| 2021年研究生数学建模D题:抗胰腺癌候选药物的优化建模 | 您所在的位置:网站首页 › 21年华为杯数学建模竞赛 › 2021年研究生数学建模D题:抗胰腺癌候选药物的优化建模 |
2021年研究生数学建模D题:抗胰腺癌候选药物的优化建模
|
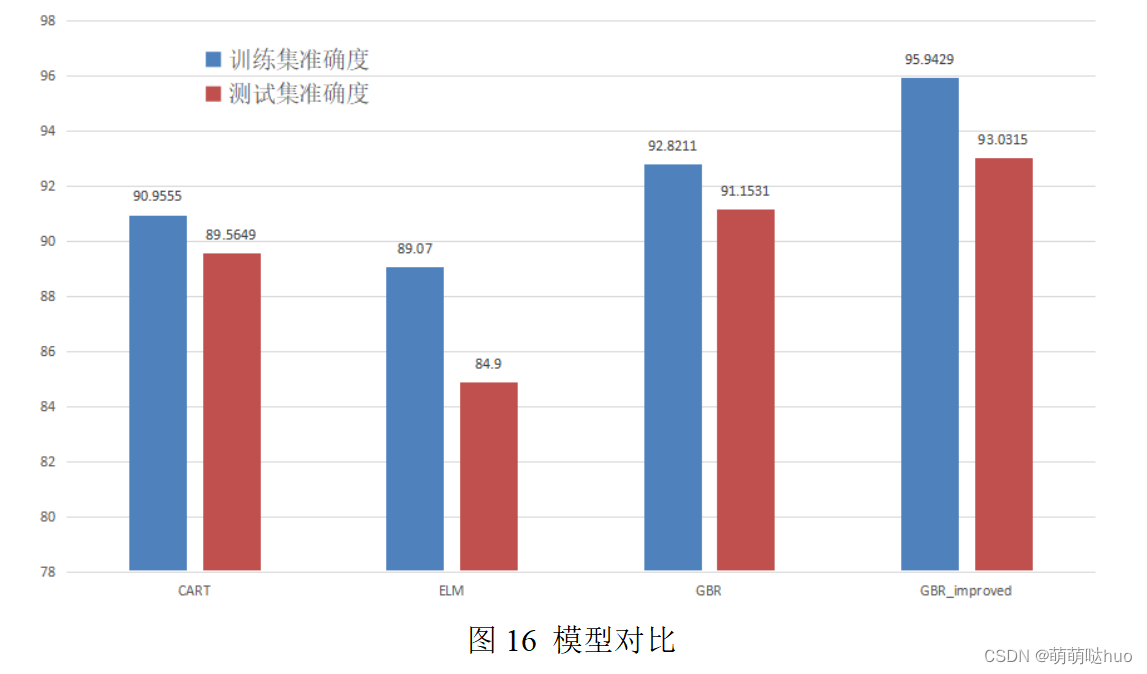
这是我们队伍2021年参加正式比赛的题目,其实很简单,典型的数据处理 + 机器学习。只要前几年的数据处理类题目有练习过,一定没问题的。 这篇文章其实没什么好讲的,主要是给大家提供了丰富的代码,方便调用各种预测、分类模型。 题目、代码、文章都在下面的百度网盘链接中,如果失效了可以私聊或评论告诉我。 链接:https://pan.baidu.com/s/1hUjuuC6PSjFKgHazy1lM_w 提取码:2x2p 题目描述首先题目提供了将近2000个化合物的数据,每个化合物都有700多个【分子描述符】,也就是特征,用来描述对应化合物一些可以量化的性质。 问题一:特征提取主要是让我们从729个分子描述符中,选择了抑制乳腺癌因子、效果最好的20个。 思路: ①直接上一堆特征提取方法,计算每个特征的贡献度,根据贡献度【先选取40个效果最好的特征】; ②但其实有时候就算每个特征效果都很好,他们之间也是会有冗余的。比如:汽车的油门踏度、和瞬时油量消耗,都是反应车速的重要指标,但说的都是一回事; ③去除掉20个冗余值较高的特征,最终得到剩下20个最有效、且不冗余的特征。 专业描述: 问题一要解决的问题是在本文中所提供的数据中,根据描述化合物的结构和性质特征的参数的各项分子描述符所对应的生物活性值,找出20个对生物活性值影响最大的分子描述符。本文中所提供的数据在“Molecular_Descriptor.xlsx”和“ERα_activity.xlsx”的文件中,该数据集中一共采集了1974组不同的化合物,每种化合物对应729列不同的分子描述符。因此,在729列不同的分子描述符中选取20对生物活性值影响最大的因素的问题可以抽取为主要特征提取的问题。 首先采用随机森林算法,结合数据集中的生物活性值,计算729个分子描述符(特征)的贡献度,并进行排序,选取贡献度最高的前40个作为初始特征。由于提取出的特征可能具有较大的耦合性,因此需要对初始特征进一步处理。 第二步,采用距离相关系数方法,计算各个特征之间的相关系数,并绘制出相关系数的热力图,去除冗余的特征,从而降低模型的复杂度。 问题二:建立回归模型我们拥有的数据量足够,以上一问提取的特征为输入,对应的pIC50值为输出,采用多种方式建立预测模型。 针对问题二,要求建立化合物ERα生物活性的定量预测模型。由于样本数据中IC50的取值范围跨度较大,会给模型建立增加难度;而pIC50是通过IC50取负对数得到的,取值范围较为集中,因此以pIC50作为预测模型的目标值。考虑到化合物的分子描述符和ERα生物活性的非线性关系,不宜采用线性回归的方法来建立预测模型。本文采用梯度提升回归(Gradient Boosting Regression)对附件一“ERα_activity.xlsx”中的pIC50进行预测,通过问题一筛选出的20个对ERα生物活性有显著影响的分子描述符,来对ERα生物活性进行预测。 此外,为了验证GBR的性能,也采用了决策树回归模型CART和极限学习机的方法,通过三种模型来对预测的结果进行对比分析,来验证GBR对ERα生物活性预测的有效性和准确性。 最后,利用BP神经网络构建了残差补偿网络,对GBR模型的残差进行补偿,进一步提高模型的准确性。 结果:
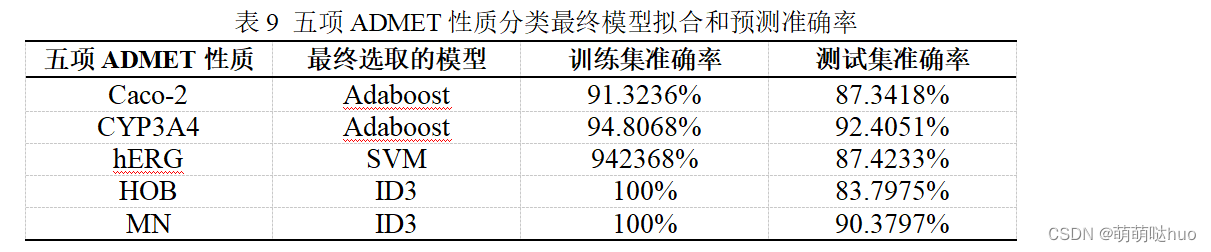
问题三:建立分类模型 将2000个化合物,分为不同的类别。 思路: 第一问是根据【活性值预测模型】选取了20个有效特征,在分类问题上,效果可能并不是很明显。 我们用问题一的方式,重新选取了30个对分类有明显效果的特征(分子描述符); 利用已有的这2000条数据训练出了一个分类模型,将重新选取的30个特征的值作为输入,分类模型即可对判断该化合物属于哪一类。 专业描述: 问题三需要在全部的729个分子描述符中,针对ADMET数据中的Caco-2、CYP3A4、hERG、HOB、MN分别建立相对应的分类预测模型。 (1)特征提取 对于不同的ADMET性质,应针对性的进行特征提取。由于ADMET的5个性质均为标签数据,利用显著性水平a为0.05的卡方检验根据729个分子描述符(特征)对其标签结果的影响力进行打分,对Caco-2、CYP3A4、hERG、HOB、MN这五项ADMET性质分别选取排名前30位的分子描述符,作为构建分类预测模型的特征。 (2)构建分类预测模型 对五项ADMET性质分别采用Adaboost、SVM、决策树、逻辑回归这四种方法建立相对应的分类预测模型。首先将1954个样本按照4:1的比例划分为训练集与测试集,将训练集拟合准确率、测试集预测准确率最高的模型作为对应ADMET性质的分类模型。 结果:
问题四: 选定的分子描述符,在什么取值范围内,对抑制该化合物的活性,效果最好。 这个题貌似和20年还是19年的数据处理题是一样的思路。 针对问题四,需要寻找合适的分子描述符,并确定其取值范围使得抑制ERa的生物活性最好且具有更好的ADMET性质。因此,首先需要找到影响生物活性值程度最大和ADEMT性质最显著的分子描述符作为特征,并作为优化参数。由于需要确定最优解的范围,所以我们采用启发式遗传算法作为优化算法。遵循“优胜略汰,适者生存”的思想,让种群中的相对最优解在不断地选择迭代中遗传下去,即该特征参数所对应的pIC50较大,且能够保证ADEMT性质至少为三个“1”,通过交叉变异操作产生新的可行解,不断寻优,从而找到可行解空间中的最优解作为最佳特征参数。 因此,在问题四中,需要利用问题二和问题三所确定的GBR预测模型和Adaboost分类模型,预测在种群的解空间中的各个个体特征参数下的pIC50值和ADMEMT性质评分,结合遗传算法,根据pIC50评价值和ADMEMT性质评价值来确定该参数下的适应度的值,在种群中不断地寻优,迭代更新,从而找到最优解。 为了验证所得解的有效性,对于选取的每个分子描述符,在求得的范围解内随机选择多个个体,验证其抑制ERα生物活性和ADMET性质是否满足问题四要求,来说明该模型得到的特征参数范围的有效性。 |
【本文地址】