数据结构与算法 |
您所在的位置:网站首页 › 链表逆序存储的流程图 › 数据结构与算法 |
数据结构与算法
|
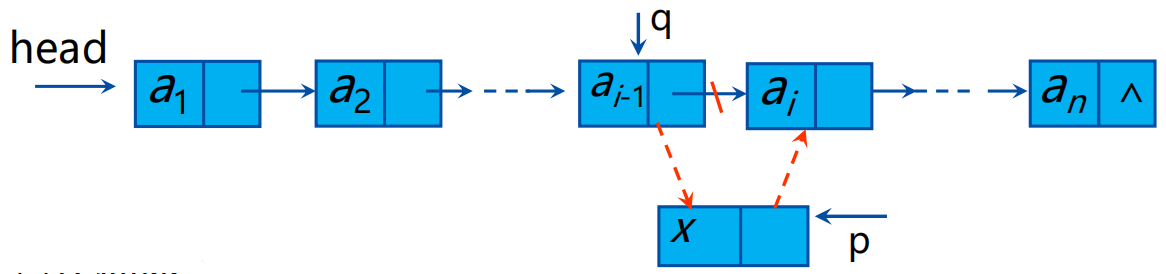
持续分享嵌入式技术,操作系统,算法,c语言/python等,欢迎小友关注支持 上篇文章我们讲述了链表的基本概念及一些查找遍历的方法,本篇我们主要将一下链表的插入删除操作,以及采用堆栈方式如何创建链表。 链表的插入首先我们先看一下链表的插入是如何实现的 在单链表中第i个数据元素之前插入一个数据元素,需要首先在单链表中找到第i-1个结点并由指针pre指示,然后申请一个新的结点并由指针p指示,其数据域的值为x,并让p结点的指针域指向第i个结点,然后修改第i-1个结点的指针使其指向s
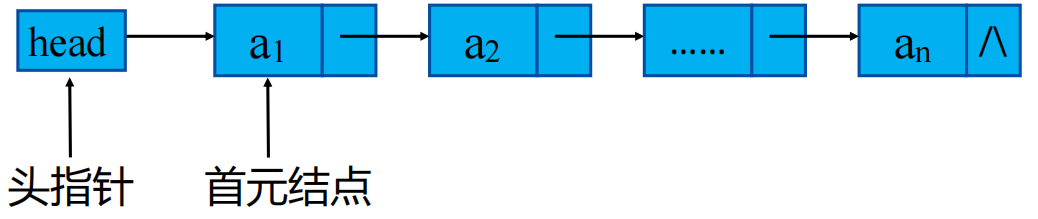
算法描述: p=(node*)malloc(sizeof(node));/*分配空间*/ p->info=x; /*设置新结点*/ p->next=q->next; q->next=p;注意一定是先p->next=q->next; 然后再是q->next=p;两者顺序不能翻了。 为什么这样就留给大家思考了。 链表的插入根据插入位置的不同又分为头插,尾插,中间插入,不同的位置插入方式也有所不同,下面是插入操作的逻辑伪代码便于大家理解 1. 工作指针q=NULL初始化; 2. 查找第i-1个结点并使工作指针q指向该结点; 3. 若查找不成功且i!=1,则插入位置不合理,输出位置不合理; 否则, 生成一个元素值为x的新结点p; 判断插入位置是表头还是非表头 若是表头,则将新结点p插入到表头,p作为新的表头;否则将新结点p插入到结点q之后。 4.返回新的表头。 代码实现: node *insert(node head,datatype x,int i) { node *p,*q; q= findKth(head,i-1); /*查找第i-1个结点*/ if(!q&&i!=1) printf("\n找不到第%d个结点,不能插入%d!",i-1,x); else { p=(node*)malloc(sizeof(node));/*分配空间*/ p->info=x; /*设置新结点*/ if(i==1){ /* 插入的结点作为单链表的第一个结点*/ p->next=head; /*插入(1)*/ head=p; /*插入(2)*/ } else { p->next=q->next; /*插入(1)*/ q->next=p;/*插入(2)*/ } } return head; }注意: 上面在i=1的情况下,我这里表述的是不带头结点链表的插入逻辑 p->next=head; /*插入(1)*/ head=p; /*插入(2)*/带头结点的链表与这个操作一点点区别,我们先来看下带表头和不带表头的区别吧 首先不带表头的链表我们的head结点直接就表示的是头结点,head就表示头结点。而带头结点的链表实在head和头结点之间有追加了一个结点,用head->next来指向头结点
带头结点的链表
不带头结点的链表 上面两个图就是两种的区别。 那么了解了这种区别之后,带头结点的头插入要怎么实现呢,其实很简单 p->next=head->next; /*插入(1)*/ head->next=p; /*插入(2)*/有没有发现头插的方式和中间插入,尾插的方式是一样的呢。 链表的删除单链表中删除第i个结点,则首先要通过计数方式找到第i-1个结点并使pre指向第i-个结点的next,而后删除第i个结点并释放结点空间。
算法描述: p=pre->next; pre->next=p->next; free (p);上面的第二步也可以写成pre->next=pre->next->next;只是看起来不太好看。其结构都是一样的。 上面讲到的插入有头插尾插之分,同样的删除也是有的。我们先来看看它们的逻辑伪代码,便于大家理解 1:工作指针pre=NULL初始化; 2:判断单链表是否为空,返回head,函数结束; 3:如果i=1,直接删除第一个结点,返回head,函数结束; 4:查找第i-1个结点并使工作指针pre指向该结点; 5:若pre不存在或者pre->next不存在,则说明删除位置错误,返回head,函数结束; 否则, 5.1 将被删结点暂存在p中; 5.2 摘链,将结点pre的后继结点从链表上摘下; 5.3 释放被删结点p; 5.4 返回head; 代码实现: linklist deleOne(linklist head,int i) { node *pre=NULL,*p; if (head==NULL) { printf("单链表为空\n"); return head; //单链表为空 } if ( i == 1 ) { /* 若要删除的是表的第一个结点 */ p= head; /*p指向第1个结点*/ head = head->next; /*从链表中删除*/ free(p); /*释放被删除结点 */ return head; } pre= findKth(head,i-1);/*pre是第i个结点的前驱结点*/ if ( pre == NULL || pre->next == NULL ) { printf(“第%d个结点不存在”, i); return head; } else{ p=pre->next; pre->next=p->next; free(p); return head; }同样的上面的代码表示的是不带头结点的操作,如果是带头结点的链表,操作起来相对简单,因为带头结点的链表删除头结点与尾结点,中间结点的方法是一样,不需要上面特别对i-1的分支做特殊处理 带头结点的头部删除操作如下: p=pre->next; pre->next=p->next; free(p);好了,就先分享到这来里了,下一篇分享下链表的创建是如何完成的,用堆栈的方式如何进行。 如果觉得文章对你有帮助,请点赞关注下。如有错误欢迎指正 |


【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |