python网络爬虫设计 |
您所在的位置:网站首页 › 豆瓣top250爬虫 › python网络爬虫设计 |
python网络爬虫设计
|
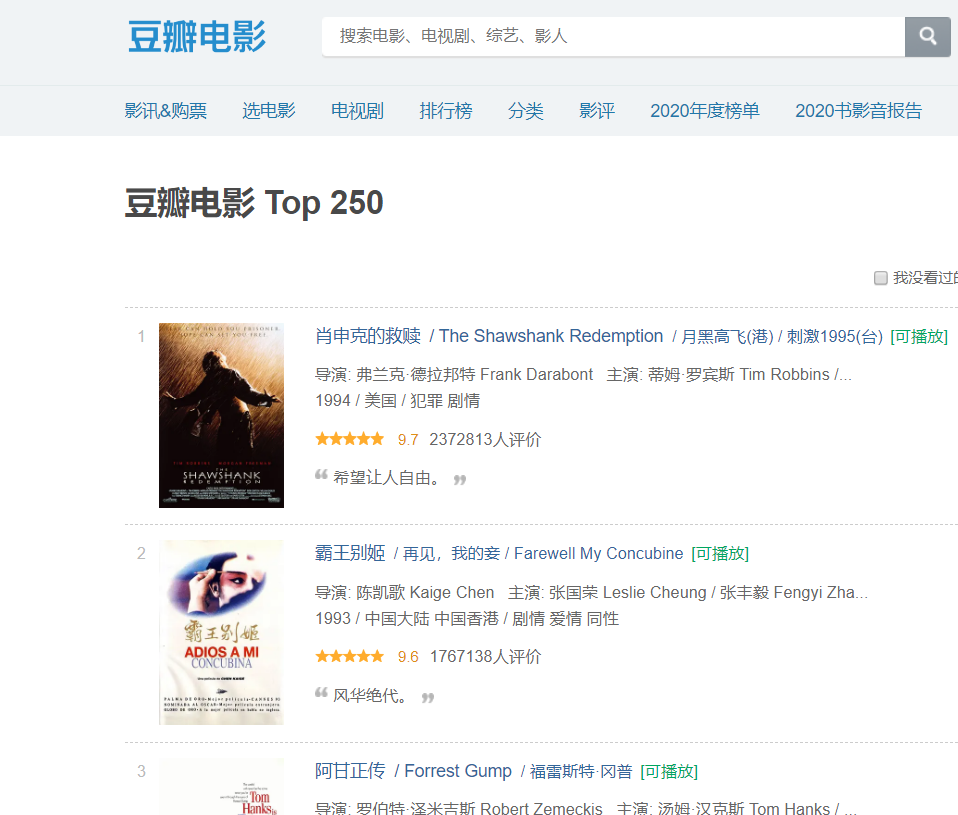
选题的背景为什么要选择此选题?要达到的数据分析的预期目标是什么?随着经济社会的快速发展,电影作为精神文化产品,得到越来越多人的青睐,人们对电影的评价页也参差不齐,在海量的资源中如何尽快找到符合个人品味的电影,成为观众新的问题。基于Python的数据爬虫技术是目前使用最广泛的方法之一,它能够以最快捷的方式展示用户体验数据,帮助观众进行影片选择。豆瓣电影是著名的电影网站,通过豆瓣电影提供的开放接口大规模地获取电影相关数据。主题式网络爬虫设计方案1.主题式网络爬虫名称 豆瓣电影top2502.主题式网络爬虫爬取的内容与数据特征分析用Python编写爬虫程序抓取了Top250排行榜的影片榜单信息,爬取电影的短评、评分、评价数量等数据,并结合Pythorn的多个库(Pandas、Numpy、Matplotib),使用Numpy系统存情和处理大型数据,最终通过图表展示出来。网络信息资源充盈的今天,网络信息的获取工作十分重要,该设计的意义在于为用户观影提供决策支持。3.主题式网络爬虫设计方案概述本次设计通过request库访问,用BeautifulSoup分析网页结构获取数据,将采集到的数据保存在本地 Htmls 页面解析
网络爬虫程序设计 1.数据爬取与采集 1 import time 2 import requests 3 import re 4 from openpyxl import workbook # 写入Excel表所用 5 from bs4 import BeautifulSoup as bs 6 from matplotlib import pyplot as plt 7 import matplotlib 8 import seaborn as sns 9 from scipy.optimize import leastsq 10 import numpy as np 11 import scipy as sp 12 import pandas as pd 13 14 class Top250: 15 def __init__(self): 16 #起始地址 17 self.start_url = 'https://movie.douban.com/top250' 18 #请求头,浏览器模拟 19 self.headers = { 20 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36', 21 } 22 #爬取页数 23 self.page_num = 10 24 25 26 def get_page_url(self): 27 n = 0 #第一页开始,下标0 28 while n |

【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |