| 使用NLTK进行英文文本的分词和统计词频 | 您所在的位置:网站首页 › 10个英语词性 › 使用NLTK进行英文文本的分词和统计词频 |
使用NLTK进行英文文本的分词和统计词频
|
目录
分词分词后词干提取或词形归一Stemming词干提取Lemmatization 词形归一标注词性
去停用词统计词频生成英文词云
分词
先将文档读入,然后全部变为小写 txt=open("English.txt","r").read() txt = txt.lower()#将英文全部变为小写中文分词需要专门的方法: 把不影响词性的inflection的词缀砍掉 例如 :walking 砍掉ing=>walk 有三种方式, LancasterStemmer()和PorterStemmer(),SnowballStemmer(),比较常用的是 Porter 提取算法。 Lancaster算法 from nltk.stem.lancaster import LancasterStemmer lancaster_stemmer=LancasterStemmer() print(lancaster_stemmer.stem('maximum')) print(lancaster_stemmer.stem('multiply')) Porter提取算法 from nltk.stem.poter import PorterStemmer porter_stemmer = porterStemmer() print(porter_stemmer.stem('maximum')) print(porter_stemmer.stem('multiply')) Snowball提取算法 from nltk.stem import SnowballStemmer snowball_stemmer=SnowballStemmer("english") print(snowball_stemmer.stem('maximum')) print(snowball_stemmer.stem('multiply')) Lemmatization 词形归一把单词的各种形式都归一, 例如:went 归一 => go are 归一 => be 词形还原默认单词是名词,所以在进行归一之前,要求手动注明词性,否则可能会有问题。因此一般先要分词、词性标注,再词性还原。 from nltk.stem import WordNetLemmatizer wnl = WordNetLemmatizer() print(wnl.lemmatize('men', 'n')) print(wnl.lemmatize('ate', 'v')) print(wnl.lemmatize('saddest', 'a')) 标注词性使用nltk.pos_tag可以输出对应词的词性 import nltk text=nltk.word_tokenize('what does the beautiful fox say') print(text) print(nltk.pos_tag(text))输出类似与: ('sentiment', 'NN'), ('analysis', 'NN'), ('challenging', 'VBG'), ('subject', 'JJ'), 去停用词 import nltk from nltk.corpus import stopwords word_list=nltk.word_tokenize('what does the beautiful fox say') #去停用词 filter_words=[word for word in word_list if word not in stopwords.words('english')] print(filter_words)文本处理流程: 去除停用词后可以进行统计词频 使用FreqDist(tokens)统计词频: freq_dist = nltk.FreqDist(filter_words) for k,v in freq_dist.items(): print(str(k)+':'+str(v) # 把最常见的50个单词拿出来 standard_freq_vector = freq_dist.most_common(50) print(standard_freq_vector) 生成英文词云清除停用词之后,生成词云 from wordcloud import WordCloud import matplotlib.pyplot as plt wordcloud = WordCloud( background_color="white", #设置背景为白色,默认为黑色 width=1500, #设置图片的宽度 height=960, #设置图片的高度 margin=10 #设置图片的边缘 ).generate(str(filter_words)) #清除停用词后生成词云 # 绘制图片 plt.imshow(wordcloud) # 消除坐标轴 plt.axis("off") # 展示图片 plt.show() # 保存图片 wordcloud.to_file('my_test2.png') |
 英文分词就可以直接使用word_tokenize()进行分词
英文分词就可以直接使用word_tokenize()进行分词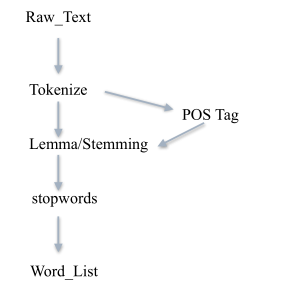
【本文地址】
公司简介
联系我们
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |