语法制导翻译(Syntax |
您所在的位置:网站首页 › 表达式求值的两种方法 › 语法制导翻译(Syntax |
语法制导翻译(Syntax
|
目录语法制导翻译属性文法带有继承属性的SDD带有综合属性的SDDS-属性定义(S-SDD)L-属性定义(L-SDD)SDD的求值顺序将S-SDD转换为SDT将L-SDD转换为SDT在非递归的预测分析过程中进行语义翻译在递归的预测分析过程中进行语义翻译在LR分析过程中进行语义翻译
语法制导翻译
语法制导翻译(Syntax-Directed Translation)是编译原理中的一种重要技术,它主要用于将源语言代码翻译成目标语言代码。这种翻译过程是完全由语法分析器驱动的,也就是说,语法分析器在解析源语言代码的同时,会根据语法规则生成对应的目标语言代码。 语法制导翻译的基本思想是为上下文无关文法(CFG)中的每个符号设置语义属性,并为每个产生式关联语义规则。这些语义属性用于表示语法成分的语义信息,而语义规则则用于计算这些语义属性的值。在构建语法分析树的过程中,利用与产生式相关联的语义规则来计算分析树中各节点的语义属性值。 具体来说,语法制导翻译可以通过两种方式实现:语法制导定义(Syntax-Directed Definitions,SDD)和语法制导翻译方案(Syntax-Directed Translation Scheme,SDT)。 语法制导定义(SDD):SDD是对CFG的推广,它将每个文法符号与一个语义属性集合相关联,并将每个产生式与一组语义规则相关联。这些语义规则用于计算产生式中各文法符号的属性值。然而,SDD并不直接给出语义规则的计算顺序,因此在实际应用中需要配合其他技术来确定计算顺序。 语法制导翻译方案(SDT):SDT是在产生式右部嵌入了程序片段(称为语义动作)的CFG。这些语义动作是在语法分析过程中执行的程序代码,用于生成目标语言代码或执行其他相关任务。与SDD不同,SDT明确给出了语义规则的计算顺序,即按照语法分析树的自底向上顺序进行计算。在语法制导翻译中,属性可以分为综合属性和继承属性两类。 综合属性是从子节点向父节点传递的信息,其值由子节点和父节点共同决定 继承属性则是从父节点向子节点传递的信息,其值由父节点和上下文环境决定。这两种属性在语法制导翻译中起着关键作用,它们使得我们能够在语法分析的过程中逐步积累和传递语义信息。 属性文法属性文法是编译原理中的一种重要技术,它扩展了传统的上下文无关文法,为文法符号(包括终结符和非终结符)关联了额外的“属性”。这些属性通常表示与文法符号相关的语义信息,如类型、值、作用域等。属性文法的目标是在语法分析的过程中同时处理语义,使得语法和语义的处理能够紧密结合。 在属性文法中,属性可以分为两类:综合属性和继承属性。 综合属性:从子结点的属性值计算得出的属性,通常用于自下而上地传递信息。在语法树中,一个结点的综合属性由其子结点或自身的某些属性值确定。 继承属性:从父结点或兄弟结点继承的属性值,用于自上而下地传递信息。在语法树中,一个结点的继承属性由父结点、兄弟结点或自身的某些属性值确定。 属性文法中的每个产生式通常都配备了一组语义规则,这些规则定义了如何计算属性值。语义规则是基于属性的计算和传递的规则,它们描述了语法结构与语义之间的对应关系。 一个没有副作用的SDD有时也称为属性文法 属性文法的规则仅仅通过其它属性值和常量来定义一个属性值
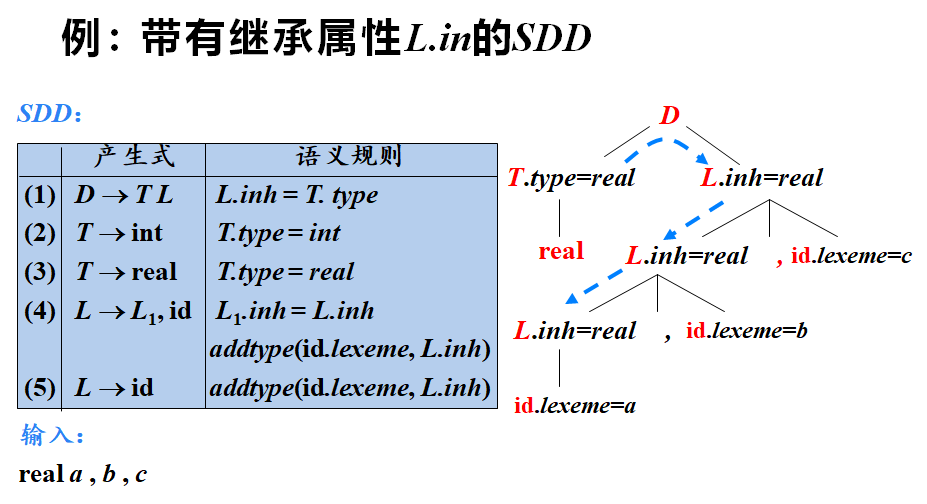
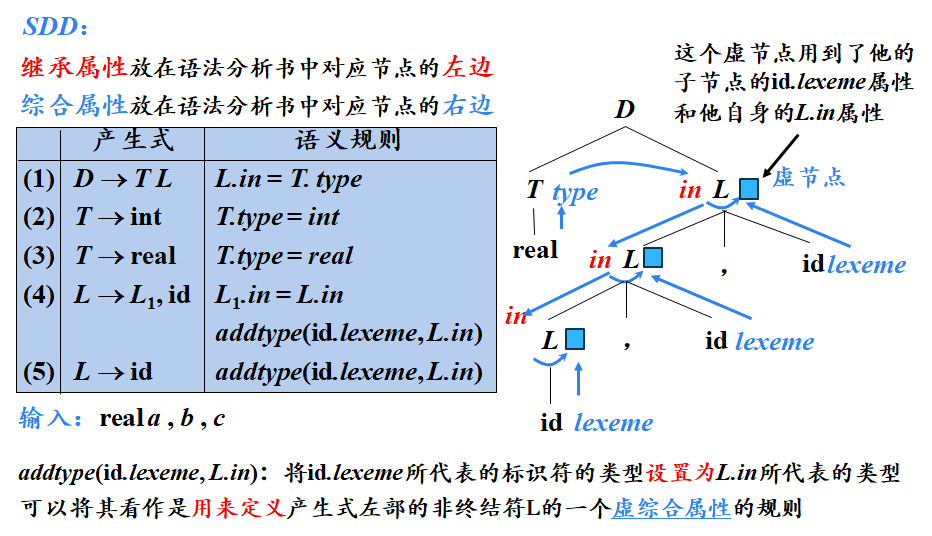
SDD(Syntax-Directed Definition)是语法制导定义,它是编译原理中的一个重要概念,用于描述语法和语义的结合。在SDD中,属性和文法符号相关联,而规则和产生式相关联。属性可以分为综合属性和继承属性。 带有继承属性的SDD,意味着在定义语法结构时,某些属性的值是由其父结点、兄弟结点或结点本身决定的,而不是由其子结点决定的。这些属性被称为继承属性(inherited attribute),因为它们从上级结点“继承”了信息。 具体来说,在分析树结点N上的非终结符A的继承属性,只能通过N的父结点、N的兄弟结点或N本身的属性值来定义。终结符号则没有继承属性,因为它们的属性值是由词法分析器提供的,而不是从上级结点继承的。 在SDD中,继承属性常用于描述一些需要上下文信息的语法结构。例如,在描述变量声明语句的上下文无关文法(CFG)中,可以使用继承属性来表示变量的作用域或类型等信息。这些信息需要从上级结点(如函数或块)继承下来,以便在语法分析过程中正确处理变量声明和引用。 需要注意的是,在使用带有继承属性的SDD时,需要确保属性之间的依赖关系不会形成循环依赖,否则将无法正确地计算属性的值。为了避免这种情况,可以使用一些技术来检测和消除循环依赖,如拓扑排序等。
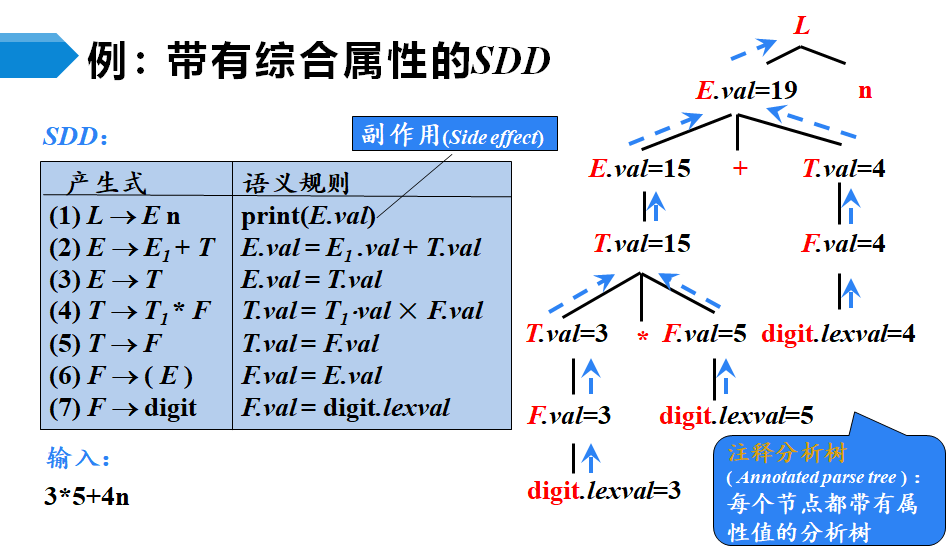
带有综合属性的SDD(Syntax-Directed Definition)是指在语法制导定义中,某些属性的值是由分析树中结点的子结点或结点本身的属性值来决定的。这些属性被称为综合属性(synthesized attribute),因为它们是由下级结点“综合”得出的信息。 在SDD中,综合属性常用于描述语法结构中的聚合或累积信息。例如,在表达式求值的语法制导定义中,可以使用综合属性来表示表达式的计算结果。对于表达式E -> E1 + T,其中E、E1和T都是非终结符,E的val属性(表示表达式的值)就是一个综合属性,因为它是由子结点E1和T的val属性值通过加法运算得出的。 与继承属性不同,综合属性是自下而上传递信息的。在语法分析过程中,当遇到一个产生式的右侧时,会先计算子结点的属性值,然后再根据这些属性值计算产生式左侧非终结符的综合属性值。 需要注意的是,在使用带有综合属性的SDD时,也需要确保属性之间的依赖关系不会形成循环依赖。此外,还需要注意综合属性和继承属性之间的相互作用,以确保语法分析的正确性和效率。
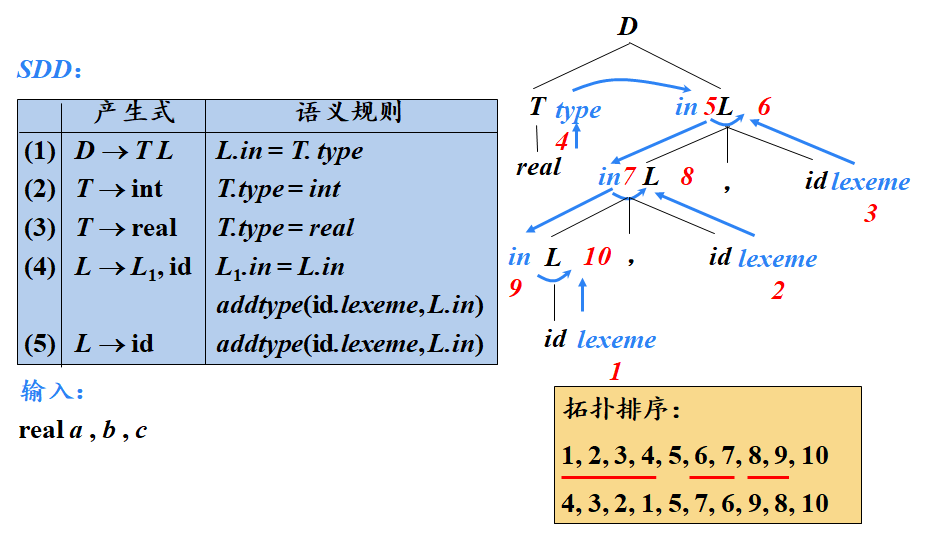
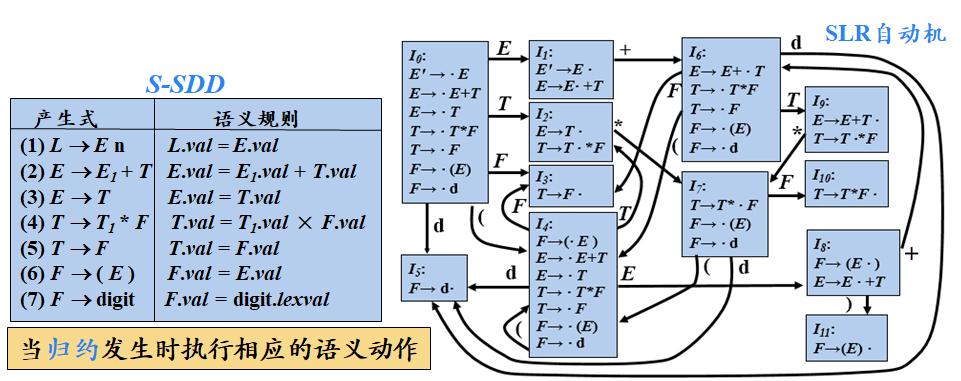
S-属性定义(S-Attributed Definition)是编译原理中的一个概念,与属性文法相关。在属性文法中,属性可以分为综合属性和继承属性。S-属性定义特指仅使用综合属性的语法制导定义(SDD)。 如果一个SDD的每个属性都是综合属性,则它是S属性定义。这意味着所有的属性值都可以通过分析树节点的子节点或节点本身的属性值来计算得出,即自底向上地计算属性值。 S-属性定义的依赖图描述了属性实例之间自底向上的信息流。当进行语法分析(如LR语法分析)时,归约步骤会计算相应节点的综合属性值。 S-属性定义在自底向上的语法分析过程中是可以实现的,因为它只涉及从子节点到父节点的信息流动。 每个S-属性定义也都是L-属性定义,但并非每个L-属性定义都是S-属性定义。L-属性定义允许属性之间的依赖关系从左到右流动,但不能从右到左。在编译器设计中,S-属性定义常用于语法制导的翻译、类型检查等任务,它有助于在语法分析的同时处理语义信息,提高编译器的效率和准确性。 L-属性定义(L-SDD)L-属性定义(L-Attributed Definition)是编译原理中属性文法的一种类型。在属性文法中,属性可以分为综合属性和继承属性,而L-属性定义则涉及这两类属性的特定使用方式。 L-属性定义的核心思想是:在一个产生式所关联的各属性之间,依赖图的边可以从左到右,但不能从右到左。具体来说,如果一个SDD(语法制导定义)的每个属性要么是综合属性,要么是满足特定条件的继承属性,则它是L-属性定义。 这些特定条件包括:对于产生式A → X1X2...Xn及其对应的继承属性Xi.a,该属性只能依赖于: 产生式头A的继承属性; 位于Xi左边的文法符号实例X1, X2, ..., Xi-1的相关继承属性或综合属性; Xi实例本身的相关继承属性或综合属性;但是,在由Xi的全部属性组成的依赖图中不能存在环。 L-属性定义允许在自顶向下的语法分析过程中计算属性值,因为继承属性可以从父节点和左侧兄弟节点获取值。这种属性定义方式有助于在语法分析的同时处理语义信息,提高编译器的效率和准确性。 需要注意的是,每个S-属性定义都是L-属性定义,但并非每个L-属性定义都是S-属性定义。这是因为S-属性定义仅使用综合属性,而L-属性定义则同时使用了综合属性和满足特定条件的继承属性。 SDD的求值顺序SDD(语法制导定义)的求值顺序是指在计算分析树中各结点对应的属性值时应遵循的顺序。这个顺序取决于属性之间的依赖关系。 确定依赖关系:语义规则建立了属性之间的依赖关系。对于给定的输入串,要计算某个结点的属性值,必须首先求出这个属性值所依赖的所有属性值。 依赖图:可以创建一个依赖图来清晰地表示这些依赖关系。依赖图是一个有向图,其中分析树中的每个节点(带有属性)都是图中的一个顶点。如果属性X.a的值依赖于属性Y.b的值,那么依赖图中就存在一条从Y.b到X.a的有向边。 求值顺序:基于依赖图,可以确定属性值的计算顺序。可行的求值顺序是满足下列条件的结点序列:如果依赖图中有一条从结点Ni到Nj的边,那么i必须小于j(即在节点序列中,Ni排在Nj前面)。这样的排序将一个有向图转化为了线性排序,称为图的拓扑排序(topological sort)。 特殊情况: 对于只具有综合属性的SDD,由于属性值只依赖于子节点的属性,因此可以按照任何自底向上的顺序来计算它们。 当SDD同时具有继承属性和综合属性时,确定求值顺序可能会变得复杂。在这种情况下,不一定能找到一个顺序来依次计算各个节点上的所有属性。如果依赖图中不存在环,则至少存在一个拓扑排序,可以使用这个排序来计算属性值。 实际应用:在实际的编译器设计中,为了避免循环依赖和其他潜在的问题,通常会使用一些特殊类型的SDD,如S-属性定义(只包含综合属性)或L-属性定义(属性依赖关系从左到右流动,但不能从右到左),这些类型的SDD能够保证存在一个明确的求值顺序。综上所述,SDD的求值顺序是基于属性之间的依赖关系来确定的,并且通常遵循拓扑排序的原则进行计算。在实际应用中,需要注意选择合适的属性定义方式以确保存在一个有效的求值顺序。 SDD依赖图示例:
将一个S-SDD转换为SDT的方法:将每个语义动作都放在产生式的最后
S-属性定义的SDT实现
如果一个S-SDD的基本文法可以使用LR分析技术,那么它的SDT可以在LR语法分析过程中实现
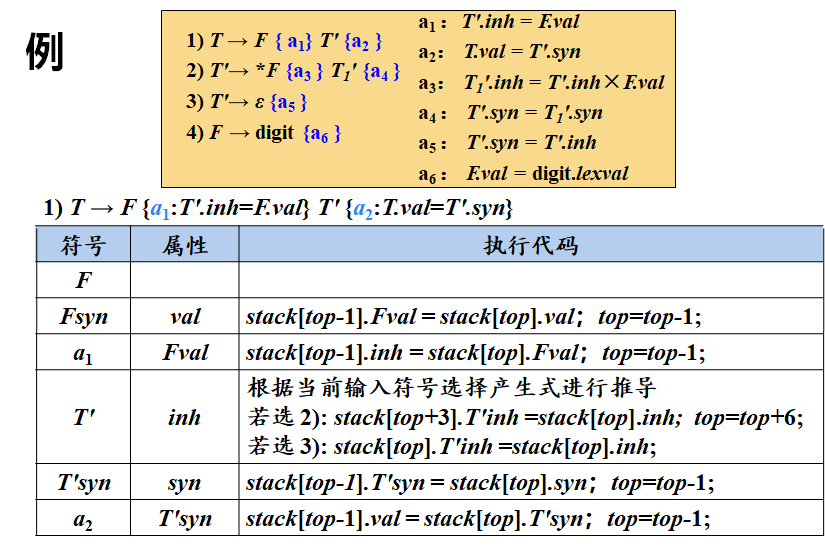
将转换为SDT的规则 将计算L-SDD某个非终结符号A的继承属性的动作插入到产生式右部中紧靠在A的本次出现之前的位置上 将计算一个产生式左部符号的综合属性的动作放置在这个产生式右部的最右端
L-属性定义的SDT实现 如果一个L-SDD的基本文法可以使用LL分析技术,那么它的SDT可以在LL或LR语法分析过程中实现 在非递归的预测分析过程中进行语义翻译 在递归的预测分析过程中进行语义翻译 在LR分析过程中进行语义翻译
在非递归的预测分析(通常指的是预测解析或LR解析)过程中进行语义翻译,通常涉及将语法分析与语义动作相结合。这些语义动作是在解析过程中执行的,用于构建抽象语法树(AST)或进行其他形式的语义处理。 以下是在非递归的预测分析过程中进行语义翻译的一般步骤: 定义语法规则:首先,您需要定义上下文无关文法(CFG)的规则。这些规则描述了语言的语法结构。 增广语法规则:为了进行语义翻译,您需要在CFG规则中嵌入语义动作。这些动作通常是在规则右侧与语法符号一起出现的。例如,您可以使用大括号 {} 来表示语义动作,并将其插入到规则中的适当位置。 构建解析表:基于CFG规则和某种解析算法(如LR(1)算法),您需要构建一个解析表。这个表通常包括一个状态集和一个动作函数,用于指导解析过程。 解析输入:使用解析表和输入字符串,您可以开始解析过程。在每一步中,您都会根据当前状态和输入字符来查找适当的动作。 执行语义动作:当解析过程遇到嵌入在语法规则中的语义动作时,您需要执行这些动作。这些动作可能涉及构建AST节点、执行类型检查、生成中间代码等。 处理解析结果:一旦解析完成,您将得到一个表示输入字符串结构的AST或其他形式的数据结构。您可以进一步处理这些数据结构以生成目标代码、执行静态分析等。扩展语法分析栈 综合记录出栈时,要将综合属性值复制给后面特定的语义动作 变量展开时(即变量本身的记录出栈时),如果其含有继承属性,则要将继承属性值复制给后面特定的语义动作
在递归的预测分析(通常指的是递归下降解析)过程中进行语义翻译,涉及将递归的语法分析与语义动作相结合。递归下降解析是一种自顶向下的解析方法,其中每个非终结符都对应一个递归过程或函数。这些递归函数负责根据语法规则来匹配和消耗输入,并在适当的时候执行语义动作。 以下是在递归的预测分析过程中进行语义翻译的一般步骤: 定义语法规则:首先,您需要定义上下文无关文法(CFG)的规则。这些规则描述了语言的语法结构。 为每个非终结符编写递归函数:对于CFG中的每个非终结符,您需要编写一个递归函数,该函数将尝试匹配并消耗与该非终结符相关的输入。这些函数通常会利用递归调用来处理嵌套的语法结构。 嵌入语义动作:在每个递归函数中,当匹配到特定的语法结构时,您需要嵌入相应的语义动作。这些动作可以是构建抽象语法树(AST)的节点、执行类型检查、进行变量绑定、生成中间代码等。 处理递归调用和回溯:在递归下降解析中,递归函数可能需要处理多种可能的语法分析路径。当遇到多个可选的解析步骤时,您需要使用条件语句(如if-else或switch-case)来选择正确的路径。在某些情况下,可能需要回溯(即撤销之前的解析步骤)以尝试不同的路径。 错误处理:在递归下降解析中,当遇到无法匹配的输入或语法错误时,您需要提供适当的错误处理机制。这可能包括报告错误位置、提供错误消息或尝试进行错误恢复。 构建和使用AST:一旦解析完成并且执行了所有的语义动作,将得到一个表示输入程序结构的抽象语法树(AST)。可以进一步遍历和操作这个AST来进行语义分析、类型检查、代码生成等后续步骤。 在LR分析过程中进行语义翻译给定一个以LL文法为基础的L-属性定义,可以修改这个文法,并在LR语法分析过程中计算这个新文法之上的SDD 首先构造SDT,在各个非终结符之前放置语义动作来计算它的继承属性, 并在产生式后端放置语义动作计算综合属性 对每个内嵌的语义动作,向文法中引入一个标记非终结符来替换它。每个这样的位置都有一个不同的标记,并且对于任意一个标记M都有一个产生式M→ε 如果标记非终结符M在某个产生式A→α{a}β中替换了语义动作a,对a进行修改得到a' ,并且将a'关联到M→ε 上。动作a' (a) 将动作a需要的A或α中符号的任何属性作为M的继承属性进行复制 (b) 按照a中的方法计算各个属性,但是将计算得到的这些属性作为M的综合属性 |


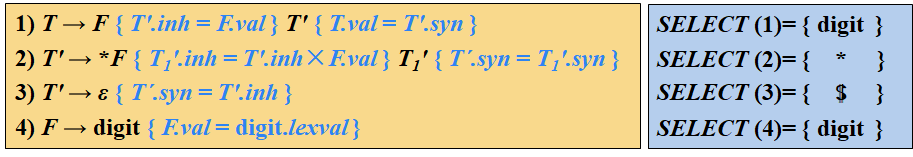


【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |