| 小白通过Fiddler爬取手机app的数据并提取出来(详细版) | 您所在的位置:网站首页 › app数据包修改器 › 小白通过Fiddler爬取手机app的数据并提取出来(详细版) |
小白通过Fiddler爬取手机app的数据并提取出来(详细版)
|
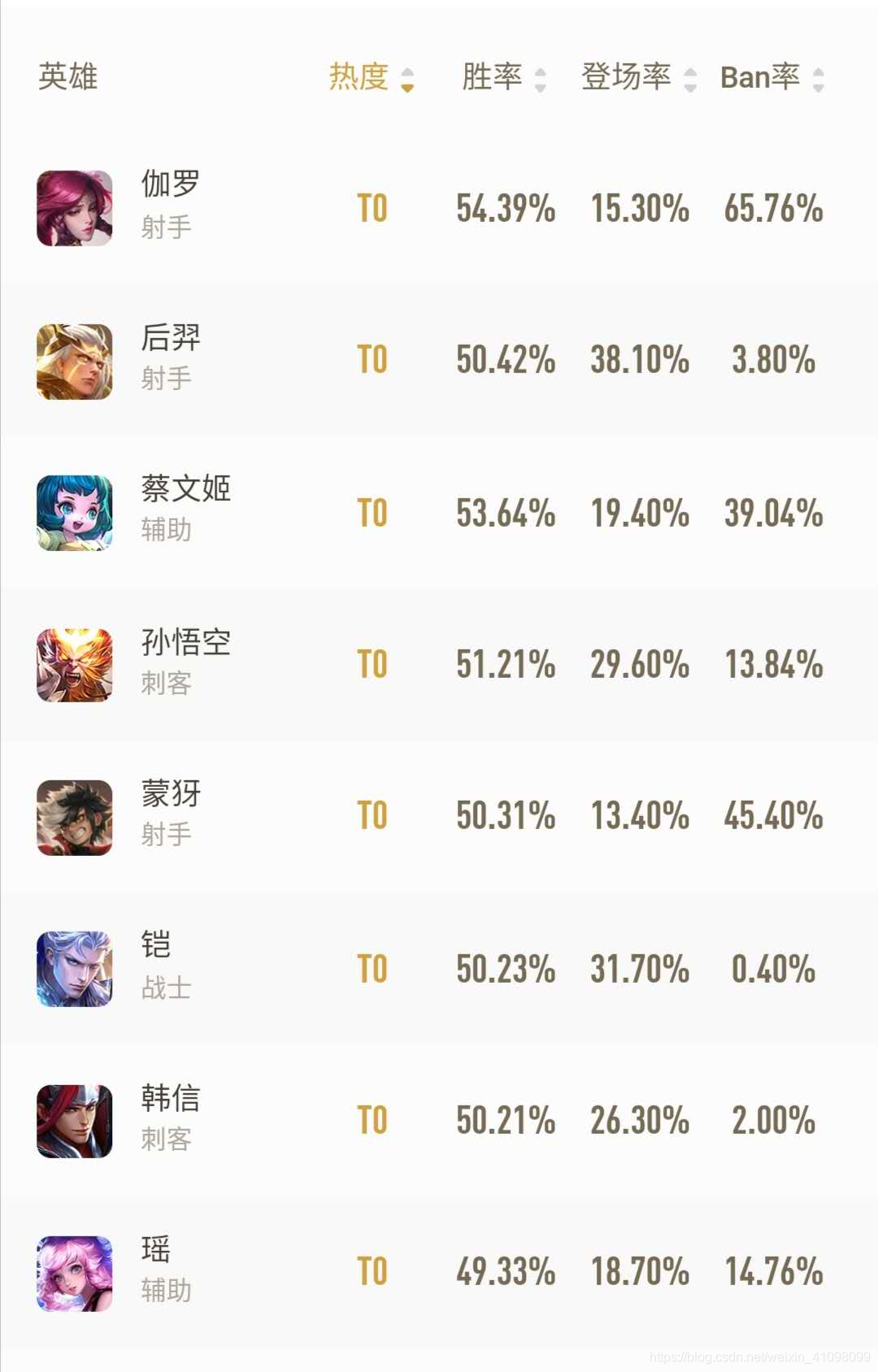
我们就以爬取安卓端上的王者营地上英雄热度榜为例: 1.下载 Fiddler下载网站,进入网站点击Download now 1.查看本地的IP,在命令行输入ipconfig 打开手机WLAN(我这里已经跟电脑连接同一个网),点击下面的修改网络 接下来我们要做的是提前json中的数据,保存到CSV文件中,并下载其英雄图标。 import csv import codecs import json from urllib.request import urlretrieve # 数据文本的命名 file_name = 'wangzhedata.csv' # 文件的保存路径 path = file_name # 指定编码为 utf-8, 避免写 csv 文件出现中文乱码 with codecs.open(path, 'w', 'utf-8') as csvfile: # 在创建wangzhedata.csv文件后,设立他们的首行表头 filednames = ['英雄ID', '英雄名', '英雄职业', '热度', '胜率', '登场率', 'Ban率', '头像链接', 'jumpurl'] writer = csv.DictWriter(csvfile, fieldnames=filednames) writer.writeheader() # 读取json文件内容,返回字典格式 with open('476_.json','r',encoding='utf8')as fp: # 加载json文件,解码规格化 json_data = json.load(fp) # 加载完后,它为dict,这点需要我们来分析(dict、list类型) hero_list = json_data['data']['list'] for i in hero_list: for j in i: if j == 'heroInfo': for k in i[j]: heroId = k['heroId'] heroName = k['heroName'] heroIcon = k['heroIcon'] # 这里是下载我们英雄的图标 urlretrieve(heroIcon, './heroIcon/' + heroName + '.jpg') jumpUrl = k['jumpUrl'] heroCareer = k['heroCareer'] winRate = i['winRate'] banRate = i['banRate'] showRate = i['showRate'] tRank = i['tRank'] try: # 将每次取出的英雄属性进行一行一行的写入 writer.writerow({'英雄ID': heroId, '英雄名': heroName, '英雄职业': heroCareer, '热度': tRank, '胜率': winRate, '登场率': showRate, 'Ban率': banRate, '头像链接': heroIcon, 'jumpurl': jumpUrl}) except UnicodeEncodeError: print("编码错误, 该数据无法写到文件中, 直接忽略该数据")运行之后,即可提取出相关的数据与图片: |
 再填写好相关信息,点击红色的Download for Windows,即可完成下载。
再填写好相关信息,点击红色的Download for Windows,即可完成下载。 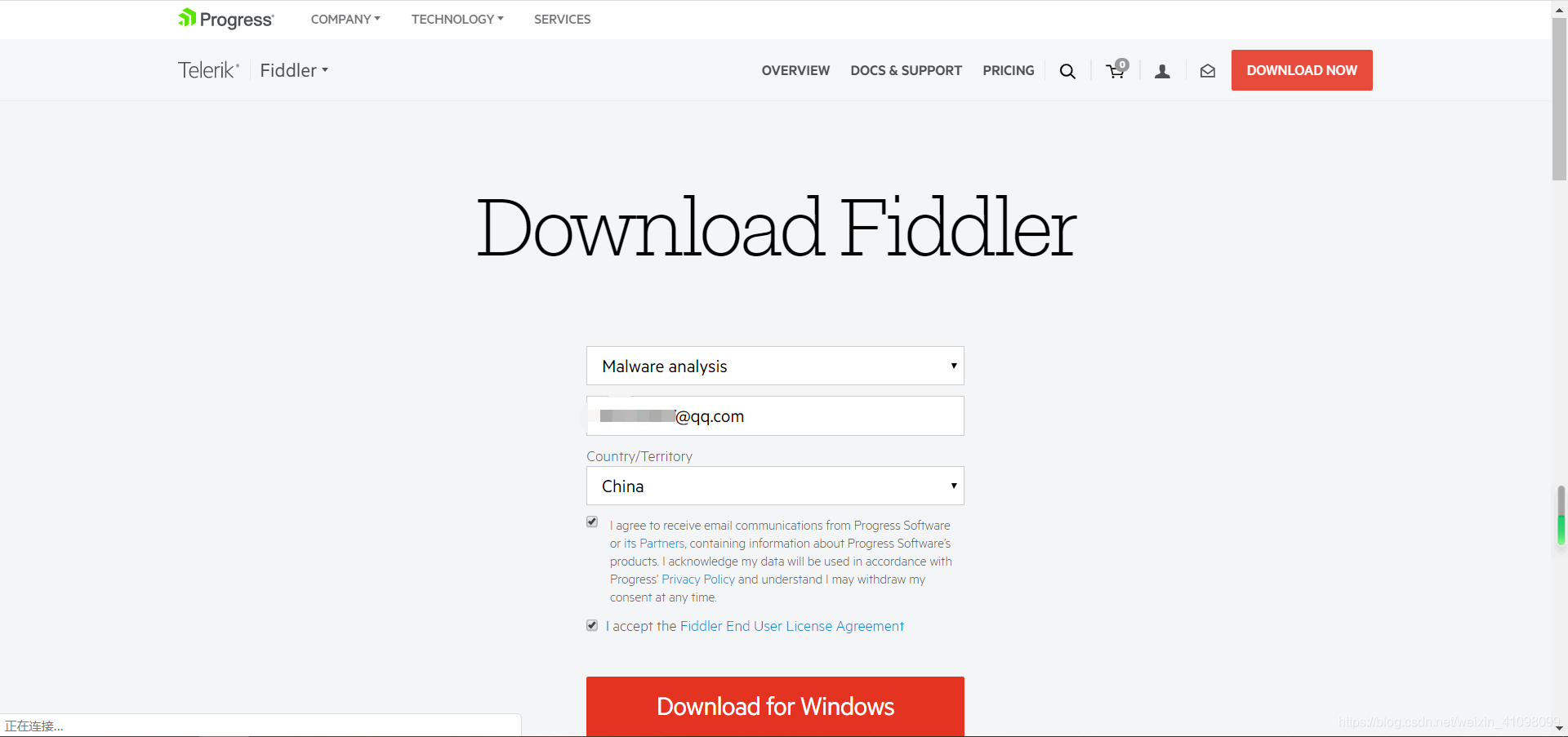 2.安装 基本是往下点就行,确定好安装路径即可。
2.安装 基本是往下点就行,确定好安装路径即可。  这里,我是选择在我的E盘
这里,我是选择在我的E盘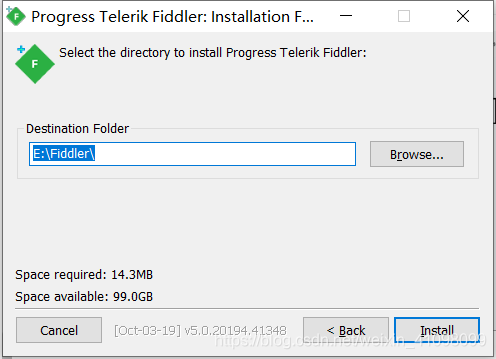 3.配置相关选项。 进入Tools中的Options
3.配置相关选项。 进入Tools中的Options 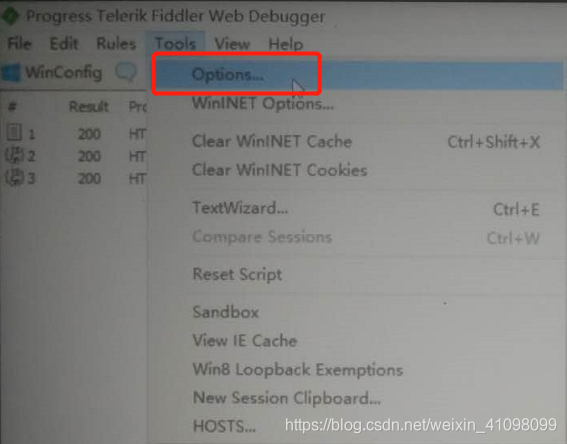 进行相关的设置,注意这里我是选择了8888的端口(等会要用到)
进行相关的设置,注意这里我是选择了8888的端口(等会要用到) 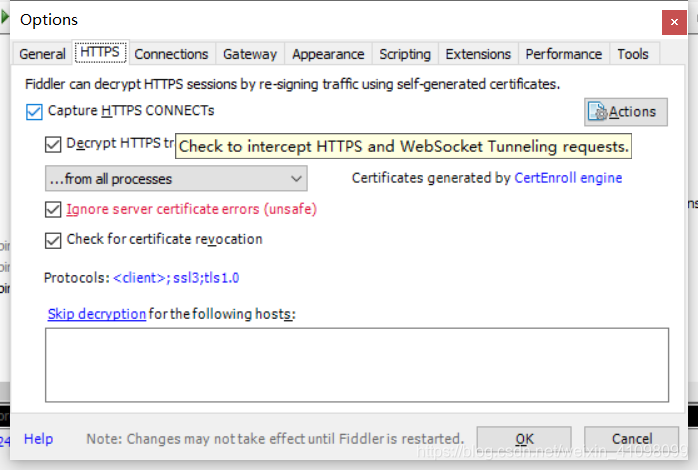
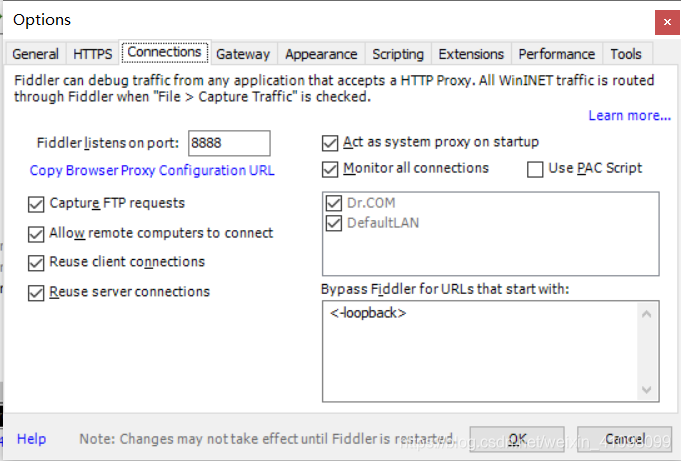 配置完成后,点OK。(最好重新启动Fiddler)
配置完成后,点OK。(最好重新启动Fiddler) 要记住这个IP地址,并且待会确保电脑与手机连接同一个WiFi。(我用的是手提,手机和手提都用同一个WiFi) 2.设置手机代理。(就是让手机连上电脑上的网络) 先打开注册表
要记住这个IP地址,并且待会确保电脑与手机连接同一个WiFi。(我用的是手提,手机和手提都用同一个WiFi) 2.设置手机代理。(就是让手机连上电脑上的网络) 先打开注册表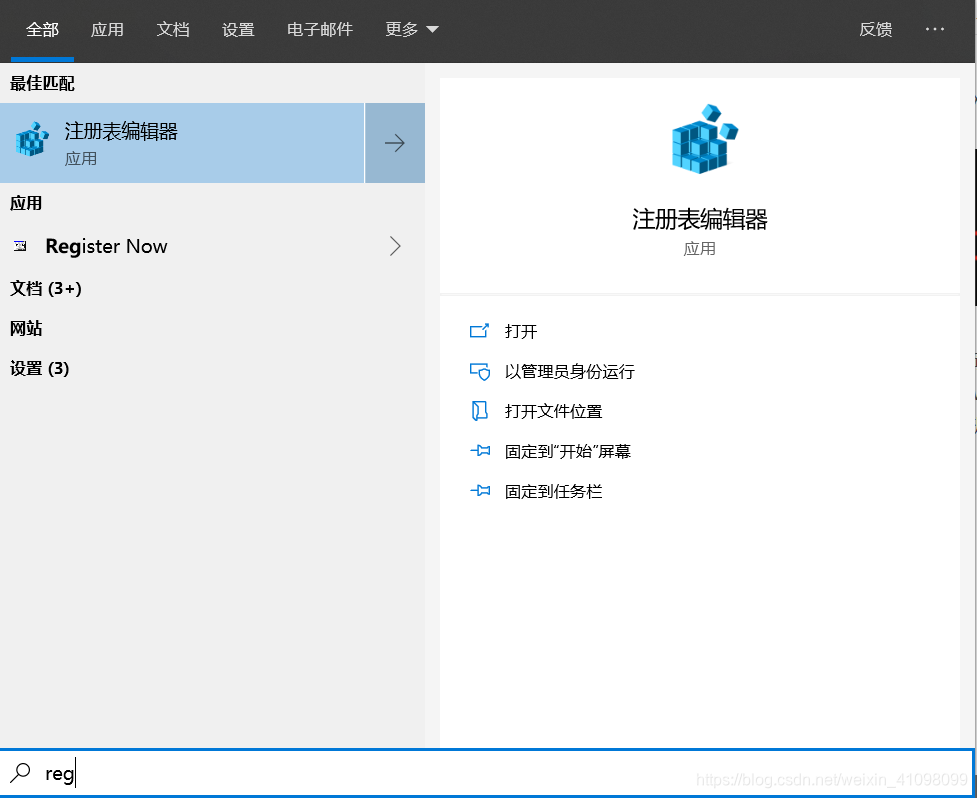 在计算机\HKEY_CURRENT_USER\Software\Microsoft\Fiddler2目录下创建 QWORD文件
在计算机\HKEY_CURRENT_USER\Software\Microsoft\Fiddler2目录下创建 QWORD文件  并命名为80
并命名为80  设置规则
设置规则 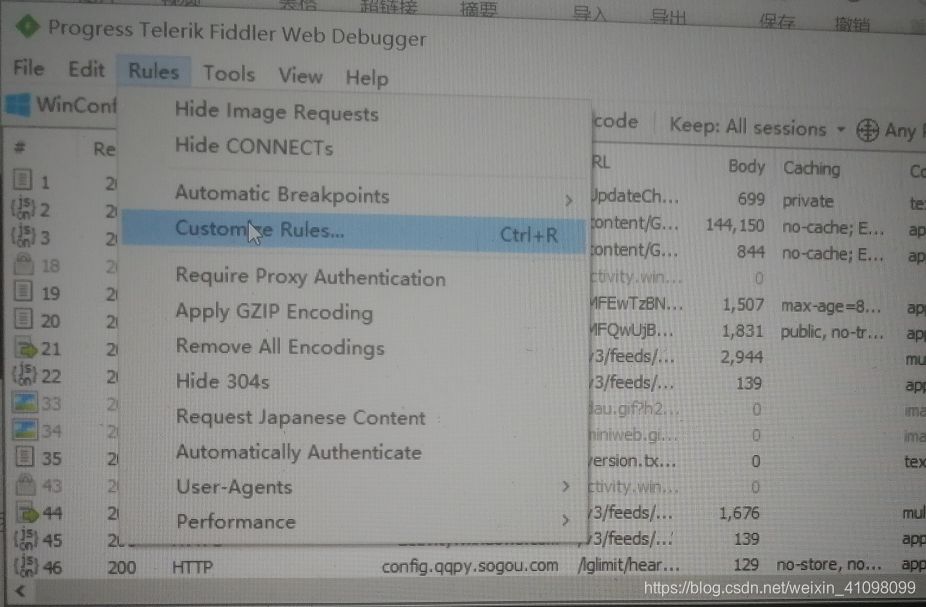 找到OnBeforeRequest
找到OnBeforeRequest 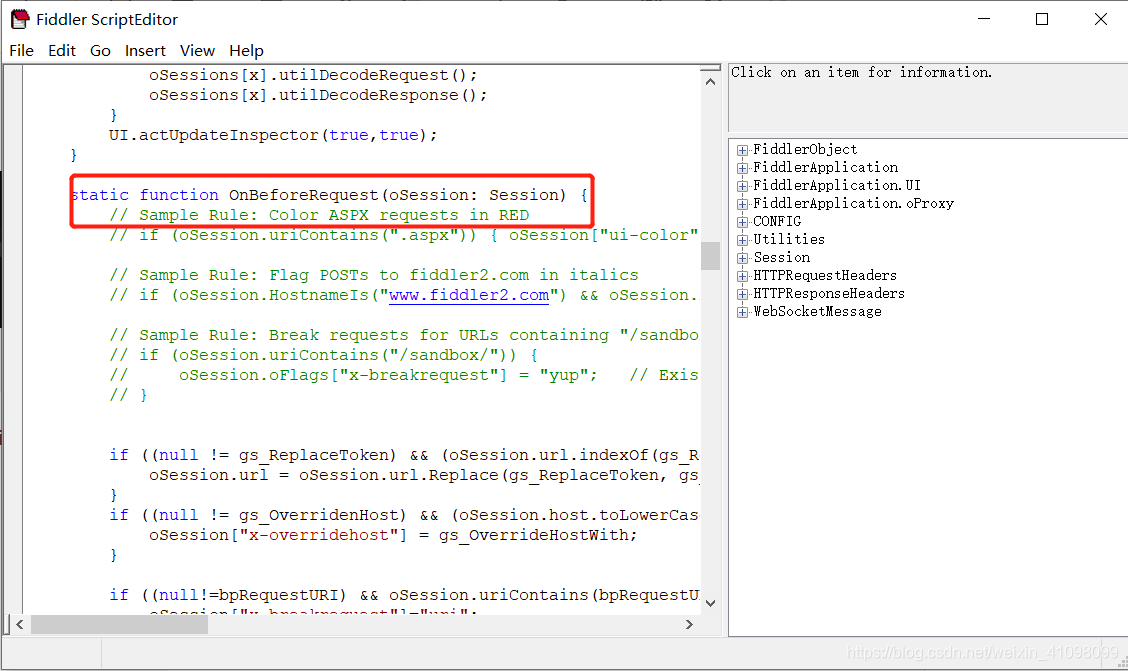 在其里面添加 if (oSession.host.toLowerCase() == “webserver:8888”) { oSession.host = “webserver:80”; }
在其里面添加 if (oSession.host.toLowerCase() == “webserver:8888”) { oSession.host = “webserver:80”; } 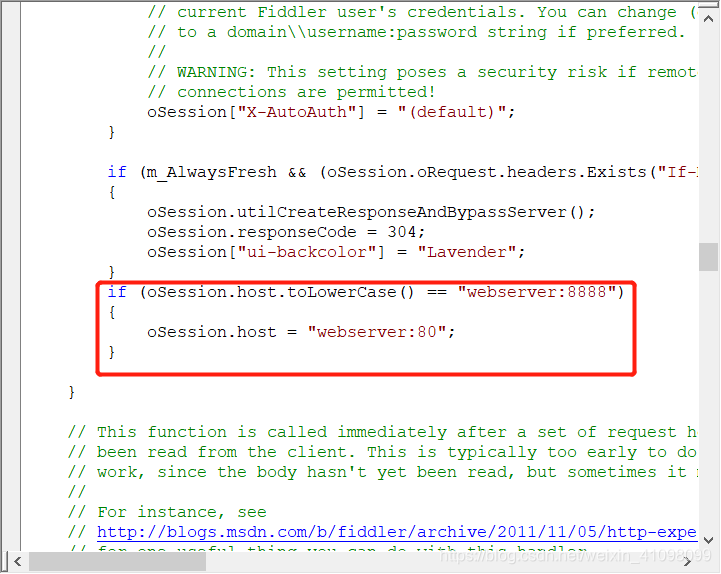 保存后,关闭电脑上的防火墙(要不然很可能连接不上电脑的网络):
保存后,关闭电脑上的防火墙(要不然很可能连接不上电脑的网络): 
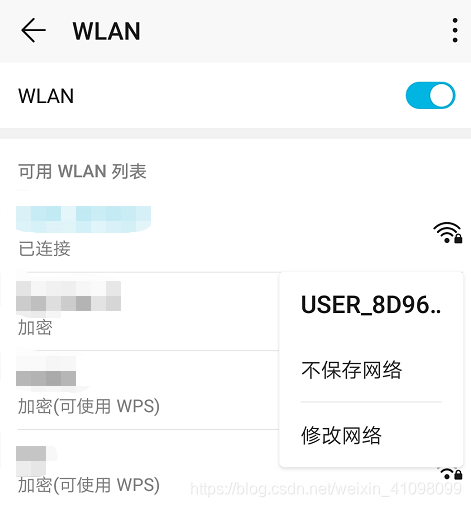 点击显示高级选项,代理改为手动,输入服务器主机名(就是刚才电脑上查询到的IP号)和服务器端口(刚才我们设置了8888),点击保存即可完成。
点击显示高级选项,代理改为手动,输入服务器主机名(就是刚才电脑上查询到的IP号)和服务器端口(刚才我们设置了8888),点击保存即可完成。 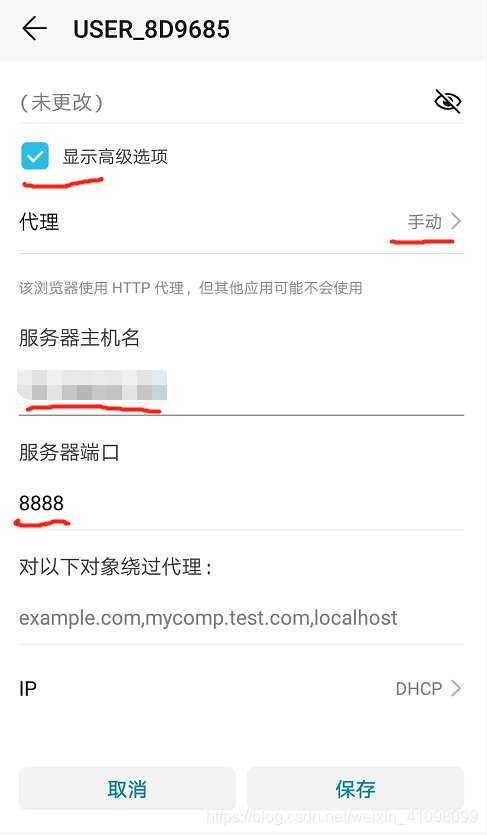 有时候我们可能会没网,先点击使用:
有时候我们可能会没网,先点击使用: 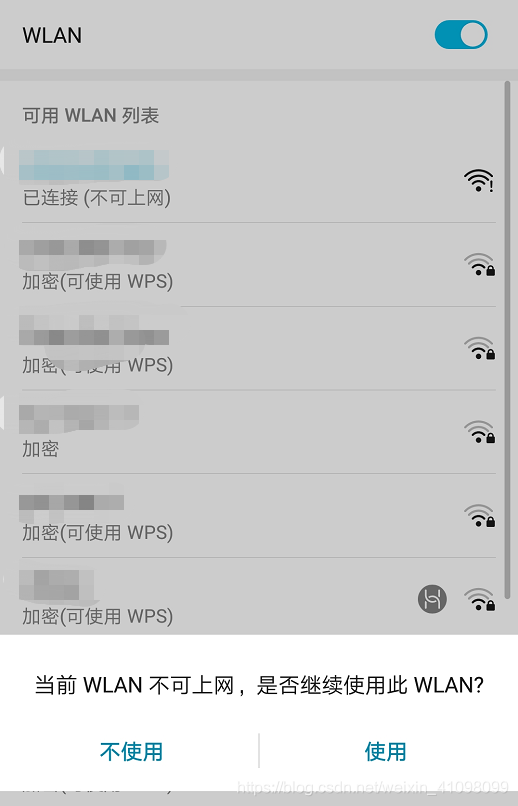 我们需要重新进入,再保存一次:
我们需要重新进入,再保存一次: 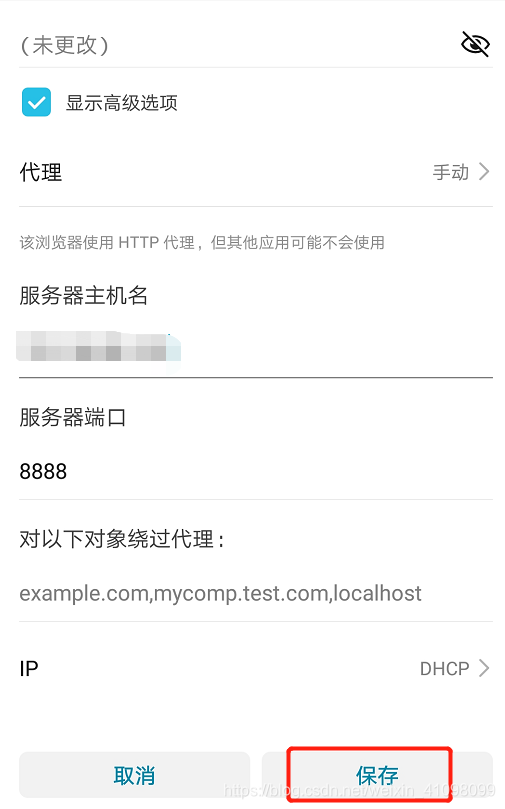 此时一般可以连接上了。 由于有安全证书的问题,我们需要打开浏览器,登录到电脑上的IP+端口(8888),进入下载证书。
此时一般可以连接上了。 由于有安全证书的问题,我们需要打开浏览器,登录到电脑上的IP+端口(8888),进入下载证书。 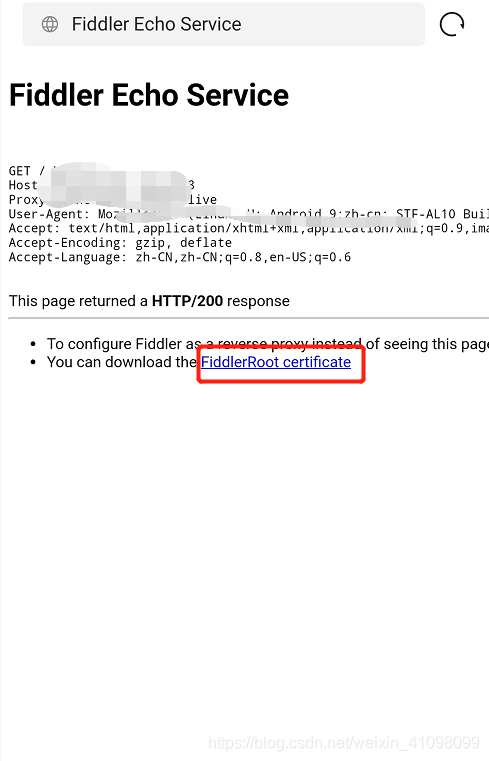
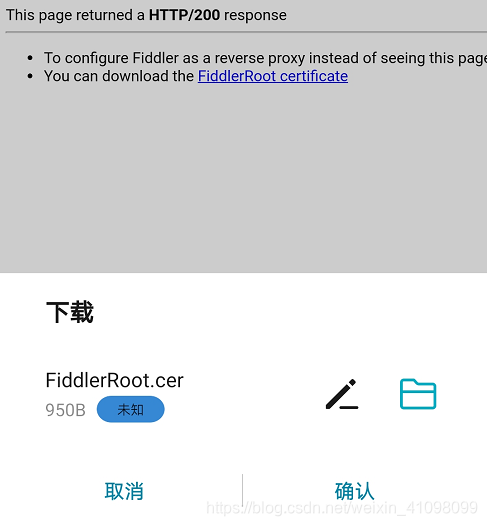 确认下载后,安装:
确认下载后,安装: 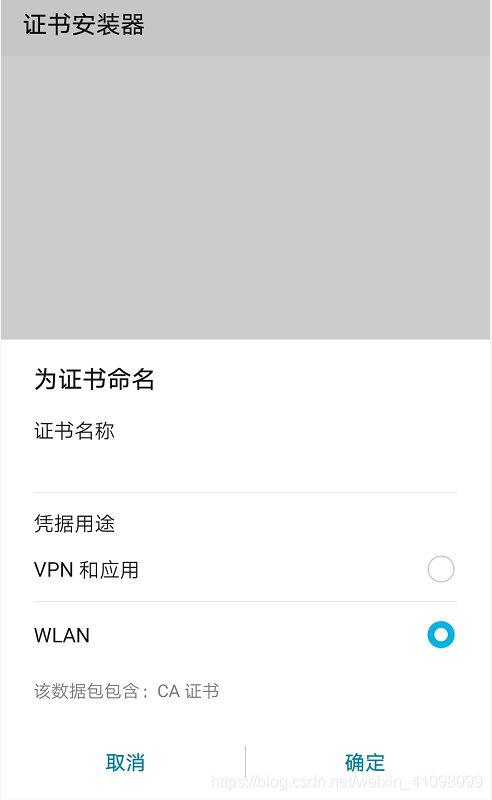 3.抓取手机APP上的数据 接下来,我们打开我们手机上的王者营地,有时可能电脑的网络不足以连上,可以先切换到自己的手机网络,进入到此界面中,然后换回电脑上的网络(即WiFi),再点击下面的全部
3.抓取手机APP上的数据 接下来,我们打开我们手机上的王者营地,有时可能电脑的网络不足以连上,可以先切换到自己的手机网络,进入到此界面中,然后换回电脑上的网络(即WiFi),再点击下面的全部 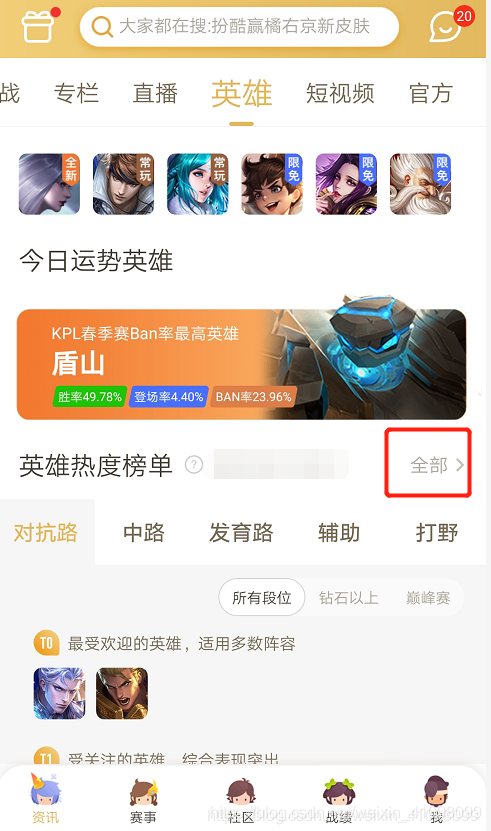 进入到我们的英雄热度榜里(这也是我们要爬取的榜单数据)
进入到我们的英雄热度榜里(这也是我们要爬取的榜单数据) 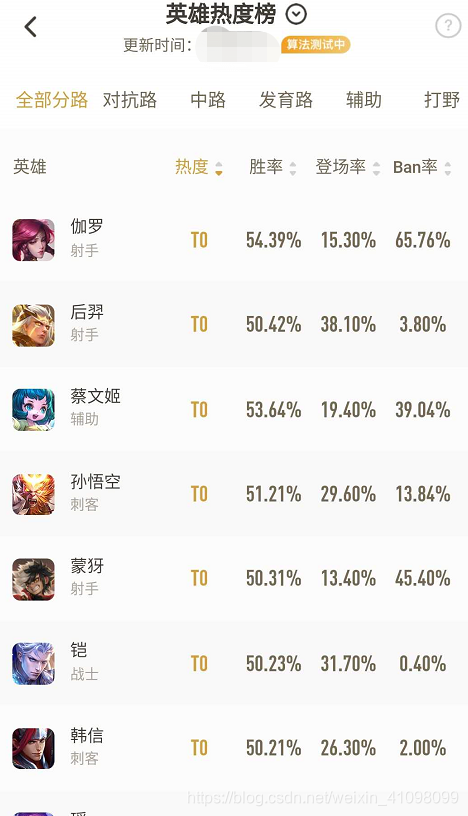 此时,我们的Fiddler会出现相关的数据
此时,我们的Fiddler会出现相关的数据 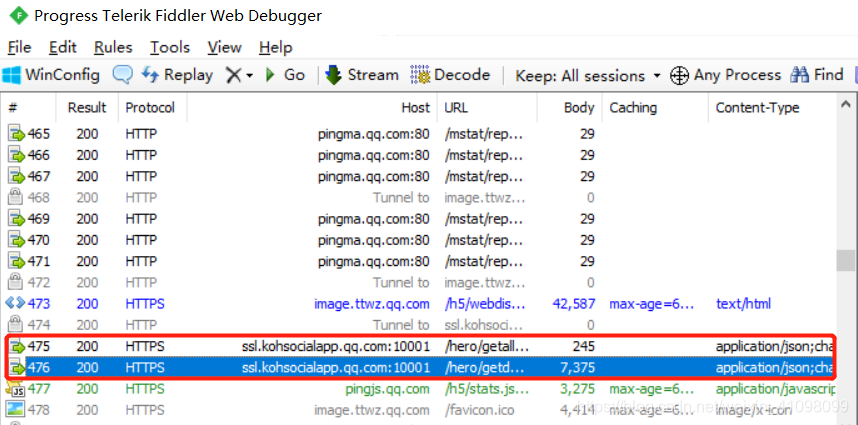 点击第476条下的json文件,我们可以发现,数据已经出来了
点击第476条下的json文件,我们可以发现,数据已经出来了 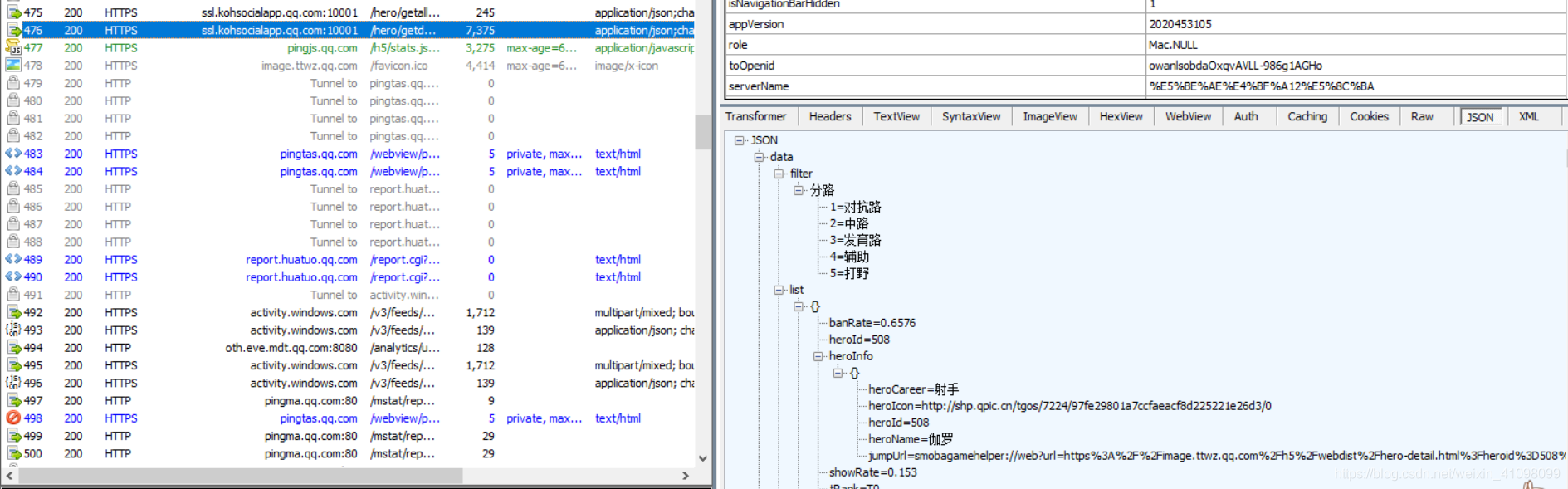 对此条进行保存
对此条进行保存 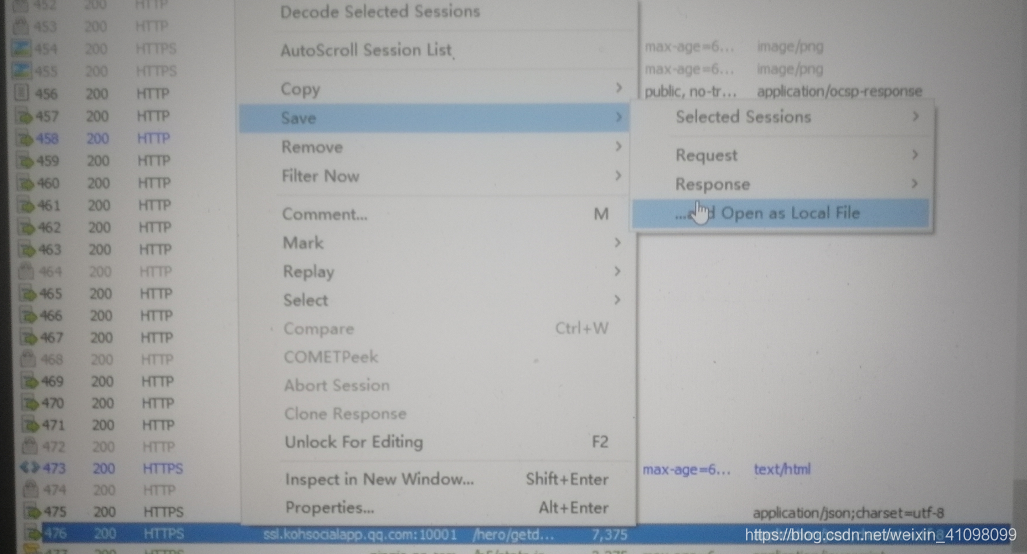 可以看到我们有个json文件产生,打开:
可以看到我们有个json文件产生,打开: 
 发现没有解密,我们可以进入到 https://www.json.cn/ ,复制到里面,解密规范查看:
发现没有解密,我们可以进入到 https://www.json.cn/ ,复制到里面,解密规范查看: 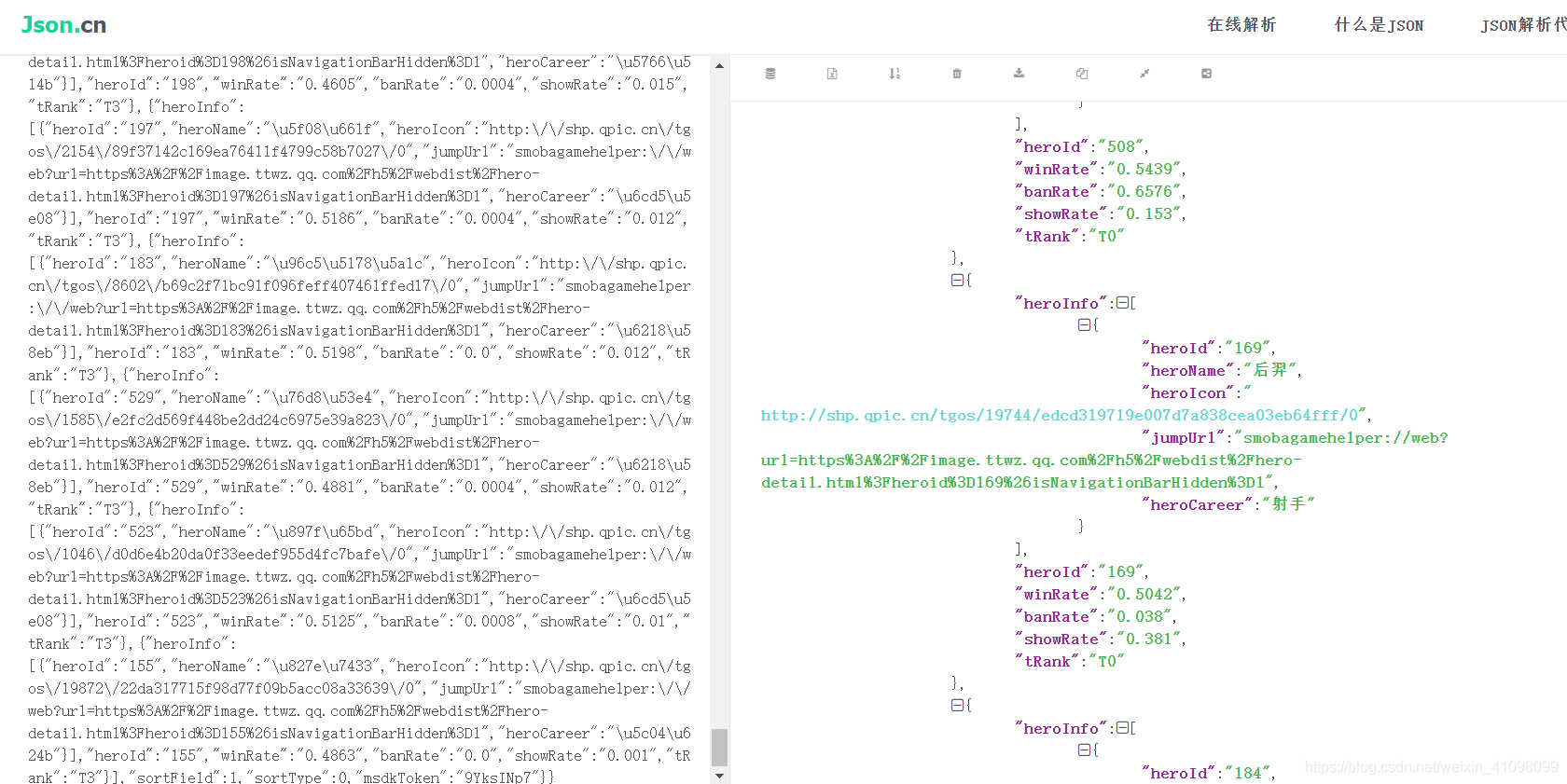
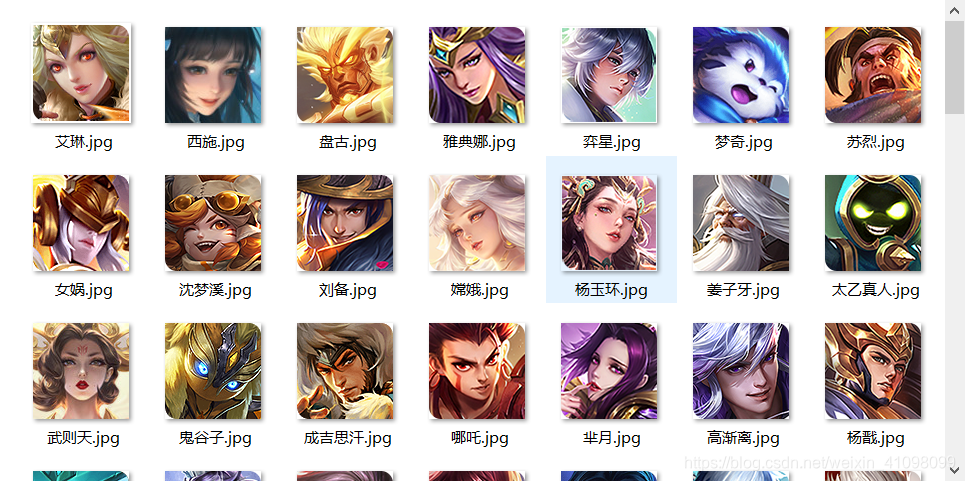
 但用Excel打开csv文件时,可能会出现乱码,因为我们写进去的是UTF-8编码,而Excel打开的是ANSI编码。
但用Excel打开csv文件时,可能会出现乱码,因为我们写进去的是UTF-8编码,而Excel打开的是ANSI编码。 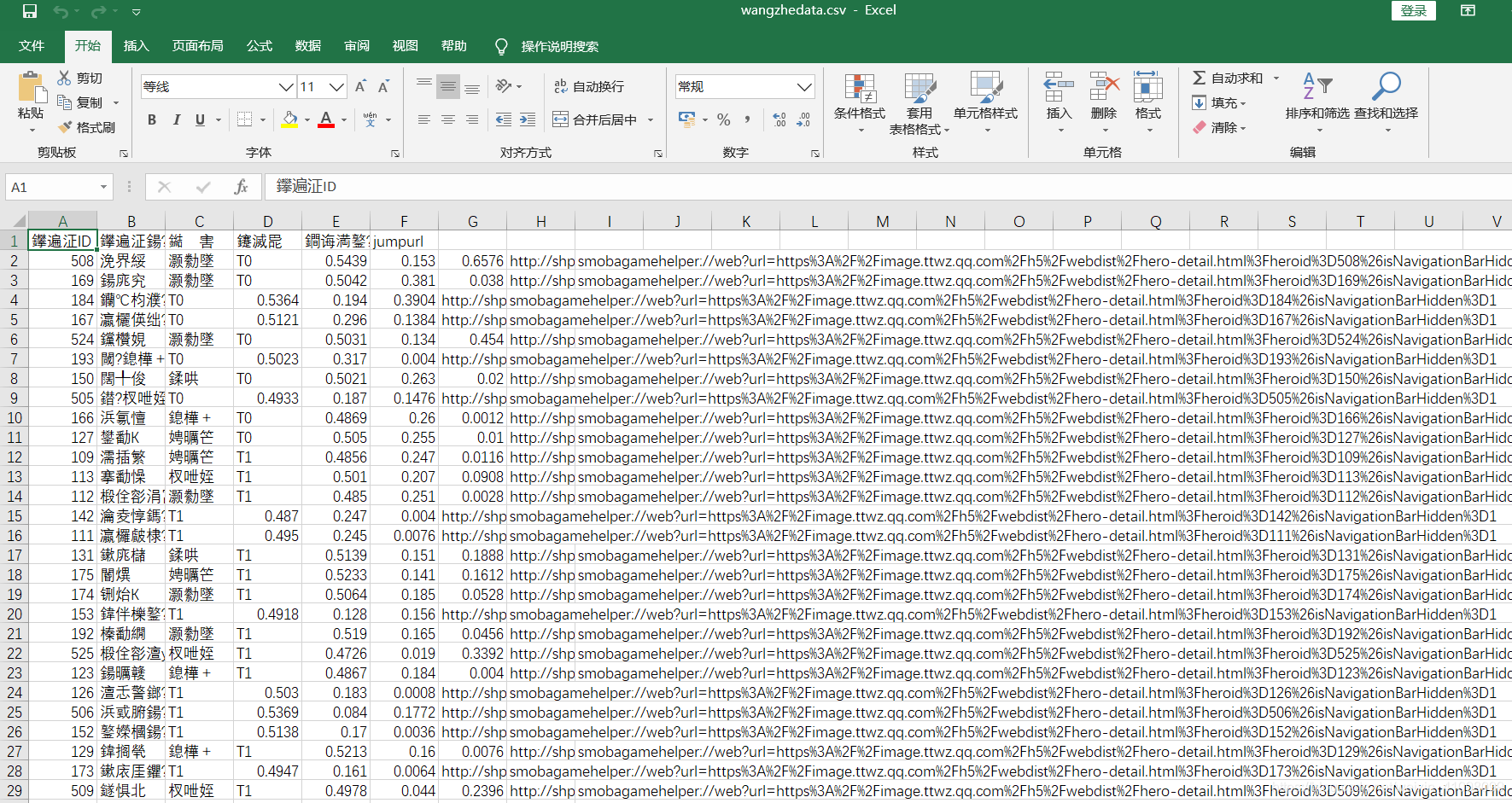 此时,我们需要用记事本打开,然后另存为(换种编码格式为ANSI)
此时,我们需要用记事本打开,然后另存为(换种编码格式为ANSI)  保存后,再打开。
保存后,再打开。 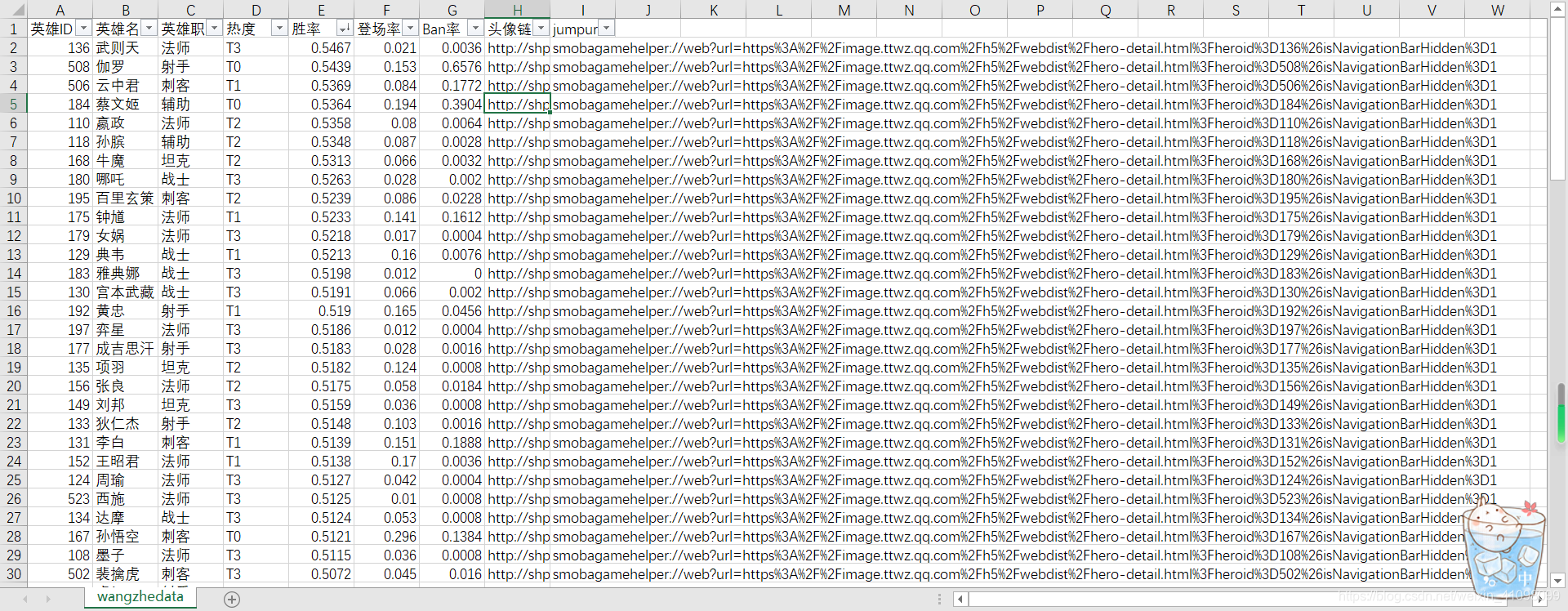
【本文地址】