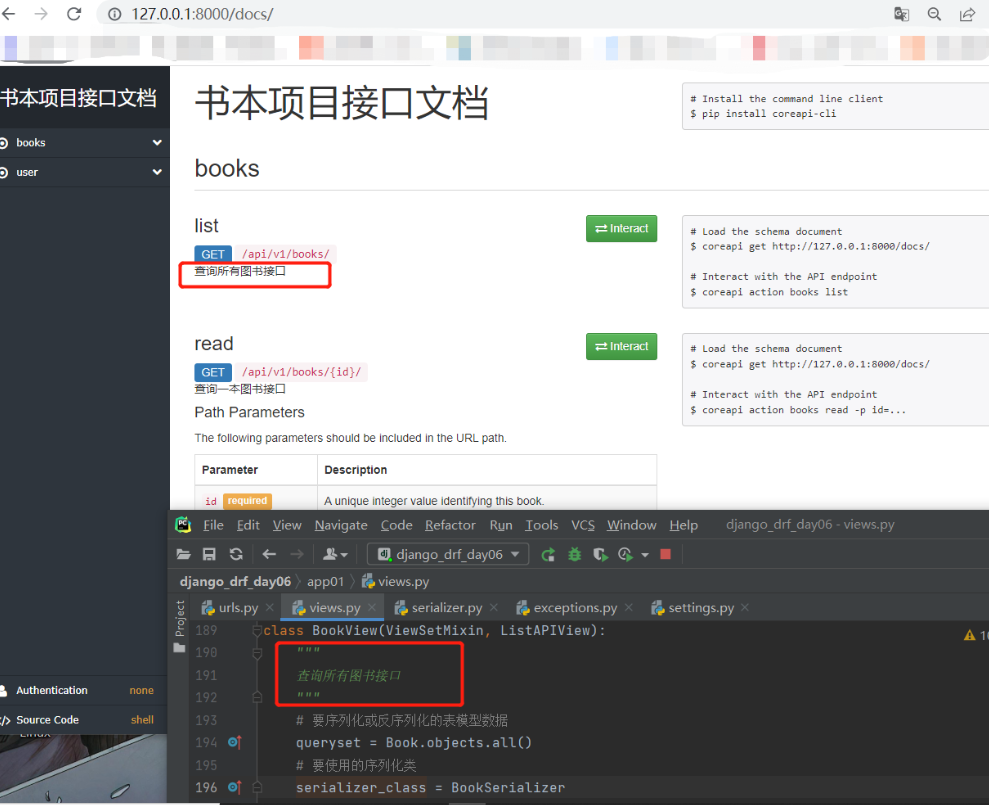
继承了它代码量会很少 # 写一个频率类,继承BaseThrottle重写allow_request方法,在里面实现频率控制 # SimpleRateThrottle---》allow_request def allow_request(self, request, view): # 这里就是通过配置文件和scop取出 频率限制是多少,比如一分钟访问5此 if self.rate is None: return True # 返回了ip,就以ip做限制 self.key = self.get_cache_key(request, view) if self.key is None: return True # 下面的逻辑,跟咱们写的一样 self.history = self.cache.get(self.key, []) self.now = self.timer() while self.history and self.history[-1] = self.num_requests: return self.throttle_failure() return self.throttle_success() # SimpleRateThrottle的init方法 def __init__(self): if not getattr(self, 'rate', None): # self.rate= '5、h' self.rate = self.get_rate() # 5 36000 self.num_requests, self.duration = self.parse_rate(self.rate) # SimpleRateThrottle的get_rate() 方法 def get_rate(self): if not getattr(self, 'scope', None): msg = ("You must set either `.scope` or `.rate` for '%s' throttle" % self.__class__.__name__) raise ImproperlyConfigured(msg) try: # self.scope 是 lqz 字符串 # return '5/h' return self.THROTTLE_RATES[self.scope] except KeyError: msg = "No default throttle rate set for '%s' scope" % self.scope raise ImproperlyConfigured(msg) # SimpleRateThrottle的parse_rate 方法 def parse_rate(self, rate): # '5/h' if rate is None: return (None, None) # num =5 # period= 'hour' num, period = rate.split('/') # num_requests=5 num_requests = int(num) duration = {'s': 1, 'm': 60, 'h': 3600, 'd': 86400}[period[0]] # (5,36000) return (num_requests, duration) 八.全局异常处理读APIView中的dispatch方法时发现:三大认证、视图类的方法如果出了异常会被异常捕获统一处理,然后执行DRF配置文件中的'EXCEPTION_HANDLER': 'rest_framework.views.exception_handler'。 from rest_framework.views import APIView 1.进到APIView源码中找到dispatch方法 def dispatch(self, request, *args, **kwargs): ... try: # 三大认证 self.initial(request, *args, **kwargs) # 视图类的方法 if requesthod.lower() in self.http_method_names: handler = getattr(self, requesthod.lower(), self.http_method_not_allowed) else: handler = self.http_method_not_allowed response = handler(request, *args, **kwargs) # exc就是异常错误对象 except Exception as exc: response = self.handle_exception(exc) self.response = self.finalize_response(request, response, *args, **kwargs) return self.response _______________________________________________ 2.进到except Exception as exc 中的handle_exception里 def handle_exception(self, exc): # drf 内置了一个函数,只要上面过程出了异常就会执行这个函数,这个函数只处理的drf的异常 exception_handler = self.get_exception_handler() context = self.get_exception_handler_context() response = exception_handler(exc, context) if response is None: self.raise_uncaught_exception(exc) response.exception = True return responsedrf 内置了一个函数,只要上面过程出了异常就会执行这个函数,这个函数只处理的drf的异常 1.主动抛的非drf异常 2.程序出错的异常 上述两个异常该函数都不会去处理! 我们的要求是:无论主动抛还是程序运行出错,都要统一返回规定格式>>>能记录日志 # 公司里一般返回的格式: {code:999,'msg':'系统错误,请联系系统管理员'} 1.异常处理操作 1.在app01下新建一个exceptions.py文件,内部写一个处理异常的函数 def common_exception_handler(exc, context): # exc 错误对象 # context:上下文,有view:当前出错的视图类的对象,args和kwargs视图类方法分组出来的参数,request:当次请求的request对象 # 记录日志尽量详细,只要走到这里就要记录日志 ,只有错了才会执行这个函数 print('时间,登录用户id,用户ip,请求方式,请求地址,执行的视图类,错误原因') # 内置的这个异常处理函数,只处理了drf自己的异常(继承了APIException的异常) res = exception_handler(exc, context) if res: # 有值,说明返回了Response 对象,没有值说明返回None # 如果是Response对象说明是drf的异常,已经被处理了, 如果是None表明没有处理,就是非drf的异常 res = Response(data={'code': 888, 'msg': res.data.get('detail', '请联系系统管理员')}) else: # res = Response(data={'code': 999, 'msg': str(exc)}) # 记录日志 res = Response(data={'code': 999, 'msg': '系统错误,请联系系统管理员'}) return res ———————————————————————————————————— 2.在settings.py中配置: REST_FRAMEWORK = { 'EXCEPTION_HANDLER': 'app01.exceptions.common_exception_handler', } 九.接口文档当我们把接口写完后还需要编写接口文档,主要是给前端人看的,告诉对方自己写的接口信息 # 接口文档包含的大致格式: -接口描述 -请求地址 -请求方式 -支持的请求编码格式 -请求参数(get、post、put) -参数类型 -参数是否必填 -参数解释 -返回格式案例 -返回数据字段解释 -错误码 # 接口文档的几种编写方式 1.直接用word或md编写接口文档 2.使用第三方平台编写接口文档# 收费 https://www.showdoc.com.cn/item/index 3.自己利用百度开源的去搭建>>Yapi https://zhuanlan.zhihu.com/p/366025001 4.项目自动生成的>>swagger【官方推荐】、coreapi【简易快捷用法】 ———————————————————————————— # 使用coreapi自动生成接口文档步骤 1.下载:pip3 install coreapi 2.配置路由: from rest_framework.documentation import include_docs_urls urlpatterns = [ path('docs/', include_docs_urls(title='xx项目接口文档')), ] 3.在视图类方法上写注释#(这是什么接口)即可 -可在类上加注释 -也可在类的方法上加注释 -也可在序列化类或表模型字段上加 help_text、required.. 4.配置文件配置 REST_FRAMEWORK = { 'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.coreapi.AutoSchema', } 5.访问地址:http://127.0.0.1:8000/decs
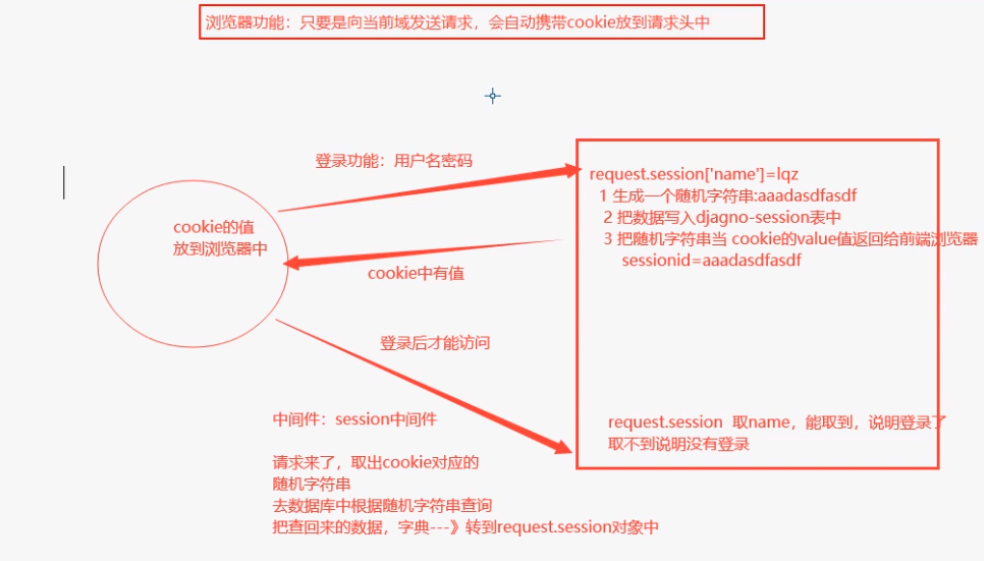
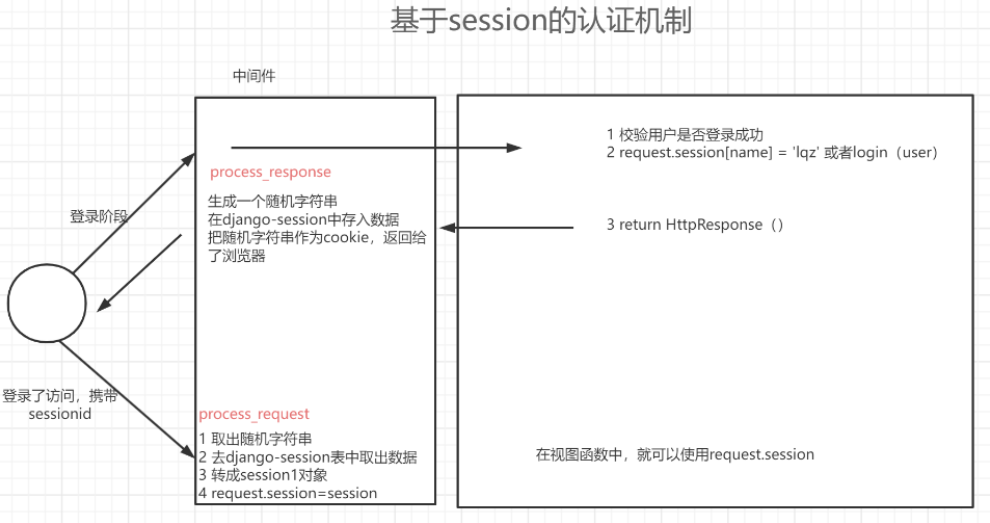
在web1.0年代是没有cookie和session概念的,但是在web2.0年代需要做到会话保持(客户端连续访问,服务端知道是他在访问),于是就出现了cookie。 此时如果只有cookie是不安全的,不能把用户信息存放在客户端,于是又出现了session,但是它有一个问题就是客户端一存我服务端就要保存一条记录,对我服务端的占用较大于是又出现了token token分三部分(头、荷载、签名),头一般放的东西都不太重要,荷载最重要但是不能往里面放密码。把头和荷载用base64编码后再通过某种加密方式加密钥得到第三部分的签名,用.连在一起就得到了token串。 cookie:存在于客户端浏览器的键值对 session:存才于服务端的键值对(可能存放在文件,内存,数据库..) token:头,荷载,签名 参考博客链接:https://www.cnblogs.com/liuqingzheng/p/8990027.html 2.jwt介绍和原理Json web token(JWT),是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准(RFC 7519),该token被设计为紧凑且安全的,特别适用于分布式站点的单点登录(sso)场景,JWT的声明一般被用来在身份提供者和服务者间传递被认证的用户身份信息,以便于从资源服务器获取资源,也可以增加一些额外的其他业务逻辑所必须的声明信息,该token也可直接被用于认证,也可被加密。其实就是前后端认证的机制,也可以说token的web形式认证机制
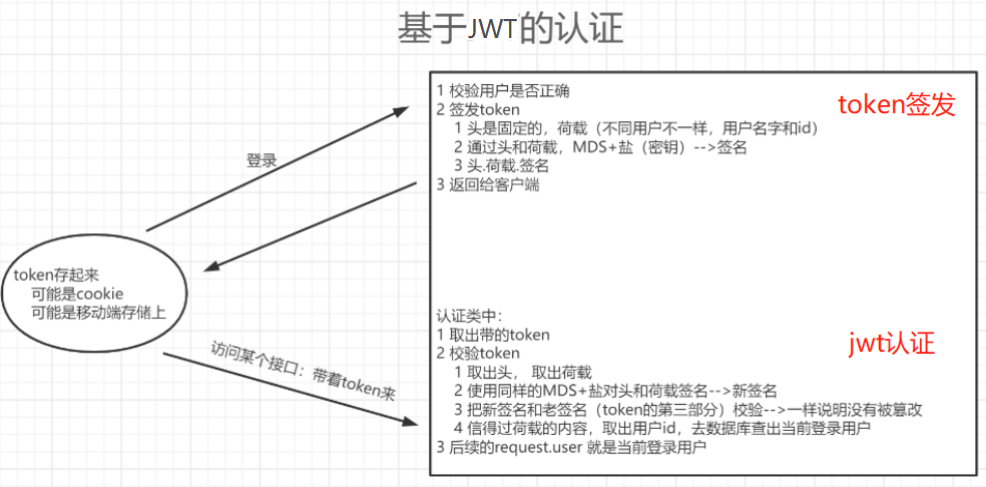
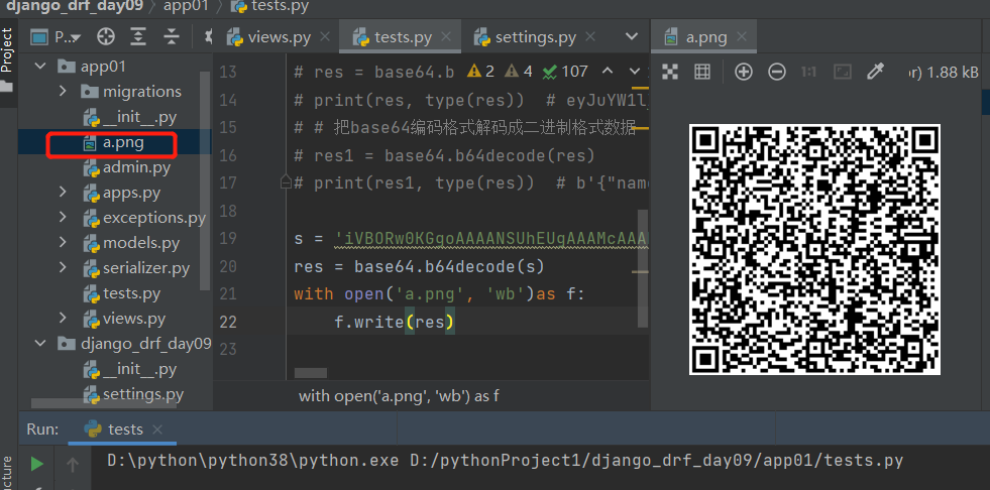
jwt使用流程中最核心的是: 1.签发:登录 2.认证:登陆后才能访问的接口 3.jwt的构成JWT看起来就是一段字符串,由三段信息构成。将这三段信息文本用.连接在一起就构成了JWT: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ这三部分信息分别是头(header)、荷载(payload)、签名(signature) 1.header:头 -typ:声明类型,这里是jwt -alg:声明加密的算法 通常直接用HMAC、SHA256 { 'typ':'JWT', 'alg':'HS256' } 通过base64编码变成了: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9 2.payload:荷载 -user_id -username -exp:jwt的过期时间,这个过期时间必须大于签发时间 -iat:jwt的签发时间 { "user_id":1, "username":"zy" "exp": "1676026014", "email":"[email protected]" } 通过base64编码变成了: eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9 3.signature:签名 把'头'和'荷载'通过base64编码后用加密方式和密钥变成了: TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ ___________________________________________ # 再把上述三个用.连接成字符串,再通过头中声明的加密方式加盐secret组合加密,就构成了jwt的第三部分注:secret是保存在服务端的(加密方式+盐),jwt的签发生成也是在服务端的,secret就是用来进行jwt的签发和jwt的验证,所以它就是你服务端的私钥,任何场景都不应该泄露出去。一但客户端得知这个secret,就意味着客户端可以自我签发jwt了 补充:base64编码与解码base64可以把字符串编码成base64的编码格式(大小写字母、数字、=),同理也可以把base64编码的字符串解码成原来的格式 注意:base64编码后,字符长度一定是4的倍数,如果不是就用 【=】补齐, = 不是数据里的数据 应用场景: 1.jwt中使用 2.网络中传输字符串就可以用base64编码 3.网络中传输图片也可以使用base64编码 base64编码 import json import base64 d1 = {'name': 'zy', 'age': 18} json_str_d1 = json.dumps(d1) print(json_str_d1, type(json_str_d1)) # {"name": "zy", "age": 18} # 把上述json格式字符串转成二进制格式后再用base64编码 res = base64.b64encode(json_str_d1.encode('utf-8')) print(res, type(res)) # eyJuYW1lIjogInp5IiwgImFnZSI6IDE4fQ==base64解码 # 把base64编码格式解码成二进制格式数据 res1 = base64.b64decode(res) print(res1, type(res1)) # b'{"name": "zy", "age": 18}'将网上base64编码的图片保存到本地 # 以12306登录上的二维码为例: base64,后面的都是 s = 'xxxxx' res = base64.b64decode(s) with open('a.png','wb')as f: f.write(res)
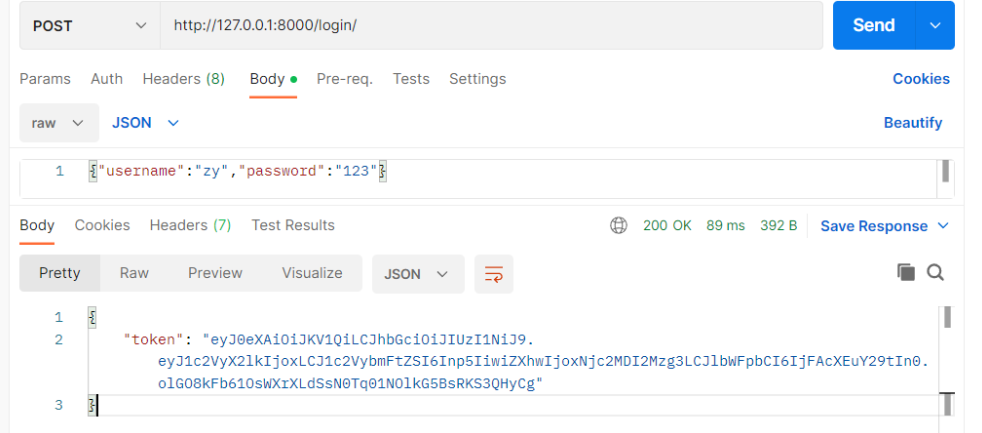
django+drf平台开发jwt有两个模块 -djangorestframework-jwt # 一直可以用 -djangorestframework-simplejwt # 公司用的多 自行了解 -也可以自己封装jwt的签发和认证 # 安装:pip3 install djangorestframework-jwt数据准备 # 数据准备: 【models.py】 class Book(models.Model): book_name = models.CharField(max_length=32) book_price = models.CharField(max_length=32) ———————————————————————— 【views.py】 from rest_framework.viewsets import ViewSetMixin from rest_framework.generics import ListAPIView from .models import Book from .serializer import BookSerializer class BookView(ViewSetMixin, ListAPIView): # 要序列化或反序列化的表模型数据 queryset = Book.objects.all() # 要使用的序列化类 serializer_class = BookSerializer ———————————————————————— 【serializer.py】 from rest_framework import serializers from .models import Book class BookSerializer(serializers.ModelSerializer): # 跟表关联 class Meta: model = Book # 序列化Book表中的哪些字段和方法 fields = ['book_name', 'book_price'] # 定制序列化和反序列化的额外规则 extra_kwargs = { 'book_name': {'max_length': 8}, } ———————————————————————— 【urls.py】 from app01 import views from django.urls import include from rest_framework.routers import SimpleRouter # 实例化得到对象 router = SimpleRouter() # 注册路由 router.register('books', views.BookView, 'books') urlpatterns = [ path('api/v1/', include(router.urls)), ] 1)快速使用 # 使用步骤 :【基于auth的User表签发token】 1.迁移表(因为它默认用auth的user表签发token) # -makemigrations # -migrate 2.创建超级用户(auth的user表中要有记录) # -createsuperuser 3.不需要写登录接口(如果使用auth的user表作为用户表,可以快速签发token) 4.签发(登录):只需要在路由中配置即可(帮我们提前写好登录接口了) from rest_framework_jwt.views import obtain_jwt_token urlpatterns = [ path('login/', obtain_jwt_token), ] 5.向http://127.0.0.1:8000/login/发送post请求,携带username和password
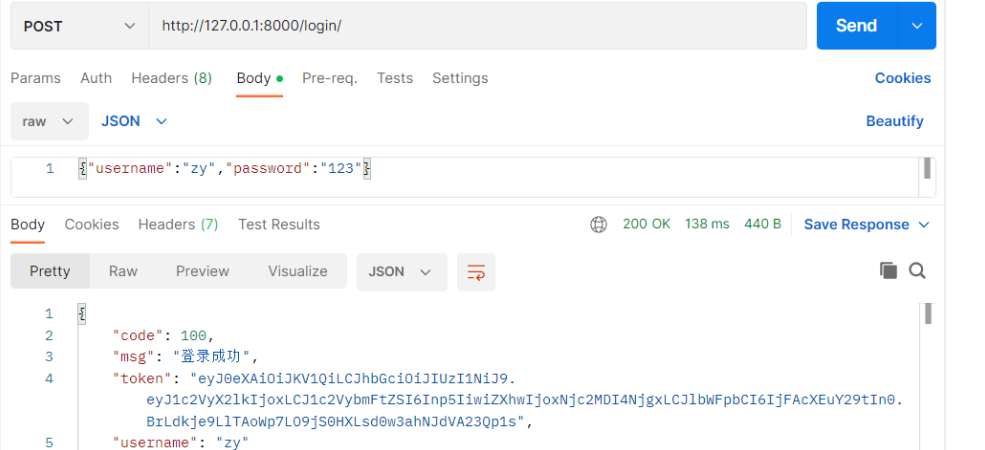
今后如果是基于auth的User表签发token都可以不用自己写登录接口,但是登录接口的返回格式是固定返回token的!不符合公司规范,所以需要定制一个返回格式。 2)定制返回格式写的该函数返回什么,前端就可以看到什么 # 期望的返回格式: {'code':100,'msg':'登陆成功','token':xxxxxx,'username':用户名} # 使用步骤 1.app01下新建utils.py文件,写个函数# 函数名必须叫这个 def jwt_response_payload_handler(token, user=None, request=None): return { 'code': 100, 'msg': '登录成功', 'token': token, 'username': user.username # 假如有用户头像也可以一起返回 # 'icon':user.icon } 2.在settings.py中配置 JWT_AUTH = { 'JWT_RESPONSE_PAYLOAD_HANDLER':'app01.utils.jwt_response_payload_handler', }
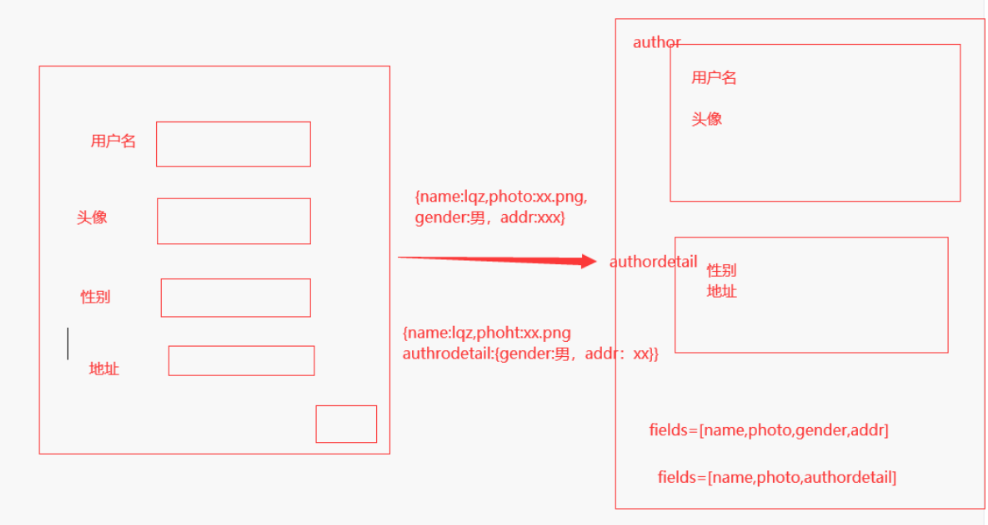
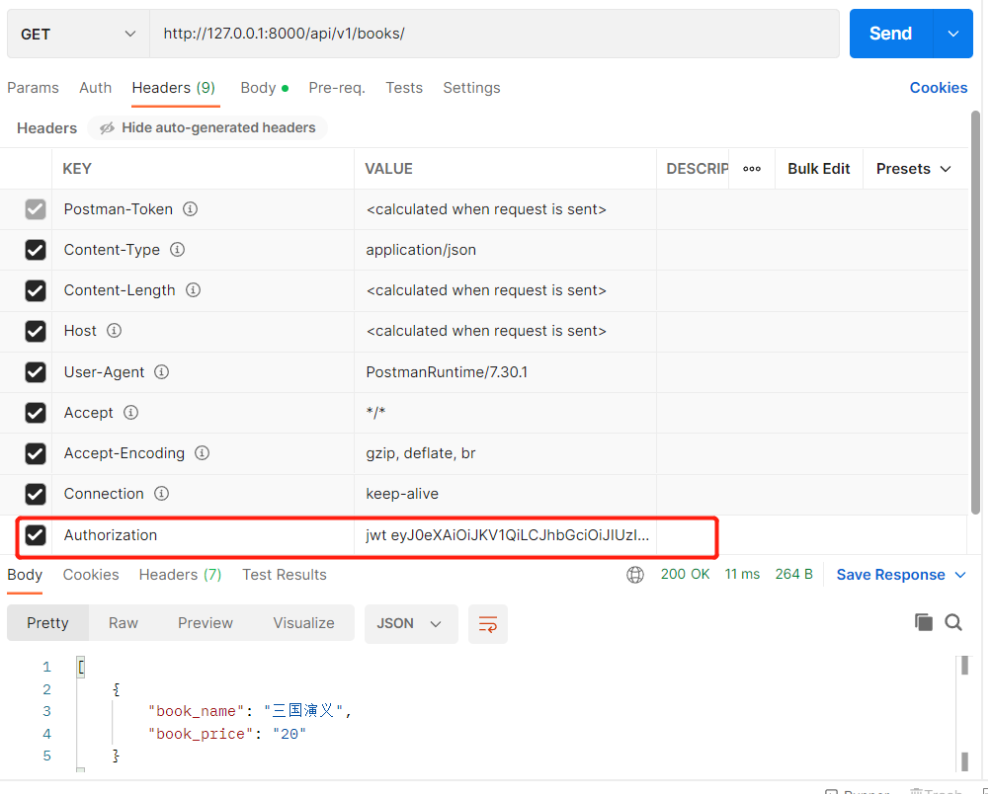
限制某个接口只有登录后才能访问 必须加一个认证类和权限类才可以 # 局部配置 在视图类中# 加一个【认证类】,一个【权限类】 from rest_framework_jwt.authentication import JSONWebTokenAuthentication from rest_framework.permissions import IsAuthenticated class BookView(ViewSetMixin, ListAPIView): # jwt提供的认证类(传了token就给你认证,不传就不认证) authentication_classes = [JSONWebTokenAuthentication] # drf提供的权限类(登录的用户有权限,没登录就没权限) permission_classes = [IsAuthenticated] ... —————————————————————— '也可以配置全局,不过要给局部禁用' 4)jwt快速使用验证 # 必须在请求头中带以下值: key值:Authorization value值: jwt 有效的token值 # 请求中要携带用户名和密码
from rest_framwork_jwt.views import obtain_jwt_token, refresh_jwt_token, verity_jwt_token obtain_jwt_token:签发token refresh_jwt_token:刷新token verity_jwt_token:验证token 1)签发(登录)本质就是登录接口-->校验用户是否正确,如果正确签发token,如果不正确,返回错误 # 自动生成登录接口,当路由匹配成功执行obtain_jwt_token(当post请求来时---》执行父类的post方法) from rest_framework_jwt.views import obtain_jwt_token path('login/',obtain_jwt_token) # ObtainJSONWebToken的post方法 继承APIView def post(self, request, *args, **kwargs): # 实例化得到序列化类 serializer = self.get_serializer(data=request.data) # 当执行了is_valid()就会做校验:字段自己,局部钩子,全局钩子 if serializer.is_valid(): # user:当前登录用户 user = serializer.object.get('user') or request.user # 签发的token token = serializer.object.get('token') # 构造返回格式(定制返回格式!) response_data = jwt_response_payload_handler(token, user, request) response = Response(response_data) #最终返回了定制的返回格式 return response # 如果没有校验通过就返回错误信息 return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST) # 那么到底是如何得到user?如何签发的token?----》在序列化类的全局钩子中得到的user和签发的token -JSONWebTokenSerializer全局钩子>>validate #attr:前端传入,校验过后的数据---》{"username":"zy","password":"123"} class JSONWebTokenSerializer(Serializer): def validate(self, attrs): credentials = { self.username_field: attrs.get(self.username_field), # 其实就是username:attrs.get('username') # 'username':attrs.get('username') 'password': attrs.get('password') } if all(credentials.values()): # auth 模块,authenticate 可以传入用户名密码如果用户存在,就返回用户对象,如果不存就是None # 正确的用户 user = authenticate(**credentials) if user: # 校验用户是否是活跃用户,如果禁用了就下不能登录成功 if not user.is_active: msg = _('User account is disabled.') raise serializers.ValidationError(msg) # 荷载:通过user得到荷载 {id,name,email,exp} payload = jwt_payload_handler(user) return { # jwt_encode_handler通过荷载得到token串 'token': jwt_encode_handler(payload), 'user': user } else: # 根据用户名和密码查不到用户 msg = _('Unable to log in with provided credentials.') raise serializers.ValidationError(msg) else: # 用户名和密码不传、传多了都不行 msg = _('Must include "{username_field}" and "password".') msg = msg.format(username_field=self.username_field) raise serializers.ValidationError(msg) # 重点: '签发token': jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER 1 通过user得到荷载:payload = jwt_payload_handler(user) 2 通过荷载得到token:token = jwt_encode_handler(payload) # 了解: # 翻译函数,只要做了国际化,放的英文会翻译成该国语言(配置文件配置的) —————————— 1.【settings.py】 LANGUAGE_CODE = 'zh-hans' TIME_ZONE = 'Asia/Shanghai' 2. 不要忘记注册drf —————————— from django.utils.translation import ugettext as _ msg = _('Unable to log in with provided credentials.')数据准备 #【models.py】 class UserInfo(models.Model): username = models.CharField(max_length=32) password = models.CharField(max_length=32)写自定义登录接口,且自动生成路由 #【views.py】 # 在配置文件中复制出需要的jwt_payload_handler和jwt_encode_handler from rest_framework_jwt.settings import api_settings jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER from rest_framework.viewsets import ViewSet from rest_framework.decorators import action from .models import UserInfo from rest_framework.response import Response # 由于登录功能不用序列化,所以继承ViewSet即可 class UserView(ViewSet): # 添加自动生成路由装饰器 @action(methods=['POST'], detail=False) def login(self, request, *args, **kwargs): # 获取前端传过来的用户名和密码 username = request.data.get('username') password = request.data.get('password') # 获取登录成功后的该用户数据 user = UserInfo.objects.filter(username=username, password=password).first() # 看是否有值判断密码是否正确 if user: # 登录成功签发token # 1.通过user可以得到荷载 payload = jwt_payload_handler(user) payload = jwt_payload_handler(user) # 2.通过荷载得到token token = jwt_encode_handler(payload) return Response({'code': 100, 'msg': '登陆成功', 'token': token}) else: return Response({'code': 101, 'msg': '用户名或密码错误'}) #【urls.py】 from rest_framework_jwt.views import obtain_jwt_token from rest_framework.routers import SimpleRouter from app01.views import UserView router = SimpleRouter() # # 127.0.0.1:8000/user/login/ router.register('user', UserView, 'user') urlpatterns = [ path('login/', obtain_jwt_token), ] urlpatterns += router.urls之前公司里做项目要使用权限快速搭建后台管理,会使用djagno的admin直接搭建,但是django的admin界面不好看于是就出现了第三方的美化 # 第三方的美化: -【xadmin】:现在作者已经弃坑了(bug太多)#基于bootstrap+jq写的 -【simpleui】:界面更好看#基于vue写的 # 现阶段,一般前后端分离比较多:基于django+vue写 -急需一种带权限的前后端分离的快速开发框架 -django-vue-admin -自己写Simpleui官方文档: https://simpleui.72wo.com/docs/simpleui/doc.html#介绍 1)使用步骤 # 1 安装 pip install django-simpleui # 2 在app中注册:记得放在最上面 INSTALLED_APPS = [ 'simpleui', ... ]此时访问http://127.0.0.1:8000/admin/登录管理员账号密码后即可发现页面变了 此时快速生成一个图书管理系统 #【models.pu】 class UserInfo(models.Model): username = models.CharField(max_length=32) password = models.CharField(max_length=32) class Book(models.Model): nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32, verbose_name='作者名') price = models.DecimalField(max_digits=5, decimal_places=2) publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE) authors = models.ManyToManyField(to='Author') def __str__(self): return self.name class Author(models.Model): nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) age = models.CharField(max_length=32) author_detail = models.OneToOneField(to='AuthorDetail', unique=True, on_delete=models.CASCADE) class AuthorDetail(models.Model): nid = models.AutoField(primary_key=True) phone = models.BigIntegerField() addr = models.CharField(max_length=32) class Publish(models.Model): nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) """ 不要忘记做数据库迁移命令 """ 在【apps.py】中添加verbose_name可把admin后台中的app01改成想要的名字 verbose_name = '图书管理系统'24 # 3 调整左侧导航栏----》在【settings.py中】 -menu_display对应menus name -如果是项目的app,就menus写app -菜单可以多级,一般咱们内部app,都是一级 -可以增加除咱们app外的其它链接---》如果是外部链接直接写地址,如果是内部链接就跟之前前后端混合项目一样的写法:咱们的案例---》show 的路由 import time SIMPLEUI_CONFIG = { 'system_keep': False, 'menu_display': ['图书管理', '权限认证', '张红测试'], # 开启排序和过滤功能, 不填此字段为默认排序和全部显示, 空列表[] 为全部不显示. 'dynamic': True, # 设置是否开启动态菜单, 默认为False. 如果开启, 则会在每次用户登陆时动态展示菜单内容 'menus': [ { 'name': '图书管理', 'app': 'app01', 'icon': 'fas fa-code', 'models': [ { 'name': '图书', 'icon': 'fa fa-user', 'url': 'app01/book/' }, { 'name': '出版社', 'icon': 'fa fa-user', 'url': 'app01/publisssh/' }, { 'name': '作者', 'icon': 'fa fa-user', 'url': 'app01/author/' }, { 'name': '作者详情', 'icon': 'fa fa-user', 'url': 'app01/authordetail/' }, ] }, { 'app': 'auth', 'name': '权限认证', 'icon': 'fas fa-user-shield', 'models': [ { 'name': '用户', 'icon': 'fa fa-user', 'url': 'auth/user/' }, { 'name': '组', 'icon': 'fa fa-user', 'url': 'auth/group/' }, ] }, { 'name': '张红测试', 'icon': 'fa fa-file', 'models': [ { 'name': 'Baidu', 'icon': 'far fa-surprise', # 第三级菜单 , 'models': [ { 'name': '爱奇艺', 'url': 'https://www.iqiyi.com/dianshiju/' # 第四级就不支持了,element只支持了3级 }, { 'name': '百度问答', 'icon': 'far fa-surprise', 'url': 'https://zhidao.baidu.com/' } ] }, { 'name': '大屏展示', 'url': '/show/', 'icon': 'fab fa-github' }] } ] } # 4 内部app,图书管理系统某个链接要展示的字段---》在admin.py 中----》自定义按钮 @admin.register(Book) class BookAdmin(admin.ModelAdmin): list_display = ('nid', 'name', 'price', 'publish_date', 'publish') # 增加自定义按钮 actions = ['custom_button'] def custom_button(self, request, queryset): print(queryset) custom_button.confirm = '你是否执意要点击这个按钮?' # 显示的文本,与django admin一致 custom_button.short_description = '测试按钮' # icon,参考element-ui icon与https://fontawesome.com # custom_button.icon = 'fas fa-audio-description' # # 指定element-ui的按钮类型,参考https://element.eleme.cn/#/zh-CN/component/button custom_button.type = 'danger' # # 给按钮追加自定义的颜色 # custom_button.style = 'color:black;' # 5 app名字显示中文,字段名字显示中文 -新增,查看修改展示中文,在表模型的字段上加:verbose_name='图书名字',help_text='这里填图书名' -app名字中文:apps.py---》verbose_name = '图书管理系统' # 6 其它配置项 SIMPLEUI_LOGIN_PARTICLES = False #登录页面动态效果 SIMPLEUI_LOGO = 'https://avatars2.githubusercontent.com/u/13655483?s=60&v=4'#图标替换 SIMPLEUI_HOME_INFO = False #首页右侧github提示 SIMPLEUI_HOME_QUICK = False #快捷操作 SIMPLEUI_HOME_ACTION = False # 动作 2)大屏显示在国内的Gitee上搜模板下载出来 , # 监控大屏展示 -https://search.gitee.com/?skin=rec&type=repository&q=%E5%B1%95%E7%A4%BA%E5%A4%A7%E5%B1%8F -就是前后端混合项目,只需要把js,css,图片对应好就可以了 十二.权限控制(acl、rbac) # 公司内部项目 -rbac:是基于角色的访问控制(Role-Based Access Control )在 RBAC 中,权限与角色相关联,用户通过成为适当角色的成员而得到这些角色的权限。这就极大地简化了权限的管理。这样管理都是层级相互依赖的,权限赋予给角色,而把角色又赋予用户,这样的权限设计很清楚,管理起来很方便 -用户表:用户和角色多对多关系, -角色表 -一个角色可能有多个权限----》 -开发角色:拉取代码,上传代码 -财务角色:开工资,招人,开除人 - -权限表:角色和权限是多多多 -拉取代码 -上传代码 -部署项目 -开工资 -招人 -开除人 - -通过5张表完成rbac控制:用户表,角色表,权限表, 用户角色中间表, 角色权限中间表 -如果某个人,属于财务角色,单只想要拉取代码权限,不要上传代码权限 -通过6张表:django的admin----》后台管理就是使用这套权限认证 用户表, 角色表, 权限表, 用户角色中间表, 角色权限中间表 用户和权限中间表 # 互联网项目 -acl:Access Control List 访问控制列表,权限放在列表中 -权限:权限表----》 发视频,评论,开直播 -用户表:用户和权限是一对多 张三:[发视频,] 李四:[发视频,评论,开直播] # 演示了 django-admin 的权限控制 -授予lqz 某个组 -单独授予权限 # django -auth--6张表 auth_user 用户表 auth_group 角色表,组表 auth_permission 权限表 ----------- auth_user_groups 用户和角色中间表 auth_group_permissions 角色和权限中间表 ------------- auth_user_user_permissions 用户和权限中间表 # java:若依 # go :gin-vue-admin # python :django-vue-admin 十三.补充 1.django里auth的user表 密码是加密的,就算是同样的密码 密文也不一样 -每次加密都会随机生成一个盐 把盐拼在加密后的串中 # 比如 pbkdf2_sha256$260000$B9ZRmPFpWb3H4kdDDmgYA9$CM3Q/ZfYyXzxwvjZ+HOcdovaJS7681kDsW77hr5fo5o= 明文:lqz12345 盐:B9ZRmPFpWb3H4kdDDmgYA9 当用户来登录时因为用户名知道,所以就取出数据库中用户名对应的密钥,把密钥中的盐取出来再结合之前的加密方法把明文和盐加密,如果得到的结果和后面一样则登录成功 2.django的auth的user生成密文密码使用下面的模块中的函数去做的,当想实现一样的加密就可以导入该函数去做 from django.contrib.auth.hashers import make_password res = make_password('zy123') print(res) # pbkdf2_sha256$150000$RjzYbDTWBe0D$3WfQXhTc+hRmPeBH6Fgecryx5c5XLjO7T5NFpbeCOD0= '验证是check_password' 3.用户表的密码忘了怎么办???新增一个用户,把它的密码复制过去 4.双token认证用户正在app或者应用中操作 token突然过期,此时用户不得不返回登陆界面,重新进行一次登录,这种体验性不好,于是引入双token校验机制 实现原理:首次登陆时服务端返回两个token ,accessToken和refreshToken,accessToken过期时间比较短,refreshToken时间较长,且每次使用后会刷新,每次刷新后的refreshToken都是不同 refreshToken假设7天,accessToken过期时间5分钟 以后带着accessToken访问就好了,校验也是accessToken 当accessToken过期了,校验refreshToken,然后在生成一个accessToken 当refreshToken过期以后,refreshToken与accessToken一起过期的机率比较小,如果真的同时失效了,那就重新登录一次。 正常使用accessToken即可,如果accessToken过期了,重新发请求,携带refreshToken过来,能正常返回,并且这次响应中又带了acessToken |

【本文地址】