|
为什么读文件操作一次读取字节数组最大值是8192 ?
最近做项目遇到将服务器上的文件下载到本地操作。其中用到了一个方法Files.copy
调试过程中查看源码发现一个很有意思的事
// buffer size used for reading and writing
private static final int BUFFER_SIZE = 8192;
/**
* Reads all bytes from an input stream and writes them to an output stream.
*/
private static long copy(InputStream source, OutputStream sink)
throws IOException
{
long nread = 0L;
byte[] buf = new byte[BUFFER_SIZE];
int n;
while ((n = source.read(buf)) > 0) {
sink.write(buf, 0, n);
nread += n;
}
return nread;
}
源码中
byte[] buf = new byte[BUFFER_SIZE];
BUFFER_SIZE 这个值为8192 为什么不使用文件的length ?一次不是可以读完不是更快捷吗? 带着这些疑问开始查找答案 度娘了一番 发现这玩意与tcp 协议有关:
IPv4 (Internel协议)头部 
#include
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,ihl:4;
#else
#error “Please fix ”
#endif
__u8 tos;
__be16 -tot_len;
__be16 -id;
__be16 -frag_off;
__u8 ttl;
__u8 protocol;
__be16 -check;
__be32 -saddr;
__be32 -daddr;
};
iphdr->version:版本(4位),目前的协议版本号是4,因此IP有时也称作IPv4。iphdr->ihl:首部长度(4位):首部长度指的是IP层头部占32 bit字的数目(也就是IP层头部包含多少个4字节 — 32位),包括任何选项。由于它是一个4比特字段, 因此首部最长为60个字节。普通IP数据报(没有任何选择项)字段的值是5 5 * 32 / 8 = 5 * 4 = 20 Bytes。iphdr->tos:服务类型字段(8位): 服务类型(TOS)字段包括一个3 bit的优先权子字段(现在已被忽略),4 bit的TOS子字段和1 bit未用位但必须置0。4 bit的TOS子字段分别代表:最小时延、最大吞吐量、最高可靠性和最小费用。4 bit中只能设置其中1 bit。如果所有4 bit均为0,那么就意味着是一般服务。iphdr->tot_len:总长度字段(16位)是指整个IP数据报的长度,以字节为单位。利用首部长度字段和总长度字段,就可以知道 IP数据报中数据内容的起始位置和长度。由于该字段长16比特,所以IP数据报最长可达65535字节总长度字段是IP首部中必要的内容,因为一些数据链路(如以太网)需要填充一些数据以达到最小长度。尽管以太网的最小帧长为46字节,但是IP数据可能会更短。如果没有总长度字段,那么IP层就不知道46字节中有多少是IP数据报的内容。iphdr->id:标识字段(16位)唯一地标识主机发送的每一份数据报。通常每发送一份报文它的值就会加1。iphdr->frag_off (16位):frag_off域的低13位 — 分段偏移(Fragment offset)域指明了该分段在当前数据报中的什么位置上。除了一个数据报的最后一个分段以外,其他所有的分段(分片)必须是8字节的倍数。这是8字节是基本分段单位。由于该域有13个位,所以,每个数据报最多有8192个分段。因此,最大的数据报长度为65,536字节,比 iphdr->tot_len域还要大1。iphdr->frag_off的高3位: (1) 比特0是保留的,必须为0;(2) 比特1是“更多分片”(MF — More Fragment)标志。除了最后一片外,其他每个组成数据报的片都要把该比特置1。(3) 比特2是“不分片”(DF — Don’t Fragment)标志, 如果将这一比特置1,IP将不对数据报进行分片。这时如果有需要进行分片的数据报到来,会丢弃此数据报并发送一个ICMP差错报文给起始端。iphdr->ttl:TTL(time-to-live) — 8位,生存时间字段设置了数据报可以经过的最多路由器数。它指定了数据报的生存时间。TTL的初始值由源主机设置(通常为32或64),一旦经过一个处理它的路由器,它的值就减去1。当该字段的值为0时,数据报就被丢弃,并发送ICMP报文通知源主机。TTL(Time to live)域是一个用于限制分组生存期的计数器。这里的计数时间单位为秒,因此最大的生存期为255秒。在每一跳上该计数器必须被递减,而且,当数据报在一台路由器上排队时间较长时,该计数器必须被多倍递减。在实践中,它只是跳计数器,当它递减到0的时候,分组被丢弃,路由器给源主机发送一个警告分组。此项特性可以避免数据报长时间地逗留在网络中,有时候当路由表被破坏之后,这种事情是有可能发生的。iphdr->protocol:协议字段(8位): 根据它可以识别是哪个协议向IP传送数据。当网络层组装完成一个完整的数据报之后,它需要知道该如何对它进行处理。协议(Protocol)域指明了该将它交给哪个传输进程。TCP是一种可能,但是UDP或者其他的协议也是可能的。iphdr->check:首部检验和字段(16位)是根据IP首部计算的检验和码。它不对首部后面的数据进行计算。 ICMP、IGMP、UDP和TCP在它们各自的首部中均含有同时覆盖首部和数据检验和码。为了计算一份数据报的IP检验和,首先把检验和字段置为0。然后,对首部中每个16 bit进行二进制反码求和(整个首部看成是由一串16 bit的字组成),结果存在检验和字段中。当收到一份IP数据报后,同样对首部中每个16 bit进行二进制反码的求和。由于接收方在计算过程中包含了发送方存在首部中的检验和,因此,如果首部在传输过程中没有发生任何差错,那么接收方计算的结果应该为全1。如果结果不是全1(即检验和错误),那么IP就丢弃收到的数据报。但是不生成差错报文,由上层去发现丢失的数据报并进行重传。iphdr->saddr:32位源IP地址iphdr->daddr:32位目的IP地址
网络字节序 4个字节的32 bit值以下面的次序传输:首先是07bit,其次815bit,然后1623bit,最后是2431 bit。这种传输次序称作big endian字节序。由于TCP/IP首部中所有的二进制整数在网络中传输时都要求以这种次序,因此它又称作网络字节序。
TCP头 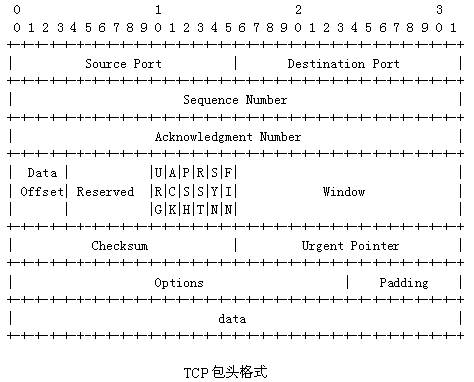
#include
struct tcphdr {
__be16 source;
__be16 dest;
__be32 seq;
__be32 ack_seq;
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u16 res1:4, doff:4, fin:1, syn:1, rst:1,
psh:1, ack:1, urg:1, ece:1, cwr:1;
#elif defined(__BIG_ENDIAN_BITFIELD)
__u16 doff:4, res1:4, cwr:1, ece:1, urg:1,
ack:1, psh:1, rst:1, syn:1, fin:1;
#else
#error “Adjust your defines”
#endif
__be16 window;
__be16 check;
__be16 urg_ptr;
};
tcphdr->source:16位源端口号tcphdr->dest:16位目的端口号tcphdr->seq:表示此次发送的数据在整个报文段中的起始字节数。序号是32 bit的无符号数。为了安全起见,它的初始值是一个随机生成的数,它到达32位最大值后,又从零开始。tcphdr->ack_seq:指定的是对方所期望接收的字节。tcphdr->doff:TCP头长度,指明了在TCP头部包含多少个32位的字(即单位为4字节)。此信息是必须的,因为options域的长度是可变的,所以整个TCP头部的长度也是变化的。从技术上讲,这个域实际上指明了数据部分在段内部的其起始地址(以32位字作为单位进行计量),因为这个数值正好是按字为单位的TCP头部的长度,所以,二者的效果是等同的。tcphdr->res1:为保留位。tcphdr->window:是16位滑动窗口的大小,单位为字节,起始于确认序列号字段指明的值,这个值是接收端正期望接收的字节数,其最大值是63353字节。TCP中的流量控制是通过一个可变大小的滑动窗口来完成的。window域指定了从被确认的字节算起可以接收的多少个字节。window = 0也是合法的,这相当于说,到现在为止多达ack_seq-1个字节已经接收到了,但是接收方现在状态不佳,需要休息一下,等一会儿再继续接收更多的数据,谢谢。以后,接收方可以通过发送一个同样ack_seq但是window不为0的数据段,告诉发送方继续发送数据段。tcphdr->check:检验和,覆盖了整个的TCP报文段,这是一个强制性的字段,一定是由发送端计算和存储,并由接收端进行验证。tcphdr->urg_ptr:这个域被用来指示紧急数据在当前数据段中的位置,它是一个相对于当前序列号的字节偏移值。这个设施可以代替中断信息。 fin, syn, rst, psh, ack, urg为6个标志位 这6个位域已经保留了超过四分之一个世纪的时间而仍然原封未动,这样的事实正好也说明了TCP的设计者们考虑的是多么的周到。它们的含义如下:tcphdr->fin:被用于释放一个连接。它表示发送方已经没有数据要传输了。 tcphdr->syn:同步序号,用来发起一个连接。syn位被用于建立连接的过程。在连接请求中,syn=1; ack=0表示该数据段没有使用捎带的确认域。连接应答捎带了一个确认,所以有syn=1; ack=1。本质上,syn位被用来表示connection request和connection accepted,然而进一步用ack位来区分这两种情况。tcphdr->rst:该为用于重置一个已经混乱的连接,之所以会混乱,可能是由于主机崩溃,或者其他的原因。该位也可以被用来拒绝一个无效的数据段,或者拒绝一个连接请求。一般而言,如果你得到的数据段设置了rst位,那说明你这一端有了问题。tcphdr->psh:接收方在收到数据后应立即请求将数据递交给应用程序,而不是将它缓冲起来直到整个缓冲区接收满为止(这样做的目的可能是为了效率的原因)。tcphdr->ack:ack位被设置为1表示tcphdr->ack_seq是有效的,需要check ack_seq字段是否为所需要。如果ack为0,则该数据段不包含确认信息,所以,tcphdr->ack_seq域应该被忽略。tcphdr->urg:紧急指针有效。tcphdr->ece:用途暂时不明。tcphdr->cwr:用途暂时不明。
内核源代码在函数tcp_transmit_skb()中建立tcp首部。
linux内核参数注释(部分)
名称默认值建议值描述tcp_max_orphans819232768系统所能处理不属于任何进程的TCP sockets最大数量。假如超过这个数量﹐那么不属于任何进程的连接会被立即reset,并同时显示警告信息。之所以要设定这个限制﹐纯粹为了抵御那些简单的 DoS 攻击﹐千万不要依赖这个或是人为的降低这个限制。如果内存大更应该增加这个值。(这个值Redhat AS版本中设置为32768,但是很多防火墙修改的时候,建议该值修改为2000)tcp_syn_retries51对于一个新建连接,内核要发送多少个 SYN 连接请求才决定放弃。不应该大于255,默认值是5,对应于180秒左右时间。。(对于大负载而物理通信良好的网络而言,这个值偏高,可修改为2.这个值仅仅是针对对外的连接,对进来的连接,是由tcp_retries1决定的)
一般在tcp或者udp上进行传输数据,当数据比较大的时候,都进行分段传输,例如以1024为一个包进行传输。
TcpClient.ReceiveBufferSize 属性默认是 8192 ,如果返回的流数据大于这个值,是不是我就不能收到完整的数据,必须将ReceiveBufferSize数据设置更大才行?
//这个流程是这样的: 比如你调用SEND方法发送一个byte[65535]的时候,其实是把这个65535的数据一次一次的发送到SOCKET内部的缓冲区去,SendBufferSize默认是8192,所以每一次交给TCP的数据其实只有8192,然后TCP分段把他们全部发送出去,直到发送完你的65535数据。
而接收的时候,也是如此,ReceiveBufferSize 属性默认是 8192,很明显,不管来的数据有多大,但是接收缓冲区内部最大只有8192,每一次等待接收的数据其实只有8192这么大。难道我们RECEIVE的时候只能收到这8192吗,当然不是了,RECEIVE的时候他会一次一次的重接收缓冲区里取数据来,直到取完为止。
|