| 3D目标检测技术发展综述 | 您所在的位置:网站首页 › 2021年小目标检测最新研究综述 › 3D目标检测技术发展综述 |
3D目标检测技术发展综述
|
梁小芳 余华平
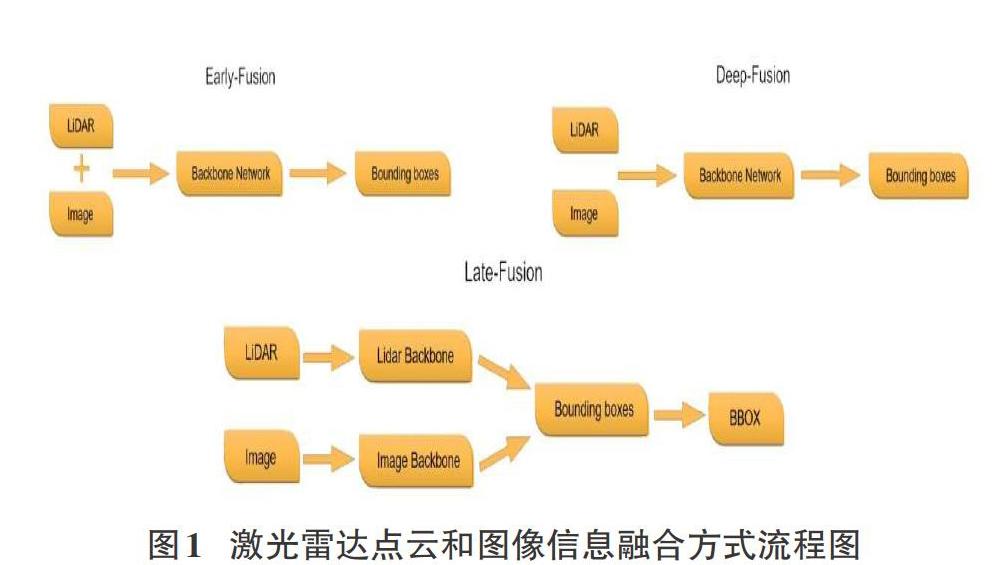
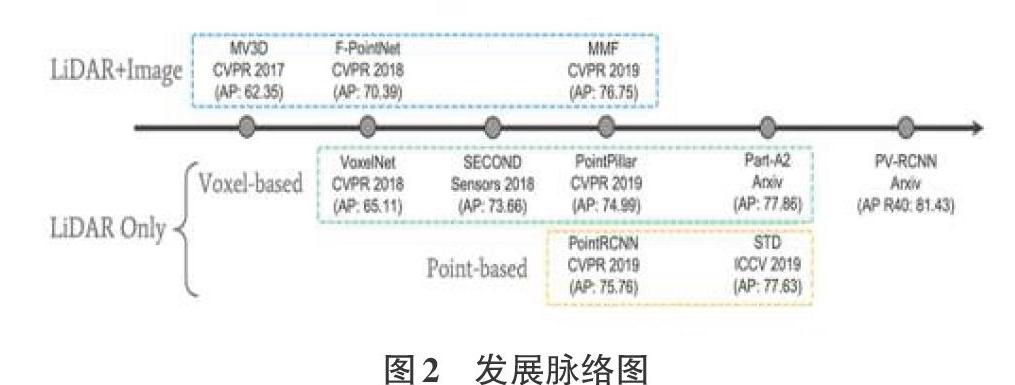
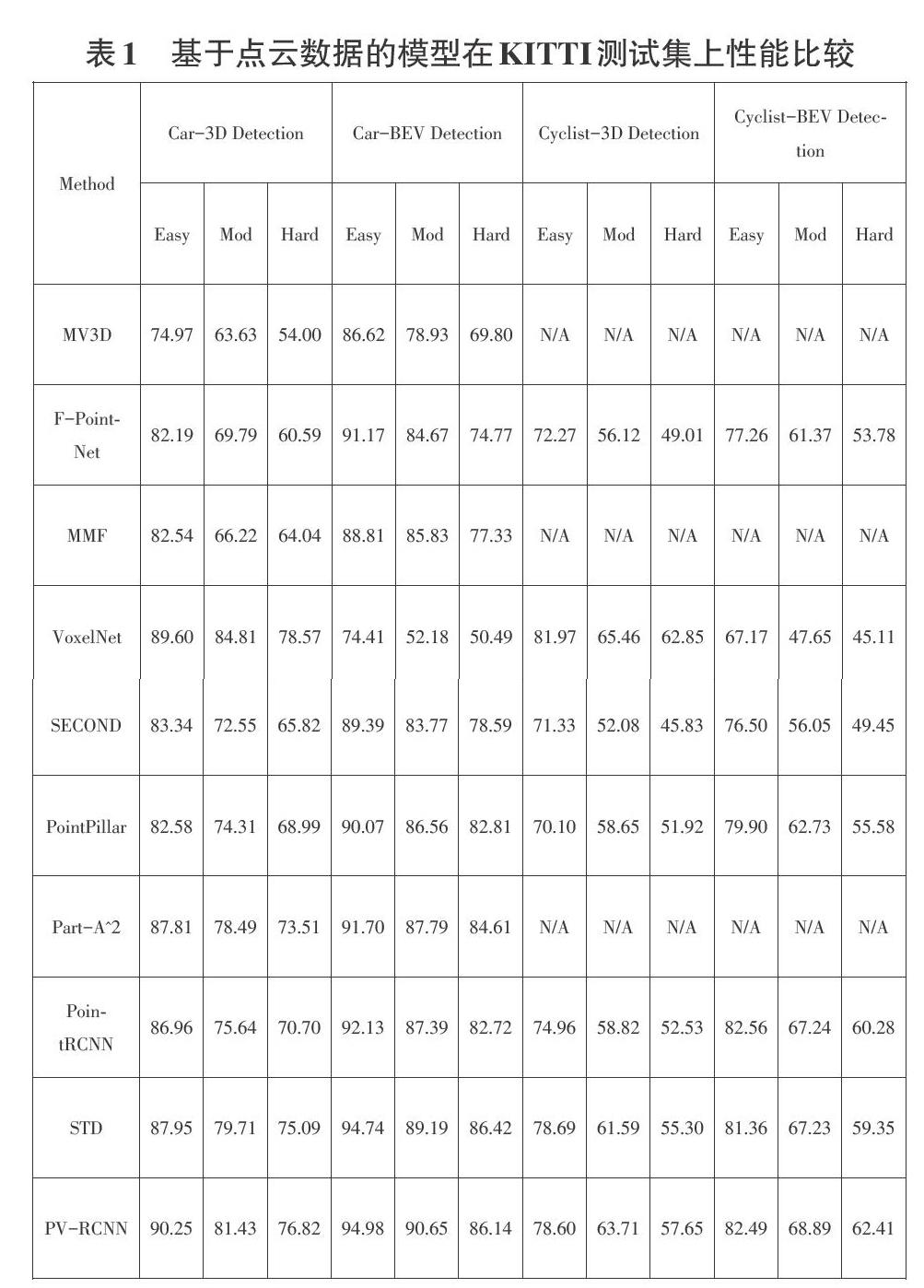
摘要:目标检测是计算机视觉领域的一个重要分支,由于2D目标检测技术自身的发展限制和近年来硬件技术的发展与应用,3D目标检测技术逐步取得了较不错的成绩,并为目标检测技术打开了新的应用领域,如AR/VR、自动驾驶、文化遗产保护等。文中从2个方向,4个分支介绍近年来3D检测技术领域的经典架构以及关键性知识,简要分析了各架构特点,并对3D目标检测技术的发展做出总结与展望。 关键词:目标检测;深度学习;激光雷达点云;图像数据;神经网络 中图分类号:TP399文献标识码:A 文章编号:1009-3044(2021)01-0231-04 Abstract: Target detection is an important branch in the field of computer vision, Due to the limitations of the development of 2D target detection technology and the development and application of hardware technology in recent years,3D target detection technology has gradually achieved relatively good results and opened up new possibilities for target detection technology. The application areas of the company, such as AR/VR, autonomous driving, cultural heritage protection, etc. The article introduces the classic architecture and key knowledge in the field of 3D detection technology in recent years from 2 directions and 4 branches, briefly analyzes the characteristics of each architecture, and summarizes and prospects the development of 3D target detection technology. Key words: target detection;deep learning;LIDAR point cloud; image data; neural network 1引言 在计算机视觉领域,目标检测是近些年来引发各界关注的主要方向之一,其理论的进步和在各大领域的广泛应用,很大程度上利用计算机视觉技术节约了对人力资源的消耗。目标检测需要识别出物体的位置和相应类别信息,根据输出结果的不同,分为2D目标检测和3D目标检测。与2D目标检测相比,3D目标检测包含物体的长度、宽度、高度以及旋转角度等信息,因此,实际应用中,3D空间的目标检测具有更深远的意义,在AR/VR、遥感测绘、军事勘察、无人驾驶、生物医学检测、文化遗产保护等领域,3D目标检测技术能很好体现自身优势,从而完成相关任务。 2基于点云的3D目标检测 3D目标检测问题本质上是三维点的划分问题,而激光雷达点云是通过众多无序数据点组成的集合进行表达的。与单视图和多视图对比发现,激光雷达点云中点的深度属性能够被直接测量,所以基于激光雷达点云的3D目标检测方式显得更为直观和精准,同时由于一般深度相机的视野问题,激光雷达点云可以更好地应用于户外环境下的大尺度场景。 关于点云数据的3D目标检测研究,目前国际上大致分为两个方向,一个方向是将图像数据和点云数据进行融合,另一个方向则是仅以点云数据作为输入。本章将从这两个方向对近年来较优秀模型进行介绍。 2.1 激光雷达点云与图像融合的3D目标检测 从信息论来看,多传感器具有更多的互补信息,采用多模态的信息能够很好地提高鲁棒性和检测准确率。在3D目标检测中,将激光雷达点云和图像信息进行融合的主要方法为前融合(Early-Fusion)、中间层融合(Deep-Fusion)和后融合(Late-Fusion)。它们的简要流程如图1所示。 Early-Fusion 指的是在对原始传感器数据进行提取特征任务之前对特征进行融合。通常表现为将多个单独的数据集处理成单一的特征向量,然后输入到分类器中,再经过深度学习网络实现边框回归。理论上,这种融合方法是多模态融合中效果最好的方法,因为此时对应的特征在现实中存在一定的索引关系和更少的特征抽象。但前融合技术通常不能很好地利用不同模态数据间的互补特性,并且前融合的原始数据经常含有非常多的冗余信息。所以,前融合方法经常和特征提取方法进行结合,从而达到剔除冗余信息的目的,如最大相关最小冗余算法(MRMR)、自动解码器(Autoencoders)、主成分分析(PCA)等。 Deep Fusion需要在特征层中做一定的交互。激光雷达点云和图像数据的分支都各自采用自己的特征提取器,并且各分支网络在前馈层次中进行逐语义级别的融合,做到多尺度(multi-scale)信息的语义融合。其主要特点是可以灵活选择进行融合的位置。因此也是最可能创造出新的融合方法的融合方式。 Late fusion是最简单的融合方法,核心思想就是两种模态的特征不在特征层或者最开始就融合,因为不同传感器的数据本身存在比较大的差异,就激光雷達和图像而言,最大的差异就在视图的不同,图像中物体尺度会随距离变化而发生改变,但是点云数据不存在这个问题。此外,点云和图像做特征层的融合最大的难点是像素和点云点之间索引精准性和领域差异。而该融合方式的误差来自多个分类器,不同分类器的误差通常互不干扰,从而不会使误差发生累加现象。较普遍的后融合方式包括平均值融合(Averaged-Fusion)、贝叶斯规则融合(Bayesrule Based)、最大值融合(Max-Fusion),以及集成学习(Ensemble Learning)等。 通过上述内容不难发现,Early-Fusion、Deep-Fusion和 Late-Fusion分别是在输入层、特征层和决策层上的融合。 目前3D目标检测的多模态融合方法可以从MV3D(CVPR17)说起,它是将点云数据以特定的视角投影到二维平面,再将不一样视觉角度的数据进行融合,从而完成认知任务。该方法进行鸟瞰视角投影时会丢失几何结构信息,损失精度,并且实验最终结果显示MV3D只对汽车结果较好,对行人和自行车的检测表现的都很差。 F-PointNet没有对激光雷达点云和图像这两类信息分别处理(并行)进行融合,而是通过串行方式,先在2D目标检测器中生成边框,然后再投影到三维点云上对边框做进一步的优化工作。该类方法提高了检测效率,实现了逐维(2D-3D)定位,缩短了对点云的搜索时间,并且几乎没有任何维度的信息损失。但其突出劣势表现为整个流程对2D的检测效果比较依赖,且无法解决遮挡问题。 MMF(CVPR19)创新点主要是第一次将图像特征投影到鸟瞰视图(BEV图)中做回归,其次是解决了BEV视图信息和图像信息在点对点(point-wise)级别的融合问题。 以上三个架构是近年来通过激光雷达点云和图像数据融合进行3D目标检测方向的优秀作品,从中可以看出。多模态融合的3D目标检测目前普遍存在以下难点: 1) 传感器视角差异:摄像头由于小孔成像原理,是从视锥出发获取信息,而激光雷达是在真实的3D世界中获取信息。 2) 数据表征不同:图像数据是规则、稠密的,而点云数据则是无序、稀疏的。 3) 信息融合难度:图像数据因距离存在尺度问题,2D检测中,深度学习方法都是以CNN结构为基础进行设计,而点云数据具备几何结构和深度信息,无法采用传统的CNN架构感知,且点云目标检测领域中有MLP、CNN,GCN等多个简单结构构成的网络,在融合过程中将哪几种网络进行融合是需要进行研究的。 2.2激光雷达点云的3D目标检测 相对于激光雷达点云与图像融合方式而言,纯点云数据做数据增强更容易,因为不需要考虑数据间的对应关系。 为了方便分析,相关学者将使用纯激光雷达点云的3D检测分为基于点素(Point-Based的)和基于体素(Voxel-Based)两个分支。Point-Based方式采用原始的点云数据坐标作为特征载体,直接利用激光雷达点云进行处理。Voxel-Based方式将点云数据转化成规则数据,利用卷积实现任务,换而言之,该方式将voxel中心作为CNN感知特征载体,但相对原始点云对图像的坐标索引来说,voxel中心与原始图像的索引存在偏差。 苹果公司提出的VoxelNet架构将三维点云划分为一定数量的voxel,经过点的随机采样及归一化处理后,对每一个非空voxel都采用若干个VFE层进行局部特征提取,然后经过中间的3D卷积层进一步特征抽象处理,实現增大感受野并学习几何空间特征,最后使用RPN对物体进行分类检测与位置回归。该方法提出了端到端、可训练的深度网络架构,可以直接处理稀疏的3D点云,避免了因人工设计的特征而引入的信息瓶颈问题。 SECOND方法是一个一阶段的用于3D激光点云的目标检测方法,主要特点为: 1)使用了3D稀疏卷积(SparseConvolution),大大提升了3D卷积的速度; 2)数据库采样的操作被应用到数据增强过程中; 3)分类损失使用了focal loss,方向损失使用smoothL1(sin(theat1-theta2))+softmax loss。 PointPillar是一种新颖的编码器,它利用PointNet架构来学习在垂直列柱体组织中的点云的特征,完成3D物体检测网络的端到端训练;通过将柱体上的所有计算都设置为稠密的2D卷积,从而实现62 Hz的检测速率,比前期其他方法快2-4倍; Part-A^2首次将稀疏卷积(SparseConvolution)应用到两阶段(Two-Stage)的3D点云目标检测中,整个网络分为局部感知(Part-Aware Stage)和局部聚集(Part-Aggregation Stage)这两个模块。Part-Aware Stage将整个空间栅格化,然后对每一个格子生成特征,使用全连接层和最大池化(MaxPooling)方法对栅格内的点云自动进行特征提取,得到每个栅格的特征,这个阶段的输出是4维的特征图和区域提案。Part-Aggregation Stage对前一阶段产生的voxel实现池化和分类。 PointRCNN是第一个从原始点云进行3D物体检测的Two-Stage框架,也是首个基于点云的免锚提案生成策略的方案,实现了纯粹使用点云数据完成3D目标检测任务,并且很好地解决了遮挡问题和以及检测过程中对2D检测结果的依赖。该框架包括两个部分:第一部分通过将前景点分割的方式,实现从原始点云空间产生3D提案;第二部分通过使用规范的坐标来调整提案,从而获取最后的检测结果。 STD是腾讯优图和港科大的研究成果,它是一个Two-Stage方法,先通过语义信息对每一个点生成一个球形锚(anchor),再通过非极大值抑制(NMS)方法得到最终的分类提案,接下来是点池化层得到每一个提案的特征,采用的是VFE操作,这一阶段区别于VoxelNet系列,VoxelNet系列的特征是以小size的anchor为单位,而STD则是以一个“提案”为单位进行提取的。第二阶段是一个巨大的创新,是将交并比分支(IOU Branch)和边框预测分支(Box Prediction Branch)进行结合。 香港中文大学团队提出了一种新颖的高性能3D对象检测框架,称为PointVoxel-RCNN(PV-RCNN),用于从点云中进行精确的3D对象检测。该方法也是一个Two-Stage方法,将3D体素卷积神经网络和基于PointNet的集合进行抽象,通过深度集成来学习更多判别性点云功能。它利用了3D体素CNN的高效学习和替代提案以及基于PointNet的网络灵活接收范围等优势。PV-RCNN不仅是一个Multi-Scale和voxel的特征信息融合,同时也是point和voxel的融合。point的方法具有可变、多尺度感受野的特征,而voxel的方法则具有高效性,PV-RCNN将这两点得到了很好的体现。 图2展示的是近几年来基于激光雷达点云数据进行3D目标检测的主要发展脉络。 表1展示的是基于激光雷达点云数据进行3D目标检测的几大模型在KITTI测试集上的性能比较,这些结果是通过具有40个召回位置的平均精度评估结果。 3基于非激光雷达点云的3D目标检测 3.1单目图像下的3D目标检测 2017年CVPR中,A.Mousavian团队提出了一种利用单目图像对目标物体进行朝向、大小和3D位置进行预测的方法。这种算法框架主要由2D目标检测网络、目标大小姿态估计网络、目标3D中心点向量求解模块这三个部分构成。它首次利用深度神经网络获得了相对稳定的3D对象属性,并利用这些属性和2D几何约束,得到了3D的边框,与此同时,这种方法不需要预处理阶段,并为后人提供了MultiBin回归这种新颖的用于估计物体方向的思路。 以王晓刚教授为主导的香港中文大学和商汤科技团队提出的高性能3D目标检测框架——GS3D,是一种基于可靠2D检测结果和表面特征的三维车辆检测算法,它的主要流程是:利用2D检测器得到目标物体的方向和边界框,然后得到具有指导意义的粗糙长方体3D边界框,再利用3D边框重投影到二维平面的信息来获取目标物体的3D表面特征;最后将2D边框提取的纹理信息和3D边框提取的表面特征融合,获得更加精细化的3D检测框。GS3D为单目图像下的3D目标检测模型的精细化提供了指导性思路。 YOLO-6D是利用YOLO系列进行3D目标检测的优秀算法,相比之前同类型算法,它的运行速度相对稳定,几乎不受运行时间和目标数量影响,并且避免了因微调结果导致物体检测超时问题,但它主要弊端是需要使用先验3D模型知识。YOLO-6D通过预测目标物体3D边框的1个中心点和8个顶点以及后续的PNP算法,实现了将6D姿态预测问题到9个坐标点预测的转换。 3.2基于RGB-D图像下的3D目标检测 计算机图形领域,含有与目标对象表面距离有关信息的图像或图像通道被称为深度图,传感器与物体的实际距离就是由深度图的像素值来表示。由于RGB图像和深度图像的配准关系,像素点间具备一一对应关系。 2014年,RGB大神对2D目标检测架构——R-CNN进行改进,通过模块对深度图实现利用,第一阶段基于RGB图像和深度图,检测图像中的轮廓,并生成包括每个像素的视差、高度、倾斜角2.5D的提案。第二阶段利用DepthCNN和RGB CNN分别提取深度图和2D图像特征,最后使用SVM实现最终分类任务。 随后,2015年陈晓智团队将R-CNN推广到RGB-D图像,引入一种新的编码方式来捕获图像中像素的地心姿态,该方式比单独利用深度通道取得了更好的实验效果。普林斯顿大学学者,提出的方法为Faster R-CNN的3D版本,侧重于室内场景下的目标检测。该团队增加了多种尺度的检测手段来检测各种大小不一的目标。具体来说,是在不同的卷积层上进行3D滑窗,最后得到6个偏移量:来自坦普尔大学的学者则利用Fast R-CNN架构,重新回到2.5D方法来进行3D目标检测。即从RGB-D上提取出合适的表达,而后建立模型以将2D结果转换为3D空间。 虽然利用三维几何特征实现3D目标检测前景光明,但在实践中,重建的三维形状往往不完整,并且由于遮挡、反射等原因包含各种噪声。 4结论 随着硬件技术和理论技术的发展,3D目标检测领域硕果累累,一定程度上改善了人类的生活习惯,促进了科技发展并推动了社会进步。尽管3D目标检测发展势头迅猛,但也不难发现,该领域仍存在许多暂时难以突破的瓶颈,如单目图像下的3D目标检测中,由于透视投影存在,很难捕捉局部目标和尺度问题;基于深度图的3D目标检测因遮挡、光线等造成数据噪声较多,极大影响三维重建过程;在基于激光雷达的3D目标检测方向,采用激光雷达点云与图像进行融合时,两者间的数据配准以及对运算对显存的极高要求暂时还未有突破性进展。 虽然在3D目标检测技術的发展道路中存在许多艰辛,但其潜力仍不能小觑,未来3D目标检测技术在识别精准度以及实时性方面或许会吸引更多的学者参与研究,当然各种因技术发展引发的道德伦理以及个人隐私和信息安全等问题也需要引起各界重视。 参考文献: [1] Chen X, Ma H, Wan J, et al. Multi-view 3d object detection network for autonomous driving[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1907-1915. [2] Qi C R, Liu W, Wu C, et al. Frustum pointnets for 3d object detection from rgb-d data[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 918-927. [3] Liang M, Yang B, Wang S, et al. Deep continuous fusion for multi-sensor 3d object detection[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 641-656. [4] Zhou Y, Tuzel O. Voxelnet: End-to-end learning for point cloud based 3d object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4490-4499. [5] Yan Y, Mao Y, Li B. Second: Sparsely embedded convolutional detection[J]. Sensors, 2018, 18(10): 3337. [6] Lang A H, Vora S, Caesar H, et al. Pointpillars: Fast encoders for object detection from point clouds[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 12697-12705. [7] Qi C R, Su H, Mo K, et al. Pointnet: Deep learning on point sets for 3d classification and segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 652-660. [8] Shi S, Wang Z, Shi J, et al. From Points to Parts: 3D Object Detection from Point Cloud with Part-aware and Part-aggregation Network[J]. arXiv preprint arXiv:1907.03670, 2019. [9] Shi S, Wang X, Li H. Pointrcnn: 3d object proposal generation and detection from point cloud[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 770-779. [10] Yang Z, Sun Y, Liu S, et al. Std: Sparse-to-dense 3d object detector for point cloud[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 1951-1960. [11] Shi S, Guo C, Jiang L, et al. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10529-10538. 【通聯编辑:梁书】 猜你喜欢 目标检测神经网络深度学习 基于自适应神经网络的电网稳定性预测华东师范大学学报(自然科学版)(2019年5期)2019-11-11基于深度卷积神经网络实现端子批量识别研究科技资讯(2019年1期)2019-04-27基于遗传算法对广义神经网络的优化智富时代(2018年7期)2018-09-03基于遗传算法对广义神经网络的优化智富时代(2018年7期)2018-09-03交通信号灯识别现状研究科技传播(2018年15期)2018-08-21直升机相控阵毫米波防撞雷达信号处理技术研究电子技术与软件工程(2017年15期)2018-01-30三次样条和二次删除相辅助的WASD神经网络与日本人口预测软件(2017年6期)2017-09-23促进深度学习,提升数学核心素养江苏教育(2016年19期)2017-03-12基于BP神经网络PID控制的无刷直流电动机调速系统设计电子技术与软件工程(2016年24期)2017-02-23历史深度学习的六个着力点教学与管理(中学版)(2016年12期)2017-01-07
|
 电脑知识与技术2021年1期
电脑知识与技术2021年1期【本文地址】