| 2021 | 您所在的位置:网站首页 › 2021深度学习目标检测综述 › 2021 |
2021
|
医疗影像小目标检测——从眼底病变检测说起
原文:https://zhuanlan.zhihu.com/p/138108192 之前写过一篇《沿着大咖们指引的方向前进》,说的是,2018年医学影像大咖们开了个会,会上讨论总结了医疗影像AI未来的发展方向,或者说,值得研究的重点问题。其中之一,是“针对医学影像的机器学习方法”。 “针对医学影像的机器学习方法”,是比较论文范儿的说法,换成网文范儿,就是“我们(医学影像)不一样,我们要有自己的方法”。 那医学影像又是如何不一样的呢?最直接明显的,就是要分析的图像和要检测的目标不一样。 大家都了解,当前主流的深度学习模型,都是从计算机通用视觉领域发展起来的。一开始被提出,都是用于从照片中定位行人、车辆,或区分猫猫狗狗的。这和我们更关心的医学影像分析,确实存在差别。既包括,图像自身维度和像素格式的差别,例如CT、MR影像都是三维和灰度的,而日常照片则是二维和彩色的;还包括,要检测的目标大小的差别,很多疾病辅助检测所关心的目标都比较小,只占据图像中很小的区域,而日常照片中,大家关注的目标都比较大,往往占据图像主体区域。 关于小目标检测,最典型的例子,就是大家都熟知的肺小结节和眼底病变了。肺小结节检测,更多基于CT影像,属于三维图像领域;眼底病灶检测,则大多使用眼底相机拍摄的眼底彩色照相图片,属于二维图像领域。肺小结节检测,首先需要把网络模型,从二维扩展到三维,然后还需要针对小目标检测,进行优化。而眼底病变检测,由于眼底图像本身就是数码相机相机拍摄出来的彩色照片,所以只需要解决针对小目标检测的优化问题。 也就是说,把通用深度学习模型应用到肺小结节检测,需要解决2个问题;而通用AI用于眼底病灶检测,则只需要解决(或优化)一个问题,就是目标很小的问题。 咱们今天就先从简单的开始,以眼底病变检测说起,聊聊医疗影像中小目标的检测问题。 “小”却不能忽视的眼底病变们为什么来来回回总在说“小目标”,为什么总要在“目标”二字前面加上一个“小”字? 原因很简单。与行人、车辆、猫猫狗狗相比,我们所要检测的眼底病变,确实真的很小。有图有真相,咱们来看图。
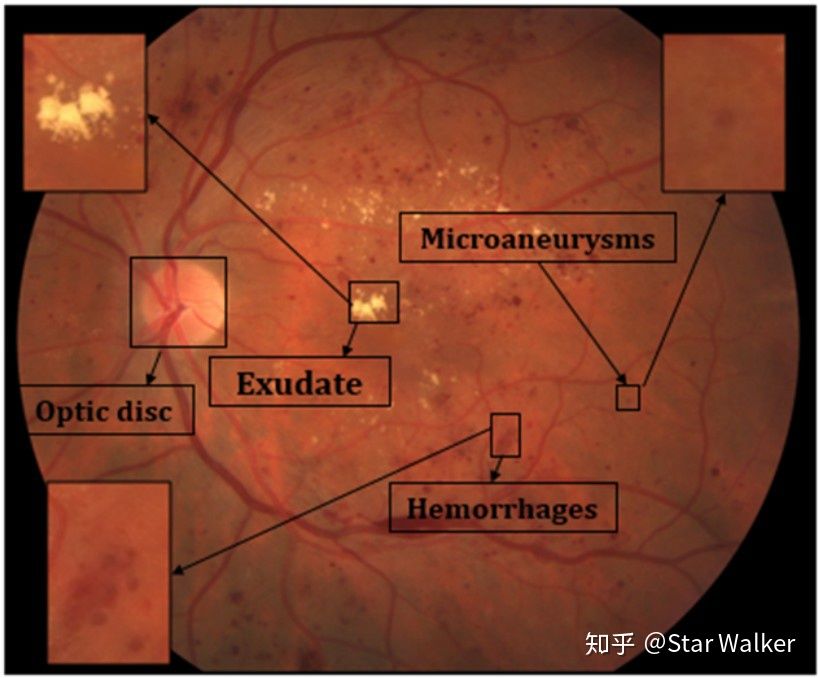
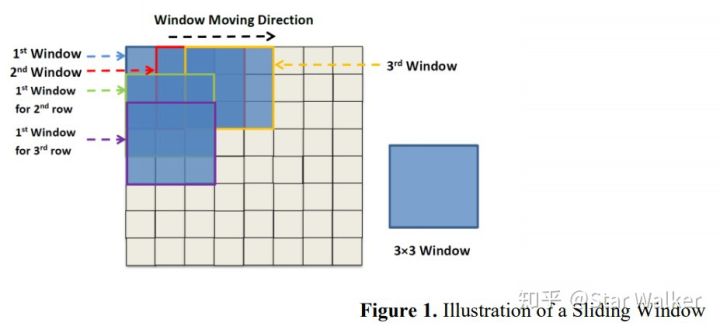
(图片来源:【Review——Diabetic Retinopathy Deep Learngin 2019.pdf】,文献完整信息见文末。) 熟悉眼底图像的同学,对上面的图片,肯定一目了然。对于不熟悉的同学,正好来学习3个单词先。 Microaneurysms——微血管瘤。就是眼底微小血管上鼓起来的小包,类似于被血流撑起来的气球,随时都有被撑爆的危险。Hemorrhages——出血。就是上面说的血管上的小气球被撑爆了,血液流出,弥散到眼底。Exudate——渗出物。当血管壁发生病变,屏蔽功能损害时,血管内液体、血浆或细胞渗出,形成的病变。根据渗出物的不同,还可以进一步细分为硬性渗出物和软性渗出物。这里不展开说了。大家可以再看一下上面的图片。从微血管瘤、到出血,再到渗出物,病变区域的面积是由小到大。当然,这只是指一般情况,或者说早期还不是很严重的阶段。但即使上图中面积最大的渗出物病变区域,它的面积相比整个图像区域,也还是很小的。 以眼底图像常见的512x512像素大小为例,如上图所示的渗出物病变区域的宽度(高度)一般在30~50像素。而微血管瘤就更小了,宽度(高度)一般在10~20像素。 这些病变虽然很小,但临床风险与危害,却不可忽视。打个比方,可以把眼底血管看做与市政自来水管网相类似,也是枝枝叉叉、层层分级。而这些病变就相当于供水管网中的跑冒滴漏现象。如果任其发展,愈演愈烈,就会导致局部视野受限(失明),乃至完全失明。 此外,眼底病变除了上面提到的,还有很多其他病变。但上面3种,作为小病变,更加有代表性。 一路铺垫到这里,终于可以再次提出咱们今天的问题 —— 怎么从图像中用深度学习网络检测定位出这些“小目标”? 方法还是老套路,查论文,看看别人是怎么解决这个问题的。 使用“滑窗”,变小为大,检测变分类查找了近两年来,这个方向发表的论文。意外发现,大家在总体思路上,几乎都采用了相同的套路。概括起来,就是使用“滑窗”抠图方法,每次只“抠出”一个很小的区域进行分析,在这个很小的区域中,“小”目标也就变成了“大”目标,而检测问题也变成了在这个小区域内是否包含病变的“二分类”问题。对一幅尺寸不大的图像,进行二分类判断,简直是深度学习网络最拿手的入门问题啊。大家是不是又回想起,当年入门上手时,折腾过的MNIST、CIFAR数据集? 作为旁观群众,咱们来看看,别人是如何真刀真枪、动手实练的。 代表作:基础动作+标准套路【Patches——Hard Exudates——CNN 2018】 大家看到上面的“【Patches——Hard Exudates——CNN 2018】”,肯定感觉奇怪,什么鬼?解释一下,这里是为了便于区分和记忆,个人给论文起的一个缩写名称。Patches表示,结合咱们今天讨论的主题范畴,这篇论文属于“基于Patches进行分析”这个大类;Hard Exudates表示,这篇文章的检测目标是Hard Exudates;CNN则表示,作为主要方法或特色,论文中用到了CNN;2018就简单了,论文是2018年发表的。 解释完个人“臆造”的这个命名法后,大家也对这篇论文有了一个大概的了解。 再稍微说一下“Patches"和”CNN“。 这里的Patches对应的就是就是前面说的滑窗方法(Sliding Window)。Sliding window是一种对图像进行处理的方法,大致理解,就是把一个尺寸远远小于图像尺寸的方框,从图像左上角开始,从左向右、自上而下,逐步移动(滑动)。当滑动到每一个位置时,把方框对应的局部图像,“抠出来”,作为一个Patch,进行处理。也就是说,Sliding window是用于生成Patches的一种方法,当然还有别的方法。 关于Sliding window,可以参考下图,来帮助理解。
(图片来源:https://www.sciencedirect.com/science/article/abs/pii/S0923596516300601) 这篇论文先把每一幅尺寸为512x512的眼底彩照进行降采样,缩小到256x256;然后,采用尺寸为16x16窗口从最左上角开始滑动,一共可以得到224x224=50716个尺寸为16x16的Patches。这里,因为限制窗口不能超出图像,所以最终Patches数目比256x256要少。 下面是来自论文的Pateches示例。
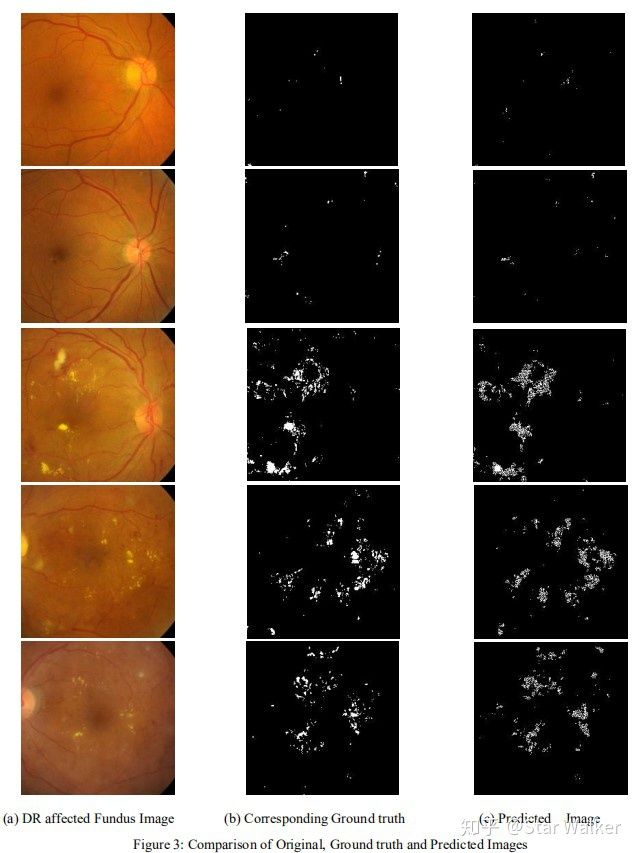
接下来,就是把每一个16x16的Patch作为单独的图像,输入一个8层的CNN网络,进行二分类预测。关于这个8层CNN,不专门说了,是一个非常标准(常规)的CNN。 需要说的是,对每一个Patch,进行二分类(有/无 Hard Exudate)后,实际决定的是这个Patch的中心像素,所对应的原始图像中的像素,是被分割为病灶(前景),还是非病灶(背景)。 至此,大家应该已经可以理解,下面的最终结果示例图片,是如何得出的。
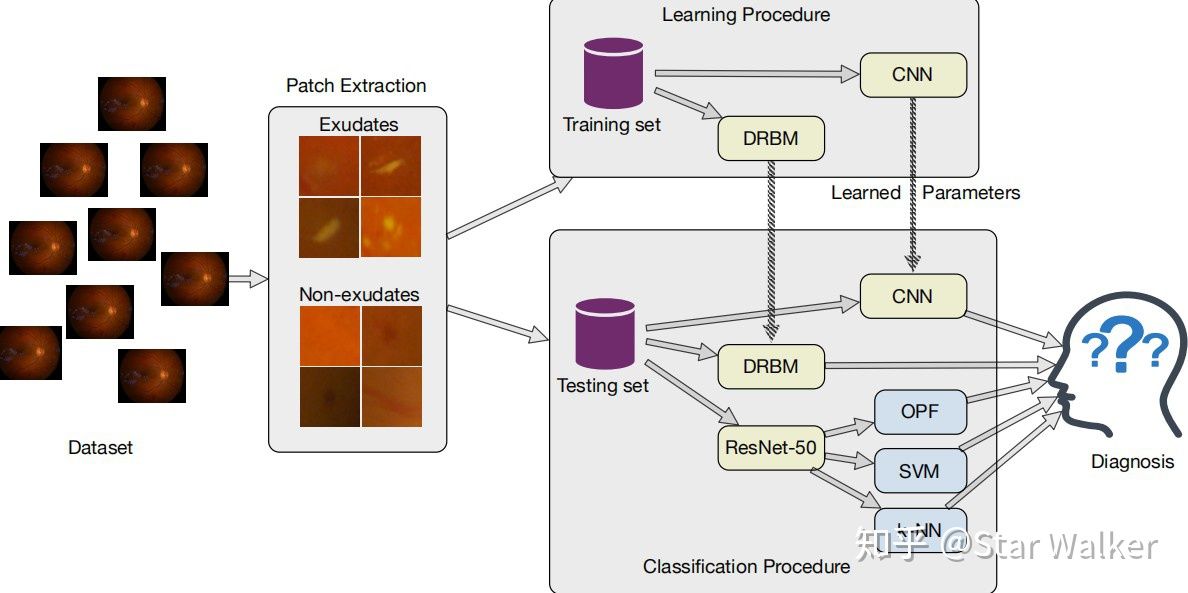
【Patches——Microaneurysm——Machine Learning Methods 2018】 大家如果还记得,上面提到的论文名称缩写构成方法,应该已经知道,这篇论文也采用了Patches方法,但检测目标是Microaneurysm,发表于2018年。 这篇论文的Patches生成方法,乃至Patch的尺寸,都和上一篇,几乎完全一致。但这篇的特点在于—— 使用了多种机器学习分类经典方法,包括经典的单隐藏层神经网络,并把不同方法的表现做了横向比较。 论文用到的分类方法包括,随机森林、神经网络(单隐藏层)和支持向量机。通过横向比较,作者发现,支持向量机的分类准确率要优于神经网络。为了确保这一结论的普适性,作者在多个眼底图像数据集上,进行了测试,得到了基本一致的结果。 这篇论文的发现能带来一些启示,可以看出,在不同应用场景下,传统的(非神经网络的)分类方法也能取得不错的效果。但是,论文对这一结论的支持,还说不上特别的严密或有力。因为,论文使用的是单隐藏层的网络,也就是在深度神经网络之前的,浅层神经网络。 如果把浅层网络,换成深层网络,比如上文的8层CNN,或者更强大的RestNet,是否神经网络就可以打败支持向量机?取得更优的分类效果? 发论文的“墨菲定律”?高性价比的SVM?【Patches——Exudates——Deeply learnable features 2018】 不再解释上面的缩写名称了。直接说特点,这篇论文的关键创新在于,把深度学习网络作为特征提取器(Feature Extractor)来使用,将提取出的深度学习特征,输入传统的经典分类器,进行分类。 搞学术、发论文,有一个很有趣(无奈)的规律。当你突然迸现一个特别好的创意,或者偶然发现一个特别有价值的问题,在迫不及待想要搞起来之前,最担心的就是,这个创意或问题千万可别已经有人研究过了。稳妥起见,做个文献检索先。Bingo,果不其然,已经有人捷足先登了:( 墨菲定律又一次应验:) 扯远了,话归正题。前面提到,如果把浅层网络换成深度网络,再做比较,会怎样?果然,这个工作已经有人做了。当然,相比上一篇文献,检测目标不再是Microaneurysm,而是回到了Exudates。但这篇文章同样是比较了多种分类模型,既包含了一个8层CNN,包含了Discriminative Restricted Boltzmann Machines,还包含了ResNet-50,并且是把ResNet-50和SVN相连,用RestNet-50来提取特征,然后用SVN对特征进行分类。此外,ResNet-50的特征输出还被连接到k-NN(k最近邻)和OPF(Optimum-Path Forest),进行比较。 论文的整个横向比较体系,还是有些复杂的。大家可以通过下面作者给出的示意图感受一下。
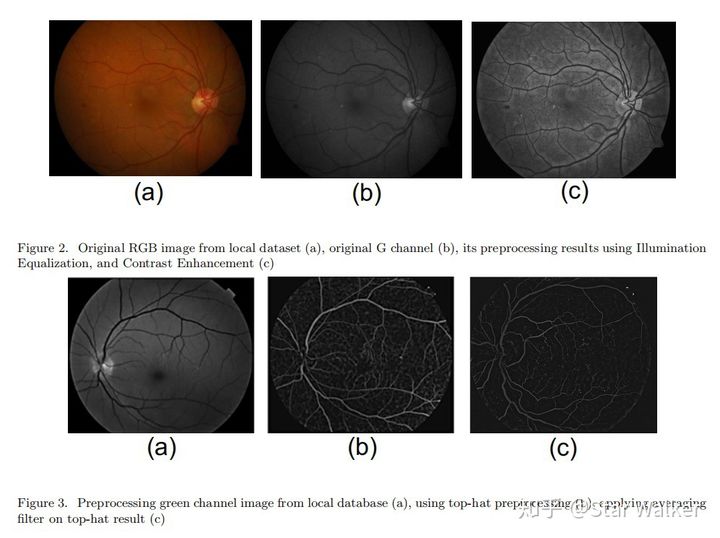
经过一番比较,作者发现,采用Res-Net 50连接SVM,取得的分类效果最佳。 前后两篇论文,连着看下来,让人对SVM心生敬意啊。应该说,SVM性价比很高,在数据量要求、训练计算负担和分类效果之间,能够取得很好平衡,适应性强。可以在很多场合,都拿来试一下(碰碰运气)。 预处理也可以比较一下【Patches——Microaneurysm——Different Preprocessing 2020】 如同上面小标题所说的,不知道作者团队是否看过上面两篇文献,受到了启发。这又是一篇把横向比较作为创新点的论文。只是,这次比较的重点,前移到了预处理环节。作者采用和比较了,两种非常经典(常规)的预处理方法,对CNN分类效果的影响。 第一种是“Illumination Equalization, and Contrast Enhancement”,第二种是“ Top-hat transformation”。够经典吧?几乎是图像处理入门方法,或者说是硕士课程练习题的内容。下图是两种预处理方法的处理效果。
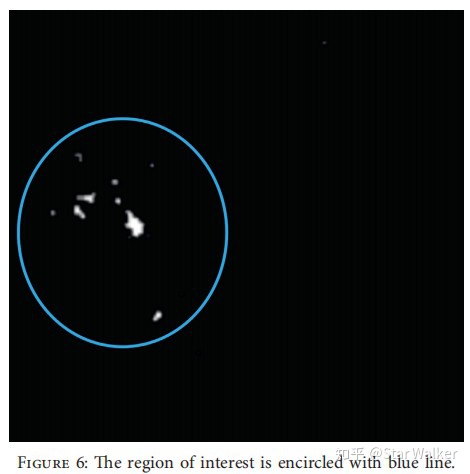
然后,作者发现采用第一种方法,结合CNN分类,能够取得更好效果。 至于CNN网络,文章中几乎一笔带过,仅仅提了一下,是用Matlab实现的。 看到这篇论文,挺受启发的。在这个大家争抢发论文的当下,对于很多“人从众”的热点问题或热点方法,如果能够换个视角,找到一个冷门视角,或者一个大家太熟悉反而忽略的环节,作为切入点,说不定还真能发一篇“不大不小”的文章。 这篇论文就是一个很好的例子。把大家都在使用的预处理环节,作为创新立足点。文章发表在SPIE会议上,级别不算很高,但也还不错。 抓重点与三合一【Patches ROI——Exudate——Pretrained CNNs 2020】 先来解释一下,论文缩写名称中的“Patches ROI”是怎么回事,为什么多了“ROI”? 前面4篇论文都使用了Patches方法。并且,虽然滑窗的滑动方式有细节差异,但总体上,都是滑动遍历整个图像区域,对生成的所有Patches,进行无差别处理,统一输入分类器,进行分类识别。 大家稍微思考一下,就会意识到,这种处理方法的效率是很低的。如同第一篇论文提到的,即使把原始图像降采样到256x256后,也会生成超过5万个Patches。对于大多数正常或不是特别严重的图像来讲,其中大部分都是正常的背景区域。而把5万多个Patches,一股脑都扔给分类器去分类,显然效率很低。 相比之下,眼科医生的读片方式,往往是快速扫视整个图像,快速定位疑似病灶区域,再盯着疑似病灶所在的局部区域,去仔细观察。显然,这是一种更有重点,更高效的方法。 应该是受到了相似的启发,本篇论文的创新点之一,就是先使用传统图像处理方法(高斯混合模型),对图像进行整体分析(特征增强),快速定位出疑似病灶的区域,然后只在疑似区域范围内生成Patches,再用CNN对生成的Patches进行分类。如下图所示,就是具有高亮度像素值的区域,就是高度疑似存在Exudates的区域。
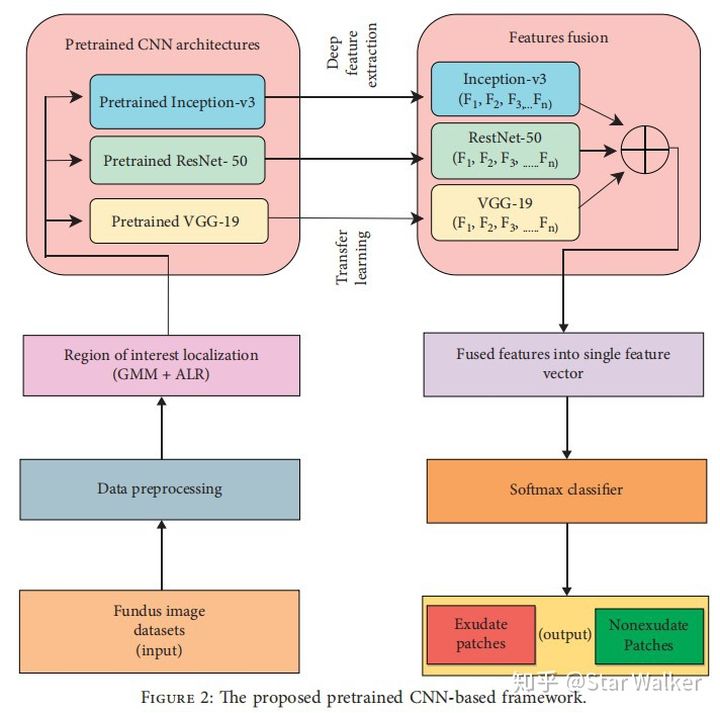
作为另外一个创新点,在分类器的设计上,作者不仅使用了更复杂的深度网络,而且是把当前三个最流行的深度学习分类网络都纳入囊中,组合起来使用。这三个网络分别是Inception-v3,RestNet-50,VGG-19。整个分类器设计如下图所示。
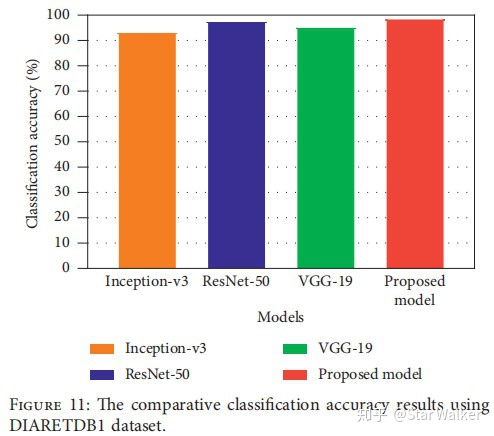
大家知道,要想把上面3个网络模型训练好,需要非常庞大的训练数据集。为了缓解训练数据集不够的问题,作者采用了迁移学习策略,也就是,都使用的是预训练网络模型。 看到这里,大家心里可能会问,为什么非要用3个网络? 对于这个问题,作者在文中专门回答了。作者认为,每个网络模型基于不同的架构,能够从图像中提取出不同的特征。同时采用3个网络模型,提取出的特征最全面,避免遗漏潜在的有价值特征,特征提取的效果会最好。 那么,第二个问题来了,使用3个网络模型,真的会取得更好的效果吗? 对于这个问题,作者也提前想到了。(必须给作者的前瞻性思维点赞啊!)在试验部分,作者专门把自己设计的三合一网络模型,和三个单独网络模型,进行了分类准确率对比。概括来说,作者的三合一模型,略胜一筹。下面是来自论文的准确率对比。
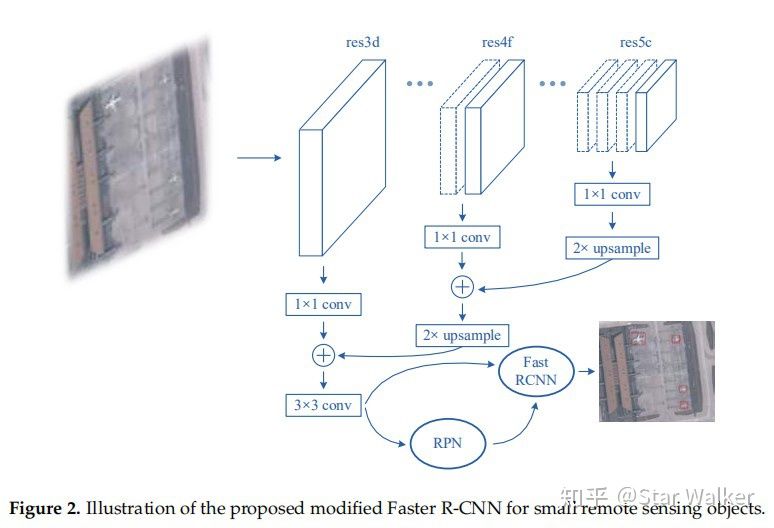
说“略胜一筹”,其实也就是1%~5%的差别。也就是说,三合一模型的准确率,比表现最好的ResNet-50单网络模型,仅仅高出1个百分点。套用现在比较热点的一句话,可以说,没有统计学意义,或者说,没有显著差异。但是,同时采用3个模型,在模型的训练、预测和部署成本上,却是有显著(极大)差异的。 也就是说,如果让软件工程师或商业化公司来选择,几乎肯定选择更简单的ResNet-50单网络模型,而不会花费额外成本,去追求那1个百分点的准确率提升。 看看隔壁别人家孩子——面向小目标优化的Faster R-CNN【Faster R-CNN——Optical Remote Sensing Image——Small Objects 2018】 如果今天的分享到这里就结束了,大家肯定觉得少了些什么。 没错,我也有同感。因为,前面讨论了5篇眼底病变检测的论文,竟然一直都没有出现目标检测领域的王者,Faster R-CNN。是啊,我也不知道为啥,努力去找了,但确实没有找到用Faster R-CNN去检测眼底病变的论文。大家如果有发现,欢迎后台留言啊。拱手,谢了先:) 但是,隔壁别人家孩子,却做了类似的研究。这里说的隔壁,其实离眼科有些远,甚至不是医学影像领域,而是航拍图像分析领域。大家可能已经有所了解,深度学习目标检测方法提出后,有若干图像分析领域得到了极大的促进和提升,不仅仅是医学影像分析。另外还有航拍图像和遥感图像分析。 稍微思考一下,也很自然。航拍图像和遥感图像都有一个特点,那就是图像大、目标小。所以,在大图像中检测小目标,应该是这个领域更加关注,或者说必须解决的问题。 这篇论文的中心思想非常明确,作者在摘要中,明确说了,就是研究“ how to modify Faster R-CNN for the task of small object detection”。 作者首先讨论了为什么常规的Faster R-CNN用于遥感图像目标检测,效果不佳。 原因很直接,遥感图像中要检测的目标在图像中所占面积太小了。Faster R-CNN初始是基于PASCAL VOC数据集提出的。PASCAL VOC中,要检测的目标通常占据图像的大部分面积;而作者所要检测的遥感图像中的飞机或船舶,所占面积通常在10x10~100x100像素范围内。这样的面积与咱们前面讨论的眼底病灶面积是非常接近的。但这么小的面积,在Faster R-CNN的FPN阶段,很容易就被模糊掉了;并在RPN阶段,如果直接采用常规Bounding Box尺寸,也很难捕捉到。 除了检测目标面积小,作者还面临一个额外的难题。就是阳性样本太少。换个好理解的说法,作者手上有一批遥感图像作为训练数据集,目标是检测定位其中的飞机或船舶,但这些图像中,包含的飞机和船舶数量很少。用医学术语来说,类似于拿到了一批肺部CT扫描影像,但大多数来自于健康人,可供学习的肺结节(阳性)样本太少。用深度学习术语来说,就是样本分布极度不均衡。 看来,作者面对遥感图像需要解决的问题,比咱们面对眼底影像需要解决的问题,要多,要困难啊。 那么,作者用了哪些方法来克服困难呢? 首先,对于常规Faster R-CNN容易漏掉小目标的问题,作者对Faster R-CNN进行了改进。包括两个方面:1)根据要检测的目标大小,修改重新设置了RPN阶段的Anchors尺寸,从而更好的定位小目标;2)选择FPN的不同层级网络,把高分辨率Feature Map和低分辨率Feature Map级联,从而在最终的Feature Map中包含小目标信息。 改进后的网络结构如下图。
其次,在常规Proposal Region以外,额外增加了包含范围更大的Context Region,用于帮助识别是否包含目标。作者提到,有时目标太小了,在Feature Map中变成了一个像素,很难判断是背景还是目标。因此,作者创造性引入了Context Region,来解决这个问题。大家看下图,应该就可以理解。
此外,为了解决缺少阳性样本,样本极度不均衡问题,作者采用了两种处理方法。1)对阳性样本引入随机旋转,达到样本扩容;2)在每个Batch抽样选择样本时,允许对阳性样本重复选择,多次利用,从而达到样本均衡。 有了上述方法的加持,作者在试验中,确实显著提高了小目标检测准确率。比较来讲,如果直接采用原版常规Faster R-CNN,mAP为66.6%;而加入作者提出的上述改进措施后,mAP可以提升到78.9%。这个提升无疑是有统计意义,是有显著差异的。 他山之玉要和大家分享的主要内容,就是这些了。在结束之前,有些想法还可以再唠叨一下。 我们用了本文的大半部分篇幅,分享了5篇眼底病变检测的论文。然后提出了一个问题,为什么大家都在用Patches方法,而没有人尝试Faster R-CNN方法?更进一步,其实我们更想知道,Faster R-CNN是否可以用于小目标检测?如果可以,又该如何使用或优化? 这些问题,最后一篇来自遥感图像目标检测的论文,给出了很好的分析和解答。论文中实验数据也确实证明了,经过改造,Faster R-CNN确实可以比较好的完成小目标检测。但需要注意,必须进行改造才行。原版无改造的Faster R-CNN,直接拿来用,效果并不好。 再回过头来看前面的5篇眼科论文,使用滑窗,产生固定尺寸的Patches,再把Patch输入到包括CNN在内的分类器进行分类。这种处理方式,实际上可以被看做是一种最简单初级的R-CNN,只是Anchor尺寸固定,并且不做区域筛选。由于Anchor尺寸固定,不太能适应和包容检测目标的大小变化,必然会影响和限制检测的准确率;由于缺少有效的区域筛选(Region Proposal),这种方式要耗费大量时间,去处理一些不重要的(低价值的)背景区域,检测的效率也并不高。 从方法的先进性上,Faster R-CNN肯定更加先进。也为大家进一步“魔改”,找到自己的创新点,发表论文,留有更大的空间。 但另一方面,从工程实用性来讲,基于Patches的方法,仍然是非常有价值的。简单直接,编程实现快,调参训练成本低,这些都是工程师和产业化所钟意和在意的。并且,与自动驾驶、航拍等应用不同,医学影像分析分析对分析的实时性,要求并不高。自动驾驶往往要求,一秒钟内分析完成多少帧。而对于眼底影像,只要3~5秒内,哪怕10秒内,能完成单张图像的分析,就完全可以接受。所以,Faster R-CNN中强调和追求的Faster,在医学影像中,就不那么吸引人了。 最后,还有一些问题,【Faster R-CNN——Optical Remote Sensing Image——Small Objects 2018】,这篇文献发表于2018年。在它之后,是否还有后续文章,提出更创意的改进?来自遥感图像分析领域的他山之玉,如果用于眼底影像分析,效果会如何? 原文:https://zhuanlan.zhihu.com/p/138108192 引用文献 【Patches——Hard Exudates——CNN 2018】——Detection of Hard Exudates in Retinal Fundus Images using Deep Learning[J]. 2018. https://arxiv.org/abs/1808.03656【Patches——Microaneurysm——Machine Learning Methods 2018】——Microaneurysm Detection Using Principal Component Analysis and Machine Learning Methods. IEEE Transactions on Nanobioscience, 2018:1-1.【Patches——Exudates——Deeply learnable features 2018】——Exudate detection in fundus images using deeply-learnable features[J]. Computers in biology and medicine, 2019, 104: 62-69.【Patches——Microaneurysm——Different Preprocessing 2020】——Automated detection of microaneurysms in color fundus images using deep learning with different preprocessing approaches, Medical Imaging 2020: Imaging Informatics for Healthcare, Research, and Applications. International Society for Optics and Photonics, 2020, 11318: 113180E. https://arxiv.org/pdf/2004.09493.pdf【Patches ROI——Exudate——Pretrained CNNs 2020】——Exudate Detection for Diabetic Retinopathy Using Pretrained Convolutional Neural Networks. Complexity. 2020. 1-11. 10.1155/2020/5801870.【Faster R-CNN——Optical Remote Sensing Image——Small Objects 2018】——Small object detection in optical remote sensing images via modified faster R-CNN[J]. Applied Sciences, 2018, 8(5): 813. https://www.mdpi.com/2076-3417/8/5/813/pdf【Review——Diabetic Retinopathy Deep Learngin 2019】——Asiri N, Hussain M, Al Adel F, et al. Deep learning based computer-aided diagnosis systems for diabetic retinopathy: A survey[J]. Artificial intelligence in medicine, 2019. |



【本文地址】