| flink的几个组件的作用 | 您所在的位置:网站首页 › Flink架构的组成部分 › flink的几个组件的作用 |
flink的几个组件的作用
|
客户端不是运行时和程序执行 的一部分,但它用于准备并发送dataflow(JobGraph)给 Master(JobManager),然后,客户端断开连接或者维持连接以等待接收计算结果。当 Flink 集 群启 动 后 , 首 先 会 启 动 一 个 JobManger 和一个或多个的TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming 的任务),也可以不结束并等待结果返回。JobManager 主 要 负 责 调 度 Job 并 协 调 Task 做 checkpoint, 职 责 上 很 像Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个Task,Task 为线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
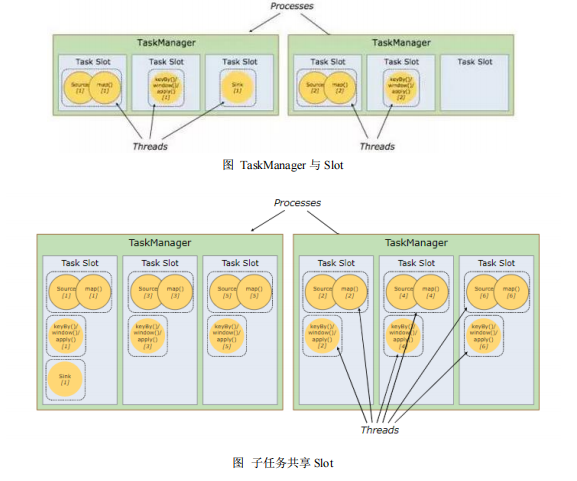
⚫TaskManger 与 Slots (说人话就是,每个小弟也是自己要管理自己滴,每个小弟都是一个机器,他们有个JVM进程,进程可以有多个线程,假如我有1GB内存,我分给三个部分(slot),那就是每个333.3MB) Flink 中每一个 worker(TaskManager)都是一个 JVM 进程,它可能会在独立的线程上执行一个或多个 subtask。为了控制一个 worker 能接收多少个 task,worker 通过 task slot 来进行控制(一个 worker 至少有一个 task slot)。每个 task slot 表示 TaskManager 拥有资源的一个固定大小的子集。假如一个TaskManager 有三个 slot,那么它会将其管理的内存分成三份给各个 slot。资源 slot化意味着一个 subtask 将不需要跟来自其他 job 的 subtask 竞争被管理的内存,取而代之的是它将拥有一定数量的内存储备。需要注意的是,这里不会涉及到 CPU 的隔离,slot 目前仅仅用来隔离 task 的受管理的内存。通过调整 task slot 的数量,允许用户定义 subtask 之间如何互相隔离。如果一个 TaskManager 一个 slot,那将意味着每个 task group 运行在独立的 JVM 中(该 JVM可能是通过一个特定的容器启动的),而一个 TaskManager 多个 slot 意味着更多的subtask 可以共享同一个 JVM。而在同一个 JVM 进程中的 task 将共享 TCP 连接(基于多路复用)和心跳消息。它们也可能共享数据集和数据结构,因此这减少了每个task 的负载。
(说人话就是,一个jobManager有三个小弟taskManager,每个TaskManager有三个slot,假设有一个任务需要4个slot,Job把它分给A,B两个TaskManager,A,B同一个job,所以B可以使用A的计算资源) 默认情况下,Flink 允许子任务共享 slot,即使它们是不同任务的子任务(前提是它们来自同一个 job)。 这样的结果是,一个 slot 可以保存作业的整个管道。Task Slot 是静态的概念,是指 TaskManager 具有的并发执行能力,可以通过参数 taskmanager.numberOfTaskSlots 进行配置;而并行度 parallelism 是动态概念,即 TaskManager 运行程序时实际使用的并发能力,可以通过参数 parallelism.default进行配置。也就是说,假设一共有 3 个 TaskManager,每一个 TaskManager 中的分配 3 个TaskSlot,也就是每个 TaskManager 可以接收 3 个 task,一共 9 个 TaskSlot,如果我们设置 parallelism.default=1,即运行程序默认的并行度为 1,9 个 TaskSlot 只用了 1个,有 8 个空闲,因此,设置合适的并行度才能提高效率 ⚫程序与数据流(DataFlow) 所有的 Flink 程序都是由三部分组成的: Source 、Transformation 和 Sink。Source 负责读取数据源,Transformation 利用各种算子进行处理加工,Sink 负责输出。 在运行时,Flink 上运行的程序会被映射成“逻辑数据流”(dataflows),它包含了这三部分。每一个 dataflow 以一个或多个 sources 开始以一个或多个 sinks 结束。dataflow 类似于任意的有向无环图(DAG)。在大部分情况下,程序中的转换运算(transformations)跟 dataflow 中的算子(operator)是一一对应的关系,但有时候,一个 transformation 可能对应多个 operator。 ⚫执行图(ExecutionGraph) 由 Flink 程序直接映射成的数据流图是 StreamGraph,也被称为逻辑流图,因为它们表示的是计算逻辑的高级视图。为了执行一个流处理程序,Flink 需要将逻辑流图转换为物理数据流图(也叫执行图),详细说明程序的执行方式。Flink 中的执行图可以分成四层:StreamGraph -> JobGraph ->ExecutionGraph ->物理执行图。StreamGraph根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。 JobGraph:StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。 ExecutionGraph : JobManager 根 据 JobGraph 生 成 ExecutionGraph 。ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。(不存在滴,已经物理传输给别的机器啦) ⚫并行度(Parallelism) (一个并行的任务,需要占用的slot数是整个任务最大并行的数量,也就是你设置的Parallelism在整个处理流程重最大的数量) Flink 程序的执行具有并行、分布式的特性。在执行过程中,一个流(stream)包含一个或多个分区(stream partition),而每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中彼此互不依赖地执行。一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度 ⚫分组的概念 当一个大的工程启动以后,需要做三个步骤,第一个source源读入,第二个transformer处理,第三个sink输出。 那么对于第二个处理就可以分为几个组,每个组里有几个小任务。组于组之间不可以共享slot,加入有red组的并行度为2,green组并行度为2,那么你就需要4个slot才可以。如果你不分组,那么只需要两个。⚫数据流图的划分 数据流图是否分为几个块儿是需要看数据流是怎么流的,以及并行度是否相同 举个例子,你有一个socket来了一次数据,假设就是hello wordld两个单词,此时source读取并行度为1,然后flatMap处理的还是这次的数据源,而且这个小任务的并行度也为1,那么这两个就可以被划到一个框框里。如果为二就不行了。(Map,filter,flatMap都是one-to-one关系,就是同一个数据流)。然后你想要keyby,这时候数据就会被分成不同的部分,所以此时就不再是one-to-one了,就会分成两个框,然后到输出了,如果你的sink的并行度和你keyby的并行度相同,那么这两个也可以被画到同一个框内 |
【本文地址】
公司简介
联系我们