部署系列 |
您所在的位置:网站首页 › 量化是什么意思啊 › 部署系列 |
部署系列
| 部分资料在原文中:开篇 老潘刚开始接触神经网络量化是2年前那会,用NCNN和TVM在树莓派上部署一个简单的SSD网络。那个时候使用的量化脚本是参考于TensorRT和NCNN的PTQ量化(训练后量化)模式,使用交叉熵的方式对模型进行量化,最终在树莓派3B+上部署一个简单的分类模型(识别剪刀石头布静态手势)。 这是那会的一篇文章,略显稚嫩哈哈: 一步一步解读神经网络编译器TVM(二)——利用TVM完成C++端的部署转眼间过了这么久啦,神经网络量化应用已经完全实现大面积落地了、相比之前成熟多了! 我工作的时候虽然也简单接触过量化,但感觉还远远不够,趁着最近项目需要,重新再学习一下,也打算把重新学习的路线写成一篇系列文,分享给大家。 本篇系列文的主要内容计划从头开始梳理一遍量化的基础知识以及代码实践。因为老潘对TensorRT比较熟悉,会主要以TensorRT的量化方式进行描述以及讲解。不过TensorRT由于是闭源工具,内部的实现看不到,咱们也不能两眼一抹黑。所以也打算参考Pytorch、NCNN、TVM、TFLITE的量化op的现象方式学习和实践一下。 当然这只是学习计划,之后可能也会变动。对于量化我也是学习者,既然要用到这个技术,必须要先理解其内部原理。而且接触了挺长时间量化,感觉这里面学问还是不少。好记性不如烂笔头,写点东西记录下,也希望这系列文章在能够帮助大家的同时,抛砖引玉,一起讨论、共同进步。 参考了以下关于量化的一些优秀文章,不完全统计列了一些,推荐感兴趣的同学阅读: 神经网络量化入门--基本原理从TensorRT与ncnn看卷积网络int8量化模型压缩:模型量化打怪升级之路 - 1 工具篇NCNN Conv量化详解(一)当然在学习途中,也认识了很多在量化领域经验丰富的大佬(田子宸、JermmyXu等等),嗯,这样前进路上也就不孤单了。 OK,废话不多说开始吧。 Why量化我们都知道,训练好的模型的权重一般来说都是FP32也就是单精度浮点型,在深度学习训练和推理的过程中,最常用的精度就是FP32。当然也会有FP64、FP16、BF16、TF32等更多的精度: 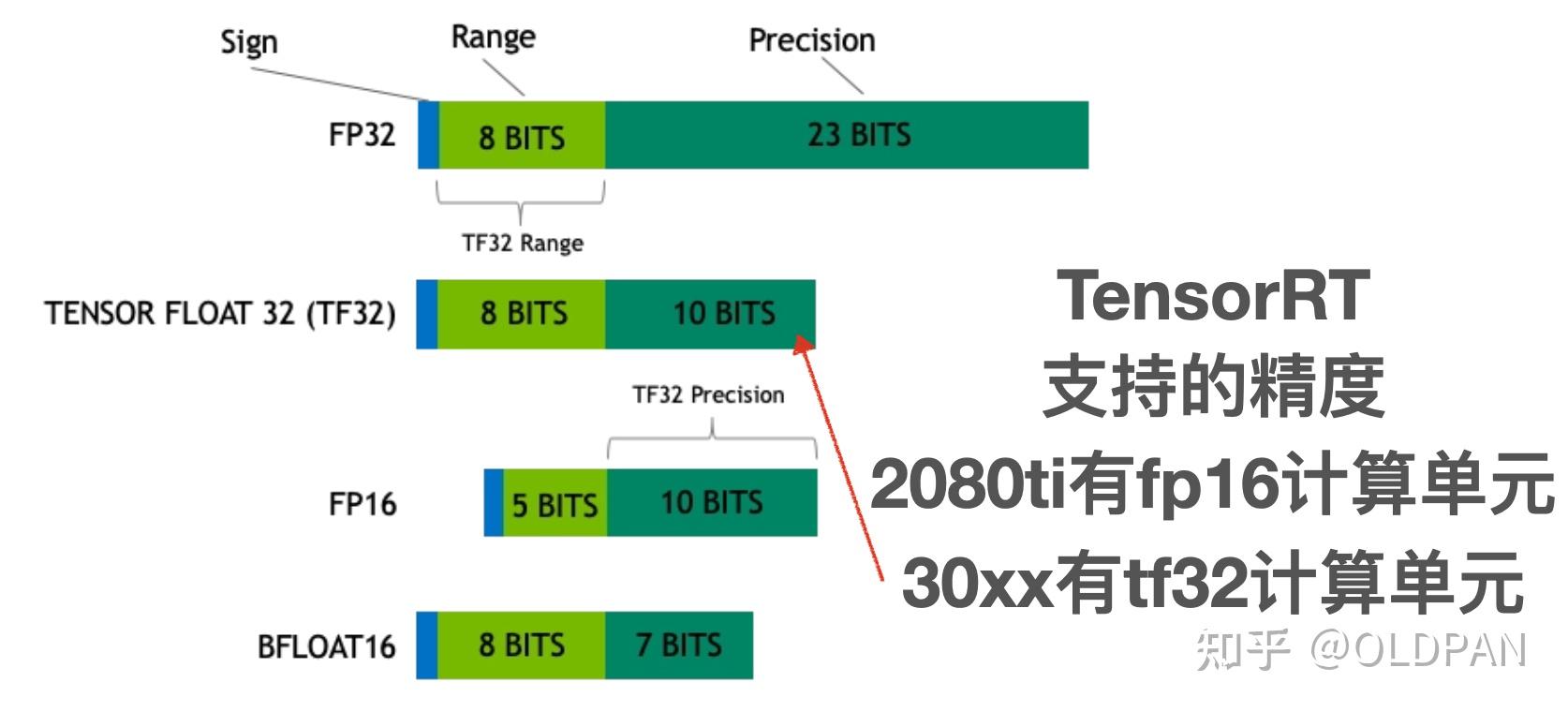 FP32 是单精度浮点数,用8bit 表示指数,23bit 表示小数;FP16半精度浮点数,用5bit 表示指数,10bit 表示小数;BF16是对FP32单精度浮点数截断数据,即用8bit 表示指数,7bit 表示小数。TF32 是一种截短的 Float32 数据格式,将 FP32 中 23 个尾数位截短为 10 bits,而指数位仍为 8 bits,总长度为 19 (=1 + 8 + 10) bits。 对于浮点数来说,指数位表示该精度可达的动态范围,而尾数位表示精度。之前老潘的一篇文章中提到,FP16的普遍精度是~5.96e−8 (6.10e−5) … 65504,而我们模型中的FP32权重有部分数值是1e-10级别。这样从FP32->FP16会导致部分精度丢失,从而模型的精度也会下降一些。 |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |