| 【深度学习文本分类实践】BERT+Attention+神经网络模型 | 您所在的位置:网站首页 › bert模型参数配置 › 【深度学习文本分类实践】BERT+Attention+神经网络模型 |
【深度学习文本分类实践】BERT+Attention+神经网络模型
【深度学习文本分类实践】BERT+Attention+神经网络模型
 Charzous
分类:机器学习
发布时间 2021.12.06阅读数 4604 评论数 0
本文目录
Charzous
分类:机器学习
发布时间 2021.12.06阅读数 4604 评论数 0
本文目录
 1 项目概述
1 项目概述
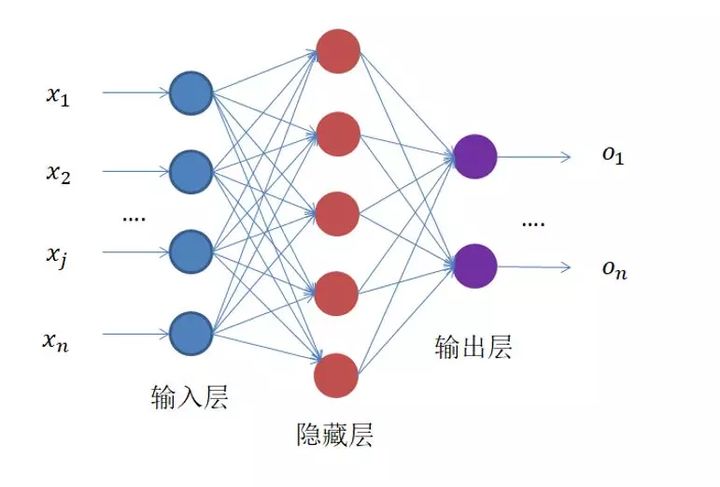
这个小项目是关于文本分类的,文本分类作为机器学习、深度学习和自然语言处理(NLP)中的重要课题,也是最基础的应用,但是在这些领域中应用十分广泛,也可以作为许多AI任务的第一个基础步骤。比如目标检测:分类可以通过文本信息进行过滤判断是否为目标(0或1标签),缩小范围,再进一步通过图像等维度的信息确定。 接下来,这篇文章将总结的是文本分类的一个应用,属于二分类问题,检测新报道闻或文本描述是否是关于体育信息的内容。当然,这只是一个使用案例,对于检测其他关于分类的问题都是可以举一反三的。 2 开发环境IDE: PyCharm Community Python 3.6 tensorflow 1.14 其他配置如有需要,在下面会指出。 3 模型和算法这个项目使用深度学习框架,具体是BERT预训练模型、全连接神经网络、Attention注意力机制。 3.1 BERT预训练模型BERT全称是Bidirectional-Encoder-Representations-from-Transformers。看来这么长一个名字,会有一种复杂的感觉,确实BERT模型不是一下子就能理解的。 早在2019年,BERT就已经由Google AI提出,当时公布出来引起一片狂潮,其中发表的论文也是非常详细的介绍BERT的何去何从,有兴趣可以看看原论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》 。 这里我们也无需深究其实现原理,只需要知道它的应用场景。NLP领域的许多任务,直到现在,一些使用BERT作为预训练模型都达到前所未有的效果,可见BERT的强大。Google BERT预训练模型在深度学习、NLP领域的应用已经十分广泛了,在文本分类任务达到很好的效果。相比传统的词嵌入Word2vec、Golve,使用BERT预训练得到的效果有更好地提升。 3.2 全连接神经网络各种神经网络都是基于全连接神经网络出发的,比如CNN、RNN、LSTM,最基础的原理都是由反向传播而来。其结构简化如下图。
注意力模型(Attention Model)已经成为神经网络中的一个重要概念,在人工智能(AI)领域,注意力已成为神经网络结构的重要组成部分,并在自然语言处理、统计学习、语音和计算机等领域有着大量的应用。 对于注意力的理解,可以类比我们通常所说的注意力:听课要集中注意力、注意这个知识点,等等。 所谓注意力模型就是,通过允许模型动态地关注有助于执行手头任务的输入的某些部分,将这种相关性概念结合起来。 4 数据集数据集如下图,共有2000多条数据,由文本和标签组词,文本是一段描述性信息,标签是0或1,体育信息标记1,非体育信息标记0.
这里是二分类问题,但训练样本可能包含其他标签,所以进行简单的预处理,去掉label大于1的,并将文本和标签进行分离。 5 搭建模型 5.1 加载BERT配置首先需要下载BERT预训练的模型,具体可参考这篇文章BERT预训练模型简单应用,里面写的很详细。
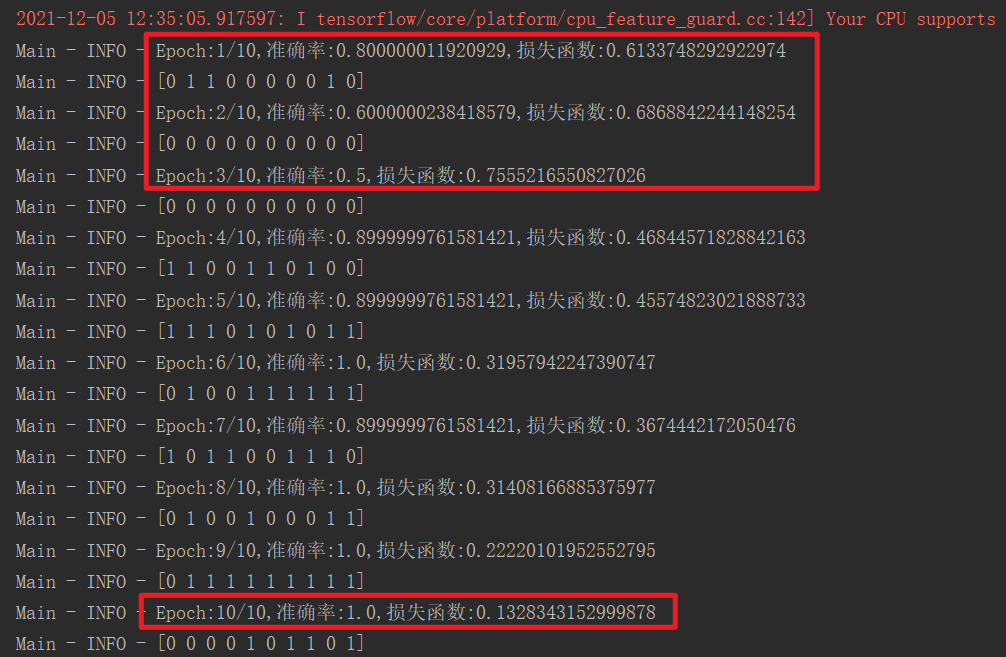
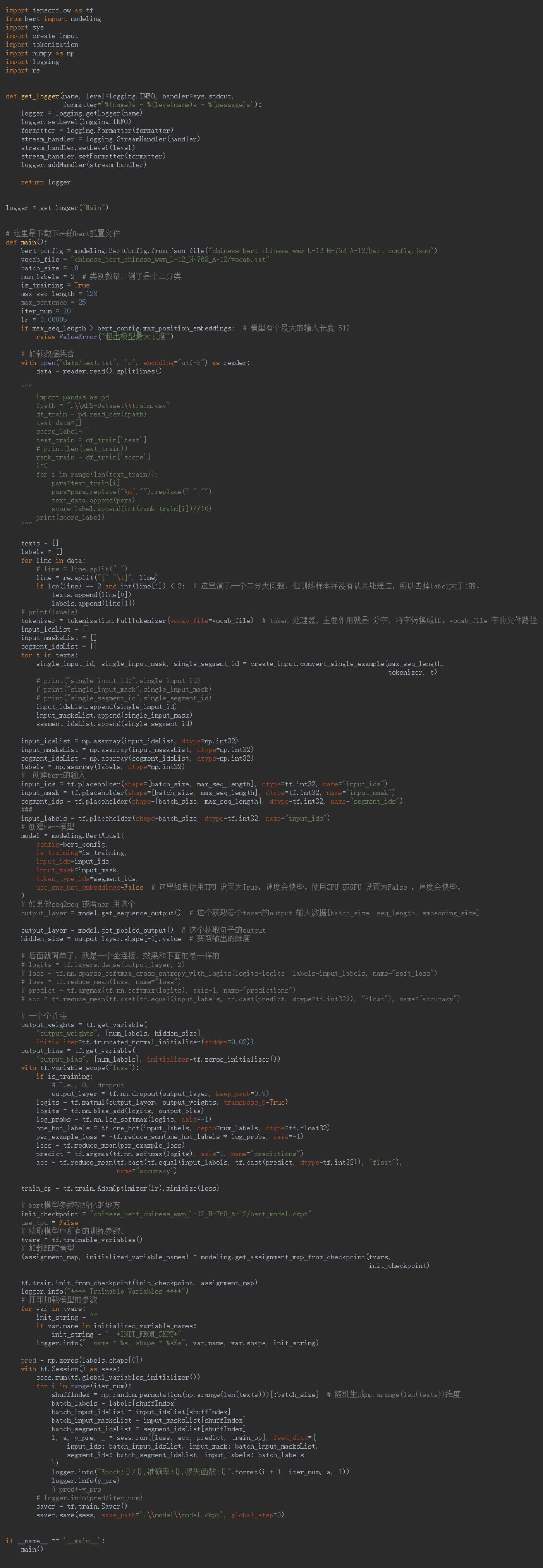
创建BERT模型主要是将数据转化为BERT输入的格式,然后配置一下BERT的信息,把搭建BERT搭建起来,就是相当于以前使用Word2vec的词嵌入层一样。 5.3 搭建全连接神经网络 # 一个全连接 output_weights = tf.get_variable( "output_weights", [num_labels, hidden_size], initializer=tf.truncated_normal_initializer(stddev=0.02)) output_bias = tf.get_variable( "output_bias", [num_labels], initializer=tf.zeros_initializer()) with tf.variable_scope("loss"): if is_training: output_layer = tf.nn.dropout(output_layer, keep_prob=0.9) logits = tf.matmul(output_layer, output_weights, transpose_b=True) logits = tf.nn.bias_add(logits, output_bias) log_probs = tf.nn.log_softmax(logits, axis=-1) one_hot_labels = tf.one_hot(input_labels, depth=num_labels, dtype=tf.float32) per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1) loss = tf.reduce_mean(per_example_loss) predict = tf.argmax(tf.nn.softmax(logits), axis=1, name="predictions") acc = tf.reduce_mean(tf.cast(tf.equal(input_labels, tf.cast(predict, dtype=tf.int32)), "float"), name="accuracy") train_op = tf.train.AdamOptimizer(lr).minimize(loss)#优化器这一层就是搭建神经网络,作用是神经网络对数据进行训练,计算loss、预测结果、计算准确率都在这里完成,然后这里使用Adam优化器,来最小化loss。 5.4 搭建模型 # bert模型参数初始化的地方 init_checkpoint = "chinese_bert_chinese_wwm_L-12_H-768_A-12/bert_model.ckpt" use_tpu = False # 获取模型中所有的训练参数。 tvars = tf.trainable_variables() # 加载BERT模型 (assignment_map, initialized_variable_names) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint) tf.train.init_from_checkpoint(init_checkpoint, assignment_map) logger.info("**** Trainable Variables ****") # 打印加载模型的参数 for var in tvars: init_string = "" if var.name in initialized_variable_names: init_string = ", *INIT_FROM_CKPT*" logger.info(" name = %s, shape = %s%s", var.name, var.shape, init_string) pred = np.zeros(labels.shape[0]) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(iter_num): shuffIndex = np.random.permutation(np.arange(len(texts)))[:batch_size] # 随机生成np.arange(len(texts))维度 batch_labels = labels[shuffIndex] batch_input_idsList = input_idsList[shuffIndex] batch_input_masksList = input_masksList[shuffIndex] batch_segment_idsList = segment_idsList[shuffIndex] l, a, y_pre, _ = sess.run([loss, acc, predict, train_op], feed_dict={ input_ids: batch_input_idsList, input_mask: batch_input_masksList, segment_ids: batch_segment_idsList, input_labels: batch_labels }) logger.info("Epoch:{}/{},准确率:{},损失函数:{}".format(i + 1, iter_num, a, l)) logger.info(y_pre)这一步骤就完成了所有网络层的拼接,从数据输入经过BERT预训练,得到转换后的信息,在输入到全连接神经网络,最后输出层得到结果。 这里可以将模型保存下来: saver = tf.train.Saver() saver.save(sess, save_path='.\\model\\model.ckpt', global_step=0)然后就是main函数,开启我们的训练,看看分类结果怎么样。 if __name__ == '__main__': main() 6 结果训练的参数可以自行配置。 batch_size = 10 num_labels = 2 # 类别数量,二分类 is_training = True max_seq_length = 128 max_sentence = 25 iter_num = 10 lr = 0.00005我使用了batch_size = 10,根据电脑性能可以调整,性能好可以提高每个批次的训练数据。然后训练轮数是iter_num,这里进行10轮训练,结果如下:
可以看到效果真的不错,正确率可以达到90%以上,当然更多实验还需要进行验证。 本文首发古月居博客平台,如果觉得不错欢迎三连,点赞收藏关注,一起加油进步!原创作者:Charzous. 附录 1 部分日志信息
原创文章作者:Charzous。如若转载,请注明出处:古月居 http://www.guyuehome.com/36112 打赏 0 点赞 1 收藏 1 分享 微信 微博 QQ 图片 上一篇:实战:基于机器学习模型的二手车交易价格预测 下一篇:BERT预训练模型简单应用(中文句子向量相关性分析) |



【本文地址】