| python爬虫(十二、爬取今日头条关键词所有文章) | 您所在的位置:网站首页 › 23今日头条新闻 › python爬虫(十二、爬取今日头条关键词所有文章) |
python爬虫(十二、爬取今日头条关键词所有文章)
|
今日头条 我们以搜索’妹子’为例 那 么 我 们 在 右 上 角 的 搜 索 框 搜 索 妹 子 , 出 来 了 一 系 列 文 章 那么我们在右上角的搜索框搜索妹子,出来了一系列文章 那么我们在右上角的搜索框搜索妹子,出来了一系列文章 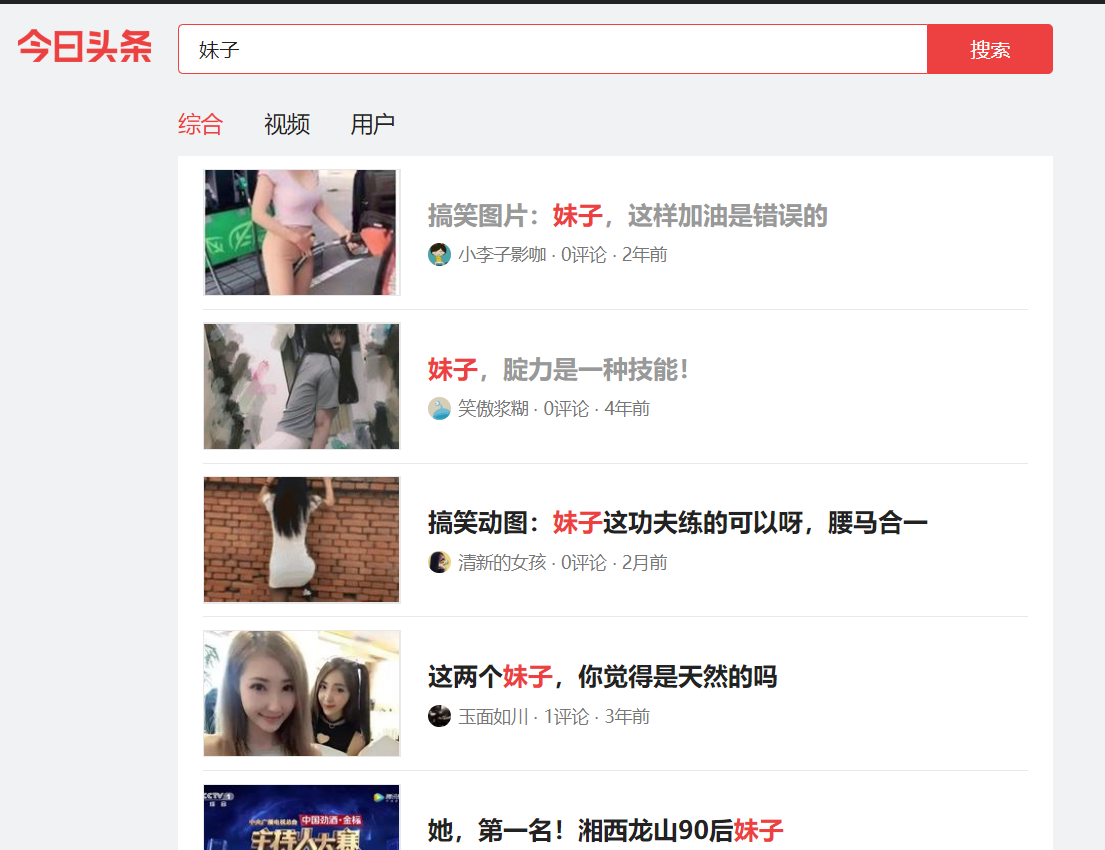
检 查 网 页 的 源 代 码 , 发 现 只 是 一 个 简 短 的 框 架 检查网页的源代码,发现只是一个简短的框架 检查网页的源代码,发现只是一个简短的框架 于 是 猜 测 这 是 用 于是猜测这是用 于是猜测这是用AJAX技术请求的,那么我们打开XHR查看 果 不 其 然 , 就 在 这 里 , 现 在 我 们 就 是 构 造 这 些 J S 加 载 请 求 果不其然,就在这里,现在我们就是构造这些JS加载请求 果不其然,就在这里,现在我们就是构造这些JS加载请求 
打 开 这 个 数 据 包 的 h e a d e r s 部 分 查 看 打开这个数据包的headers部分查看 打开这个数据包的headers部分查看 
显 然 其 中 的 o f f s e t 是 决 定 翻 页 的 , 每 加 20 翻 一 页 显然其中的offset是决定翻页的,每加20翻一页 显然其中的offset是决定翻页的,每加20翻一页 t i m e s t a m p 是 什 么 呢 ? timestamp是什么呢? timestamp是什么呢? 这 个 可 以 直 接 用 t i m e . t i m e ( ) 取 得 , 具 体 看 代 码 中 这个可以直接用time.time()取得,具体看代码中 这个可以直接用time.time()取得,具体看代码中 接 下 来 就 是 请 求 , 转 化 为 字 典 , 取 出 需 要 的 内 容 接下来就是请求,转化为字典,取出需要的内容 接下来就是请求,转化为字典,取出需要的内容 #-*-codeing = utf-8 -*- #@Time : 2020/6/28 13:17 #@Author : issue小菜鸡 #@File : 今日头条爬取.py #@Software: PyCharm import time import json import requests from urllib.parse import urlencode def get_data(search_name,page): data = { #构造请求的data 'aid':'24', 'app_name':'web_search', 'offset':page, 'format':'json', 'keyword':search_name, 'autoload':'true', 'count':'20', 'en_qc':'1', 'cur_tab': '1', 'from': 'search_tab', 'pd':'synthesis', 'timestamp': int(time.time()), '_signature': '21oMXgAgEBAwjHnl59qFgNtbTUAAIWq5yRBJSZ83MdD56bgu5GDIJxHd0EHk8Y1-DDSzzYJ-ZlFlc5td8NE86Wb3wfbOIt2i-9L7pr2I3.bmY8SCimmZOjMIL2g7TKFO-Lj' } url = 'https://www.toutiao.com/api/search/content/?' + urlencode(data) header={ 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36', 'x-requested-with':'XMLHttpRequest' } res = requests.get(url=url,headers=header) return res def find_content(search_name,page): dic = get_data(search_name,page).json() #转化为json字典 data = dic['data'] if data is not None: #不为空才开始 for item in data: if 'title' in item: #标题 print(item['title']) else: print('没有找到啊啊啊啊啊') if 'article_url' in item: #文章url print(item['article_url']) page = 0 for i in range(0,9): find_content('妹子',page) page = page + 20 print(page,'哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈') |
【本文地址】