| SHAPを使って機械学習モデルを解釈する方法をPython実装とともに分かりやすく解説!|スタビジ | 您所在的位置:网站首页 › SHAP方法 › SHAPを使って機械学習モデルを解釈する方法をPython実装とともに分かりやすく解説!|スタビジ |
SHAPを使って機械学習モデルを解釈する方法をPython実装とともに分かりやすく解説!|スタビジ
 ウマたん当サイト【スタビジ】の本記事では、機械学習の結果を説明する方法であるSHAPについて分かりやすく解説していきます。中身がブラックボックスで結果の解釈が難しいと思われがちな機械学習をどのように解釈してけばよいのでしょうか?Pythonでの計算もしていきますよ! ウマたん当サイト【スタビジ】の本記事では、機械学習の結果を説明する方法であるSHAPについて分かりやすく解説していきます。中身がブラックボックスで結果の解釈が難しいと思われがちな機械学習をどのように解釈してけばよいのでしょうか?Pythonでの計算もしていきますよ!こんにちは! データサイエンティストのウマたん(@statistics1012)です! みなさんは機械学習と聞くとどんなイメージがあるでしょうか? 何となくすごいことが出来そうなイメージがあるけど中身がブラックボックスで結局「なぜそうなっているのか」解釈が難しいイメージがあるのではないでしょうか? 実際に古典的な統計学に端を発する手法よりも機械学習の手法群は解釈性よりも予測精度に重きを置いています。 以下に統計学と機械学習の違いについて詳しくまとめているので興味のある方はチェックしてみてください。  機械学習と統計学の違いについてデータサイエンティストがモノ申す!!当サイト【スタビジ】の本記事では、データサイエンスの領域の機械学習と統計学の違いについて考察していきます。定義と境界が曖昧な2つの領域ですが、目的の違いを理解しておくことが大事。機械学習は予測精度を上げることを目的とし統計学はデータ構造の把握をすることを目的とします。... 機械学習と統計学の違いについてデータサイエンティストがモノ申す!!当サイト【スタビジ】の本記事では、データサイエンスの領域の機械学習と統計学の違いについて考察していきます。定義と境界が曖昧な2つの領域ですが、目的の違いを理解しておくことが大事。機械学習は予測精度を上げることを目的とし統計学はデータ構造の把握をすることを目的とします。...しかし機械学習だからといって全く解釈ができないわけではありません。 機械学習モデルをどうにかして解釈する試みは長年研究されてきており今でも研究が盛んです。 そんな機械学習を解釈するアプローチの中でも有名なのが今回紹介するSHAPなのです。 SHAPについて正しく理解して機械学習モデルから深い解釈を得られるようになりましょう! 以下のYoutube動画でも解説しているのでぜひ合わせてチェックしてみてください! 目次 SHAPとは?シャープレイ値とは?シャープレイ値からSHAPへSHAPをPythonで計算してみよう!SHAP まとめSHAPとは?それではSHAPとはどんなアプローチなのでしょうか? SHAPはSHapley Additive exPlanationsの略であり、ゲーム理論で有名なシャープレイ値に端を発する評価方法です。 SHAPは2017年に提案されたもので論文は以下。 A Unified Approach to Interpreting Model Predictions SHAPを理解する上では前述のシャープレイ値が非常に重要になりますのでまずシャープレイ値から理解しておきましょう! シャープレイ値とは?シャープレイ値(Shapley value)は、協力ゲーム理論の中で定義された概念でプレイヤー(または要因)がゲームの結果にどれだけ貢献しているかを表す値です。 シャープレイ値は、それぞれのプレイヤーがゲームの結果に貢献する価値を公平に分配する方法を提供します。 具体例を用いてシャープレイ値を見ていきましょう! 3人の友人、A、B、Cが果物を販売するビジネスを開始しました。彼らはそれぞれ異なる役割を持っており、以下のように利益を生み出します。 Aだけで働いた場合:100円の利益Bだけで働いた場合:0円の利益(Bは単独で果物を売る能力がありません)Cだけで働いた場合:50円の利益AとBが協力した場合:150円の利益AとCが協力した場合:200円の利益BとCが協力した場合:60円の利益A、B、Cが全員協力した場合:250円の利益では、A,B,Cが全員協力した場合に250円の利益はどの割合で分配するのが望ましいでしょうか? 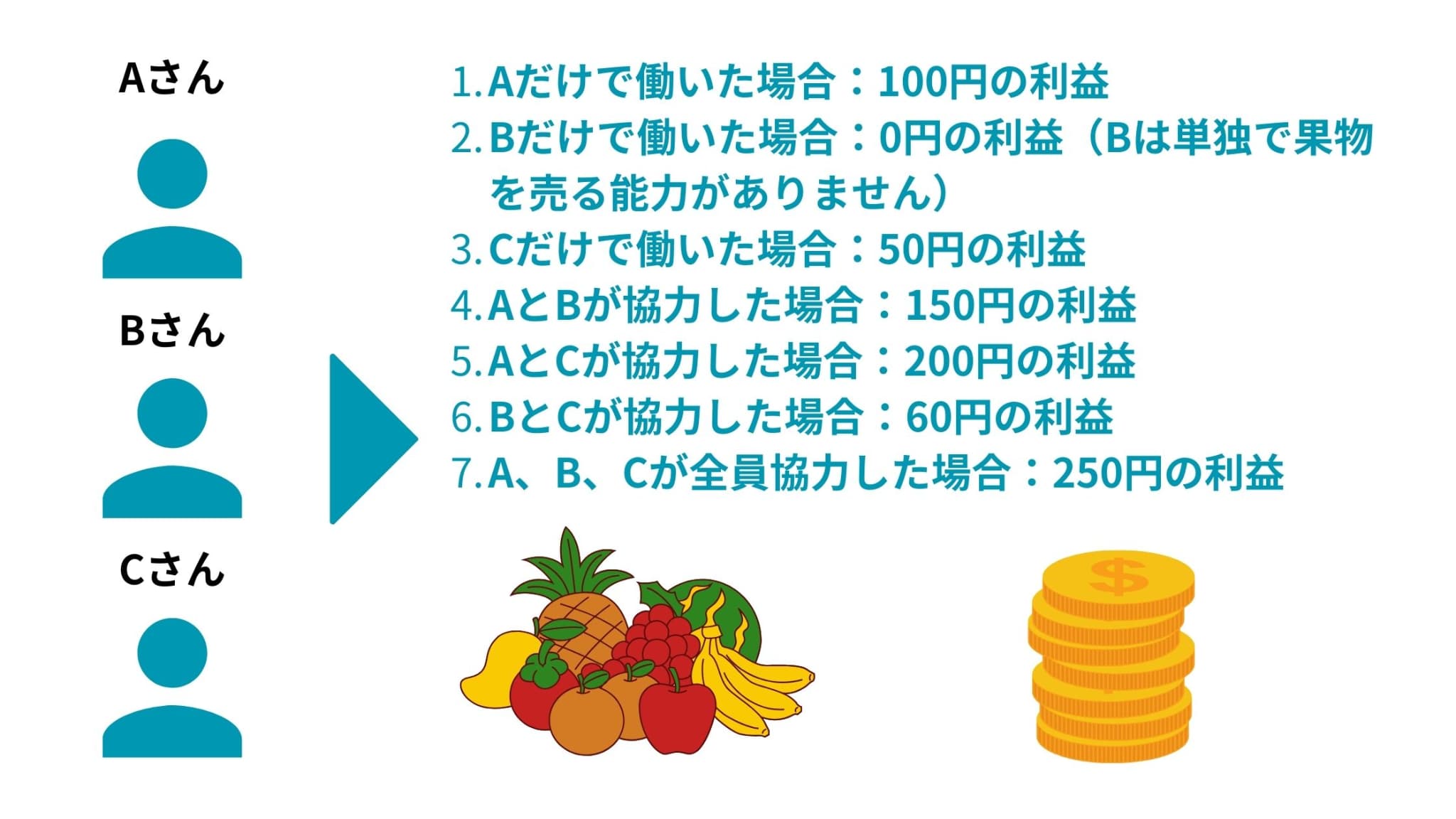 個人単体での能力で考えると、A:B:C=2:0:1なのでAさんは500/3円でBさんは0円が良いでしょうか? ただAとCさんだけの協力だと200円なのでBさんは50円分の働きはしているはず。 どう分配すればよいでしょう? ウマたん色んなパターンが絡み合っていて1つの解を出すのが難しそう・・・ここで登場するのがシャープレイ値なのです。 シャープレイ値はあるユーザーがある状況で参加した時に変化する値である「限界貢献度」を全ての状況において計算することで求めます。 まずはAさんにフォーカスして考えてみましょう! Aさんが働く状況としては以下のパターンが考えられます。 ①.誰もいない状態からAさんが働いた場合→100 – 0で100円の利益 ②.Bさんが働いている状態からAさんが働いた場合→150 – 0で150円の利益 ③.Cさんが働いている状態からAさんが働いた場合→200 – 50で150円の利益 ④.BさんとCさんが働いている状態からAさんが働いた場合→250 – 60で190円の利益 この時ABCの働く順番の組み合わせは3!で6通り。 ・A→B→C ・・・ ① ・A→C→B ・・・ ① ・B→A→C ・・・ ② ・C→A→B ・・・ ③ ・B→C→A ・・・ ④ ・C→B→A ・・・ ④ これらの平均値を取ると、 (100 + 100 + 150 + 150 + 190 + 190) / 6 = 146.66・・・となります。 これこそがシャープレイ値なのです!! それではBさんはいかがでしょう? ①.誰もいない状態からBさんが働いた場合→0 – 0で0円の利益 ②.Aさんが働いている状態からBさんが働いた場合→150 – 100で50円の利益 ③.Cさんが働いている状態からBさんが働いた場合→60 – 50で10円の利益 ④.AさんとCさんが働いている状態からBさんが働いた場合→250 – 200で50円の利益 つまり、 Bさんのシャープレイ値は、(0 + 0 + 50 + 10 + 50 + 50) = 26.66・・・ そして、Cさんは ①.誰もいない状態からCさんが働いた場合→50 – 0で50円の利益 ②.Aさんが働いている状態からCさんが働いた場合→200 – 100で100円の利益 ③.Bさんが働いている状態からCさんが働いた場合→60 – 0で60円の利益 ④.AさんとBさんが働いている状態からCさんが働いた場合→250 – 150で100円の利益 よって、 Cさんのシャープレイ値は(50 + 50 + 100 + 60 + 100 + 100) / 6 = 76.66・・・ 結果的に以下のようになりました。 Aさん:146.66 Bさん:26.66 Cさん:76.66 合計すると250円になることが分かると思います!いい感じの分配が出来たかと思います。 このように、シャープレイ値は、各プレイヤーが結果にどれだけ貢献しているかを評価する手段として用いられます。 シャープレイ値からSHAPへそれでは、シャープレイ値からSHAPへの展開を見ていきましょう! 機械学習モデルを構築する際に複数の特徴量をインプットしてそれを元に予測値を算出します。 端的に言うと、このそれぞれの特徴量が先ほどのシャープレイ値におけるユーザーにあたるものがSHAPなのです。 たとえば、「築年数」と「部屋の数」と「駅からの距離」から物件価格を予測する機械学習モデルを構築するとしましょう! その際に、築年数だけを用いてモデルを作った場合の予測値と部屋の数だけを用いてモデルを作った場合の予測値と・・・というように特徴量の貢献度を計測することができるのが分かりますね! 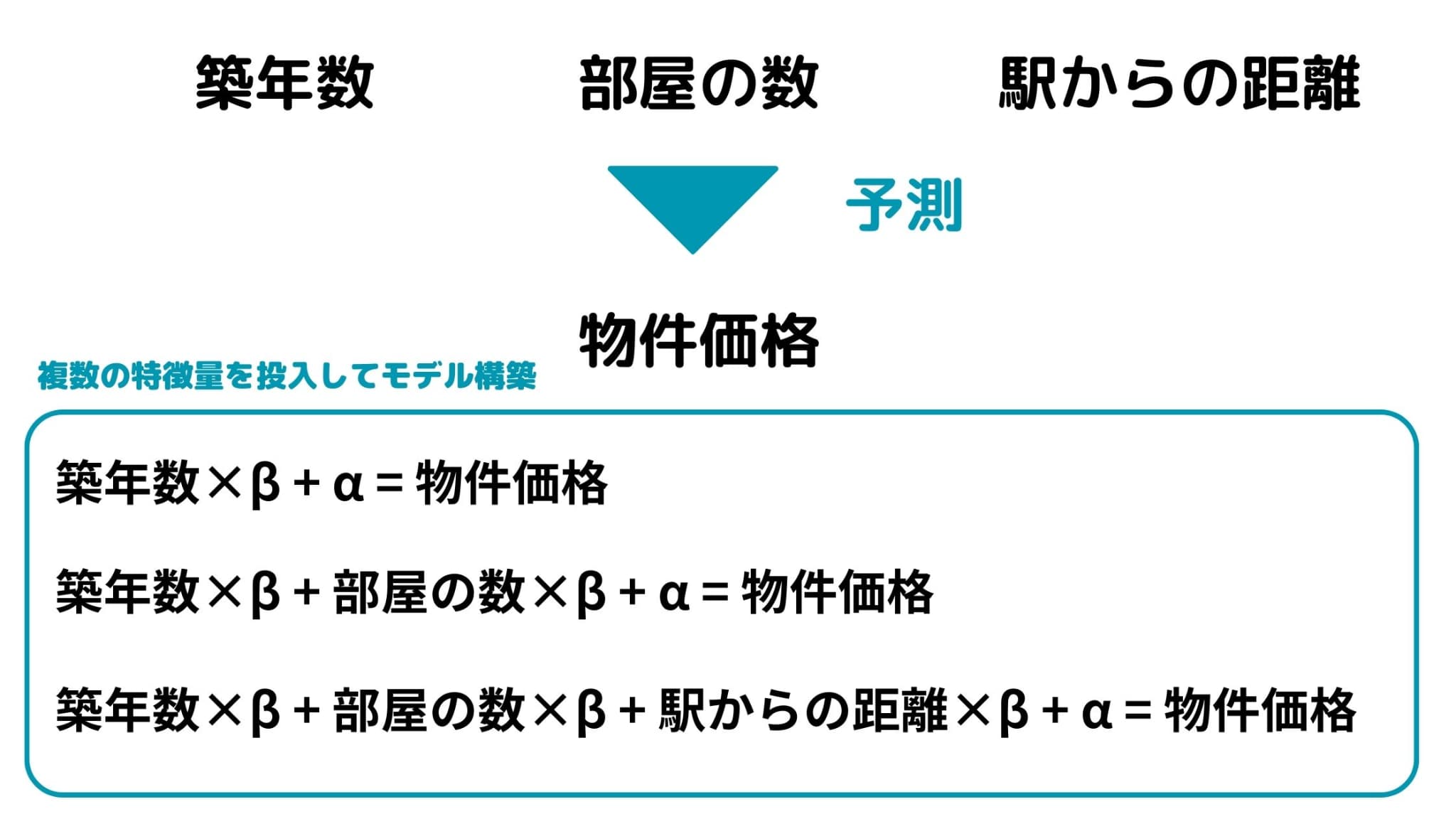 先ほどのABCさんと同じ要領で特徴量の貢献度を算出することができます。 これがまさにSHAPなのです。 ただ通常、特徴量が3つなどのような単純なケースは少なく非常に多い場合がほとんどです。 そうなると組み合わせ数が爆発的に増加するので、それに対して計算負荷をおさえつつ算出するアプローチが提案されています。 SHAPをPythonで計算してみよう!それでは、ここまで学んできたSHAP値を実際にPythonで計算していきましょう! Pythonのライブラリを利用することで簡単にSHAP値を計算することができるんです。 ここでは、よくモデル構築に使われるデータセットであるカリフォルニアの不動産価格データを題材に見ていきましょう! まずはカリフォルニアの不動産データをインポートしていきます。 # 必要なライブラリのインポート import pandas as pd import shap from sklearn.datasets import fetch_california_housing from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split # データの取得 data = fetch_california_housing() X_df = pd.DataFrame(data.data, columns=data.feature_names) y_df = pd.Series(data.target)
データを見てみましょう! X_df.head()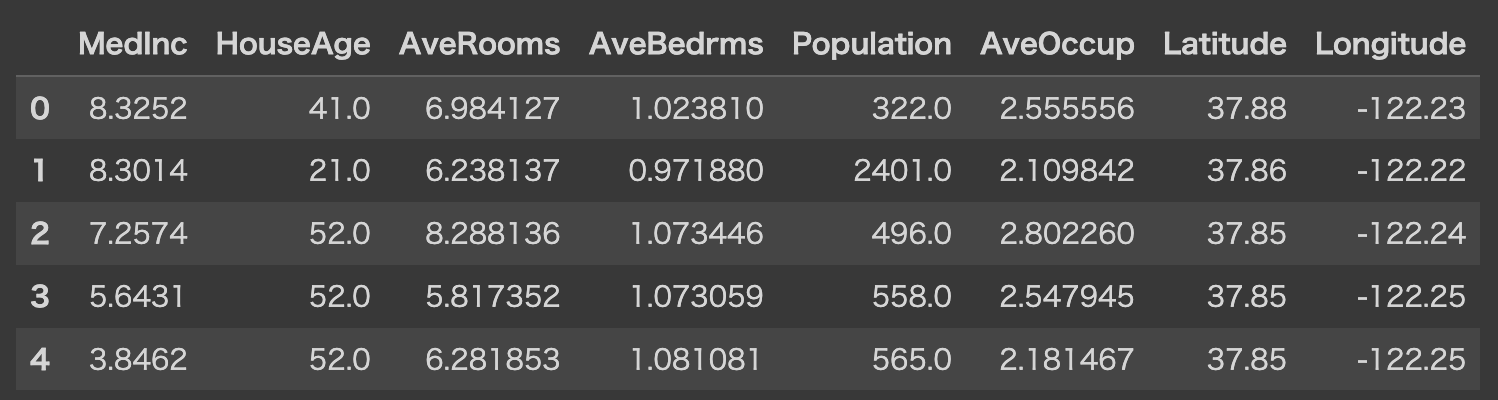 どんな特徴量があるかと言うと・・・ どんな特徴量があるかと言うと・・・それぞれ以下のような意味合いの特徴量になります。 ・MedInc:収入の中央値 ・HouseAge:築年数の平均値 ・AveRooms:部屋数の平均値 ・AveBedrms:寝室数の平均値 ・Population:人口 ・AveOccup:家の専有面積の平均値 ・Latitude:緯度 ・Longtitude:経度 それでは早速決定木でモデルを構築してSHAP値を求めてみましょう! # モデルのトレーニング model = DecisionTreeRegressor(random_state=42) model.fit(X_df, y_df) # SHAPの初期化 explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X_df) # SHAPの可視化 shap.summary_plot(shap_values, X_df)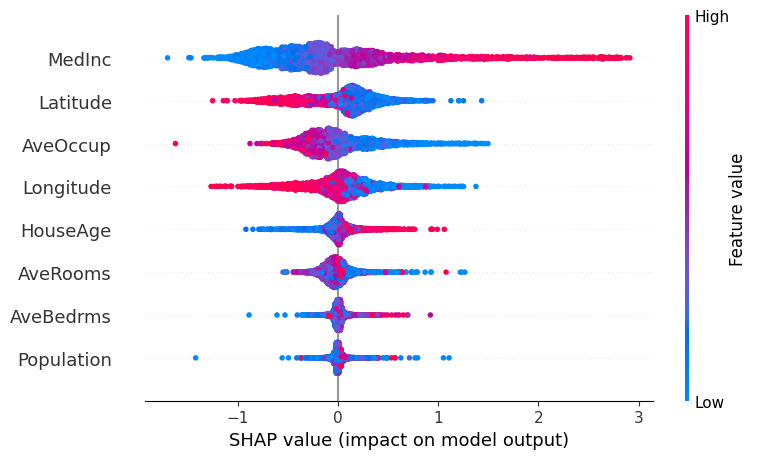 SHAP値を視覚化することができました! このグラフは横軸がSHAP値の大きさ、色が各特徴量の大きさを表したものになります。 すなわち横軸が広く広がっているものはSHAP値の振れ幅が大きく目的変数に対する寄与度も高いということになります。 そしてMedIncを見てみると、SHAP値が大きいほど赤くなっている(特徴量の値が大きい)のでMedIncと目的変数は正の相関があることが分かります。 収入と物件価格に正の相関があるのは直感的に正しいですね! 続いて以下のように記述してみましょう! shap.summary_plot(shap_values, X_test, plot_type="bar")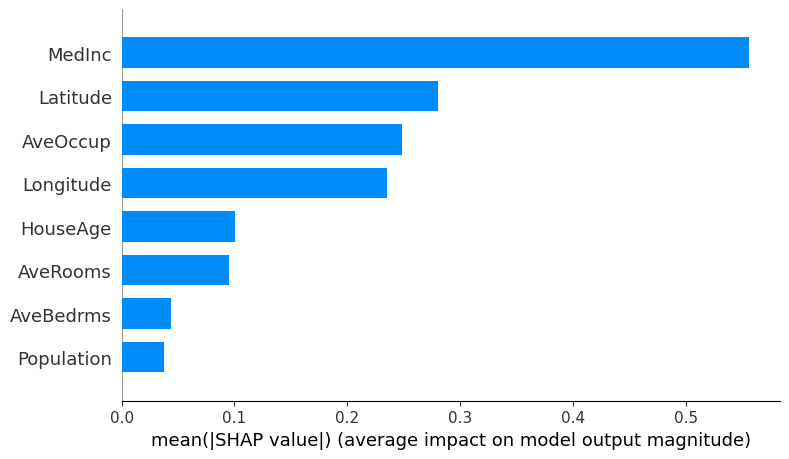 このグラフでは、シンプルにどの特徴量のSHAP値が大きいかを測ることができます! SHAP まとめここまででSHAPについて簡単に解説してきました! 機械学習モデルを作ってただ予測値を出力して終わらせるのではなく、解釈まで正しくしてビジネスに活かしていきましょう! ウマたんビジネスに活かせてこそ1人前のデータサイエンティストだ!機械学習やAIについてもっと詳しく知りたいという方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」をチェックしてみてください。 AIデータサイエンス特化スクール「スタアカ」  【価格】ライトプラン:1280円/月 プレミアムプラン:149,800円【オススメ度】【サポート体制】【受講形式】オンライン形式【学習範囲】データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ 【価格】ライトプラン:1280円/月 プレミアムプラン:149,800円【オススメ度】【サポート体制】【受講形式】オンライン形式【学習範囲】データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズデータサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!! 24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します! カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください! 他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。 そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています! Pythonが初めての人でも学べるようなカリキュラムしておりますので是非チェックしてみてください! ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます! ・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析 ・世界最大手小売企業のウォルマートの実データを用いた需要予測 ・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定 ・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ \今すぐ試す/スタアカの受講はこちら スタビジアカデミーでデータサイエンスをさらに深く学ぼう!
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております! スタビジアカデミーはこちら |
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。【本文地址】