六大全局唯一ID生成算法策略,效率对比。 总有一款是你的菜 |
您所在的位置:网站首页 › 雪花算法生成的id可以排序吗 › 六大全局唯一ID生成算法策略,效率对比。 总有一款是你的菜 |
六大全局唯一ID生成算法策略,效率对比。 总有一款是你的菜
|
前言
ID在程序设计中,无处不在,至关重要。 分布式锁中,我们会用唯一ID宣誓锁的归属。数据库中用主键ID记录每一行并绑定Data。分库分表的系统中,用ID生成,来保证全局唯一等等自己做下总结。 分布式ID的要求 UNIQ 唯一性:ID,ID 要的就是唯一HP 高性能:生成ID的服务,不能成为瓶颈HA 高可用:保证高可用,如果ID是订单ID,突然ID服务宕机,影响全局交易就不好了趋势:递增还是随机,看场景需要知道了基本要求,下面开始介绍各种策略,并分析一下他们的是否达到了这些要求。 1:UUIDuuid例子:f1c09159-97c3-4ac1-8cb1-2d820a8eeb05 经过计算,每秒生成10亿个UUID,100年不间断,有50%的可能产生一个冲突 UUID的碰撞只存在理论上的可能,现实中可以忽略不计。 我们来看下性能:单线程1秒 百万量级。 唯一性:满足 高性能:满足 高可用:满足 趋势:随机 2:Redis incrredis作为单线程的nosql系统。 使用incr就高性能的生成唯一的单调递增ID。 下面说一说大名鼎鼎的Twitter的雪花算法。 算法结果是一个长整型 Long 大佬们惯用的 位存储转基本类型。 基本原理如下图,一眼就描述清楚了。 每毫秒1024个业务,每个业务能容纳4096个ID。 生成效率,30W/s 唯一性:满足 高性能:满足 高可用:满足 趋势:趋势递增 当然这是一种思路 在企业开发中,可以在企业开发中借鉴一下 比如我们生成订单号就是类似的思路:630558772926921027。 出于保密,我就不具体解读了。 雪花就没毛病了嘛?大部分场景其实是的。不过有两个问题,还是需要考虑: 每毫秒4096,还是可能成为瓶颈的雪花ID是长整型,直接用来做SQL主键,也是比较浪费空间的。依赖机器时间,可能会有实现回拨 4: AUTO_INCREMENT数据库自增
唯一性:满足 高性能:IO瓶颈哦 高可用:单机问题 趋势:单调递增 纯粹个人玩玩可以。线上还要针对性能和可用性进行优化,所以就引入集群模式。 5:数据库集群模式要数据库的高性能高可用,肯定要考虑集群。 有了多态机器,就需要每个机器单独负责生成号码。 我们使用 初始值offset 加 步长increment 来看配置 MySQL_1 配置: set @@auto_increment_offset = 1; -- 起始值 set @@auto_increment_increment = 3; -- 步长 MySQL_2 配置: set @@auto_increment_offset = 2; -- 起始值 set @@auto_increment_increment = 3; -- 步长 MySQL_3 配置: set @@auto_increment_offset = 3; -- 起始值 set @@auto_increment_increment = 3; -- 步长 完美解决。 Mysql1生成:1,4,7,10…… Mysql2生成:2,5,8,11…… Mysql3生成:3,6,9,12……但是发现问题来了。 这里的步长就等于机器的数量。 未来如果要扩容就非常困难了。。。 唯一性:满足 高性能:满足 高可用:集群高可用 趋势:趋势递增 缺点: 无法扩容。定好步长和初始值后,就凉了。再次扩容,一般需要停滞服务,并产生号段空洞。成本高为了解决性能瓶颈和处理扩容问题 6:Segment 号段模式集群模式,每个ID和数据库交互一次。 而号段模式,借鉴单次步长step,就是一次SQL交互取出的ID代表了一个号段。 如id=1,step=1000. 代表数字[1,1000]. 获去1个ID的读写数据库的频率,从1减小到了1/step。 先看例子,我直接使用美团的id生成器Leaf来说明。 先上表。 DB数据 CREATE DATABASE leaf CREATE TABLE `leaf_alloc` ( `biz_tag` varchar(128) NOT NULL DEFAULT '', -- your biz unique name `max_id` bigint(20) NOT NULL DEFAULT '1', // 当前被使用的最大ID `step` int(11) NOT NULL, // 单步步长 `description` varchar(256) DEFAULT NULL, `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`biz_tag`) ) ENGINE=InnoDB; insert into leaf_alloc(biz_tag, max_id, step, description) values('leaf-segment-test', 1, 2000, 'Test leaf Segment Mode Get Id')
当取到309时 再取几个 可以看到这里提前开辟了号段。 // 关键的判断: 剩余 < 总数的90%(发了10%,就会去开辟新号段)。 segment.getIdle() |
 因为是全局唯一,所以我们常常用来做分布式锁的唯一标识,保证获得锁和释放锁的是同一个人。
因为是全局唯一,所以我们常常用来做分布式锁的唯一标识,保证获得锁和释放锁的是同一个人。 唯一性:基本满足(依赖可用性) 高性能:基本满足 高可用:不满足,存于内存,要考虑持久化和容灾。集群模式下重连还要进行主从复制,等待时间比较长。 趋势:单调递增
唯一性:基本满足(依赖可用性) 高性能:基本满足 高可用:不满足,存于内存,要考虑持久化和容灾。集群模式下重连还要进行主从复制,等待时间比较长。 趋势:单调递增

 直接使用DB的AUTO_INCREMENT。就能得到递增的ID。
直接使用DB的AUTO_INCREMENT。就能得到递增的ID。 使用leaf-segment-test2 生效ID的效果
使用leaf-segment-test2 生效ID的效果  可以看到 max_id = 201 而 step=100时。 此时内存中(segment对象)存储了[101,200] 共100个ID。 进行自增的发号
可以看到 max_id = 201 而 step=100时。 此时内存中(segment对象)存储了[101,200] 共100个ID。 进行自增的发号 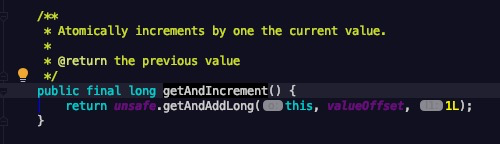 这样每100个号码才IO一次。 瓶颈解决
这样每100个号码才IO一次。 瓶颈解决  同时Leaf为了防止IO获取号段时,导致的服务不可用,采用提前加载的方式处理。称为双buffer优化
同时Leaf为了防止IO获取号段时,导致的服务不可用,采用提前加载的方式处理。称为双buffer优化 
 db效果
db效果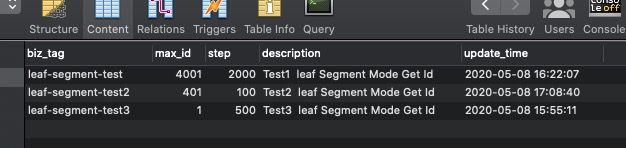
 db效果
db效果 
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |