| Python3 实现大众点评网酒店信息和酒店评论的网页爬取 | 您所在的位置:网站首页 › Python爬取大众点评评论源码 › Python3 实现大众点评网酒店信息和酒店评论的网页爬取 |
Python3 实现大众点评网酒店信息和酒店评论的网页爬取
|
**作者:**Mr. Ceong 链接:http://blog.csdn.net/leigaiceong/article/details/53188454 Python3 实现大众点评网酒店信息和酒店评论的网页爬取 概要本文根据已有的的”大众点评网”酒店主页的URL地址,自动抓取所需要的酒店的名称、图片、经纬度、酒店价格、星级评分、用户评论数量以及用户评论的用户ID、用户名字、评分、评论时间等,并且将爬取成功的内容存放到.txt文档中。本文是在博文http://blog.csdn.net/drdairen/article/details/51146961的基础上进行实现和完善。因此十分感谢该文作者的无私奉献!。 正文 一、基本信息 编程语言: Python 3.5.2实现平台: Eclipse for Pydev实现功能: 1.爬取酒店的基本信息(包括:酒店名称、地址、图片、经纬度、酒店价格、星级评分、用户评论数量) 2.爬取酒店的评论信息(包括:酒店评论用户ID、用户名字、房间评分、服务评分、总评分、评价时间、酒店评论内容)实现代码: http://download.csdn.net/detail/qq_22107075/9668373注意事项: 1.在抓取大众点评网的评论的时候如果访问大众点评网的频率过于频繁会导致大众点评网的反爬虫技术短暂屏蔽PC的IP地址(时长不定) 2.本文通过设置Python的time模块的sleep time来限定爬取评论的时间 二、实现过程本文爬取的内容为广州市天河区附近用户评论数大于100的热门酒店(按评论数排名,如下图)。 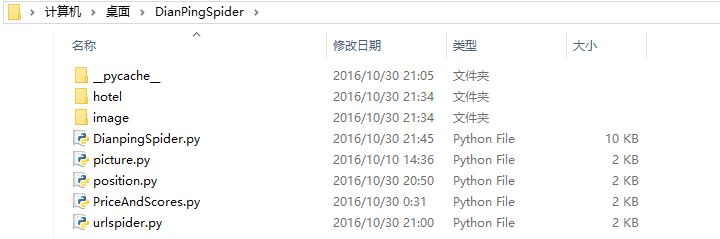 DianpingSpider.py 主程序 picture.py 爬取酒店图片 position.py 根据POI参数转换成经纬度 PriceAndScores.py 爬取酒店价格和星级评分 urlspider.py 爬取广州市天河区附近热门酒店的URL 文件夹 hotel 存放成功爬取的酒店信息和用户评论 文件夹 image 存放成功爬取的酒店图片 模块解说 (1)DianpingSpider.py 该模块是实现本文的主程序,只要运行本程序即可实验本文功能。主要功能是调用另外四个模块及实现其他未实现的功能(详情请看代码) DianpingSpider.py 主程序 picture.py 爬取酒店图片 position.py 根据POI参数转换成经纬度 PriceAndScores.py 爬取酒店价格和星级评分 urlspider.py 爬取广州市天河区附近热门酒店的URL 文件夹 hotel 存放成功爬取的酒店信息和用户评论 文件夹 image 存放成功爬取的酒店图片 模块解说 (1)DianpingSpider.py 该模块是实现本文的主程序,只要运行本程序即可实验本文功能。主要功能是调用另外四个模块及实现其他未实现的功能(详情请看代码)
实现原理为爬虫常用的Python 3模块,如:urllib.request、re、time,网上学习资料非常多,在此不作赘诉,烦请自己google。 import urllib.request import re import time import picture #获取酒店图片 import urlspider #获取酒店的主页网址 import position #获取酒店的经纬度 import os import random import PriceAndScores #获取酒店的价格和星级评分 # 统计所有酒店的评价信息,存入文本 def getRatingAll(fileIn): count =0 # 计数,显示进度 websitenumber=0 for line in open(fileIn,'r'): # 逐行读取并处理文件,即hotel的url count=line.split('\t')[0] line=line.split('\t')[1] websitenumber+=1 print("正在抓取第%s个网址的酒店信息"%(websitenumber)) try: print("正在抓取第%s家酒店的信息,网址为%s"%(count,line.strip('\n'))) # 获取酒店编号 hotelid = line.strip('\n').split('/')[4] #print('该酒店的hotelid是 : ', hotelid) # 拼凑出该酒店第一页"评论页面"的url url = line.strip('\n') + "/review_more" #print('该酒店第一页"评论页面"的url是', url) # 模拟浏览器,打开url headers = ('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko') opener = urllib.request.build_opener() opener.addheaders = [headers] data = opener.open(url).read() #print(data) 当访问大众点评网过于次数频繁的时候,大众点评网的反爬虫技术会封锁本机的IP地址,此时data就会出现异常,无法打印正常的html data = data.decode('utf-8', 'ignore') #print(data) # 获取酒店用户评论数目 rate_number = re.compile(r'全部点评\((.*?)\)', re.DOTALL).findall(data) rate_number = int(''.join(rate_number)) # 把列表转换为str,把可迭代列表里面的内容用‘ ’连接起来成为str,再进行类型转换 print("第%d家酒店的评论数为%s" % (websitenumber, rate_number)) if(rate_number= add: D = D - plus B += to_base36(D) if D > H: I = E H = D A = int(B[:I], digi) F = int(B[I+1:], digi) L = (A + F - int(G)) / 2 latitude = float(F - L) / 100000 longitude = float(L) / 100000 return longitude,latitude #----------------------------- #-----------测试程序----------- #----------------------------- if __name__ == '__main__': (longitude,latitude)=getPosition('IJGDHFZVIBRDHR') print("longitude:%s°E,latitude:%s°N"%(longitude,latitude))(4) picture.py 本模块主要实现酒店图片的爬取。每个酒店的主页都会有几张该酒店的图片,我们将它们中的前5张(有些酒店少于5张)给爬取下来,存放到“./image”文件夹中。主要思路是将html中的图片对应链接给爬取出来,然后保存到该文件夹下即可。 |
【本文地址】
公司简介
联系我们