| 一文通透位置编码:从标准位置编码、旋转位置编码RoPE到ALiBi、LLaMA 2 Long | 您所在的位置:网站首页 › 3bd906018c编码 › 一文通透位置编码:从标准位置编码、旋转位置编码RoPE到ALiBi、LLaMA 2 Long |
一文通透位置编码:从标准位置编码、旋转位置编码RoPE到ALiBi、LLaMA 2 Long
|
前言
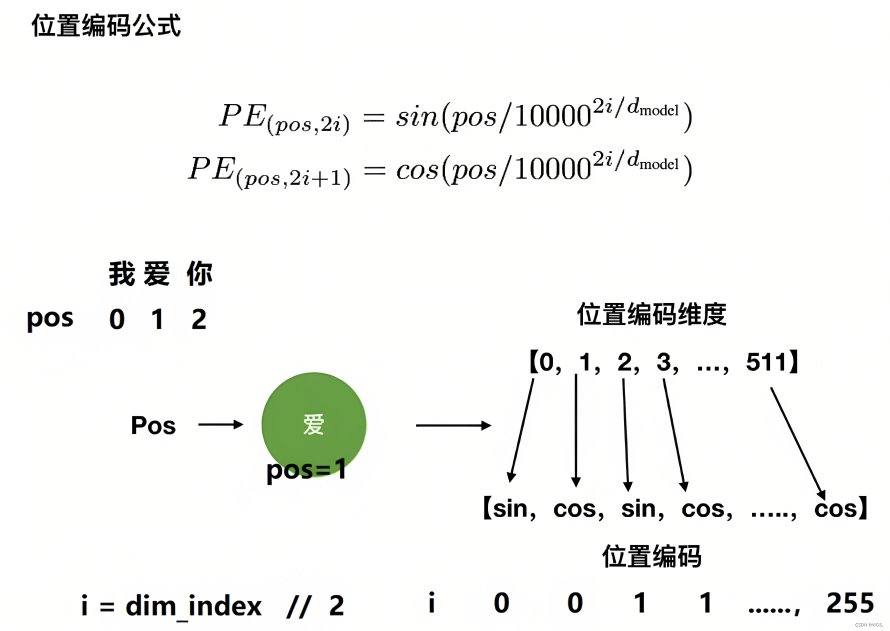
关于位置编码和RoPE 应用广泛,是很多大模型使用的一种位置编码方式,包括且不限于LLaMA、baichuan、ChatGLM等等我之前在本博客中的另外两篇文章中有阐述过(一篇是关于LLaMA解读的,一篇是关于transformer从零实现的),但自觉写的不是特别透彻好懂 再后来在我参与主讲的类ChatGPT微调实战课中也有讲过,但有些学员依然反馈RoPE不是特别好理解考虑到只要花足够多的时间 心思 投入,没有写不清楚的,讲课更是如此,故为彻底解决这个位置编码/RoPE的问题,我把另外两篇文章中关于位置编码的内容抽取出来,并不断深入、扩展、深入,比如其中最关键的改进是两轮改进,一个12.16那天,一个12.21那天 12.16那天 小的改进是把“1.1 标准位置编码的起源”中,关于i、2i、2i+1的一系列计算结果用表格规整了下 如此,相比之前把一堆数字一堆,表格更加清晰、一目了然 大的改进是把“3.1.1 第一种形式的推导(通俗易懂版)”的细节重新梳理了以下,以更加一目了然、一看即懂,可能是全网关于RoPE最通俗细致的推导12.21那天 把RoPE的本质给强调出来最终成为本文 第一部分 transformer原始论文中的标准位置编码如此篇文章《Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT》所述,RNN的结构包含了序列的时序信息,而Transformer却完全把时序信息给丢掉了,比如“他欠我100万”,和“我欠他100万”,两者的意思千差万别,故为了解决时序的问题,Transformer的作者用了一个绝妙的办法:位置编码(Positional Encoding) 1.1 标准位置编码的起源即将每个位置编号,从而每个编号对应一个向量,最终通过结合位置向量和词向量,作为输入embedding,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了,具体怎么做呢? 如果简单粗暴的话,直接给每个向量分配一个数字,比如1到1000之间也可以用one-hot编码表示位置
至于 不要小看transformer的这个位置编码,不少做NLP多年的人也不一定对其中的细节有多深入,而网上大部分文章谈到这个位置编码时基本都是千篇一律、泛泛而谈,很少有深入,故本文还是细致探讨下 1.2 标准位置编码的示例:多图多举例考虑到一图胜千言 一例胜万语,举个例子,当我们要编码「我 爱 你」的位置向量,假定每个token都具备512维,如果位置下标从0开始时,则根据位置编码的计算公式可得『且为让每个读者阅读本文时一目了然,我计算了每个单词对应的位置编码示例(在此之前,这些示例在其他地方基本没有)』 当对
然后再叠加上embedding向量,可得
最终得到的可视化效果如下图所示
代码实现如下 “”“位置编码的实现,调用父类nn.Module的构造函数”“” class PositionalEncoding(nn.Module): def __init__(self, d_model, dropout, max_len=5000): super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(p=dropout) # 初始化dropout层 # 计算位置编码并将其存储在pe张量中 pe = torch.zeros(max_len, d_model) # 创建一个max_len x d_model的全零张量 position = torch.arange(0, max_len).unsqueeze(1) # 生成0到max_len-1的整数序列,并添加一个维度 # 计算div_term,用于缩放不同位置的正弦和余弦函数 div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)) # 使用正弦和余弦函数生成位置编码,对于d_model的偶数索引,使用正弦函数;对于奇数索引,使用余弦函数。 pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0) # 在第一个维度添加一个维度,以便进行批处理 self.register_buffer('pe', pe) # 将位置编码张量注册为缓冲区,以便在不同设备之间传输模型时保持其状态 # 定义前向传播函数 def forward(self, x): # 将输入x与对应的位置编码相加 x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False) # 应用dropout层并返回结果 return self.dropout(x)本文发布之后,有同学留言问,上面中的第11行、12行代码 div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))为什么先转换为了等价的指数+对数运算,而不是直接幂运算?是效率、精度方面有差异吗? 这里使用指数和对数运算的原因是为了确保数值稳定性和计算效率 一方面,直接使用幂运算可能会导致数值上溢或下溢。当d_model较大时,10000.0 ** (-i / d_model)中的幂可能会变得非常小,以至于在数值计算中产生下溢。通过将其转换为指数和对数运算,可以避免这种情况,因为这样可以在计算过程中保持更好的数值范围二方面,在许多计算设备和库中,指数和对数运算的实现通常比幂运算更快。这主要是因为指数和对数运算在底层硬件和软件中有特定的优化实现,而幂运算通常需要计算更多的中间值所以,使用指数和对数运算可以在保持数值稳定性的同时提高计算效率。 既然提到了这行代码,我们干脆就再讲更细致些,上面那行代码对应的公式为
其中的中括号对应的是一个从 0 到 且上述公式与这个公式是等价的
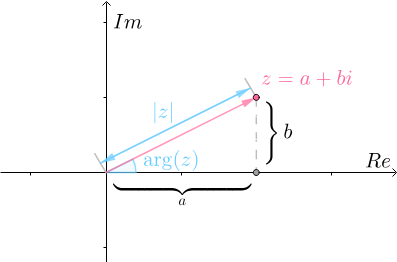
为何,原因在于 最终,再通过下面这两行代码完美实现位置编码 # 使用正弦和余弦函数生成位置编码,对于d_model的偶数索引,使用正弦函数;对于奇数索引,使用余弦函数。 pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) 第二部分 从复数到欧拉公式先复习下复数的一些关键概念 我们一般用
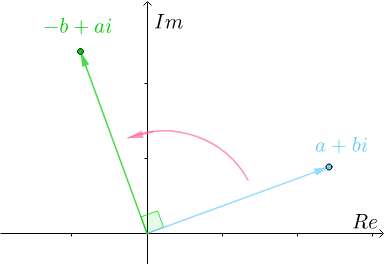
在我们的日常生活中,经常会遇到各种平移运动,为了描述这些平移运动,数学上定义了加减乘除,然还有一类运动是旋转运动,而加减乘除无法去描述旋转运动,而有了复数之后,便不一样了,此话怎讲? 根据复数的定义:
so,
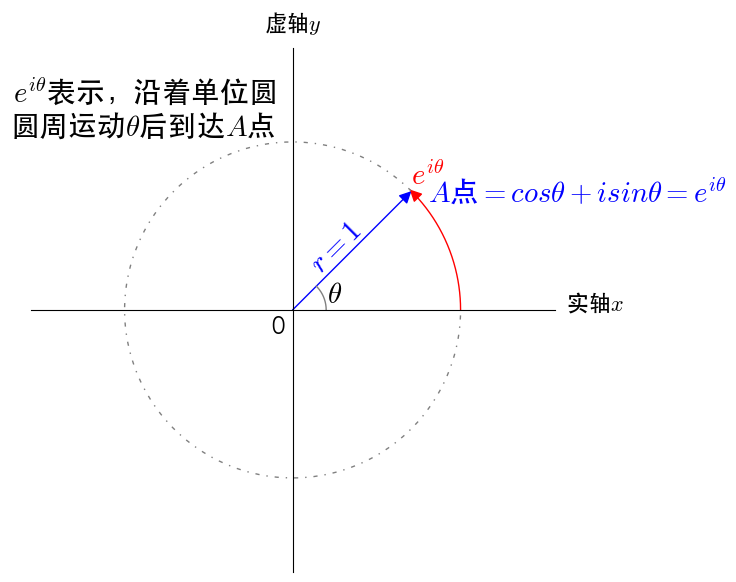
当 表达的含义在于该指数函数可以表示为实部为 该欧拉公式相当于建立了指数函数、三角函数和复数之间的桥梁,但怎么推导出来的呢,其实很简单 由于有如何直观的理解这个欧拉公式呢? 其实,可以把
根据欧拉公式 我们把复数当作向量来看待,复数的实部是
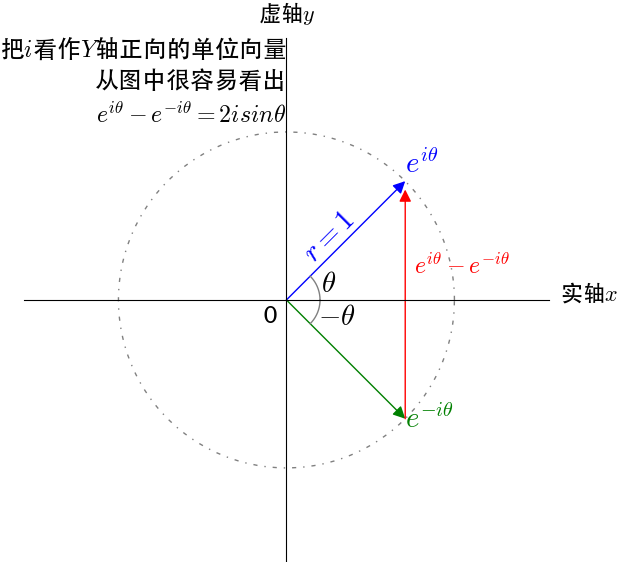
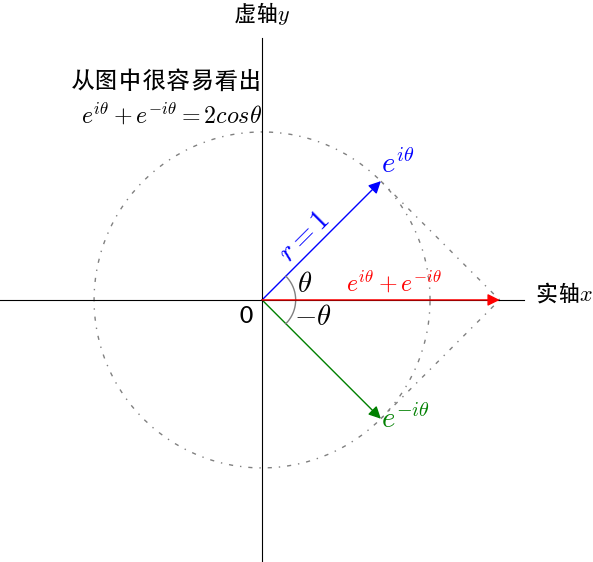
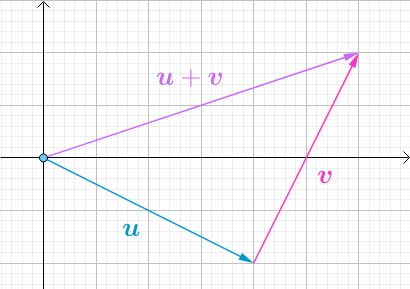
还在思考怎么得来的?很简单哦,还记得向量的加减法么?
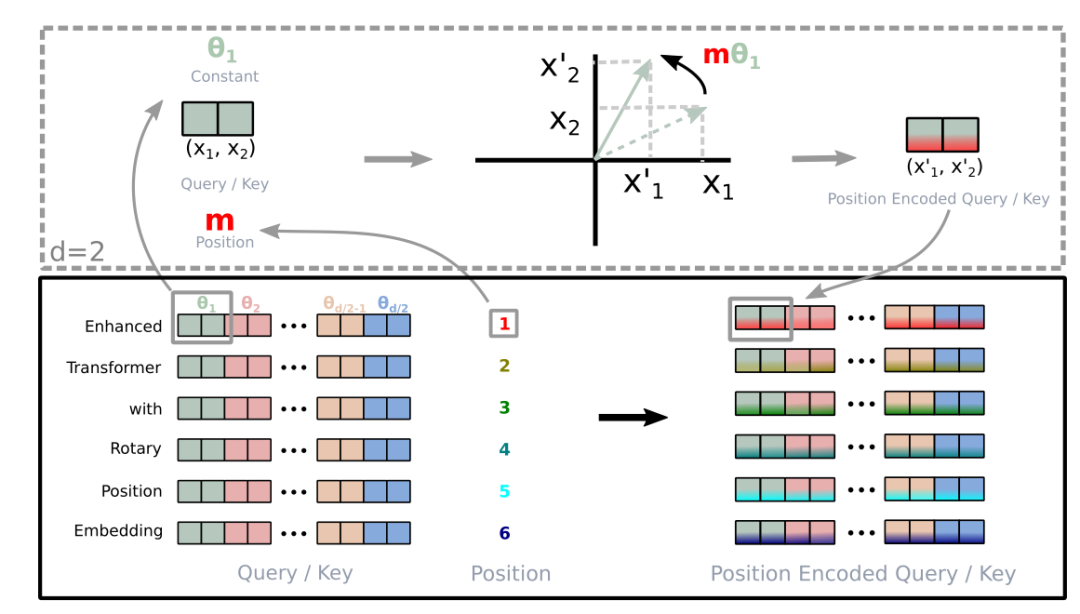
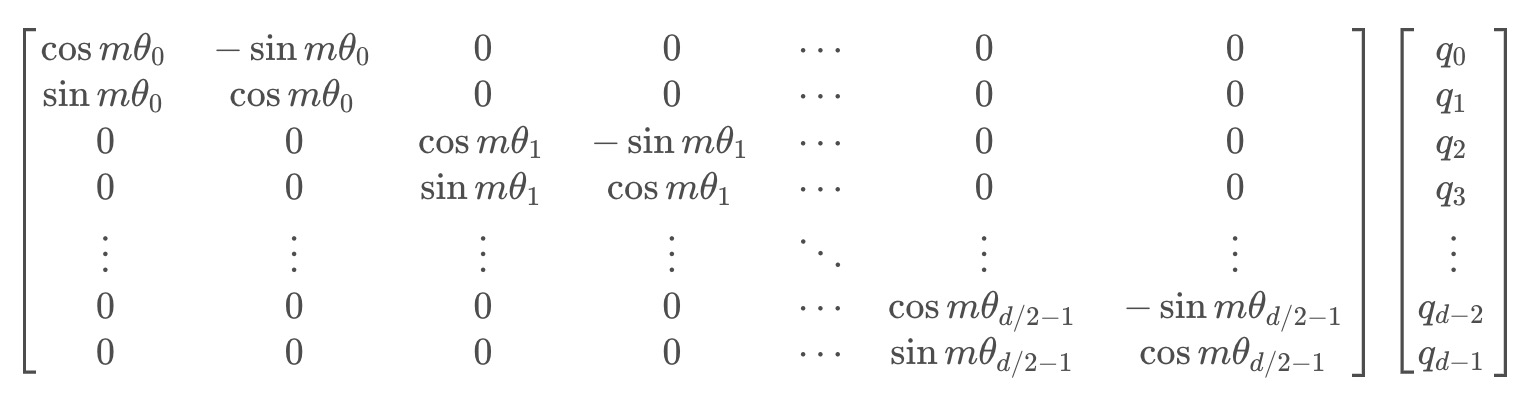
所谓旋转位置编码,其在位置编码上删除了绝对位置嵌入,而在网络的每一层增加了苏剑林等人(2021)提出的旋转位置嵌入(RoPE),其思想是采用绝对位置编码的形式 实现相对位置编码,且RoPE主要借助了复数的思想 具体来说,当咱们给self-attention中的 其中 接着论文中提出为了能利用上 token 之间的相对位置信息,假定 query 向量 这里面其实有很大的一个关键,但大部分资料甚至RoPE原始论文都不会给你特别强调出来,即为何要构造这么一个等式呢? 原因在于左边算是q和k向量的内积,而这恰好是transformer计算自注意力机制的核心一步,右边等式则意味着m与n的相对位置 如此一来,该等式便把“q和k的内积”与“它们的相对位置”给串起来了也如阿荀所说,左边是含有各自绝对位置信息的q向量和k向量,而这个等式就是RoPE追求的目标,物理含义就是通过显式传入绝对位置信息实现与传入相对位置信息对等的情况假定现在词嵌入向量的维度是两维 这里面的 Re 表示复数的实部 进一步地,然上述分别关于 首先看第一个式子,对于 至于第二个式子,根据上述过程同理,可得key向量 最后第三个式子,函数g,则可得 其中, 最后,把上面的式子一、式子二的最终结果都分别用矩阵向量乘的形式来表达就是: 接下来,我们要计算两个旋转矩阵的乘积,即中间部分的这个式子 展开之后,可得 从而有 上面都还只是针对词嵌入维度为2的情况,那对于 内积满足线性叠加性,因此任意偶数维的RoPE,我们都可以表示为二维情形的拼接,即将词嵌入向量元素按照两两一组分组 每组应用同样的旋转操作且每组的旋转角度计算方式如下: 所以简单来说 RoPE 的 self-attention 操作的流程是
与上面第一种形式的推导类似,为了引入复数,首先假设了在加入位置信息之前,原有的编码向量是二维行向量 也就是说,我们分别为 故我们希望的内积的结果带有相对位置信息,即寻求的这个 「怎么理解?很简单,当m和n表示了绝对位置之后,m与n在句子中的距离即位置差m-n,就可以表示为相对位置了,且对于复数,内积通常定义为一个复数与另一个复数的共轭的乘积」 为合理的求出该恒等式的一个尽可能简单的解,可以设定一些初始条件,比如于是,对于任意的位置为 从而上述的相乘变换也就变成了(过程中注意: 把上述式子写成矩阵形式:
而这个变换的几何意义,就是在二维坐标系下,对向量 根据刚才的结论,结合内积的线性叠加性,可以将结论推广到高维的情形。可以理解为,每两个维度一组,进行了上述的“旋转”操作,然后再拼接在一起:
由于矩阵的稀疏性,会造成计算上的浪费,所以在计算时采用逐位相乘再相加的方式进行:
其中 原理理解了,接下来可以代码实现旋转位置编码,考虑到LLaMA本身的实现不是特别好理解,所以我们先通过一份非LLaMA实现的版本,最后再看下LLaMA实现的版本 对于,非LLaMA版的实现,其核心就是实现下面这三个函数 (再次强调,本份关于RoPE的非LLaMA版的实现 与上面和之后的代码并非一体的,仅为方便理解RoPE的实现) 3.2.1 非LLaMA版的实现 3.2.1.1 sinusoidal_position_embedding的编码实现sinusoidal_position_embedding:这个函数用来生成正弦形状的位置编码。这种编码用来在序列中的令牌中添加关于相对或绝对位置的信息 def sinusoidal_position_embedding(batch_size, nums_head, max_len, output_dim, device): # (max_len, 1) position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(-1) # (output_dim//2) # 即公式里的i, i的范围是 [0,d/2] ids = torch.arange(0, output_dim // 2, dtype=torch.float) theta = torch.pow(10000, -2 * ids / output_dim) # (max_len, output_dim//2) # 即公式里的:pos / (10000^(2i/d)) embeddings = position * theta # (max_len, output_dim//2, 2) embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1) # (bs, head, max_len, output_dim//2, 2) # 在bs维度重复,其他维度都是1不重复 embeddings = embeddings.repeat((batch_size, nums_head, *([1] * len(embeddings.shape)))) # (bs, head, max_len, output_dim) # reshape后就是:偶数sin, 奇数cos了 embeddings = torch.reshape(embeddings, (batch_size, nums_head, max_len, output_dim)) embeddings = embeddings.to(device) return embeddings一般的文章可能解释道这个程度基本就over了,但为了让初学者一目了然计,我还是再通过一个完整的示例,来一步步说明上述各个步骤都是怎么逐一结算的,整个过程和之前此文里介绍过的transformer的位置编码本质上是一回事.. 为方便和transformer的位置编码做对比,故这里也假定output_dim = 512 首先,我们有 ids 张量,当 output_dim 为 512 时,则
RoPE:这个函数将相对位置编码(RoPE)应用到注意力机制中的查询和键上。这样,模型就可以根据相对位置关注不同的位置 import torch import torch.nn as nn import torch.nn.functional as F import math def RoPE(q, k): # q,k: (bs, head, max_len, output_dim) batch_size = q.shape[0] nums_head = q.shape[1] max_len = q.shape[2] output_dim = q.shape[-1] # (bs, head, max_len, output_dim) pos_emb = sinusoidal_position_embedding(batch_size, nums_head, max_len, output_dim, q.device) # cos_pos,sin_pos: (bs, head, max_len, output_dim) # 看rope公式可知,相邻cos,sin之间是相同的,所以复制一遍。如(1,2,3)变成(1,1,2,2,3,3) cos_pos = pos_emb[..., 1::2].repeat_interleave(2, dim=-1) # 将奇数列信息抽取出来也就是cos 拿出来并复制 sin_pos = pos_emb[..., ::2].repeat_interleave(2, dim=-1) # 将偶数列信息抽取出来也就是sin 拿出来并复制 # q,k: (bs, head, max_len, output_dim) q2 = torch.stack([-q[..., 1::2], q[..., ::2]], dim=-1) q2 = q2.reshape(q.shape) # reshape后就是正负交替了 # 更新qw, *对应位置相乘 q = q * cos_pos + q2 * sin_pos k2 = torch.stack([-k[..., 1::2], k[..., ::2]], dim=-1) k2 = k2.reshape(k.shape) # 更新kw, *对应位置相乘 k = k * cos_pos + k2 * sin_pos return q, k老规矩,为一目了然起见,还是一步一步通过一个示例来加深理解 sinusoidal_position_embedding函数生成位置嵌入。在output_dim=512的情况下,每个位置的嵌入会有512个维度,但为了简单起见,我们只考虑前8个维度,前4个维度为sin编码,后4个维度为cos编码。所以,我们可能得到类似以下的位置嵌入 # 注意,这只是一个简化的例子,真实的位置嵌入的值会有所不同。 pos_emb = torch.tensor([[[[0.0000, 0.8415, 0.9093, 0.1411, 1.0000, 0.5403, -0.4161, -0.9900], [0.8415, 0.5403, 0.1411, -0.7568, 0.5403, -0.8415, -0.9900, -0.6536], [0.9093, -0.4161, -0.8415, -0.9589, -0.4161, -0.9093, -0.6536, 0.2836]]]]) 然后,我们提取出所有的sin位置编码和cos位置编码,并在最后一个维度上每个位置编码进行复制 sin_pos = pos_emb[..., ::2].repeat_interleave(2, dim=-1) # 提取出所有sin编码,并在最后一个维度上复制 cos_pos = pos_emb[..., 1::2].repeat_interleave(2, dim=-1) # 提取出所有cos编码,并在最后一个维度上复制 更新query向量 我们首先构建一个新的q2向量,这个向量是由原来向量的负的cos部分和sin部分交替拼接而成的 我们用cos_pos对q进行元素级乘法,用sin_pos对q2进行元素级乘法,并将两者相加得到新的query向量 q2 = torch.stack([-q[..., 1::2], q[..., ::2]], dim=-1).flatten(start_dim=-2) # q2: tensor([[[[-0.2, 0.1, -0.4, 0.3, -0.6, 0.5, -0.8, 0.7], # [-1.0, 0.9, -1.2, 1.1, -1.4, 1.3, -1.6, 1.5], # [-1.8, 1.7, -2.0, 1.9, -2.2, 2.1, -2.4, 2.3]]]]) q = q * cos_pos + q2 * sin_pos 公式表示如下
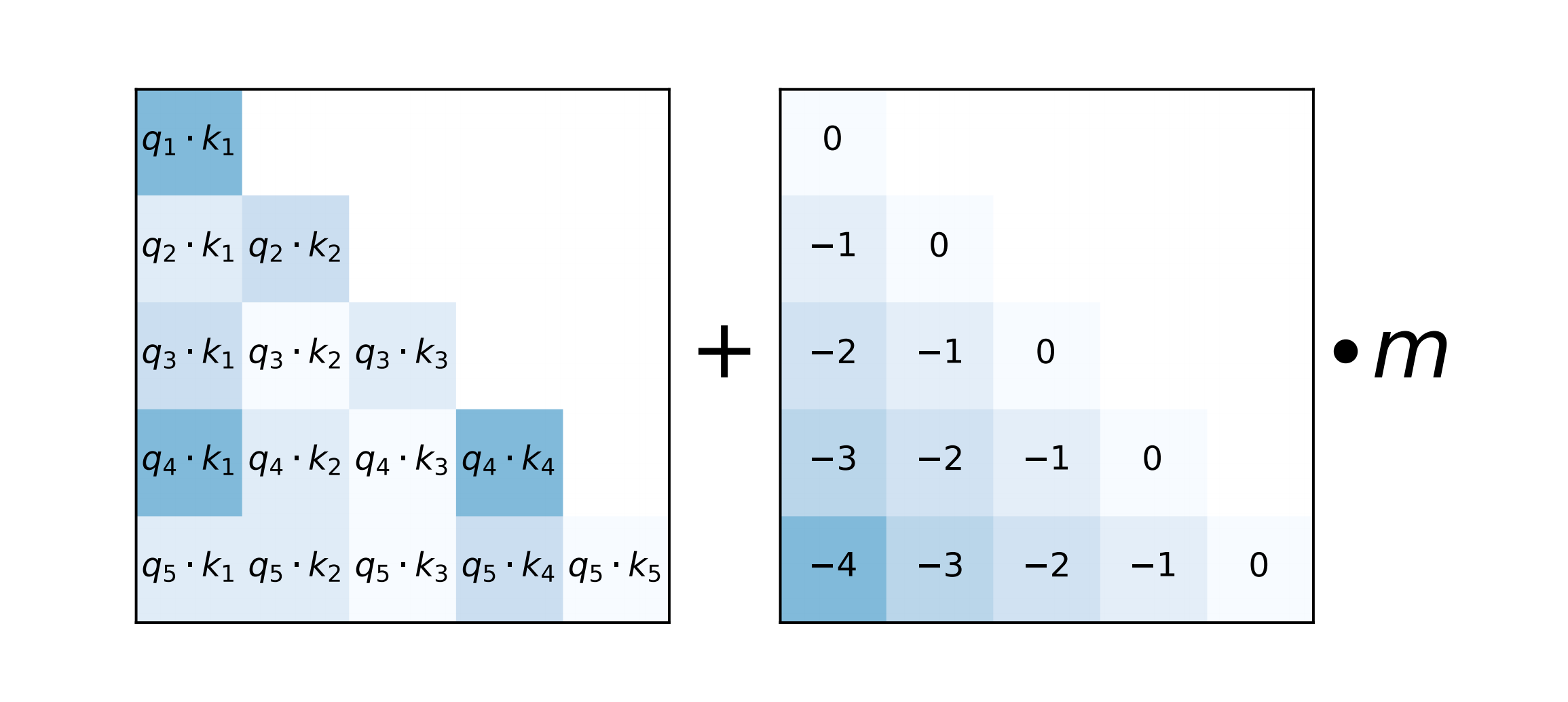
attention:这是注意力机制的主要功能 首先,如果use_RoPE被设置为True,它会应用RoPE,通过取查询和键的点积(并进行缩放)然后,进行softmax操作来计算注意力分数,以得到概率,输出是值的加权和,权重是计算出的概率最后,旋转后的q和k计算点积注意力后,自然就具备了相对位置信息 def attention(q, k, v, mask=None, dropout=None, use_RoPE=True): # q.shape: (bs, head, seq_len, dk) # k.shape: (bs, head, seq_len, dk) # v.shape: (bs, head, seq_len, dk) if use_RoPE: # 使用RoPE进行位置编码 q, k = RoPE(q, k) d_k = k.size()[-1] # 计算注意力权重 # (bs, head, seq_len, seq_len) att_logits = torch.matmul(q, k.transpose(-2, -1)) att_logits /= math.sqrt(d_k) if mask is not None: # 对权重进行mask,将为0的部分设为负无穷大 att_scores = att_logits.masked_fill(mask == 0, -1e-9) # 对权重进行softmax归一化 # (bs, head, seq_len, seq_len) att_scores = F.softmax(att_logits, dim=-1) if dropout is not None: # 对权重进行dropout att_scores = dropout(att_scores) # 注意力权重与值的加权求和 # (bs, head, seq_len, seq_len) * (bs, head, seq_len, dk) = (bs, head, seq_len, dk) return torch.matmul(att_scores, v), att_scores if __name__ == '__main__': # (bs, head, seq_len, dk) q = torch.randn((8, 12, 10, 32)) k = torch.randn((8, 12, 10, 32)) v = torch.randn((8, 12, 10, 32)) # 进行注意力计算 res, att_scores = attention(q, k, v, mask=None, dropout=None, use_RoPE=True) # 输出结果的形状 # (bs, head, seq_len, dk), (bs, head, seq_len, seq_len) print(res.shape, att_scores.shape) 3.2.2 LLaMA版的实现接下来,我们再来看下LLaMA里是怎么实现这个旋转位置编码的,具体而言,LLaMA 的model.py文件里面实现了旋转位置编码(为方便大家理解,我给相关代码 加了下注释) 首先,逐一实现这三个函数 precompute_freqs_cis reshape_for_broadcast apply_rotary_emb # 预计算频率和复数的函数 def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0): freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim)) # 计算频率 t = torch.arange(end, device=freqs.device) # 根据结束位置生成序列 freqs = torch.outer(t, freqs).float() # 计算外积得到新的频率 freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # 计算复数 return freqs_cis # 返回复数 # 重塑的函数 def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor): ndim = x.ndim # 获取输入张量的维度 assert 0 Tuple[torch.Tensor, torch.Tensor]: xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2)) # 将xq视为复数 xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2)) # 将xk视为复数 freqs_cis = reshape_for_broadcast(freqs_cis, xq_) # 重塑复数的形状 xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3) # 计算xq的输出 xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3) # 计算xk的输出 return xq_out.type_as(xq), xk_out.type_as(xk) # 返回xq和xk的输出之后,在注意力机制的前向传播函数中调用上面实现的第三个函数 apply_rotary_emb,赋上位置信息 # 对Query和Key应用旋转嵌入 xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis) 第四部分 线性偏差注意力ALiBi 模型名称 隐藏层维度 层数 注意力头数 词表大小 训练数据(tokens) 位置编码 最大长度Baichuan-7B4,096323264,0001.2 万亿RoPE4,096Baichuan-13B5,120404064,0001.4 万亿ALiBi4,096Baichuan 2-7B40963232125,6962.6万亿RoPE4096Baichuan 2-13B51204040125,6962.6万亿ALiBi4096注意看上表的位置编码那一列,baichuan 7B无论第一代还是第二代,位置编码均用的RoPE,而baichuan 13B则无论是第一代还是第二代,均用的ALiBi 下面便详细介绍下该ALiBi 4.1 什么是ALiBiALiBi全称是Attention with Linear Biases,通过论文《Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation》提出,其不像标准transformer那样,在embedding层添加位置编码,而是在softmax的结果后添加一个静态的不可学习的偏置项(说白了,就是数值固定) 具体而言,如下图所示
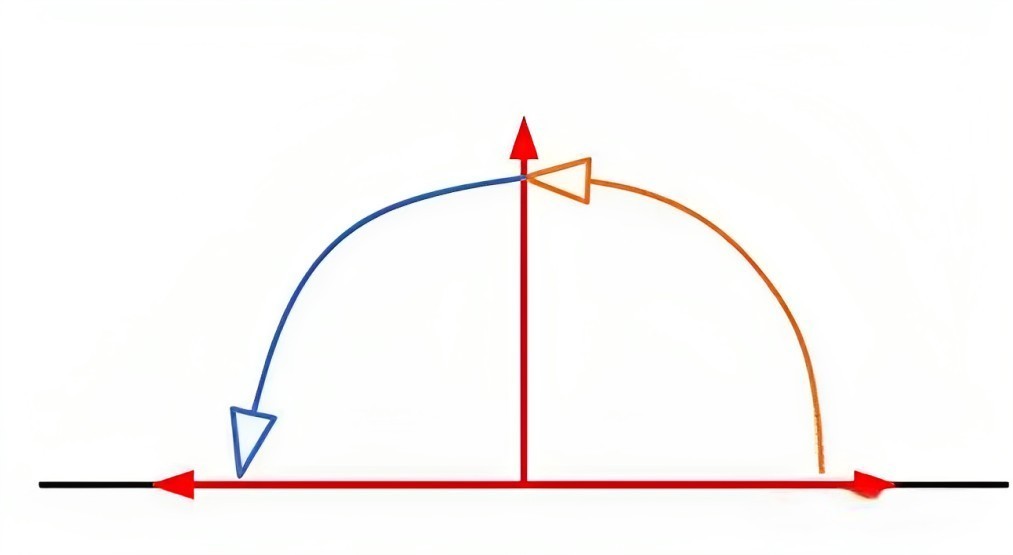
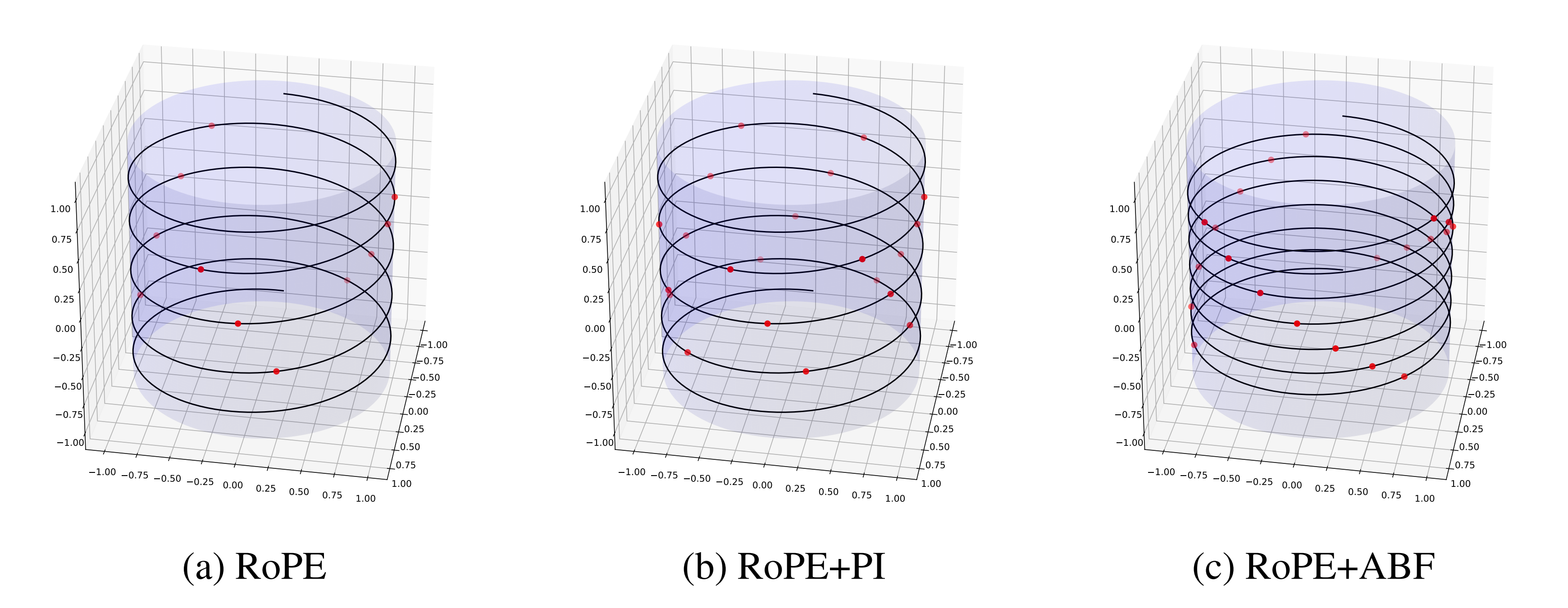
左边是自注意力得分,关于q和k的内积 右边是一个相对距离的矩阵,q1 q2 q3 q4 q5 k1 k2 k3 k4 k5 所以才有 // 待更 第五部分 LLaMA 2 Long中位置编码的修改 5.1 LLaMA 2 Long相比LLaMA 2的变化:修改位置编码 长度达到32K9月底,GenAI, Meta正式发布LLaMA 2 Long(这是其论文《Effective Long-Context Scaling of Foundation Models》),与LLaMA 2相比,LLaMA 2 Long的变化主要体现在以下两点 一是训练参数上,采用了高达4000亿token的数据源(We build our models by continually pretraining from LLAMA 2 checkpoints with additional 400 billion tokens formed as long training sequences) ——相反,原始LLaMA 2包含多个变体,但最多的版本也只有700亿二是架构上,与LLaMA 2保持不变,但对位置编码进行了一个非常小的必要修改,以此完成高达3.2万token的上下文窗口支持 5.1.1 LLaMA 2 Long中的位置编码做了怎样的修改在LLaMA 2中,它的位置编码采用的是旋转编码RoPE方法,其通过旋转矩阵来实现位置编码的外推 本质上来说,RoPE就是将表示单词、数字等信息的token embeddings映射到3D图表上,给出它们相对于其他token的位置——即使在旋转时也如此这就能够使模型产生准确且有效的响应,并且比其他方法需要的信息更少,因此占用的计算存储也更小然,Meta的研究人员通过对70亿规模的LLaMA 2进行实验,确定了LLaMA 2中的RoPE方法的一个局限性,即,阻止注意力模块聚集远处token的信息 为此,Meta想出了一个非常简单的破解办法: 减少每个维度的旋转角度(which essentially reduces the rotation angles of each dimension) 具体而言就是将超参数“基频(base frequency)b”从10000增加到500000(increasing the “base frequency b” of ROPE from 10, 000 to 500, 000) 在附录中,Meta还通过可视化为螺旋图这一非常有趣的方式,将RoPE ABF与RoPE PI的差异进行了理论分析
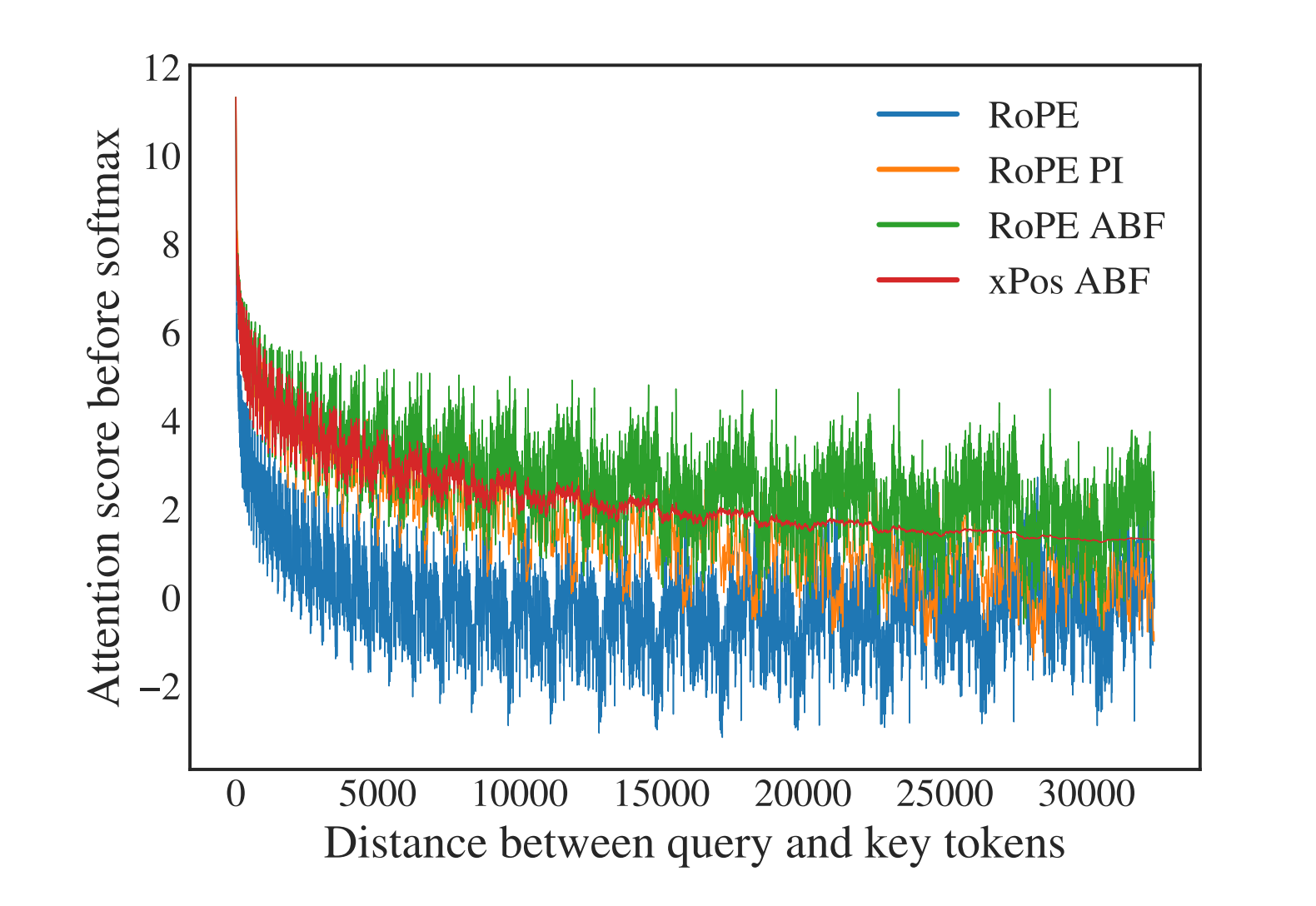
总之,与RoPE PI相比,RoPE ABF的优势主要体现在它能以更大的粒度分配嵌入向量(the embedded vectors),从而使模型更容易区分位置 此外,他们还观察到,嵌入向量之间的相对距离既对RoPE PI的关键参数有线性依赖性,也对RoPE ABF的关键参数也有对数依赖性。 这也就是为什么可以很容易地对基频这一超参数“下手” 5.1.2 改动之后的效果这一改动立刻奏效,缩小了RoPE对远端token的衰减效应,并且在扩展LLAMA的上下文长度上优于一项类似的名为“位置插值”的方法RoPE PI(如下图所示,RoPE表示基线方法,RoPE ABF为Meta此次发明的新方法,xPos是另一种应用了该方法的旋转编码变体)
然,一个问题是,通过上面这个可视化结果,Meta观察到RoPE在长程区域出现了较大的“振荡”,这对于语言建模来说可能不是个好消息 不过,通过报告几种方法在长序列困惑度和FIRST-SENTENCE-RETRIEVAL两个任务上的表现来看,问题不大
而且,尤其在后者任务上,他们提出的RoPE ABF是唯一一个可以始终保持性能的变体
最终,LLaMA 2 Long凭借着这一改动,达成了3.2万的上下文token,并通过长下文连续预训练的共同作用,获得了开头所示的好成绩: 除了全面超越LLaMA 2、在特定任务上超越Claude 2和ChatGPT,Meta也给出了它和一些开源长下文模型的对比。结果也相当不赖,如下图所示 //待更 后记最后,说明下为何像开头说的是「23年12.16日这天对本文做了大修」呢,原因在于 我司《论文审稿GPT第2版》即将进入模型训练阶段,其涉及到三个候选模型:mistral-yarn、mistral、llama-longlora 故准备解析下YaRN,顺带把外推、内插都全面介绍下,而过程中不可避免会提到RoPE,故也总算把RoPE彻底写清楚了这些东西,哪怕是近期最新的技术、模型等理解了后 会发现都不难,但我总想把理解的门槛无限降低,所以想真正写清楚或讲清楚一个东西,必须得反复琢磨、反复修改,以让更多人因此看懂,更何况当我和我的团队每天看paper、做项目,更可以帮到大家不断进阶、深入如今博客的访问PV2000万,希望明年达到2000万UV以上,以上视为后记 参考文献与推荐阅读 马同学关于向量和欧拉公式的几篇科普文章向量的加法欧拉公式,复数域的成人礼关于欧拉公式的几篇文章被众人膜拜的欧拉恒等式是个什么东东?怎么向小学生解释欧拉公式 e^(πi)+1=0?读懂旋转编码(RoPE)LLM学习记录(五)--超简单的RoPE理解方式,这篇文章很不错苏剑林:Transformer升级之路:2、博采众长的旋转式位置编码LLaMA的解读与其微调:Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙/LLaMA 2关于ALiBi的两篇文章[速读经典]ALiBi - 给注意力加上线性偏置关于Transformer中的位置编码-ALiBi最强LLaMA突然来袭!只改一个超参数,实现上下文3.2万token,多个任务打败ChatGPT、Claude 2 |




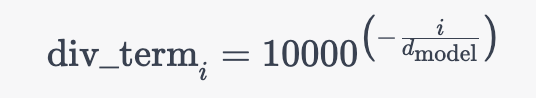



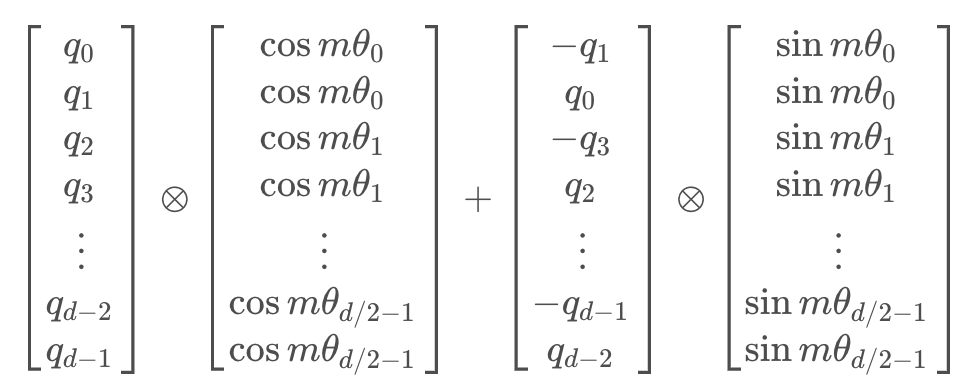


【本文地址】