| 自然语言处理pyltp(词性标注、命名实体识别、角色标注等) | 您所在的位置:网站首页 › argument的词性 › 自然语言处理pyltp(词性标注、命名实体识别、角色标注等) |
自然语言处理pyltp(词性标注、命名实体识别、角色标注等)
|
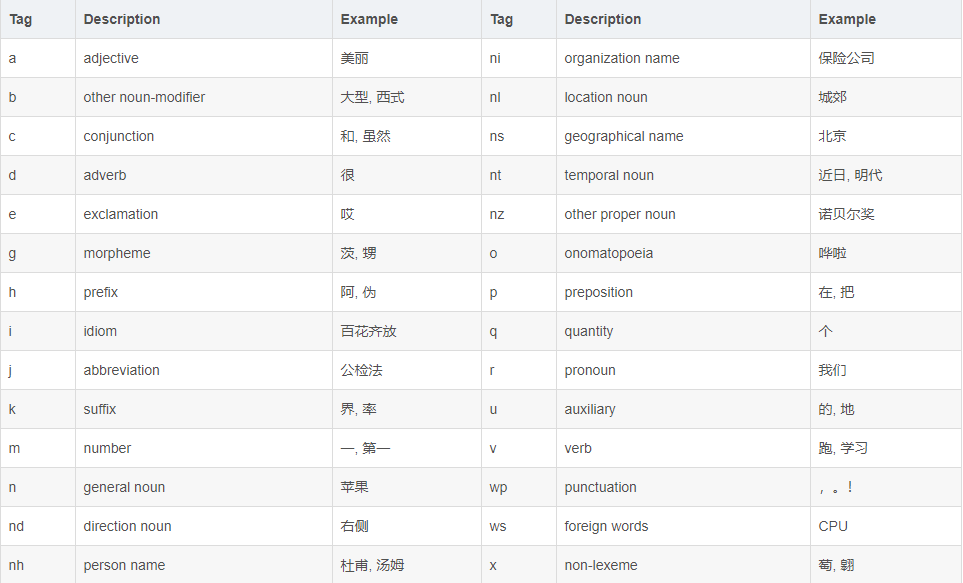
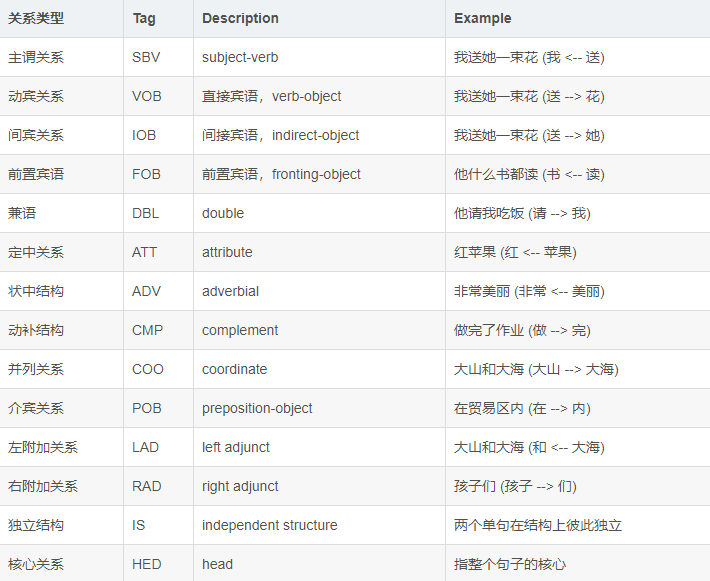
pyltp 是 LTP 的 Python 封装,提供了分词,词性标注,命名实体识别,依存句法分析,语义角色标注功能。 可能你才刚刚开始了解pyltp,所以下面是pyltp模块下载和pyltp模型下载的地址: pyltp安装下载:安装pyltp点我 pyltp模型下载:下载模型点我 注意注意注意(说三遍):pyltp必须下载和它对应版本模型才能正常使用,所以在下载之前,请务必记住自己下载的什么版本的pyltp python环境:python3.6 系统:Windows10 目录 分句分词词性标注命名实体识别依存语义分析语义角色标注 分句pyltp提供的SentenceSplitter可以将一段文字根据中文和英文的标点符号规则进行分句,从而得到这段话中的每个句子。听过SentenceSplitter中的split函数我们可以得到一个存储句子的列表,我们再将列表打印出来。 ''' created on January 22 17:23 2019 @author:lhy ''' from pyltp import SentenceSplitter def sentenceSplitter(sentence='机器学习有下面几种定义: “机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。 “机器学习是对能通过经验自动改进的计算机算法的研究”。 “机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。” 一种经常引用的英文定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.'): sents=SentenceSplitter.split(sentence)#分句 print('\n'.join(sents)) sentenceSplitter()结果: 机器学习有下面几种定义: “机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。 “机器学习是对能通过经验自动改进的计算机算法的研究”。 “机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。” 一种经常引用的英文定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E. 分词使用官方提供的模型cws.model将一句话分成对应的词: ''' created on January 22 17:34 2019 @author:lhy ''' from pyltp import Segmentor def segmentor(sentence=''): segmentor=Segmentor()#初始化实例 segmentor.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\cws.model') # 加载模型 words=segmentor.segment(sentence)#产生分词 segmentor.release()#释放模型 print('\n'.join(words)) segmentor(sentence='我今天很开心能去看电影')结果: 我 今天 很 开心 能 去 看 电影可以看到已经将一个句子按照中文的语法进行分割成一个个中文词。 词性标注在分词的基础上,我们可以知道每个词的词性: ''' created on January 22 17:42 2019 @author:lhy ''' from pyltp import Segmentor from pyltp import Postagger #分词 def segmentor(sentence=''): segmentor=Segmentor()#初始化实例 segmentor.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\cws.model') # 加载模型 words=segmentor.segment(sentence)#产生分词 words_list=list(words) segmentor.release()#释放模型 return words_list #词性标注 def posttagger(words): postagger=Postagger()#初始化实例 postagger.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\pos.model') postags=postagger.postag(words)#词性标注 postagger.release() return postags if __name__=='__main__': words=segmentor(sentence='我今天很开心能去看电影') postags=posttagger(words) for word,tag in zip(words,postags): print(word+'/'+tag)运行结果: 我/r 今天/nt 很/d 开心/a 能/v 去/v 看/v 电影/n可以看到ltp对每个词都进行了词性标注。LTP中采用了863词性标注级,其各个词性的含义可以参考下表: 命名实体识别 (Named Entity Recognition, NER) 是在句子的词序列中定位并识别人名、地名、机构名等实体的任务。 想要实现命名实体识别需要知道一个句子中的分词和这些词对应的词性标注。 LTP 采用 BIESO标注体系。B 表示实体开始词,I表示实体中间词,E表示实体结束词,S表示单独成实体,O表示不构成命名实体。LTP 提供的命名实体类型为:人名(Nh)、地名(Ns)、机构名(Ni)。B、I、E、S位置标签和实体类型标签之间用一个横线 - 相连;O标签后没有类型标签。 例子: ''' created on January 22 17:56 2019 @author:lhy ''' from pyltp import Segmentor from pyltp import Postagger from pyltp import NamedEntityRecognizer #分词 def segmentor(sentence=''): segmentor=Segmentor()#初始化实例 segmentor.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\cws.model') # 加载模型 words=segmentor.segment(sentence)#产生分词 words_list=list(words) segmentor.release()#释放模型 return words_list #词性标注 def posttagger(words): postagger=Postagger()#初始化实例 postagger.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\pos.model') postags=postagger.postag(words)#词性标注 postagger.release() return postags #命名实体识别 def reco(words,postags): recognizer=NamedEntityRecognizer()#初始化实例 recognizer.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\ner.model') netags=recognizer.recognize(words,postags)#命名实体识别 for word ,ntag in zip(words,netags): print(word+'/'+ntag) recognizer.release() return netags if __name__=='__main__': #因为有**词,只能通过拼音,大家在练习的时候换成汉字就行 words=segmentor(sentence='guowuyuanzonglilikeqiang调研上海外高桥时提出,支持上海积极探索新机制') postags=posttagger(words) reco(words,postags)结果: guowuyuan/S-Ni zongli/O likeqiang/S-Nh 调研/O 上海/B-Ns 外高桥/E-Ns 时/O 提出/O ,/O 支持/O 上海/S-Ns 积极/O 探索/O 新/O 机制/O“guowuyuan”是机构名标注为Ni,“likeqiang”是人名标注为Nh,“上海外高桥”是地名标注为Ns。其中“上海外高桥”以“上海”为开始B,以“外高桥”为结束E。guowuyuan是单个实体,所以是S。 依存语义分析依存语义分析通过分析语言单位内成分之间的依存关系来确定语法结构。依存语义分析用来识别句子中的“主谓宾”、“定状补”等语法成分,并分析这些成分之间的关系。 依存句法分析标注关系有14种,具体如下: 结果: 1/guowuyuan/2/ATT 2/zongli/3/ATT 3/likeqiang/4/SBV 4/调研/7/ATT 5/上海/6/ATT 6/外高桥/4/VOB 7/时/8/ADV 8/提出/0/HED 9/,/8/WP 10/支持/8/COO 11/上海/13/SBV 12/积极/13/ADV 13/探索/10/VOB 14/新/15/ATT 15/机制/13/VOB代码中,arc.head指的是依存弧的父节点的索引,arc.relation指的是依存弧的关系。在结果中我们可以看到“提出”是整句话的核心关系,所以它的父节点是索引0。而对于其他关系,我们可以看到“guowuyuan”的父节点是索引2“总理”,他们之间构成了定中关系ATT,构成“guowuyuanzongli”,“上海”和父节点13的“探索”之间构成了主谓关系SBV,构成“上海探索”。 语义角色标注语义角色标注 (Semantic Role Labeling, SRL) 是一种浅层的语义分析技术,标注句子中某些短语为给定谓词的论元 (语义角色) ,如施事、受事、时间和地点等。其能够对问答系统、信息抽取和机器翻译等应用产生推动作用。 guowuyuanzonglilikeqiang调研上海外高桥时提出,支持上海积极探索新机制。 我们分析上句,以“探索”为例,“积极”是他的方式,一般用ADV表示,而“新机制”是他的受事,一般用 A1表示。 核心的语义角色为A0-5六种,A0通常表示动作的施事,A1通常表示动作的影响等,A2-5根据谓语动词会有不同的语义含义。其余的15个语义角色为附加语义角色,比如说LOC表示地点,TMP表示时间等。语义角色列表如下: 结果: 7 TMP:(0,6)A1:(9,14) 9 A1:(10,10)可以看到,根据分词的索引,索引7对应的谓词是“提出”,而对于“提出”而言,时间TMP为索引0-6代表的东西,即“guowuyuanzonglilikeqiang调研上海外高桥时”。“提出”的影响A1是(也就是提出的内容是)索引9-14代表的东西,即“支持上海积极探索新机制”。索引9代表了“支持”,支持的内容是“上海”。(总感觉有点怪怪的,支持的东西不应该是“上海积极探索新机制”嘛) |
 例子:
例子: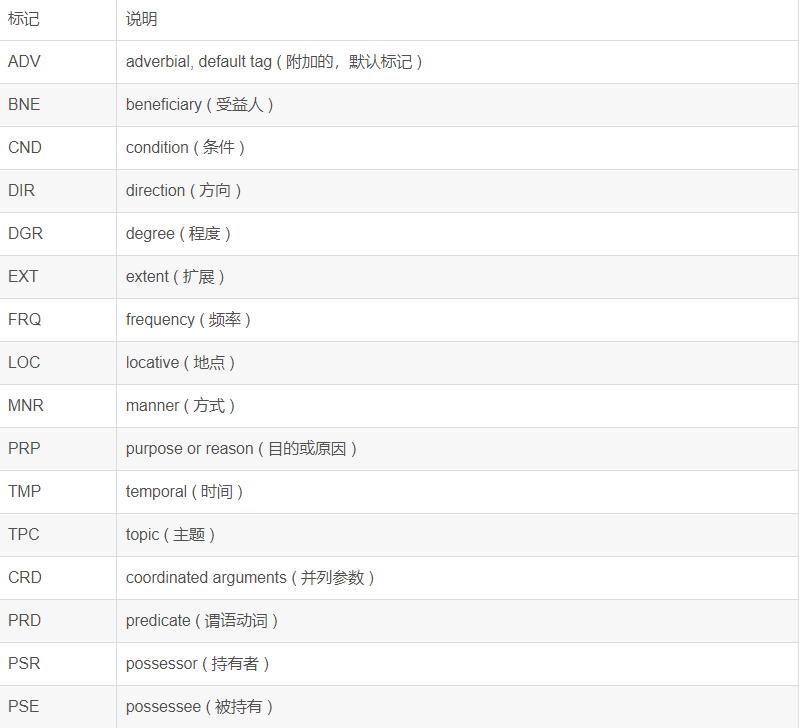 例子:
例子:【本文地址】