| Hadoop中HDFS的文件到底存储在集群节点本地文件系统哪里 | 您所在的位置:网站首页 › ai在哪里看文件大小 › Hadoop中HDFS的文件到底存储在集群节点本地文件系统哪里 |
Hadoop中HDFS的文件到底存储在集群节点本地文件系统哪里
|
Hadoop中HDFS的文件到底存储在集群节点本地文件系统哪里
1.前言HDFS存储机制ClientNameNode 与 DataNode
2. Hdfs存储具体对应的计算机存储位置实践举例上传大文件到datanode 上寻找真正的文件
1.前言
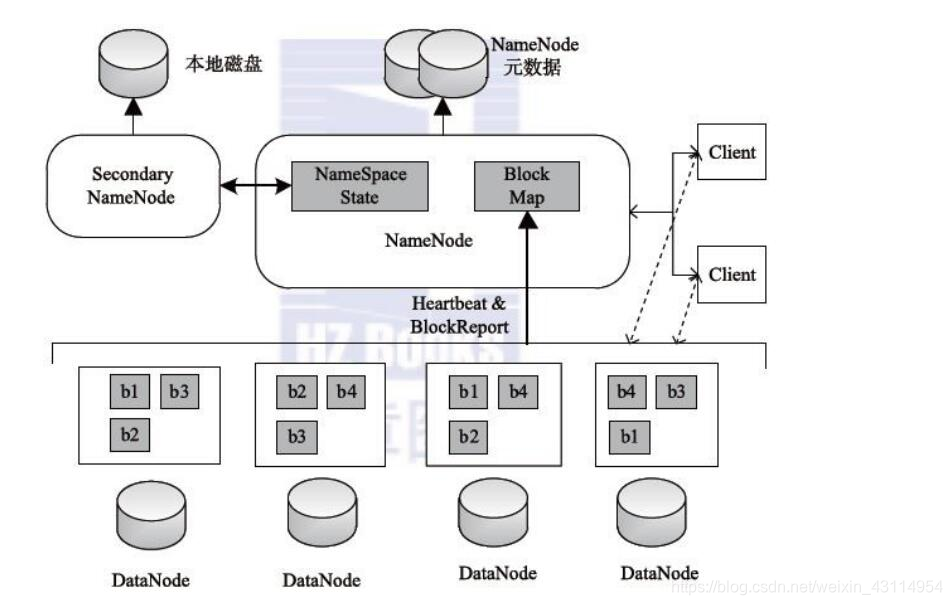
对于刚刚接触学习Hadoop的同学来说,我们经常会用到以下命令: cd /usr/local/hadoop/ ./bin/hdfs dfs -put example.file这个put命令的作用是把本地的 example.file文件上传到HDFS分布式文件系统当中。那么有没有想过,上传到HDFS当中的文件是具体保存在哪里呢?接下来让我们揭晓。 HDFS存储机制在回答这个问题之前,我们先稍微回顾下HDFS文件系统的存储原理。 切分文件;访问或通过命令行管理HDFS;与NameNode交互,获取文件位置信息;与DataNode交互,读取和写入数据。 NameNode:就是 master。它是一个主管、管理者。 作用如下: 1、管理 HDFS 的名称空间。 2、管理数据块(Block)映射信息 3、配置副本策略 4、处理客户端读写请求。 元数据:NameNode中元数据作用 DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。作用如下: 1、存储实际的数据块。 2、执行数据块的读/写操作。 由以上可知,DataNode负责存储实际的数据块。所以我们大概知道了上传到Hdfs中的文件应该是存储在DataNode中。 2. Hdfs存储具体对应的计算机存储位置我们先来分析下我们安装hadoop时配置的hdfs-site.xml 文件 (在 /usr/local/hadoop/etc/hadoop/ 下) dfs.namenode.secondary.http-address Master:50090 dfs.replication 3 dfs.namenode.name.dir file:/usr/local/hadoop/tmp/dfs/name dfs.datanode.data.dir file:/usr/local/hadoop/tmp/dfs/data我们主要看其中的两个配置参数 dfs.replication 3可以看出,block文件副本数为3 dfs.datanode.data.dir file:/usr/local/hadoop/tmp/dfs/data可以看出,datanode的存储目录为 /usr/local/hadoop/tmp/dfs/data 因此,当用户通过client提交文件上传到Hdfs文件系统时,将该文件以block块的形式存放在不同的datanode上,并且备份副本数为3。 实践举例我用5台虚拟机搭建了一个小集群,一个Master节点作为namenode,4个Slave节点作为 datanode。如下图所示: 通过put命令上传一个大于128M的文件(这样一个文件就会被分成多个block块存储。 我在Client本地的/home/hadoop/下准备了一个大小为211.8M的压缩包文件hadoop.master.tar.gz 通过以下指令将这个压缩包文件上传到Hdfs上 cd /usr/local/hadoop/ ./bin/hdfs dfs -put /home/hadoop/hadoop.master.tar.gz其中第二条命令等价于: ./bin/hdfs dfs -put /home/hadoop/hadoop.master.tar.gz /user/hadoop/即将该文件上传到Hdfs上的 /user/hadoop/ 下。 结果如下: 192.168.1.101:50070/explorer.html 其中192.168.1.101为我的Master的IP,50070为访问端口号。
由以上我们得知hadoop.master.tar.gz被分割成Block0以及Block1两个块。 hadoop.master.tar.gz = Block0 +Block1 Block0(ID:1073741907): Slave1,Slave3,Slave4 Block1(ID:1073741908): Slave2,Slave4,Slave3 又由上文的hdfs-site.xml 文件中的配置文件 dfs.datanode.data.dir file:/usr/local/hadoop/tmp/dfs/data结合以上信息通过在相关Slave节点运行以下关键指令到制定目录可以找到hadoop.master.tar.gz被分割的block块文件存放的位置。 这里以Slave2数据节点为例,按照上文分析的,Slave2中存放的 应该是Block1(ID:1073741908) cd $HADOOP_HOME/tmp/dfs/data cd current cd BP-2040097831-192.168.1.101-1616043168582 cd current cd finalized cd subdir0/subdir0 ll结果如下,图中倒数第二个大小为77594165,文件名为blk_1073741908,与上文的网页查看的信息一致。 Block1(ID:1073741908): Slave2,Slave4,Slave3 我们在Slave3上查找 Block0(ID:1073741907) 以及Block1(ID:1073741908)的存放位置。直接在Slave3上图形化查找,结果如下: 由上图,blk_1073741907+blk_1073741908=134.2M+77.6M=211.8M=hadoop.master.tar.gz 以上就是在Slave数据节点上寻找HDFS存储的文件的实际物理位置的步骤。 |
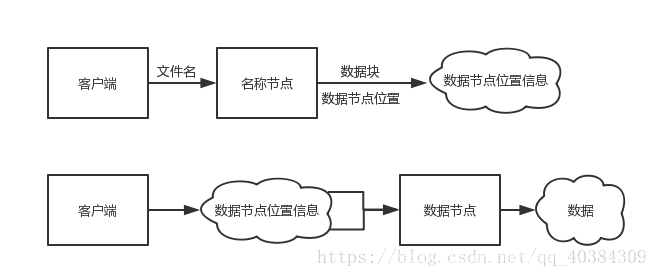 客户端要获取HDFS内的数据时,首先将文件名发送给名称节点;名称节点根据文件名找到对应数据块信息,再根据数据块信息,找到存储了这些块的数据节点位置信息。
客户端要获取HDFS内的数据时,首先将文件名发送给名称节点;名称节点根据文件名找到对应数据块信息,再根据数据块信息,找到存储了这些块的数据节点位置信息。 启动集群后,在Master节点上通过命令“hdfs dfsadmin -report”查看数据节点是否正常启动,如果屏幕信息中的“Live datanodes”不为 0 ,则说明集群启动成功。由于有4个Slave节点充当数据节点,因此,数据节点启动成功以后,会显示如下图所示信息。
启动集群后,在Master节点上通过命令“hdfs dfsadmin -report”查看数据节点是否正常启动,如果屏幕信息中的“Live datanodes”不为 0 ,则说明集群启动成功。由于有4个Slave节点充当数据节点,因此,数据节点启动成功以后,会显示如下图所示信息。 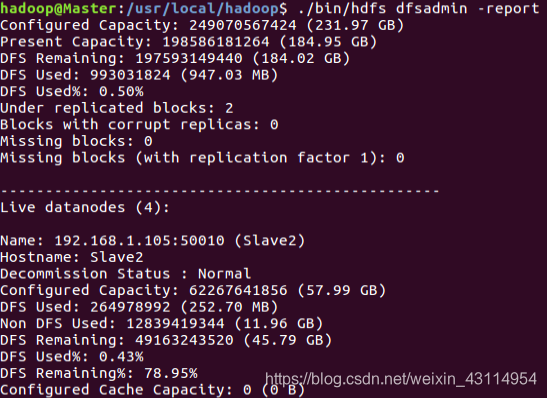
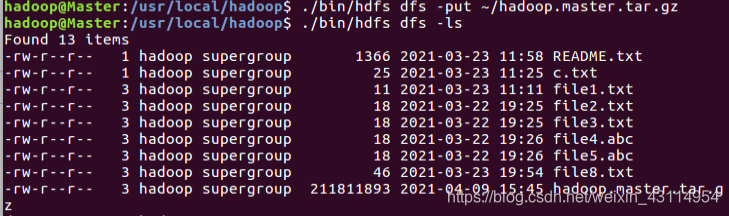 我们也可以通过网页查看上传是否成功。我的URL为:
我们也可以通过网页查看上传是否成功。我的URL为: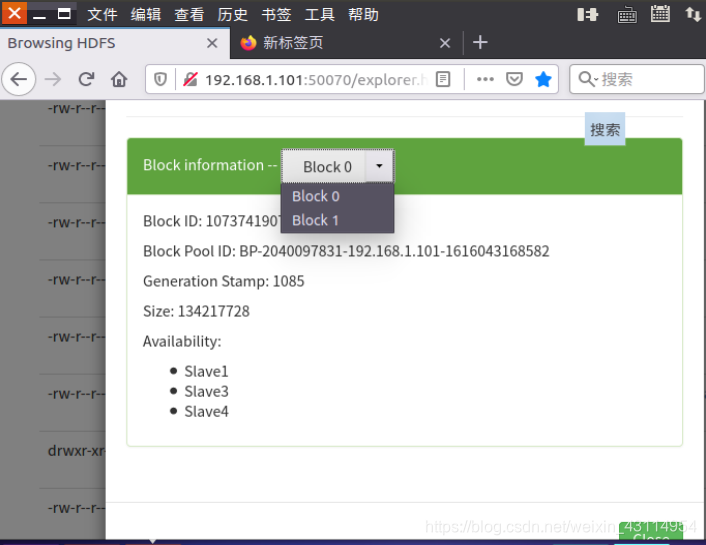
 发现该文件被分成了block0,block1两个块。 原因是该文件大小大于128M,所以要被切割分为2个块。然后备份3份。 block0备份存储共3份在Slave1,Slave3以及Slave4 这3个datanode机器上。 block1备份存储共3份在Slave2,Slave4以及Slave3 这3个datanode机器上。
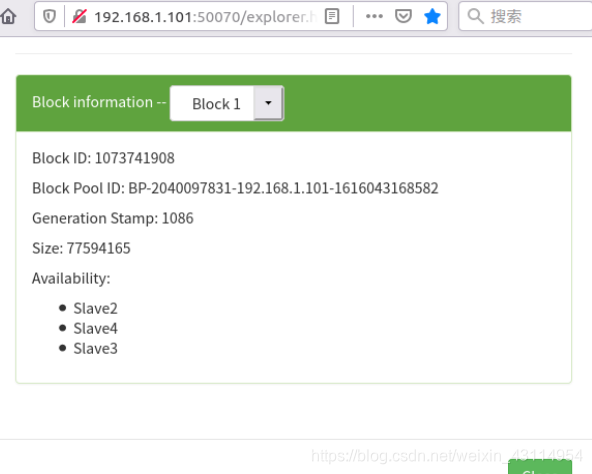
发现该文件被分成了block0,block1两个块。 原因是该文件大小大于128M,所以要被切割分为2个块。然后备份3份。 block0备份存储共3份在Slave1,Slave3以及Slave4 这3个datanode机器上。 block1备份存储共3份在Slave2,Slave4以及Slave3 这3个datanode机器上。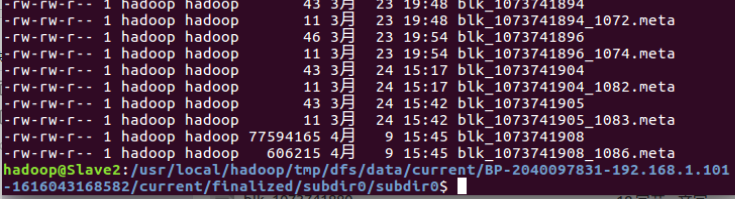 我们也可以不通过命令行的方式,可以直接图形化鼠标点击查看,如下图:
我们也可以不通过命令行的方式,可以直接图形化鼠标点击查看,如下图: 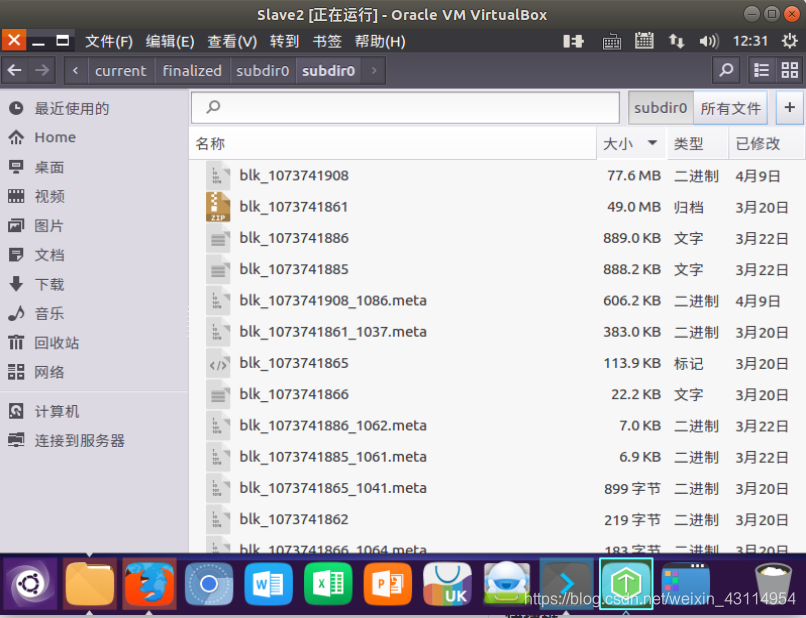 同样的,按照Block0(ID:1073741907): Slave1,Slave3,Slave4
同样的,按照Block0(ID:1073741907): Slave1,Slave3,Slave4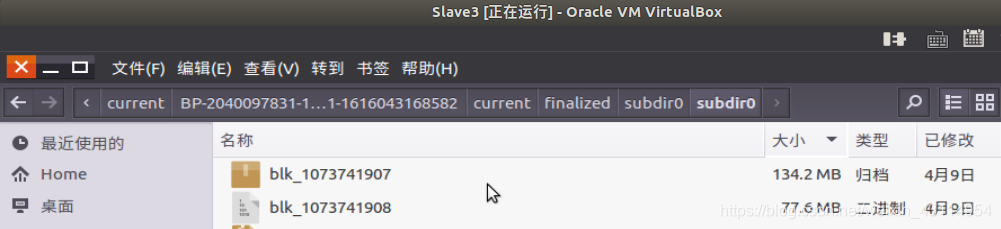
【本文地址】