| JPEG编码细节介绍 | 您所在的位置:网站首页 › 1125185078_15726966313781n.jpg › JPEG编码细节介绍 |
JPEG编码细节介绍
|
一、前言
最近在学习如何进行JPEG编码,在网上找了很多文章,发现很少有文章将每一个细节都讲得十分清楚,以至于在编程时踩了不少的坑,因此打算尽量结合python代码写一个涉及细节部分的文章。具体程序可以参考我在github上的开源项目。 二、JPEG文件中的各种标志很多文章都对JPEG文件的标志有所介绍,我也上传了一个对实际图片进行标注的文档(下载)可供参考。 所有的标志符均以0xff(16进制的255)开始,后面跟着代表本块数据的字节数以及描述本块信息的数据,具体如下图:
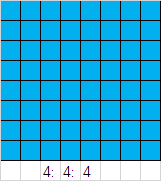
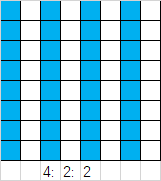
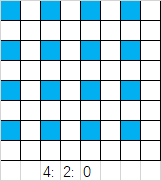
到这里我们就只剩图像数据部分没有写入了,但图像数据部分到底是如何编码的,以及上面提到的量化、哈夫曼编码具体是怎样实现的,请看下一部分的介绍。 三、JPEG编码流程由于JPEG编码过程中需要对图片进行8*8分块,这就要求图片的高度和宽度均为8的倍数,因此我们可以采用图像内插或抽样的方法,将图片进行微小的改变,变成高度和宽度均为8的倍数的图片,对于一个成千上万个像素点的图片而言,这个操作并不会对图片的整体横纵比产生很大的变化。 # 转换图片大小,必须能被切分成8*8的小块 if((h % 8 == 0) and (w % 8 == 0)): nblock = int(h * w / 64) else: h = h // 8 * 8 w = w // 8 * 8 YCrCb = cv2.resize(YCrCb, [h, w], cv2.INTER_CUBIC) nblock = int(h * w / 64) 1. 色彩空间转换JPEG图像统一采用YCbCr的色彩空间,这是因为人眼对亮度感知较强而对色度的感知则较弱,因此我们选择性的增大对Cb和Cr分量的压缩,既能保证图片观感不变,又能更大程度地减小图片的大小。变换为YCbCr空间后,我们可以对Cb Cr色彩分量进行采样,减少它们的点数,从而实现更大程度的压缩。常见的采样格式有4:4:4、4:2:2、4:2:0。这里便对应了SOF0标识中的水平采样因子和垂直采样因子。为简单起见,本文中所有的采样因子均为1,也就是不进行采样,一个Y分量对应一个Cb Cr分量(4:4:4)。而4:2:2为两个Y分量对应一个Cb Cr分量,4:2:0为四个Y分量对应一个Cb Cr分量。如下图,每个单元格对应一个Y分量,而蓝色格子则是Cb Cr分量采样的像素点。
色彩空间转换的公式为:Y = 0.299*R + 0.587*G + 0.114*B,Cb = -0.1687*R - 0.3313*G + 0.5*B + 128,Cr = 0.5*R - 0.4187*G - 0.0813*B + 128(上述运算均四舍五入位整数)。在24位的RGBbmp图片中R G B分量的范围均为0-255,经过简单的数学关系,我们不难发现Y Cb Cr分量的范围也是0-255。在JPEG图像中,通常我们需要对每个分量减去128,使范围有正有负。 python中可以使用opencv库中的函数进行色彩空间变换: YCrCb = cv2.cvtColor(BGR, cv2.COLOR_BGR2YCrCb) npdata = np.array(YCrCb, np.int16)需要注意的是,三维列表中,npdata[:,:,0]存储Y分量、npdata[:,:,2]存储Cb分量、npdata[:,:,1]存储Cr分量。 2. 8*8分块JPEG编码中是对每个8*8块进行处理,按从上到下、从左到右的顺序进行接下来的数据处理,最后将每个分块的数据组合在一起就行了。对于每一个分块的Y Cb Cr三个色彩分量,则按照Y Cb Cr的顺序,采取相同的操作(使用的量化表和哈夫曼表会有所不同)。 for i in range(0, h, 8): for j in range(0, w, 8): ... 3. DCT变换DCT(离散余弦变换),将空间域的数据换算到频域进行运算,这样我们可以在频域上选择性的减少高频分量的数据,而并不会对图像观感产生较大影响。而相对于离散傅里叶变换,离散余弦变换均是在实数域进行运算,更有利于计算机进行运算。离散余弦变换的公式如下: 其中 当然也可以使用opencv库中的函数: now_block = npdata[i:i+8, j:j+8, 0] - 128 # 取出一个8*8块并减去128 Y分量 now_block = npdata[i:i+8, j:j+8, 2] - 128 # 取出一个8*8块并减去128 Cb分量 now_block = npdata[i:i+8, j:j+8, 1] - 128 # 取出一个8*8块并减去128 Cr分量 now_block_dct = cv2.dct(np.float32(now_block)) # DCT变换 4. 量化经过DCT变换后,直流分量为8*8块的第一个元素,低频分量集中在左上角,而高频分量集中在右下角。为了选择性的去掉高频分量,我们可以进行量化操作,实际上就是对8*8方块中的每一个元素除以一个定值。量化表中左上角的元素较小而右下角较大。一组量化表例子如下所示(Y分量和Cb Cr分量使用不同的量化表): # 亮度量化表 std_luminance_quant_tbl = np.array( [ [16, 11, 10, 16, 24, 40, 51, 61], [12, 12, 14, 19, 26, 58, 60, 55], [14, 13, 16, 24, 40, 57, 69, 56], [14, 17, 22, 29, 51, 87, 80, 62], [18, 22, 37, 56, 68,109,103, 77], [24, 35, 55, 64, 81,104,113, 92], [49, 64, 78, 87,103,121,120,101], [72, 92, 95, 98,112,100,103, 99] ], np.uint8 ) # 色度量化表 std_chrominance_quant_tbl = np.array( [ [17, 18, 24, 47, 99, 99, 99, 99], [18, 21, 26, 66, 99, 99, 99, 99], [24, 26, 56, 99, 99, 99, 99, 99], [47, 66, 99, 99, 99, 99, 99, 99], [99, 99, 99, 99, 99, 99, 99, 99], [99, 99, 99, 99, 99, 99, 99, 99], [99, 99, 99, 99, 99, 99, 99, 99], [99, 99, 99, 99, 99, 99, 99, 99] ], np.uint8 )量化过程代码: now_block_qut = quantize(now_block_dct, 0) # Y分量 量化 now_block_qut = quantize(now_block_dct, 2) # Cb分量 量化 now_block_qut = quantize(now_block_dct, 1) # Cr分量 量化 # 量化 # block: 当前8*8块的数据 # dim: 维度 0:Y 1:Cr 2:Cb def quantize(block, dim): if(dim == 0): # 使用亮度量化表 qarr = std_luminance_quant_tbl else: # 使用色度量化表 qarr = std_chrominance_quant_tbl return (block / qarr).round().astype(np.int16)经过量化之后,8*8方块中右小角出现了较多的0,为了使这些0集中,使行程编码得到更少的数据量,我们接下来进行zigzag扫描。 5. zigzag扫描所谓的zigzag扫描,实际上便是将8*8的方块按照如下顺序变成一个64项的列表。
最终我们得到一个这样的长度为64的列表:(41, -8, -6, -5, 13, 11, -1, 1, 2, -2, -3, -5, 1, 1, -5, 1, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 1, 1, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0)。接下来的操作我们都以这个列表为例。 需要注意的是,存储量化表时我们也要将量化表对应地进行zigzag扫描,按照这中形式存储才能让图片查看器解码出正确的图片(我一开始便是在这个细节上花费了很多调试的时间),可见写入标识符的代码。 now_block_zz = block2zz(now_block_qut) # zigzag扫描 # zigzag扫描 # block: 当前8*8块的数据 def block2zz(block): re = np.empty(64, np.int16) # 当前在block的位置 pos = np.array([0, 0]) # 定义四个扫描方向 R = np.array([0, 1]) LD = np.array([1, -1]) D = np.array([1, 0]) RU = np.array([-1, 1]) for i in range(0, 64): re[i] = block[pos[0], pos[1]] if(((pos[0] == 0) or (pos[0] == 7)) and (pos[1] % 2 == 0)): pos = pos + R elif(((pos[1] == 0) or (pos[1] == 7)) and (pos[0] % 2 == 1)): pos = pos + D elif((pos[0] + pos[1]) % 2 == 0): pos = pos + RU else: pos = pos + LD return re 6. 差分编码(直流分量)直流分量的数值往往较大,同时相邻8*8方块的直流分量往往又十分相近,因此采用差分编码能够更大程度地节约空间。所谓的差分编码便是存储当前方块与上一方块直流分量的差值,而第一个方块则存储本身。需要注意的是,对于Y Cb Cr三个分量是对应地进行差分编码,即各个分量对应相减。在第8部分将介绍如何对直流分量now_block_dc进行编码与存储。 last_block_ydc = 0 last_block_cbdc = 0 last_block_crdc = 0 now_block_dc = now_block_zz[0] - last_block_ydc # 直流分量差分形式记录 last_block_ydc = now_block_zz[0] # 记录本次量 now_block_dc = now_block_zz[0] - last_block_cbdc last_block_cbdc = now_block_zz[0] now_block_dc = now_block_zz[0] - last_block_crdc last_block_crdc = now_block_zz[0] 7. 0的行程编码(交流分量)经过zigzag扫描后,不少0集中在了一起,交流分量的列表为:(-8, -6, -5, 13, 11, -1, 1, 2, -2, -3, -5, 1, 1, -5, 1, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 1, 1, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0)。 0的行程编码每次存储两个数,第二个数为一个非0数,第一个数则是这个非0的数前面有多少个0。最后以两个0作为结束标识符(尤其注意,当输入数据不以0结尾时,不需要两个0作为结束标识符,这个bug让我找到好久,见下面代码23行)。如上面这个列表的经过行程编码后得到:(0, -8), (0, -6), (0, -5), (0, 13), (0, 11), (0, -1), (0, 1), (0, 2), (0, -2), (0, -3), (0, -5), (0, 1), (0, 1), (0, -5), (0, 1), (3, -1), (6, 1), (0, 1), (0, -1), (27, 1), (0, 0)。这个数据长度为42,与原来的63相比有一点的减少。当然,这里选择的是一个特殊的数据,实际的数据会有更多的0,甚至全是0,编码后的大小可以更小。 也许你发现了上述数据中(27, 1)标红了,这是因为在第8部分的编码中,第一个数存储时是一个4bit的数,因此范围为0~15,这里显然超过了,因此我们需要将它拆分为(15, 0), (11, 1),其中(15, 0)代表16个0,(11, 1)代表11个0后面有个1。 now_block_ac = RLE(now_block_zz[1:]) # 0的行程编码 # AClist: 要编码的交流数据 def RLE(AClist: np.ndarray) -> np.ndarray: re = [] cnt = 0 for i in range(0, 63): if(AClist[i] == 0 and cnt != 15): cnt += 1 else: re.append(cnt) re.append(AClist[i]) cnt = 0 # 删除末尾的所有[15 0] while(re[-1] == 0): re.pop() re.pop() if(len(re) == 0): break # 在结尾添加两个0作为结束标记 if(AClist[-1] == 0): re.extend([0, 0]) return np.array(re, np.int16) 8. JPEG特殊二进制编码经过上述铺垫后,此部分将真正介绍经过编码后的直流分量和交流分量都是如何以数据流形式写入文件的。 在JPEG编码中,有如下的二进制编码形式: 数值 bit长度 实际保存值 0 0 无 -1,1 1 0,1 -3,-2,2,3 2 00,01,10,11 -7,-6,-5,-4,4,5,6,7 3 000,001,010,011,100,101,110,111 -15,..,-8,8,..,15 4 0000,..,0111,1000,..,1111 -31,..,-16,16,..,31 5 00000,..,01111,10000,..,11111 -63,..,-32,32,..,63 6 ... -127,..,-64,64,..,127 7 ... -255,..,-128,128,..,255 8 ... -511,..,-256,256,..,511 9 ... -1023,..,-512,512,..,1023 10 ... -2047,..,-1024,1024,..,2047 11 ...对于一个要存储的数,我们需要按照上述形式得到需要存储的bit长度和实际保存的二进制数值。观察其规律不难发现,正数保存值就是它的实际二进制,bit长度也为其实际的bit长度。而对应的负数也是相同的bit长度并且二进制数值为按位取非后的数值。0则不需要存储。 # 特殊的二进制编码格式 # num: 待编码的数字 def tobin(num): s = "" if(num > 0): while(num != 0): s += '0' if(num % 2 == 0) else '1' num = int(num / 2) s = s[::-1] # 反向 elif(num < 0): num = -num while(num != 0): s += '1' if(num % 2 == 0) else '0' num = int(num / 2) s = s[::-1] return s对于直流分量,假设差分编码后的数值为-41,按照上述操作我们可以得到它的bit长度为6,保存的二进制数据流为010110。对于数据6,我们需要采用范式哈夫曼编码保存其二进制数据流,此部分将在第9部分介绍,我们先假设6存储的二进制数据流为100,那么此8*8方块的某个颜色分量的直流量存储为100010110。 在直流分量的二进制数据流写入文件后,接下来对8*8方块的这个颜色分量的交流量进行编码。行程编码后得到的数值为:(0, -8), (0, -6), (0, -5), (0, 13), (0, 11), (0, -1), (0, 1), (0, 2), (0, -2), (0, -3), (0, -5), (0, 1), (0, 1), (0, -5), (0, 1), (3, -1), (6, 1), (0, 1), (0, -1),(15, 0), (11, 1) , (0, 0)。 首先存储(0, -8),对于第二数,采取相同的操作,可得4bit和0111,但与直流分量不同的是,我们要对0x04进行范式哈夫曼编码,其中高四位为(0, -8)的第一个数,第四位为第二个数存储的bit长度。假设0x04的范式哈夫曼编码后存储为1011,那么(0, -8)存储为10110111。接下来对(0, -6)等进行相同的操作,得到的数据流依次写入文件。 再举个例子(6, 1),其中1存储为1,1bit,因此对0x61进行范式哈夫曼编码,假设为1111011,那么(6, 1)存储为11110111。(15, 0)则仅存储0xf0的范式哈夫曼编码数值。 按照上述过程写完一个颜色分量(假设为Y)的数据后,接下来写这个8*8方块的Cb颜色分量的数据,再接着写Cr分量的数据。采用相同的方式,从左到右、从上到下写入每个8*8方块数据后,写入EOI标识(0xffd9),作为图像结束。 注意:写入数据过程中需要检测是否写入为0xff,为防止标志冲突,我们需要再后面补上0x00。 s = write_num(s, -1, now_block_dc, DC0) # 根据编码方式写入直流数据 for l in range(0, len(now_block_ac), 2): # 写入交流数据 s = write_num(s, now_block_ac[l], now_block_ac[l+1], AC0) while(len(s) >= 8): # 记录数据太长会导致爆内存 num = int(s[0:8], 2) # 运行速度变慢 fp.write(pack(">B", num)) if(num == 0xff): # 为防止标志冲突 fp.write(pack(">B", 0)) # 数据中出现0xff需要在后面补两个0x00 s = s[8:len(s)] # 根据编码方式写入数据 # s: 未写入文件的二进制数据 # n: 数据前面0的个数(-1代表DC) # num: 待写入的数据 # tbl: 范式哈夫曼编码字典 def write_num(s, n, num, tbl): bit = 0 tnum = num while(tnum != 0): bit += 1 tnum = int(tnum / 2) if(n == -1): # DC tnum = bit if(tnum > 11): print("Write DC data Error") exit() else: # AC if((n > 15) or (bit > 11) or (((n != 0) and (n != 15)) and (bit == 0))): print("Write AC data Error") exit() tnum = n * 10 + bit + (0 if(n != 15) else 1) # 范式哈夫曼编码记录0的个数(AC)以及num的bit长度 s += tbl[tnum].str_code # 特殊形式的数据存储num s += tobin(num) return s 9. 范式哈夫曼编码在本文中介绍的范式哈夫曼编码共有4个编码表,分别用于亮度直流分量、色度直流分量、亮度交流分量、色度交流分量。 # 亮度直流量范式哈夫曼编码表 std_huffman_DC0 = np.array( [0, 0, 7, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 4, 5, 3, 2, 6, 1, 0, 7, 8, 9, 10, 11], np.uint8 ) ... # 换算出哈夫曼字典 DC0 = DHT2tbl(std_huffman_DC0) # 亮度直流分量 DC1 = DHT2tbl(std_huffman_DC1) # 色度直流分量 AC0 = DHT2tbl(std_huffman_AC0) # 亮度交流分量 AC1 = DHT2tbl(std_huffman_AC1) # 色度交流分量如上代码中std_huffman_DC0等便是实际保存在标识符中的数值,具体可见标识符介绍中的代码。这串数字中前16个数字(0, 0, 7, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0)代表编码后长度为1-16bit都有多少个数,而后面跟着的12个数正好为前16个数字之和。std_huffman_DC0描述的实际上便是下图:
现在我们只知道每个原始数据编码后的数据长度,而并不知道其实际是多少。 范式哈夫曼编码有一套自己的规则:1. 最小编码长度的第一个数的编码为0;2. 相同编码长度的编码是连续的;3. 下一个编码长度(假设为j) 的第一个数的编码a取决于上一个编码长度(假设为i)的最后一个数的编码b,即a=(b+1) other.symbol # 将范式哈夫曼编码表转换为哈夫曼字典 # data: 定义的范式哈夫曼编码表 def DHT2tbl(data): numbers = data[0:16] # 1~16bit长度的编码对应的个数 symbols = data[16:len(data)] # 原数据 if(sum(numbers) != len(symbols)): # 判断是否为正确的范式哈夫曼编码表 print("Wrong DHT!") exit() code = 0 SC = [] # 记录字典的列表 for n_bit in range(1, 17): # 按范式哈夫曼编码规则换算出字典 for symbol in symbols[sum(numbers[0:n_bit-1]):sum(numbers[0:n_bit])]: SC.append(Sym_Code(symbol, code, n_bit)) code += 1 code |



{kind=link}
{kind=link}
【本文地址】