| 索引托管模式 | 您所在的位置:网站首页 › Easy-es怎么多索引查询 › 索引托管模式 |
索引托管模式
|
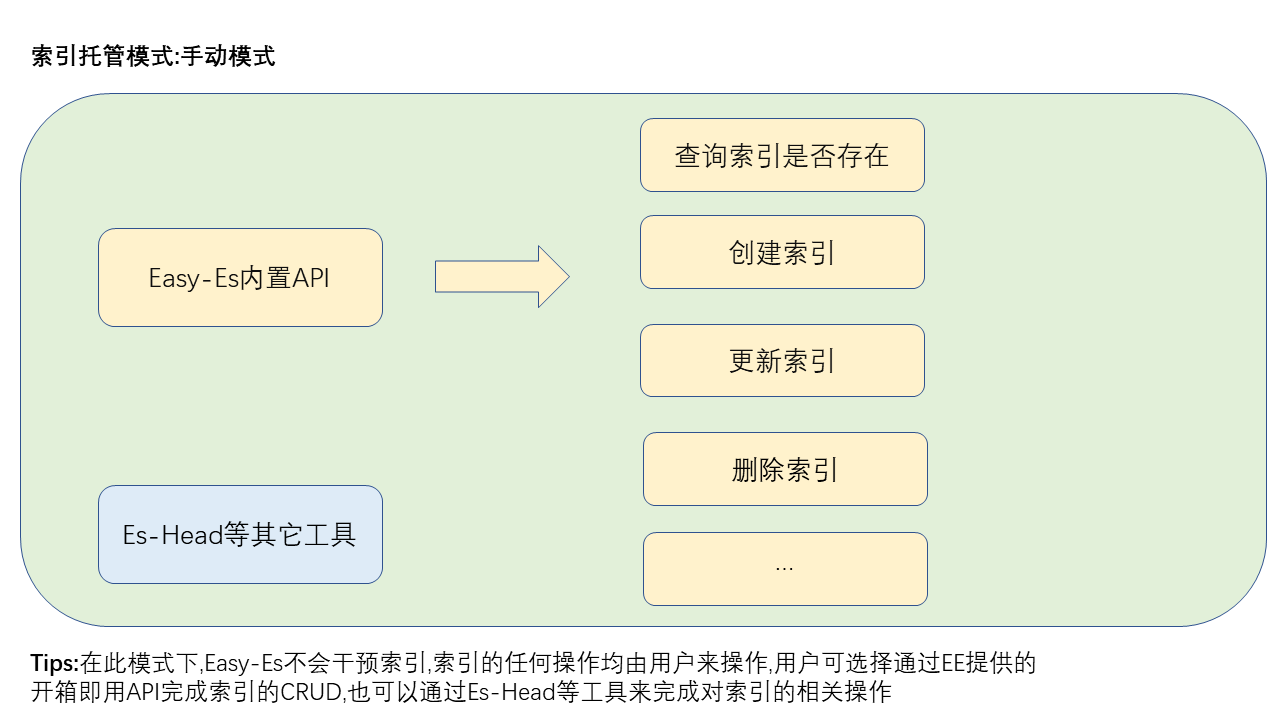
前言 ES难用,索引首当其冲,索引的创建和更新不仅复杂,而且难于维护,一旦索引有变动,就必须面对索引重建带来的服务停机和数据丢失等问题... 尽管ES官方提供了索引别名机制来解决问题,但门槛依旧很高,步骤繁琐,在生产环境中由人工操作非常容易出现失误带来严重的问题. 为了解决这些痛点,Easy-Es提供了多种策略,将用户彻底从索引的维护中解放出来,我们提供了多种索引处理策略,来满足不同用户的个性化需求. 通过对索引的初体验,相信您也可以更深体会到EE的成熟度和易用性. 其中全自动平滑模式,首次采用全球领先的"哥哥你不用动,EE我全自动"的模式,索引的创建,更新,数据迁移等所有全生命周期均无需用户介入,由EE全自动完成,过程零停机,连索引类型都可智能自动推断,一条龙服务,包您满意.是全球开源首创,充分借鉴了JVM垃圾回收算法思想,史无前例,尽管网上已有平滑过渡方案,但并非全自动,过程依旧靠人工介入,使用Easy-Es后则无这些烦恼. 警告: 新手上路可尽量选择手动挡一键模式,追求生产环境稳定性,建议您采用手动挡模式,我们手动挡也提供了非常友好的一键创建功能,使用起来也是甜甜的. 自动挡模式不建议上生产,以自动驾驶为例,目前自动挡大概能达到L2+级别的辅助程度,因为大多数开发者无法权衡好迁移时间,致使最大重试次数和重试间隔配置不理想导致迁移失败,因此并不建议在生产环境使用自动挡模式,该模式仅作为开发环境为开发者减负的体验版,否则因索引迁移对生产环境数据及机器负载带来的负面影响本框架概不承担. # 模式一:手动模式(手动挡,默认开启此模式,生产环境推荐)在此模式下,索引的所有维护工作EE框架均不介入,由用户自行处理,EE提供了开箱即用的索引CRUD相关API,您可以选择使用该API手动维护索引,由于API高度完善,尽管是手动挡,但使用起来依旧简单到爆,一行代码搞定索引创建.当然您亦可通过es-head等工具来维护索引,总之在此模式下,您拥有更高的自由度,比较适合那些质疑EE框架的保守用户或追求极致灵活度的用户使用,类似汽车的手动挡 手动挡模式下,EE提供了如下API,供用户进行便捷调用: indexName需要用户手动指定 对象 Wrapper 为 条件构造器 // 获取索引信息 GetIndexResponse getIndex(); // 获取指定索引信息 GetIndexResponse getIndex(String indexName); // 是否存在索引 Boolean existsIndex(String indexName); // 根据实体及自定义注解一键创建索引 Boolean createIndex(); // 创建索引 Boolean createIndex(LambdaEsIndexWrapper wrapper); // 更新索引 Boolean updateIndex(LambdaEsIndexWrapper wrapper); // 删除指定索引 Boolean deleteIndex(String indexName); 1234567891011121314
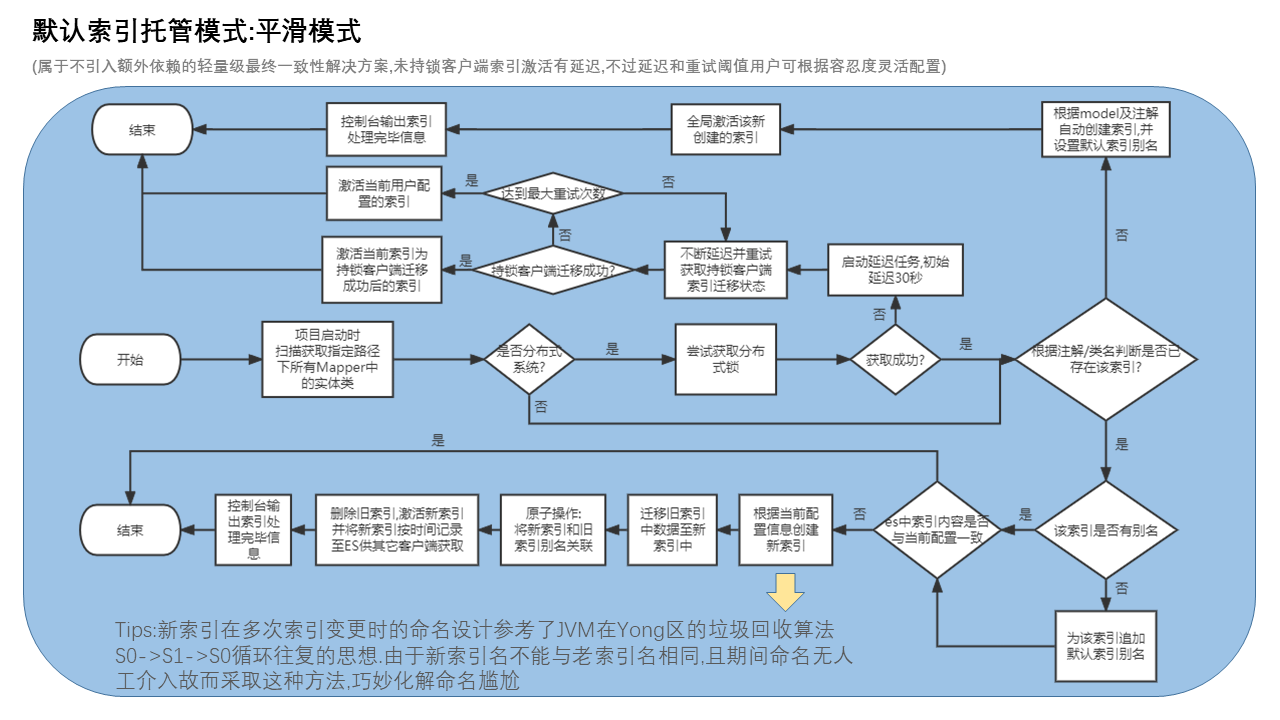
上述API,我们仅演示创建索引,其它过于简单,不在这里赘述,如有需要可移步至源码test模块查看. 通过API手动创建索引,我们提供了两种方式 -方式一:根据实体类及自定义注解一键创建(推荐),99.9%场景适用 /** * 实体类信息 **/ @Data @Settings(shardsNum = 3, replicasNum = 2) @IndexName(value = "easyes_document") public class Document { /** * es中的唯一id,如果你想自定义es中的id为你提供的id,比如MySQL中的id,请将注解中的type指定为customize或直接在全局配置文件中指定,如此id便支持任意数据类型) */ @IndexId(type = IdType.CUSTOMIZE) private String id; /** * 文档标题,不指定类型默认被创建为keyword类型,可进行精确查询 */ private String title; /** * 文档内容,指定了类型及存储/查询分词器 */ @HighLight(mappingField = "highlightContent") @IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_MAX_WORD) private String content; // 省略其它字段... } 123456789101112131415161718192021222324 @Test public void testCreateIndexByEntity() { // 然后通过该实体类的mapper直接一键创建,非常傻瓜级 documentMapper.createIndex(); } 12345提示 实体类中的注解用法可参考注解章节,整体比较傻瓜级,和MP中的注解用法高度相似. -方式二:通过api创建,不推荐,此方式是框架诞生最早提供的方案,目前已过时,每个需要被索引的字段都需要处理,比较繁琐 @Test @Deprecated public void testCreatIndex() { LambdaEsIndexWrapper wrapper = new LambdaEsIndexWrapper(); // 此处简单起见 索引名称须保持和实体类名称一致,字母小写 后面章节会教大家更如何灵活配置和使用索引 wrapper.indexName(Document.class.getSimpleName().toLowerCase()); // 此处将文章标题映射为keyword类型(不支持分词),文档内容映射为text类型,可缺省 // 支持分词查询,内容分词器可指定,查询分词器也可指定,,均可缺省或只指定其中之一,不指定则为ES默认分词器(standard) wrapper.mapping(Document::getTitle, FieldType.KEYWORD) .mapping(Document::getContent, FieldType.TEXT,Analyzer.IK_MAX_WORD,Analyzer.IK_MAX_WORD); // 如果上述简单的mapping不能满足你业务需求,可自定义mapping // wrapper.mapping(Map); // 设置分片及副本信息,3个shards,2个replicas,可缺省 wrapper.settings(3,2); // 如果上述简单的settings不能满足你业务需求,可自定义settings // wrapper.settings(Settings); // 设置别名信息,可缺省 String aliasName = "daily"; wrapper.createAlias(aliasName); // 创建索引 boolean isOk = documentMapper.createIndex(wrapper); Assert.assertTrue(isOk); } 1234567891011121314151617181920212223242526272829温馨提示 实体类中,id字段不需要创建索引,否则会报错. 由于ES索引改动自动重建的特性,因此本接口设计时将创建索引所需的mapping,settings,alias信息三合一了,尽管其中每一项配置都可缺省,但我们仍建议您在创建索引前提前规划好以上信息,可以规避后续修改带来的不必要麻烦,若后续确有修改,您仍可以通过别名迁移的方式(推荐,可平滑过渡),或删除原索引重新创建的方式进行修改. # 模式二:自动托管之平滑模式(自动挡-雪地模式) 开发环境数据量不大的情况下推荐使用,省心在此模式下,索引的创建更新数据迁移等全生命周期用户均不需要任何操作即可完成,过程零停机,用户无感知,可实现在生产环境的平滑过渡,类似汽车的自动档-雪地模式,平稳舒适,彻底解放用户,尽情享受自动驾驶的乐趣! 需要值得特别注意的是,在自动托管模式下,系统会自动生成一条名为ee-distribute-lock的索引,该索引为框架内部使用,用户可忽略,若不幸因断电等其它因素极小概率下发生死锁,可删除该索引即可.另外,在使用时如碰到索引变更,原索引名称可能会被追加后缀_s0或_s1,不必慌张,这是全自动平滑迁移零停机的必经之路,索引后缀不影响使用,框架会自动激活该新索引.关于_s0和_s1后缀,在此模式下无法避免,因为要保留原索引数据迁移,又不能同时存在两个同名索引,凡是都是要付出代价的,如果您不认可此种处理方式,可继续往下看,总有一种适合您。 其核心处理流程梳理如下图所示,不妨结合源码看,更容易理解:
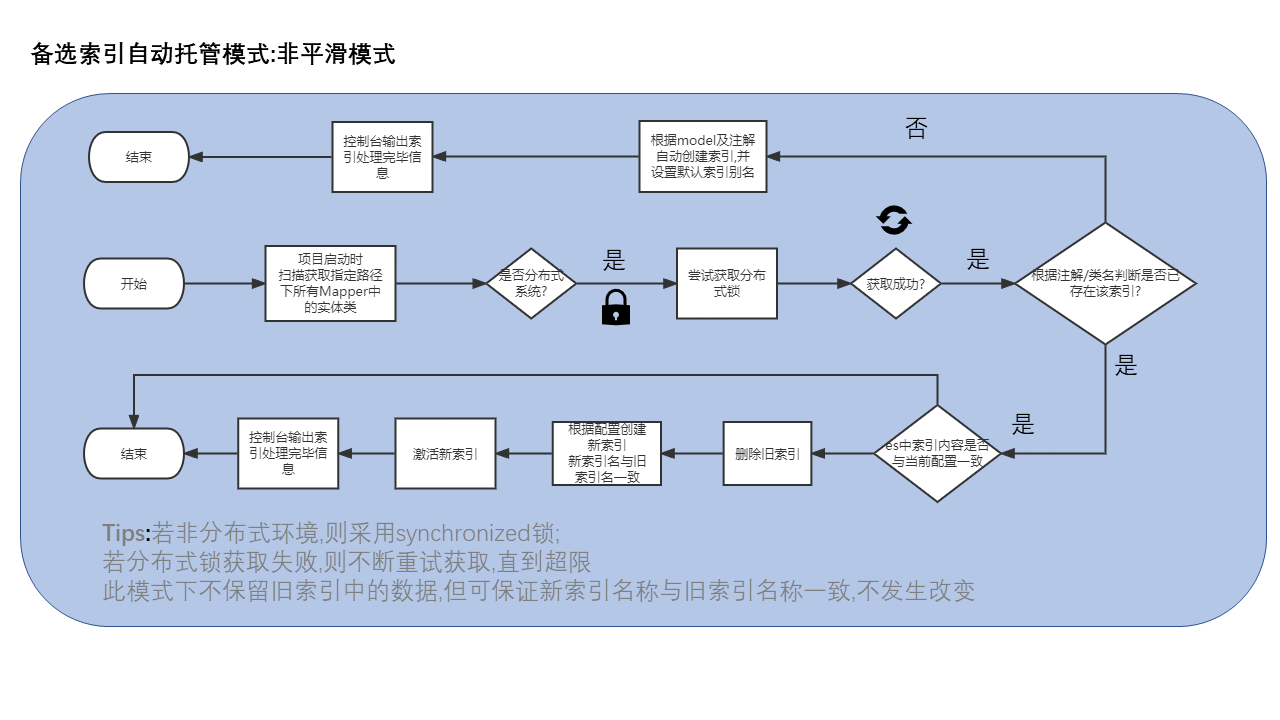
在此模式下,索引额创建及更新由EE全自动异步完成,但不处理数据迁移工作,速度极快类似汽车的自动挡-运动模式,简单粗暴,弹射起步! 适合在开发及测试环境使用,当然如果您使用logstash等其它工具来同步数据,亦可在生产环境开启此模式,在此模式下不会出现_s0和_s1后缀,索引会保持原名称.
提示 以上两种自动模式中,索引信息主要依托于实体类,如果用户未对该实体类进行任何配置,EE依然能够根据字段类型智能推断出该字段在ES中的存储类型,此举可进一步减轻开发者负担,对刚接触ES的小白更是福音. 当然,仅靠框架自动推断是不够的,我们仍然建议您在使用中尽量进行详细的配置,以便框架能自动创建出生产级的索引.举个例子,例如String类型字段,框架无法推断出您实际查询中对该字段是精确查询还是分词查询,所以它无法推断出该字段到底用keyword类型还是text类型,倘若是text类型,用户期望的分词器是什么? 这些都需要用户通过配置告诉框架,否则框架只能按默认值进行创建,届时将不能很好地完成您的期望. 自动推断类型的优先级 < 用户通过注解指定的类型优先级 自动推断映射表: JAVA ES byte byte short short int integer long long float float double double BigDecimal keyword char keyword String keyword_text boolean boolean Date date LocalDate date LocalDateTime date List text ... ..."自动挡"模式下的最佳实践示例: @Data @IndexName(shardsNum = 3,replicasNum = 2) // 可指定分片数,副本数,若缺省则默认均为1 public class Document { /** * es中的唯一id,如果你想自定义es中的id为你提供的id,比如MySQL中的id,请将注解中的type指定为customize,如此id便支持任意数据类型) */ @IndexId(type = IdType.CUSTOMIZE) private Long id; /** * 文档标题,不指定类型默认被创建为keyword_text类型,可进行精确查询 */ private String title; /** * 文档内容,指定了类型及存储/查询分词器 */ @HighLight(mappingField="highlightContent") @IndexField(fieldType = FieldType.TEXT, analyzer = Analyzer.IK_SMART, searchAnalyzer = Analyzer.IK_MAX_WORD) private String content; /** * 作者 加@TableField注解,并指明strategy = FieldStrategy.NOT_EMPTY 表示更新的时候的策略为 创建者不为空字符串时才更新 */ @IndexField(strategy = FieldStrategy.NOT_EMPTY) private String creator; /** * 创建时间 */ @IndexField(fieldType = FieldType.DATE, dateFormat = "yyyy-MM-dd HH:mm:ss") private Date gmtCreate; /** * es中实际不存在的字段,但模型中加了,为了不和es映射,可以在此类型字段上加上 注解@TableField,并指明exist=false */ @IndexField(exist = false) private String notExistsField; /** * 地理位置经纬度坐标 例如: "40.13933715136454,116.63441990026217" */ @IndexField(fieldType = FieldType.GEO_POINT) private String location; /** * 图形(例如圆心,矩形) */ @IndexField(fieldType = FieldType.GEO_SHAPE) private String geoLocation; /** * 自定义字段名称 */ @IndexField(value = "wu-la") private String customField; /** * 高亮返回值被映射的字段 */ private String highlightContent; } 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354# 配置启用模式以上三种模式的配置,您只需要在您项目的配置文件application.properties或application.yml中加入一行配置process_index_mode即可: easy-es: global-config: process_index_mode: smoothly #smoothly:平滑模式, not_smoothly:非平滑模式, manual:手动模式(默认) async-process-index-blocking: true # 异步处理索引是否阻塞主线程 默认阻塞 distributed: false # 项目是否分布式环境部署,默认为true, 如果是单机运行可填false,将不加分布式锁,效率更高. reindexTimeOutHours: 72 # 重建索引超时时间 单位小时,默认72H 根据迁移索引数据量大小灵活指定 123456若缺省此行配置,则默认开启手动挡模式. 温馨提示 自动挡模式下,如果索引托管成功,则会在控制台打印 Congratulations auto process index by Easy-Es is done ! 自动挡模式下,如果索引托管失败,则会在控制台打印 Unfortunately, auto process index by Easy-Es failed... 以及异常日志,可根据异常日志信息去排查 如果索引托管失败,此时用户调用了insert相关API插入数据,由于索引不存在,es(非框架)会自动为用户创建默认索引,创建的索引字段类型为keyword_text类型,并非用户通过注解指定的,因此出现这种情况别问我为啥没生效,因为索引托管因为你的配置或环境原有问题失败了. 运行测试模块时强烈建议开启异步处理索引阻塞主线程,否则测试用例跑完后,主线程退出,但异步线程可能还没跑完,可能出现死锁,若不幸出现死锁,删除ee-distribute-lock即可. 生产环境或迁移数据量比较大的情况下,可以配置开启非阻塞,这样服务启动更快. 以上三种模式,用户可根据实际需求灵活选择,自由体验,在使用过程中如有任何意见或建议可反馈给我们,我们将持续优化和改进, EE在索引托管采用了策略+工厂设计模式,未来如果有更多更优模式,可以在不改动原代码的基础上轻松完成拓展,符合开闭原则,也欢迎各路开源爱好者贡献更多模式PR! 我们将持续秉承把复杂留给框架,把易用留给用户这一理念,砥砺前行.上述所有API对应代码演示皆可参考源码test模块->test目录->index包下代码 |
【本文地址】