| 位、字节、字、寻址能力、编码方式、大端小端 | 您所在的位置:网站首页 › 16位寻址方式 › 位、字节、字、寻址能力、编码方式、大端小端 |
位、字节、字、寻址能力、编码方式、大端小端
|
一、机器/系统相关
1.名称表
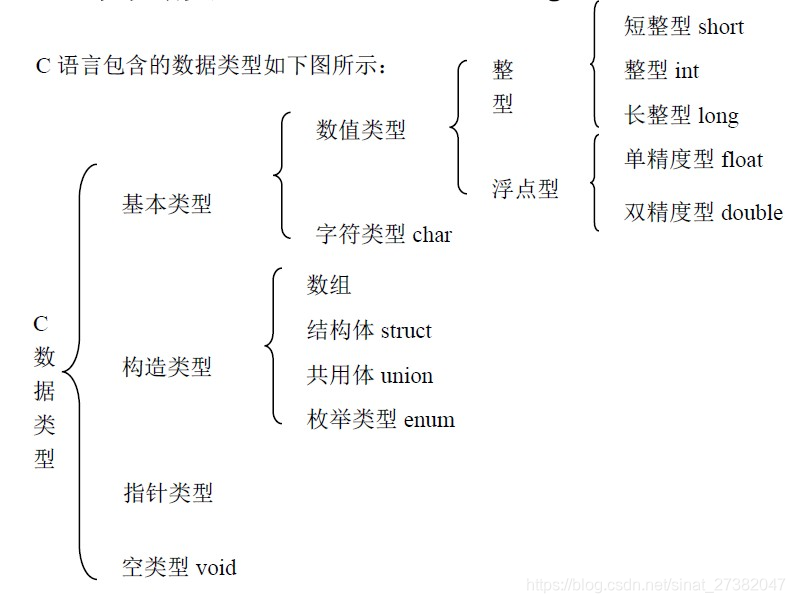
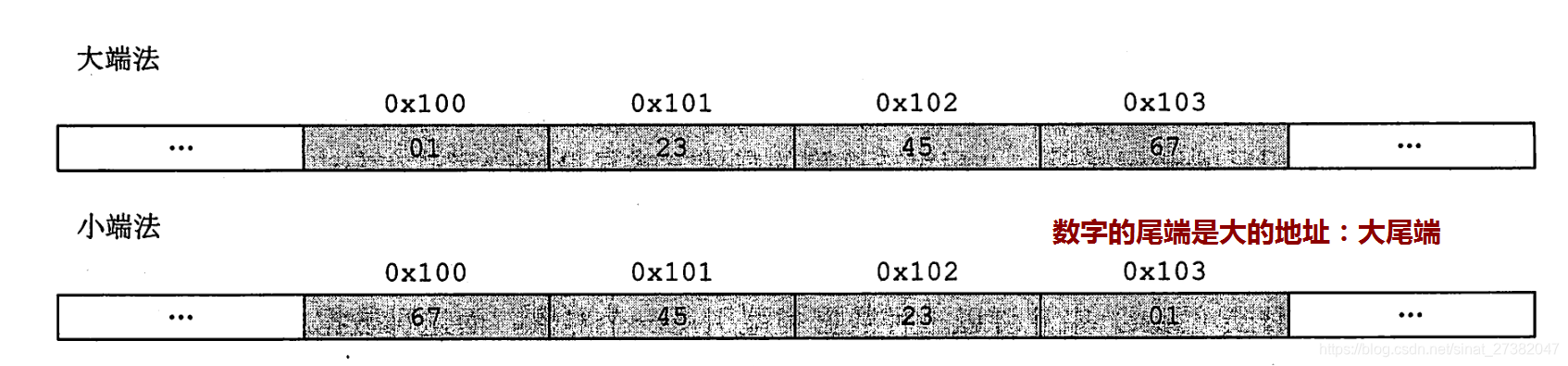
8位(比特、bit) = 2字节(Byte)= 1字(WORD)【总线所说的“字”根据系统而不同】 1、位(比特) 位是计算机存储的最小单位,简记为b,也称为比特(bit)计算机中用二进制中的0和1来表示数据,一个0或1就代表一位。位同时也是二进制数字中的位,是信息量的度量单位,为信息量的最小单位; 2、字节 字节,英文Byte,是计算机用于计量存储容量的一种计量单位,通常情况下一字节等于八位,字节同时也在一些计算机编程语言中表示数据类型和语言字符,在现代计算机中,一个字节等于八位; 3、字 字是表示计算机自然数据单位的术语,在某个特定计算机中,字是其用来一次性处理事务的一个固定长度的位(bit)组,在现代计算机中,一个字等于两个字节。 除此之外还有 双字DWORD、四字QWORD 2.寻址与字长1.机器字长,是指CPU一次能处理数据的位数,通常与CPU的寄存器位数有关。 2.指令字长,计算机指令字的位数。指令字长取决于从操作码的长度、操作数地址的长度和操作数地址的个数。不同的指令的字长是不同的。 3.存储字长,是一个存储单元存储一串二进制代码(存储字),这串二进制代码的位数称为存储字长。 4.数据字长:计算机数据存储所占用的位数。 通常早期计算机:存储字长 = 指令字长 = 数据字长。故访问一次便可取一条指令或一个数据,随着计算机应用范围的不断扩大,三者可能各不相同,但它们必须是字节的整数倍。 CPU按照其处理信息的字长可以分为:8位微处理器、16位微处理器、32位微处理器、64位微处理器等。 CPU最大能查找多大范围的地址叫做寻址能力,CPU的寻址能力以字节为单位 如32位寻址的CPU可以寻址2的32次方大小的地址也就是4G,这也是为什么32位的CPU最大能搭配4G内存的原因,再多的话CPU就找不到了。 ——原则上32位cpu是不能装64位系统的(电脑已经很少有32位的cpu) 操作系统按照 32位操作系统支持的内存是2的32次方,也就是4GB内存。 64位操作系统理论上的寻址空间为2的64次方bit,转化单位为2147483648GB。 3.编码方式(乱码产生的原因)ASCII码:一个英文字母(不分大小写)占一个字节的空间。一个二进制数字序列,在计算机中作为一个数字单元,一般为8位二进制数。换算为十进制,最小值-128,最大值127。如一个ASCII码就是一个字节。 UTF-8编码:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。中文标点占三个字节,英文标点占一个字节 Unicode编码:一个英文等于两个字节,一个中文(含繁体)等于两个字节。中文标点占两个字节,英文标点占两个字节 理解编码的关键,是要把字符的概念和字节的概念理解准确。这两个概念容易混淆,我们在此做一下区分: 概念描述 举例 字符人们使用的记号,抽象意义上的一个符号。 ‘1’, ‘中’, ‘a’, ‘$’, ‘¥’ …… 字节计算机中存储数据的单元,一个8位的二进制数,是一个很具体的存储空间。0x01, 0x45, 0xFA…… 字 在计算机中,一串数码作为一个整体来处理或运算的,称为一个计算机字,简称字。字通常分为若干个字节(每个字节一般是8位)。在存储器中,通常每个单元存储一个字,因此每个字都是可以寻址的。字的长度用位数来表示。 在计算机的运算器、控制器中,通常都是以字为单位进行传送的。字在不同的地址出现其含义是不相同。例如,送往控制器去的字是指令,而送往运算器去的字就是一个数。 字符串 在内存中,如果“字符”是以ANSI编码形式存在的,一个字符可能使用一个字节或多个字节来表示,那么我们称这种字符串为ANSI字符串或者多字节字符串。如,“中文123” (占8字节,包括一个隐藏的\0)。 字符集 对于ANSI编码方式,存在不同的字符集(Charset)。同样的字节序列,在不同的字符集下表示的字符不一样。要正确解析一个ANSI字符串,还要选择正确的字符集,否则就可能导致所谓的乱码现象。不同语言版本的操作系统,都有一个默认的字符集。在不指定字符集的情况下,系统会使用此字符集来解析ANSI字符串。也就是说,如果我们在简体中文版的Windows下打开了一个由日文操作系统保存的ANSI文本文件(仅包含ANSI字符串的文本文件),我们看到的将是乱码。但是,如果我们使用Visual Studio之类的带编码选择的文本编辑器打开此文件,并且选择正确的字符集,我们将可以看到它的原貌。注意:简体中文字符集中的繁体字和繁体中文字符集中的繁体字,编码不一定相同。 每个字符集都有一个确定的编号,称为代码页(Code Page)。简体中文(GB2312)的代码页为936,而系统默认字符集的代码页为0,它表示根据系统的语言设置来选择一个合适的字符集。 Unicode 字符串在内存中,如果“字符”是以在Unicode中的序号存在的,那么我们称这种字符串为Unicode字符串或者宽字节字符串。在Unicode中,每个字符都占两个字节。如,“中文123”(占10字节)。Unicode和ANSI的区别就相当于输入法内的“全角”和“半角”的区别。 由于不同ANSI编码所规定的标准是不相同的(字符集不同),因此,对于一个给定的多字节字符串,我们必须知道它采用的是哪一种字符集则,才能够知道它包含了哪些“字符”。而对于Unicode字符串来说,不管在什么环境下,它所代表的“字符”内容总是不变的。Unicode 有着统一的标准,它定义了世界上绝大多数的字符的编码,使得拉丁文、数字、简体中文、繁体中文、日文等都能以同一种编码方式保存。 二、实践:C语言程序。 1.存储类型在微型计算机中,通常用多少字节来表示存储器的存储容量。 在不同的系统上,这些类型占据的字节长度是不同的: short、int、long、char、float、double 这六个关键字代表C 语言里的六种基本数据类型。 在32 位的系统上 char占据的内存大小是1 个byte。 short占据的内存大小是2 个byte; int占据的内存大小是4 个byte; float占据的内存大小是4 个byte; double占据的内存大小是8 个byte; long int占据的内存大小是4 个byte; *可以用C语言关键字sizeof()来得到当前所占有字节数。 其中的整形int、浮点float、无符号unsigned 虽然在字节长度是一样的,但是存储方式不同,取读方式也不同, 详见我的另一篇博客:c语言输出0.000000或乱码,深究 2.大端、小端(字节序)大端模式Big Endian,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。 小端模式Little Endian,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。 *注 因为这张图一块内存即一个字节8位,放2个F(十六进制、4位、1111), 看这张图时要把“01”、“23”、“45”、“67”看作 “一个个字,左右结构” 所以 1.小端时不会出现“76 54 32 10” 2.对多于一个字节的short、int、double等才会出现网络字节序、大小端字节序的问题。 总线一般被设计来传输固定大小的一块数据,这块数据被称为字(word),一个字包含的字节数(即字的大小)是各种计算机系统里面的基本参数,而且这个参数在不同的系统里通常是不同的。大多数的现代计算机系统里面,一个字要么是4个字节,要么是8个字节. 由此我们可以看出,单纯问一个字占多少字节是没有意义的,因为字的大小取决去具体系统的总线宽度,如果是32位的系统(X86),则一个字是4个字节,如果是64位(X64),则是8个字节。 4.位端(位域)、位运算、结构体位运算的时候,一些用到当前最大位的情况也需要知道 #include #define WORDSIZE 32 //我现在是X86模式编译,占32位,4字节(32位=4字节) int main() { unsigned a, b, c; int n; printf("请输入a和n \n"); scanf("%x,%d", &a, &n); b = a n; c = c ^ b; printf("a:%x \nc:%x", a, c); printf("%d", IsBig_Endian()); return 0; } 三、尺度单位(国际单位制单位前缀)不同数量级间国际单位制(SI): 1KB=1024B;1MB=1024KB=1024×1024B。 国际电工委员会的电气技术用字母符号标准IEC 60027-2IEC 80000-13 数据存储是以10进制表示,数据传输是以2进制表示的,所以1KB不等于1000B。 1B(byte,字节)= 8 bit(见下文); 1KB(Kilobyte,千字节)=1024B= 2^10 B; 1MB(Megabyte,兆字节,百万字节,简称“兆”)=1024KB= 2^20 B; 1GB(Gigabyte,吉字节,十亿字节,又称“千兆”)=1024MB= 2^30 B; 1TB(Terabyte,万亿字节,太字节)=1024GB= 2^40 B; 1PB(Petabyte,千万亿字节,拍字节)=1024TB= 2^50 B; 1EB(Exabyte,百亿亿字节,艾字节)=1024PB= 2^60 B; 1ZB(Zettabyte,十万亿亿字节,泽字节)= 1024EB= 2^70 B; 1YB(Yottabyte,一亿亿亿字节,尧字节)= 1024ZB= 2^80 B; 1BB(Brontobyte,一千亿亿亿字节)= 1024YB= 2^90 B; 1NB(NonaByte,一百万亿亿亿字节) = 1024BB = 2^100 B; 1DB(DoggaByte,十亿亿亿亿字节) = 1024 NB = 2^110 B; yotta Y 10008 10^24 1000000000000000000000000 Septillion Quadrillion 1991 zetta Z 10007 10^21 1000000000000000000000 Sextillion Trilliard 1991 exa E 10006 10^18 1000000000000000000 Quintillion Trillion 1975 peta P 10005 10^15 1000000000000000 Quadrillion Billiard 1975 tera T 10004 10^12 1000000000000 Trillion Billion 1960 giga G 10003 10^9 1000000000 Billion Milliard 1960 mega M 10002 10^6 1000000 Million 1960 kilo k 10001 10^3 1000 Thousand 1795 hecto h 10002⁄3 10^2 100 Hundred 1795 deca da 10001⁄3 10^1 10 Ten 1795 10000 10^0 1 One deci d 1000−1⁄3 10^−1 0.1 Tenth 1795 centi c 1000−2⁄3 10^−2 0.01 Hundredth 1795 milli m 1000−1 10^−3 0.001 Thousandth 1795 micro µ 1000−2 10^−6 0.000001 Millionth 1960[2] nano n 1000−3 10^−9 0.000000001 Billionth Milliardth 1960 pico p 1000−4 10^−12 0.000000000001 Trillionth Billionth 1960 femto f 1000−5 10^−15 0.000000000000001 Quadrillionth Billiardth 1964 atto a 1000−6 10^−18 0.000000000000000001 Quintillionth Trillionth 1964 zepto z 1000−7 10^−21 0.000000000000000000001 Sextillionth Trilliardth 1991 yocto y 1000−8 10^−24 0.000000000000000000000001 Septillionth Quadrillionth东汉徐岳所著的《数术记遗》中,就相当完整地记载了中国表示数量的数词,由小到大依次为一、十、百、千、万、亿(10·8)、兆(10·12)、京(10·16)、垓(10·20)、秭(10·24)、穰(10·28)、沟(10·32)、涧(10·36)、正(10·40)、载(10·44),此后随着佛教的传入和文化交流,又增加了极(10·48)、恒河沙(10·52)、阿僧只(10·56)、那由他(10·60)、不可思议(10·64)、无量(10·68)、大数(10·72)等,其中万以下是十进位,万以上则为万进位。 参考引用: https://baike.baidu.com/item/字节 https://blog.csdn.net/weixin_34082177/article/details/86135393 http://bbs.gongkong.com/d/201504/613475_1.shtml https://blog.csdn.net/guosir_/article/details/78346472 https://blog.csdn.net/hammer_xie/article/details/52301243 https://www.crifan.com/big_endian_big_endian_and_small_end_little_endian_detailed/ https://zhidao.baidu.com/question/1308113215598827339.html https://www.cnblogs.com/ricksteves/p/9899893.html |
 判断是否为大端
判断是否为大端【本文地址】