| abaqus命令行基础 | 您所在的位置:网站首页 › bat文件在哪里运行 › abaqus命令行基础 |
abaqus命令行基础
|
1.abaqus命令行基础
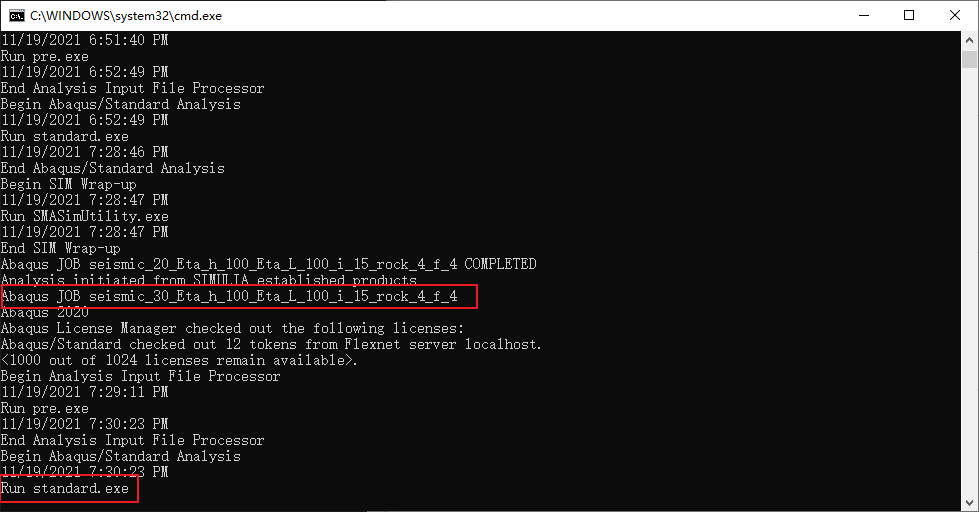
使用 abaqus 时,如果需要进行参数分析,就需要生成大量的模型,这时一般会使用python文件定义函数进行批量生成并计算。 如果已经生成了计算文件(*.inp文件),那么就可以直接在命令行进行求解,abaqus支持命令行计算,计算格式一般如下: abaqus job=job-name cpus=n int 这里的 job-name 是与要计算的 inp 文件同名的文件名(但不包含.inp后缀),这将默认创建一个名为 job-name 的任务并提交计算。cpus=n 是指定计算时使用的 cpu 的核心数。int 是指 interactive ,即abaqus在计算时会在命令行窗口打印一些信息供用户了解abaqus现在在干嘛。如下所示:
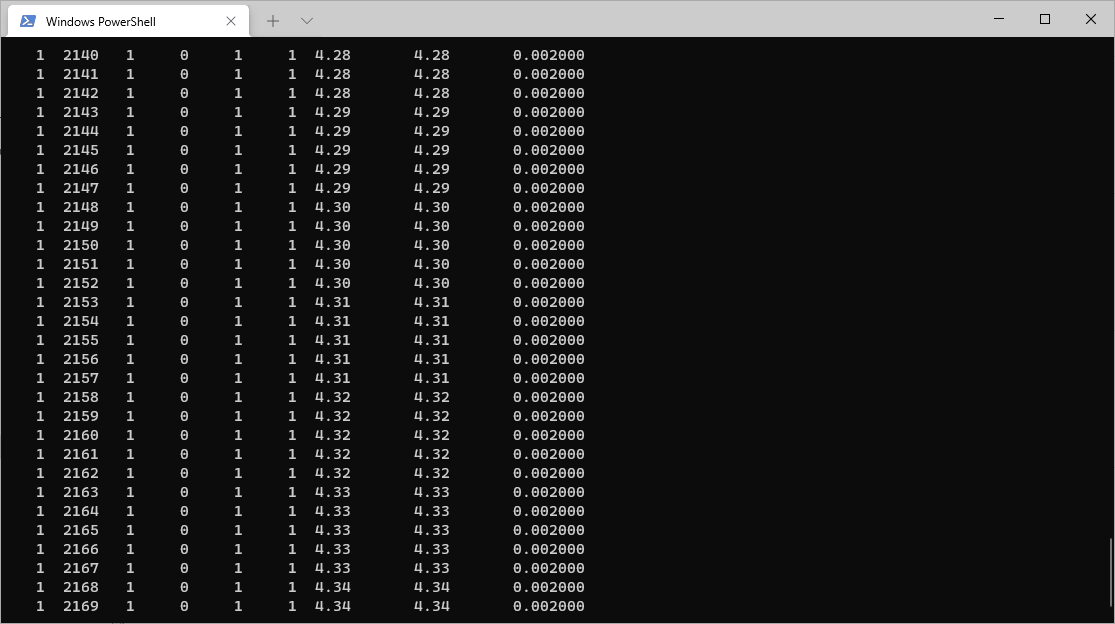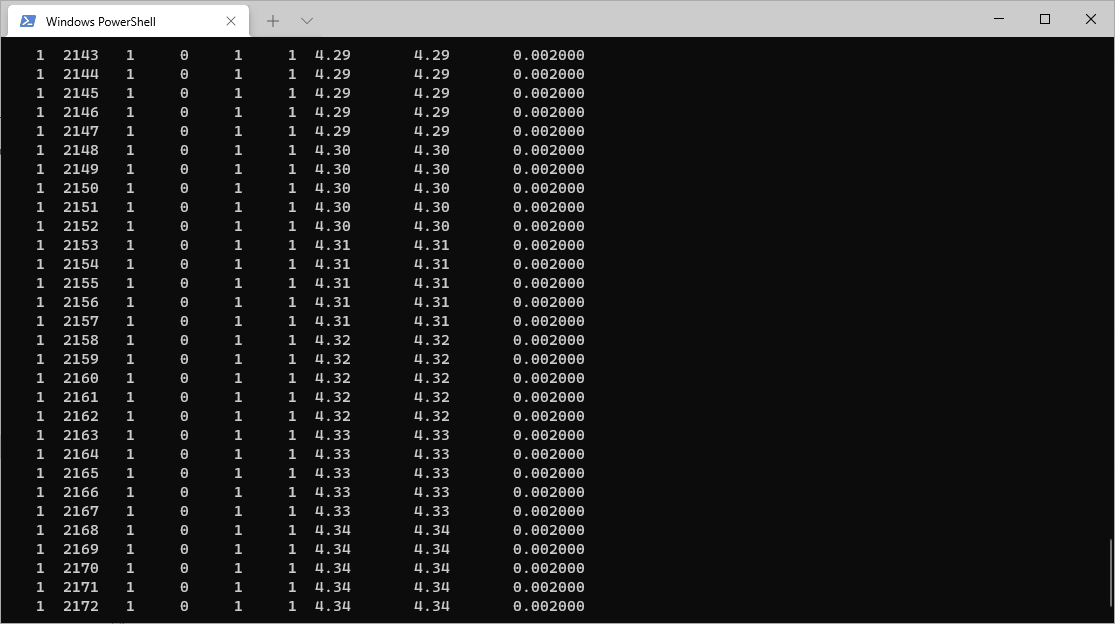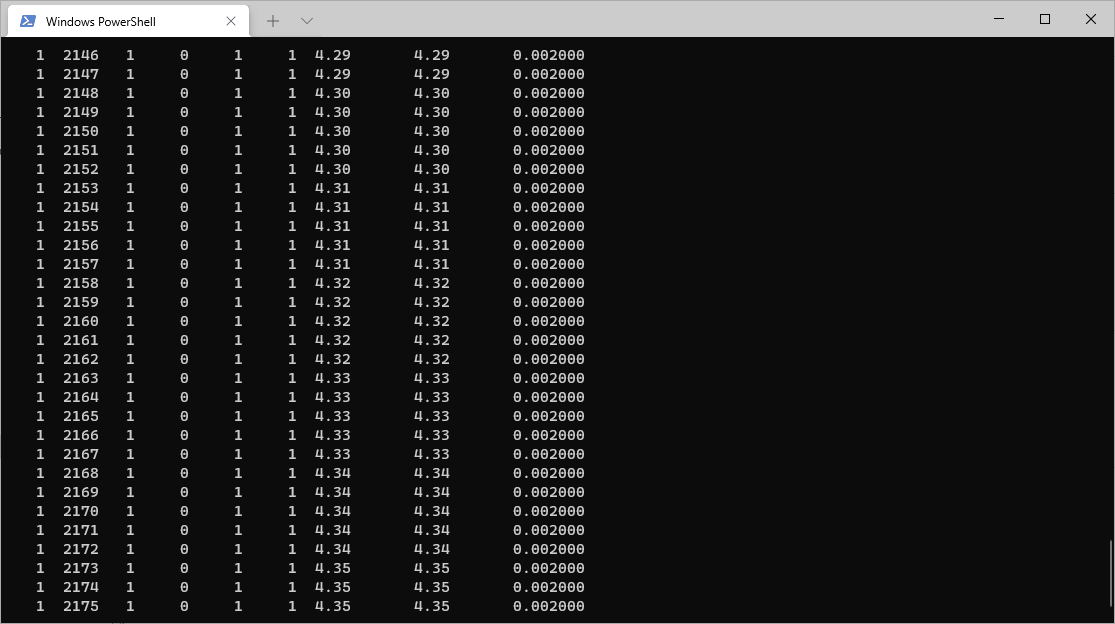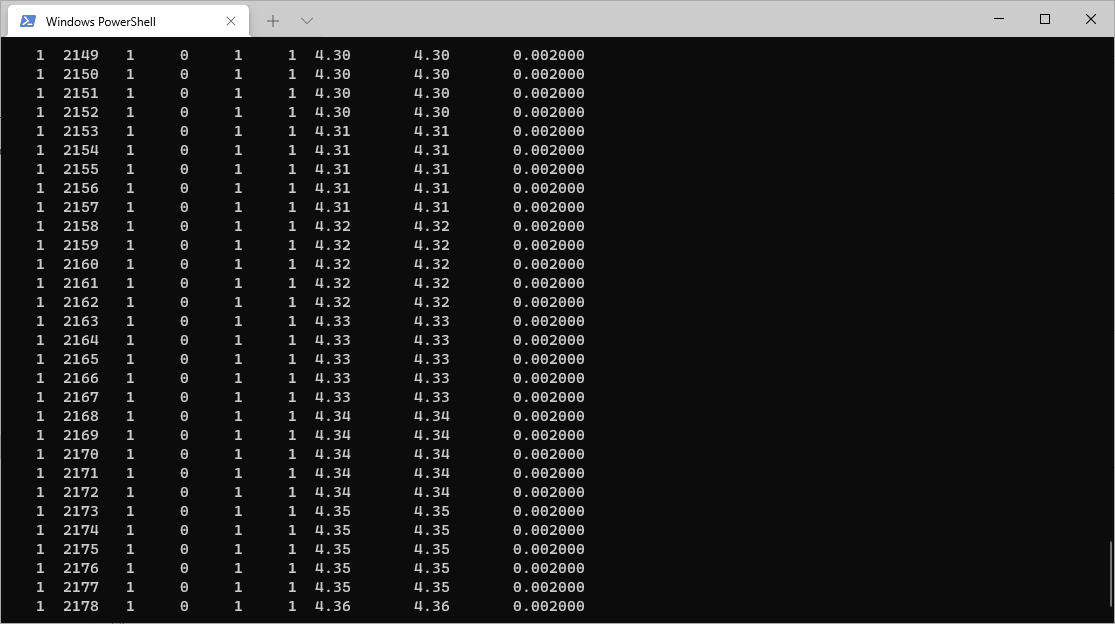
如果想指定任务名称,则可以使用 input 关键字指定输入文件,再用 job 关键字指定任务名称,如下: abaqus input=inpFileName.inp job=job-name cpus=n int 在遇到已经存在的任务时,abaqus会询问是否覆盖先前的 job,如果不想被询问直接覆盖先前的任务,可以在上述命令结尾加上 ask=off 更多关键字及更详细的命令: abaqus job =job-name [analysis | datacheck | parametercheck | continue | convert = { select | odb | state | all } | recover | syntaxcheck | information = { environment | local | memory | release | support | system | all } ] [input = input-file] [user = { source-file | object-file } ] [uniquelibs] [oldjob = oldjob-name] [fil = { append | new }] [globalmodel = { results file-name | ODB output database file-name | SIM database file-name }] [cpus = number-of-cpus] [parallel = { domain | loop }] [domains = number-of-domains] [dynamic_load_balancing = { on | off } ] [mp_mode = { mpi | threads }] [threads_per_mpi_process = number of threads per mpi process] [standard_parallel = { all | solver } ] [gpus = number-of-gpgpus] [memory = memory-size] [interactive | background | queue [= queue-name] [after time] ] [double = { explicit | both | off |constraint } ] [scratch = scratch-dir] [output_precision = { single | full } ] [resultsformat = { odb | sim | both } ] [port = co-simulation port-number] [host = co-simulation hostname] [csedirector = Co-Simulation Engine director host: port-number] [timeout = co-simulation timeout value in seconds] [unconnected_regions = { yes | no } ] [noFlexBody] [license_type = { token | credit } ] 2.abaqus批量计算(2.1节和2.2节批量计算的内容参考了http://www.feaworks.org的部分网页) 在命令行求解有一个好处就是可以实现不同job的连续计算,不用人守着每次等上一个任务计算完成再手动提交下一个任务。 2.1 dos批处理 情况1:不同inp文件位于同一文件夹下假设该文件夹里inp文件分别为:job-1.inp, job-2.inp, job-3.inp… 在该文件夹下新建记事本(.txt)文档,将其后缀修改为 .bat 文件,在 bat 文件中输入以下内容,运行该文件实现批处理: call abaqus job=job-1 cpus=10 int call abaqus job=job-2 cpus=10 int call abaqus job=job-3 cpus=10 int .... pausepause 以上命令加上 int 后,会让abaqus在当前计算完成后,才会转入下一个模型的计算。如果要实现不同job同时计算,去掉 int 即可 call abaqus job=job-1.inp cpus=10 call abaqus job=job-2.inp cpus=10 call abaqus job=job-3.inp cpus=10 .... pause最后的pause 命令会让 cmd 窗口等待用户输入,否则在执行完最后一条指令后 cmd 窗口将直接关闭,如果计算中出了问题,显示在 cmd 窗口的信息我们也看不到了,所以建议使用此命令。 情况2:不同inp文件位于不同文件夹下假设在以下路径有以下文件: D:\temp\A\job-1.inp D:\temp\B\job-2.inp D:\temp\C\job-3.inp 则可以每次进入一个文件夹,再调用abaqus进行计算,命令如下: cd D:\temp\A call abaqus job=job-1.inp cpus=10 int cd D:\temp\B call abaqus job=job-2.inp cpus=10 int cd D:\temp\C call abaqus job=job-3.inp cpus=10 int pause将上述命令保存为.bat 文件,双击运行即可 情况3:计算完成后自动关机有时候我们会希望计算机在计算完成后自动关机,可以通过在上述命令的最后面添加关机命令: shutdown -s -f -t 30-s 关闭本地计算机 -f 强制关闭计算机 -t xx 将用于系统关闭的定时器设置为 xx 秒,例如上面的设置是 30秒。 2.2 Python实现Python语言可以实现ABAQUS前后处理模块的二次开发,同时也可以采用Python实现ABAQUS所用功能,这里采用Python实现不同job的连续计算。 实现job批处理的Python基本代码: # 导入所需的模块和常量 from abaqusConstants import* import job # 使用job-1.inp文件提交job-1的计算任务,numCpus=2设置cpus数,numDomains=2设置线程数 mdb.JobFromInputFile(name='job-1',inputFileName='job-1.inp',numCpus=2,numDomains=2) # 提交计算任务 mdb.jobs['job-1'].submit() # 中断python文件的执行,等待计算任务的完成。 # 在这里waitForCompletion相当于dos批处理下的参数interactive mdb.jobs['job-1'].waitForCompletion() mdb.JobFromInputFile(name='job-2',inputFileName='job-2.inp',numCpus=2,numDomains=2) mdb.jobs['job-2'].submit() mdb.jobs['job-2'].waitForCompletion() # 导入其他模块 import os,time,sys # 实现自动关机 o="c:\windows\system32\shutdown -s -f -t 60" os.system(o)将上面的python文件保存为 run.py ,进入run.py所在目录,打开cmd窗口输入以下命令即可运行批处理文件: abaqus cae noGUI=run.py 其他问题(以下内容参考自https://zhuanlan.zhihu.com/p/149086691) 之前在网上查到的ABAQUS inp文件任务批量提交方法,如用批处理命令或利用ABAQUS内置Python环境提交,有一定局限性,比如如果批量提交的任务中,某个任务由于计算不收敛而终止,会造成整个提交队列终止,而不能继续进行。 本程序利用Python subprocess模块并行提交任务,任务间不会互相干扰,即使某个任务报错或不收敛,不会影响整个队列。 import subprocess import time import os task_list=[] for volfrac in [0.1,0.2,0.3,0.4,0.5,0.6]: #循环生成包含不同参数的文件名列表 for R in [4,5,6]: for num in range(1,11): #["Tension_x","Tension_y","Shear"] for bc in ["Tension_x","Tension_y","Shear"]: task_list.append([volfrac,R,num,bc]) i=0 for volfrac,R,num,bc in task_list: file_name="{}_{}_{}_{}.inp".format(volfrac,R,num,bc)#inp文件名 job_name="Job-{}_{}_{}_{}".format(int(volfrac*100),R,num,bc)#任务名 #通过命令行提交任务 subprocess.Popen('abaqus job={} input={} cpus=2 int ask_delete=OFF'.format(job_name,file_name),shell=True) print("{} submitted.".format(job_name)) i=i+1 if i==10: i=0 print("Waiting...") time.sleep(180)#防止一次提交过多电脑崩溃或license用尽,所以通过sleep等待任务结束 print("Finished")在inp文件所在目录下,运行此Python程序,即可批量提交任务。 3.abaqus命令行显示计算求解进程虽然命令中有 int 参数,但是abaqus只能显示简单的信息,如第一张图中所示。 在进行多步求解时,例如隐式多步或者显式计算时,我们有时想看到目前计算到哪一步了,但是abaqus自身无法在命令行打印出这些信息。 可以使用一种曲线救国的方法,即在任务文件夹中读取与任务同名的 .sta 文件,并实时显示。注意,以下命令只在 Windows PowerShell 中有效: Get-Content .\job-name.sta -Tail 10 -Wait这将会自动读取 job-name.sta 的最后10行内容。随着abaqus的计算, .sta 文件也会不断写入内容,而这条命令(因为有**-Wait**参数)也会不断读取最新的内容并刷新显示,如下图所示(这里是一个隐式计算求解):
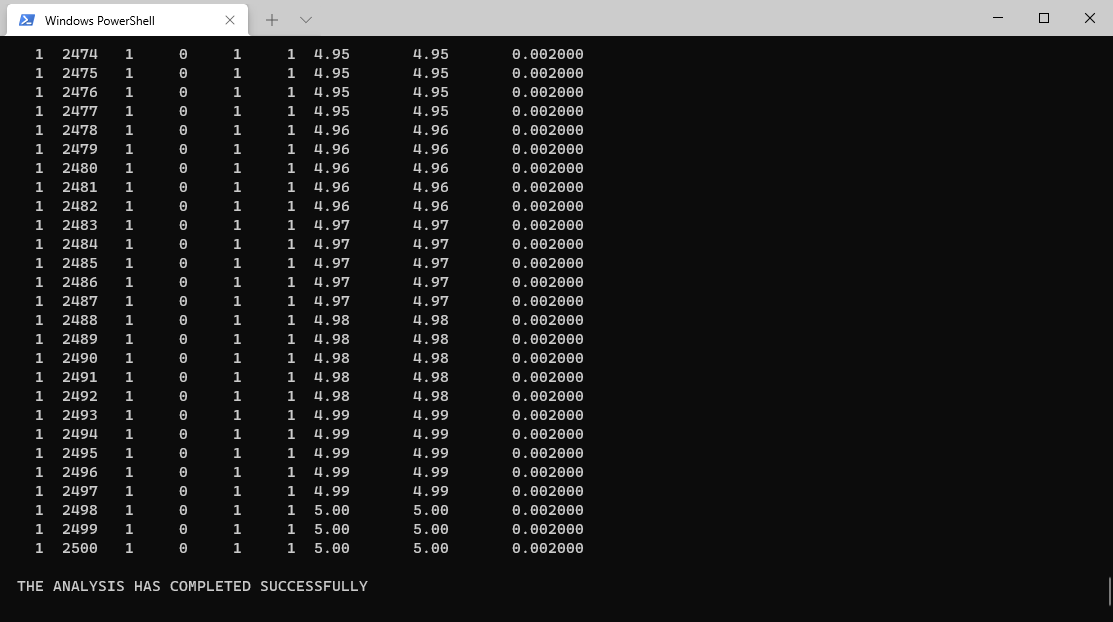
最后计算完成的视图如下:
如果要在 cmd 窗口实现以上内容,则需要以下命令: powershell -nologo "& "Get-Content -Wait job-name.sta -Tail 10"实际上还是调用 Windows PowerShell 执行 Get-Content 程序。因此,前提是你的电脑有 Windows PowerShell 较新版。如果没有 Windows PowerShell 或者其版本太低可能会提示找不到 Get-Content 程序。 |
【本文地址】