对于概率论数字特征的理解 |
您所在的位置:网站首页 › 随机抽数字的网站有哪些 › 对于概率论数字特征的理解 |
对于概率论数字特征的理解
|
数字特征概述
随机变量 常见数字特征
数学期望均值方差标准差协方差相关系数协方差矩阵 参考
数字特征概述
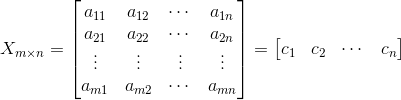
在我们学习概率论的时候,很多时候我们不能深刻理解概率论中的数字特征所具有的含义,本文章尝试去帮助读者理解一些术语、概念。 什么是数字特征?要回答这个问题,先得弄清楚什么是特征。特征是一个客体或一组客体特性的抽象结果。特征是用来描述概念的。任一客体或一组客体都具有众多特性,人们根据客体所共有的特性抽象出某一概念,该概念便成为了特征。而数字特征是对于数字的一种抽象方式,不同的抽象方式表现数字不同方面的数字特征(如,均值表现平均水平,方差表示离散程度)。从信息的角度来说,特征化(抽象)是压缩信息的一种方式。 为何会有数字特征?特征化是人们压缩数据的一种方式,它能够反映一些群体的某方面的特点。举个简单的例子,校长去某个班调查学生的学习水平,他不太可能去查看询问每个人的成绩(那样子是十分耗时的一件事情)。所以我们将班级的成绩信息进行压缩,压缩成均值,众数,标准差等,以此来为校长提供其所关心的平均水平,成绩差异程度等。 在数字特征的构造中,统一量纲 是一个十分重要的原则,下面的各个的数字特征中都会有所体现。下图说明,各个数字特征之间可以进行的运算 图1:(未涉及协方差,相关系数) 一些 不同随机变量的同一数字特征是可比较的。一些 同一随机变量的不同数字特征是可比较的。 区分概率论与统计学(参考): 【知乎】概率论与统计学的关系是什么? 随机变量要想理解数字特征,弄清楚随机变量这一个概念是十分重要的。 常见数字特征本小节主要介绍概率论中常见的一些数字特征,并且说明其直观的物理意义。这里只讨论离散型随机变量的数字特征。 数学期望(均值)在概率论和统计学中,数学期望(mean)(或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和。是最基本的数学特征之一。它反映随机变量平均取值的大小。其公式如下: E(X)=∑k=1∞xk×pk xk :表示观察到随机变量 X 的样本的值。 pk : 表示 xk 发生的概率。 数学期望反映的是平均水平。通过它,我们能够了解一个群体的平均水平(比如说,一个班平均成绩80)。但另外一个方面,它所包含的信息也是十分有限的,首先是个体信息被压缩了,其次如果单纯看期望的话,是看不出样本的数量。(平均成绩为80,在1人班和100人班的含义是不一样的) 通过这个问题想说明,在刻画群体特征的时候,多个数字特征配合才能达到效果。(上面的例子:可以是 期望 + 数量) 方差(variance)是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。在许多实际问题中,研究方差即偏离程度有着重要意义。 方差( D(X) 或 Var(X) )计算公式如下: D(X)=Var(X)=E{[X−E(X)]2} X :表示随机变量。 E(X) : 表示X的期望。 D(X) : 是 每个样本值与全体样本值的平均数之差的 平方值的平均数。公式逐步解释: [X−E(X)] —> [X−E(X)]2 —> E{[X−E(X)]2} [X−E(X)] 是计算随机变量中各个值与期望的距离(反映的是以 E(X) 为基准计算的偏差)。但是只是将偏差进行求和,可能导致结果为0的情况(会产生离散程度较高,评价却为0的情况)。 平方 [X−E(X)]2 可避免上述情况发生,但问题依据存在,不同的随机变量(比如,X,Y)之间在此级别是无法进行比较的,因为X,Y的数量空间是不同的(X可能有3个值,Y可能有1000个值),进而导致不具有可比性。 E{[X−E(X)]2} 则是将数量空间进行了统一,使得不同随机变量的方差具有了可比性。 ps : 方差的性质这里就不介绍了,可查看概率书籍。 标准差标准差也是用于衡量一组数据的离散程度的。公式如下,可以看出标准差( σ(X) 表示 )于随机变量 X 处于同一量纲下,这为X以及 σ(X) 在同一公式中计算提供了很好的支持。 σ(X)=D(X)−−−−−√ D(X) : 表示随机变量X的方差。 方差与标准差有何区别呢?(下面两个例子来自知乎: 有了方差为什么需要标准差?) 标准差和均值的量纲(单位)是一致的,在描述一个波动范围时标准差比方差更方便。比如一个班男生的平均身高是170cm,标准差是10cm,那么方差就是100cm^2。可以进行的比较简便的描述是本班男生身高分布是170±10cm,方差就无法做到这点。 再举个例子,从正态分布中抽出的一个样本落在[μ-3σ, μ+3σ]这个范围内的概率是99.7%,也可以称为“正负3个标准差”。如果没有标准差这个概念,我们使用方差来描述这个范围就略微绕了一点。万一这个分布是有实际背景的,这个范围描述还要加上一个单位,这时候为了方便,人们就自然而然地将这个量单独提取出来了。 协方差前面一直在探讨单个随机变量(1维),但是事实上当我们考察一个群体的时候,往往事物的属性是多方面的(多维),这里只考察2维情况,形式如: (X,Y) 。 (X,Y) 的意思这类事物具有两个方面的属性,更进一步来说,一个样本有X,Y两方面的值,体现在数据库中,有两列(X列,Y列)。当X,Y这两个属性出现在同一类事物中的时候,我们很自然想到X,Y之间有某种关系,但是如何来刻画这种关系呢,这就是本节想要介绍的。 (X,Y) 是2维的,只考虑1维会无法从整体把握问题。而如果进行关联分析,有时候却需要对维度拆分来进行研究,这就引出了下面的协方差公式: Cov(X,Y)=E{[X−E(X)][Y−E(Y)]} Cov(X,Y) : 表示随机变量X,Y的协方差。(2维因素) E(X),E(Y) : 分别表示随机变量X,Y的期望。(1维因素) [X−E(X)][Y−E(Y)] 的说明 : [X−E(X)] 与 [Y−E(Y)] 都只考虑了各自随机变量这1维,通过 相乘的方式使得上面两个离差建立起数值关系, [X−E(X)][Y−E(Y)] 是两者共同作用的结果,即和X,Y都有关。又因为X,Y都是随机变量,所以自然 [X−E(X)][Y−E(Y)] 也是 合成的新的随机变量。根据相关性定义可知,如果X,Y独立,那么 [X−E(X)] 与 [Y−E(Y)] 也是独立的,那么 ∵随机变量X,Y相互独立(即,P(X,Y)=P(X)∗P(Y)) ∴Cov(X,Y)=E{[X−E(X)][Y−E(Y)]} =E[X−E(X)]∗E(Y−E(Y)) ∵E[X−E(X)]=0且E(Y−E(Y))=0 ∴X,Y相互独立=>Cov(X,Y)=0 下面解释一下上面的结论的含义( 为何X、Y独立,Cov(X,Y)就为0 ?)。 如果X,Y有关系,那么 关联性会使得某个变量的随机性不再那么随机。即,假如说X是随机的, X的值确定后会限定Y的随机性(将Y限定在某个范围)。这里举个简单的例子,假如学生具有(年龄,年级)两个属性,如果 年龄是17岁,那么 年级范围很可能是在高中范围内。 年龄这个变量影响着年级这个变量。 如果X,Y有关系,从关系传递性角度来说,离差 [X−E(X)] 与 [Y−E(Y)] 也会有一定的关系。 正常情况下随机变量 [X−E(X)] 与 [Y−E(Y)] 会在0水平附近波动,如果上述两个随机变量无关,那么两个随机变量的相乘的方式会在0附近波动(即 Cov(X,Y)=0 );如果X,Y有关,那么 [X−E(X)]∗[Y−E(Y)] 波动范围将会受到影响,不再围绕0。(此处有待进一步解释…) 协方差计算公式 Cov(X,Y)=E{[X−E(X)][Y−E(Y)]} Cov(X,Y)=E(XY)−E(X)E(Y) D(X+Y)=D(X)+D(Y)+2Cov(X,Y) 协方差性质 1。Cov(aX,bY)=abCov(X,Y) 2。Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y) 总结一下, (X,Y) 是2元组,X,Y 共同出现,可能有关系。为度量这种相关性,制定了一个指标(协方差),来刻画X,Y之间关系。( 将相关性映射到协方差)其他关于协方差理解:【知乎】如何通俗易懂地解释「协方差」与「相关系数」的概念? 相关系数前面把比较关键的协方差说了一下,接下来说一下建立在协方差公式基础上的相关系数。简而言之,相关系数是对协方差进行了归一化处理,使其区间处于 [-1,1] 范围内。 下面看看相关系数 ρXY 的计算公式: ρXY=Cov(X,Y)D(X)−−−−−√∗D(Y)−−−−−√ 其中,Cov(X,Y)=E{[X−E(X)][Y−E(Y)]}定理 1。|ρXY|≤1 2。|ρXY|=1的充要条件是,存在常数a,b,使得 P{Y=a+bX}=1 (2。的含义:Y可完全用随机变量X线性表示。X确定,Y唯一确定) 需要注意的一些事情 【线性】 ρXY 表示的是X,Y之间线性相关程度。(不适用于多次方,指数等) ρXY=0 ,我们称X,Y不相关。【独立,相关】 X,Y相互独立=>ρXY=0 【独立,相关】X,Y相互独立 ,则 ρXY=0 ; ρXY=0 ,不能推出X,Y相互独立。( ρXY=0 只能说明非”线性相关”,但X,Y可能是”非线性”相关)为何 ρXY 反映的是线性相关性呢? 这仍旧与前面的协方差相关,为了进一步探索,我们暂且先做出一个简单的假设:X,Y完全线性相关,那么接下来看看会发生什么神奇的事情呢? 设:Y=a∗X+b,a、b都不为0 将上式带入Cov(X,Y)得: 分子:Cov(X,Y)=E(XY)−E(X)E(Y) =E[X∗(a∗X+b)]−E(X)E(a∗X+b) =aD(X) 另一方面,分母:D(X)−−−−−√∗D(Y)−−−−−√ =D(X)−−−−−√∗D(a∗X+b)−−−−−−−−−−√ =|a|D(X) 所以在线性相关的前提下,导致了相关系数只与a的符号相关。再接下来,让我们放开那个非常强的假设(完全线性相关在现实生活中几乎不太可能存在,总会有些干扰的),去掉“完全”这个假设,留下“线性”这个假设。这里只是定性的分析下,定量的证明请参考数学书。 分母这里认为是正的,那么这里先只考虑分子的正负。 假如X,Y线性相关,接下来看看会对 Cov(X,Y)=E(XY)−E(X)E(Y) 造成什么影响。 这里我们设X是自由的,那么X确定之后,则限定了Y的自由活动的空间(见前面年龄、年级的例子),即Y不再自由了。造成的后果是 在E(XY)中Y被限制住了,(因为这两个同时出现,构成了新的随机变量) 而在E(Y)中Y没有被限制住。 于是,Cov(X,Y)=E(XY)−E(X)E(Y) Cov(X,Y)=E(X∗a∗X+干扰因子)−E(X)E(a∗X+干扰因子), 假设干扰因子是随机的,此处我们暂且忽略。 于是,Cov(X,Y)=aE(X2)+aE(X)2=aD(X)−−−−−√ 所以,相关系数的正负和正负线性相关性有很大的关联性。因为思想部分已经在协方差部分说了,这里不再赘述。 协方差矩阵前面已经说了协方差的意义,协方差在于探索随机变量之间的关系。协方差矩阵计算的是不同维度之间的协方差。不是样本之间的关联关系。 协方差探索的是随机变量X,Y之间的相关性,是放在同一个样本中来进行的。举一个简单的例子,学生小明(年龄17岁,年级为高2),小红(年龄17岁,年级为高3),小明、小红就是我们所说的样本,而年龄、年级则是随机变量。计算协方差时,考虑的是小明年龄和小明年级之间的关联关系(一个样本自身属性之间的关联关系)。 ps:未考虑小明、小红之间是否有关联关系(样本之间是否有关联关系)。 当样本含有大量维度(随机变量多)的时候,我们就需要使用矩阵来刻画各个维度之间的关联关系。 PS: 个人感觉,协方差矩阵的计算是将整个维度系统中的制约关系,分解为两两之间的关系来进行刻画。 【假设】这其中隐藏了一个假设,在协方差矩阵的世界中认为,所有维度之间的关系都可以简化为两两之间的关系来进行研究。(正如牛顿的万有引力公式) 设谋个矩阵如下: (下面矩阵中每一行代表一个样本,每一列代表一个随机变量。) 则其协方差矩阵为: 关于协方差矩阵,此处不再赘述,可参看: [转]浅谈协方差矩阵 [线性代数] 如何求协方差矩阵 详解协方差与协方差矩阵 参考【知乎】排列组合的理解 |

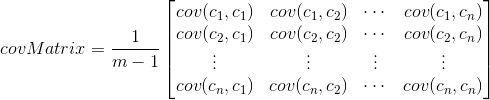
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |