爬取豆瓣书籍数据(基于R) |
您所在的位置:网站首页 › 豆瓣书籍评分标准 › 爬取豆瓣书籍数据(基于R) |
爬取豆瓣书籍数据(基于R)
|
爬取豆瓣书籍数据(基于R)
爬取豆瓣书籍数据了解网页结构自动收集单个网页数据自动收集多个网页数据字符串切割,以提取需要的信息
爬取豆瓣书籍数据
网络爬虫,就是从网页中获取需要的信息,提取相应的数据。 可以利用R语言爬虫获取网页数据信息,便于统计分析。 常用的从网页中获取信息的包有RCurl,XML,rvest等 。还可以利用RSslenium包或者Rwebdriver包模拟浏览器爬取异步加载等较难爬取的网页信息。 本文便以爬取豆瓣电影数据为例,来描述网络爬虫过程。 爬取网址如下: https://book.douban.com/top250?start=0 了解网页结构所需要的数据概况:
|
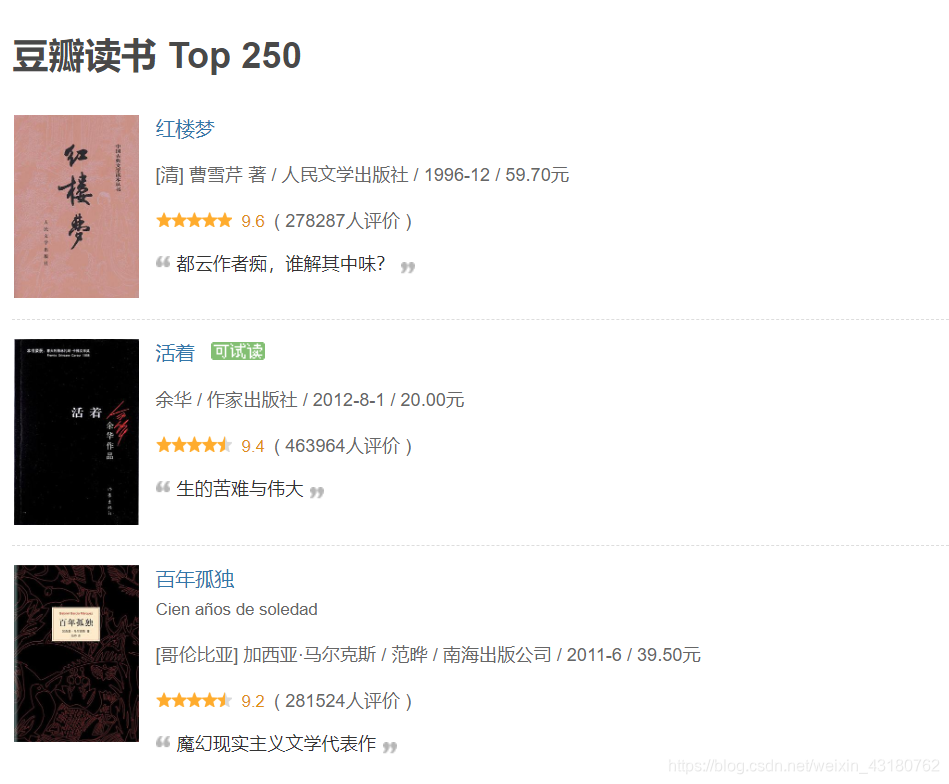 从网页中大概能发现,该网页含有书籍名称,书籍评分,书籍主题,出版时间,价格,作者名字,译者名字等数据信息。 再进入网页源代码界面找规律
从网页中大概能发现,该网页含有书籍名称,书籍评分,书籍主题,出版时间,价格,作者名字,译者名字等数据信息。 再进入网页源代码界面找规律 可以发现有十分一致的规律: 书籍名称:
可以发现有十分一致的规律: 书籍名称:【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |