Nat. Mach. Intell. |
您所在的位置:网站首页 › 蛋白质翻译的准确起始由哪两个方面保障组成 › Nat. Mach. Intell. |
Nat. Mach. Intell.
近日,来自普林斯顿大学电气和计算机工程系、斯坦福大学病理系与RVAC Medicines和Zipcode Bio等单位联合开发了一种5′ UTR语言模型(UTR-LM),由王梦迪教授担任通讯作者,褚晏伊博士和于丹博士共同担任第一作者。该模型旨在解码信使RNA(mRNA)分子起始部位的调控区,以预测和改进基因的翻译表达水平。  方法 本研究采用了多源数据集进行模型的预训练和微调。研究团队收集了来自人类、小鼠、大鼠、鸡和斑马鱼的214,349个5′ UTR序列,以及来自人类肌肉组织、PC3前列腺癌细胞系和HEK 293T细胞系的三个独立数据集。此外,研究还涉及了8个合成库,这些库提供了超过200,000个序列,用于深入探索和训练模型。为了进一步验证模型对不同序列长度的适应性和预测准确性,还采用了两种长度范围为25-100bp的独立测试集进行了序列长度的探索和评估。 UTR-LM模型基于transformer架构,通过自监督学习的方式进行预训练,并结合二级结构(SS)和最小自由能(MFE)等监督信息,以增强模型的预测能力。在多个下游任务上进行微调后,该模型能够准确预测mRNA的核糖体负载量(MRL)、翻译效率(TE)、表达水平(EL)、内部核糖体入口位点(IRES)等关键生物学特性。 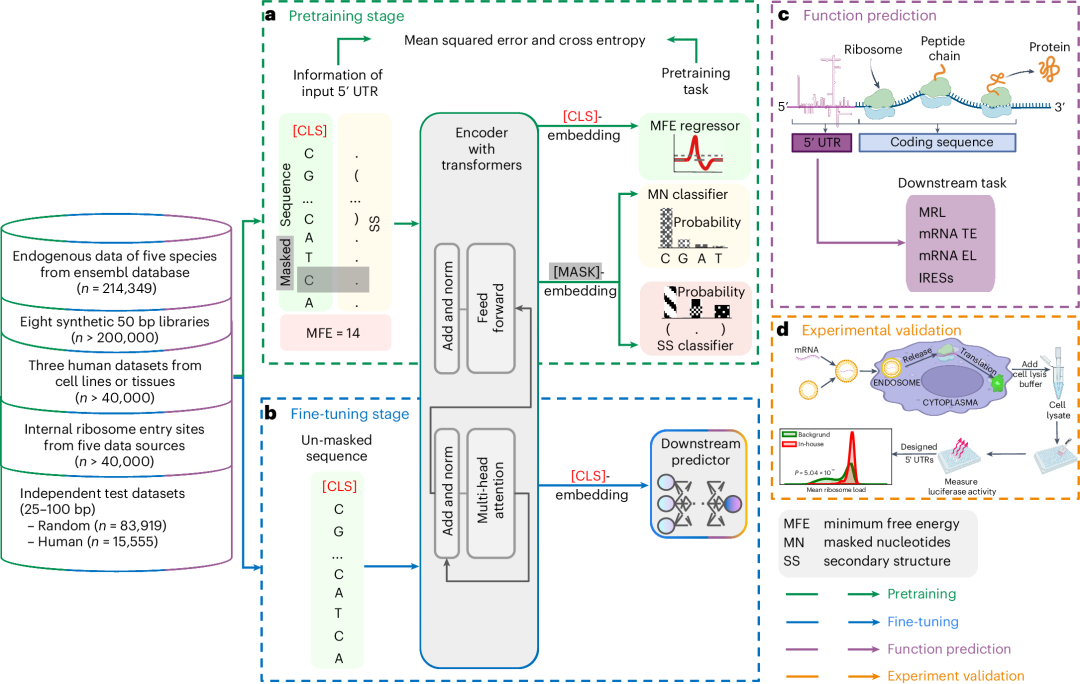 图1. 5′ UTR语言模型(UTR-LM)的开发和应用流程:(a) 模型接收5′ UTR序列作为输入,通过128维随机嵌入和[CLS]-token传输至transformer层,预训练阶段包括掩蔽核苷酸预测(MN regressor)、5′ UTR二级结构预测(SS classifier)和最小自由能预测(MFE classifier);(b) 利用[CLS]-token对模型进行下游任务的训练;(c) 对模型进行微调,以预测平均核糖体负载量(MRL)、mRNA翻译效率(TE)、mRNA表达水平(EL)和内部核糖体入口位点(IRES)等关键指标;(d) 根据模型预测的高翻译效率设计5′ UTR库,并通过mRNA转染和荧光素酶实验进行湿实验室验证。 结果 平均核糖体负载量(MRL) MRL是指在给定时间内,一个特定mRNA分子上活跃的核糖体数量的平均值。它是衡量mRNA翻译效率的一个重要指标,反映了mRNA被翻译成蛋白质的速度和程度。研究表明,UTR-LM模型在预测MRL方面具有卓越性能,这直接影响蛋白质的生产效率。图2展示了UTR-LM模型与其他基准模型在不同数据集上的性能对比。 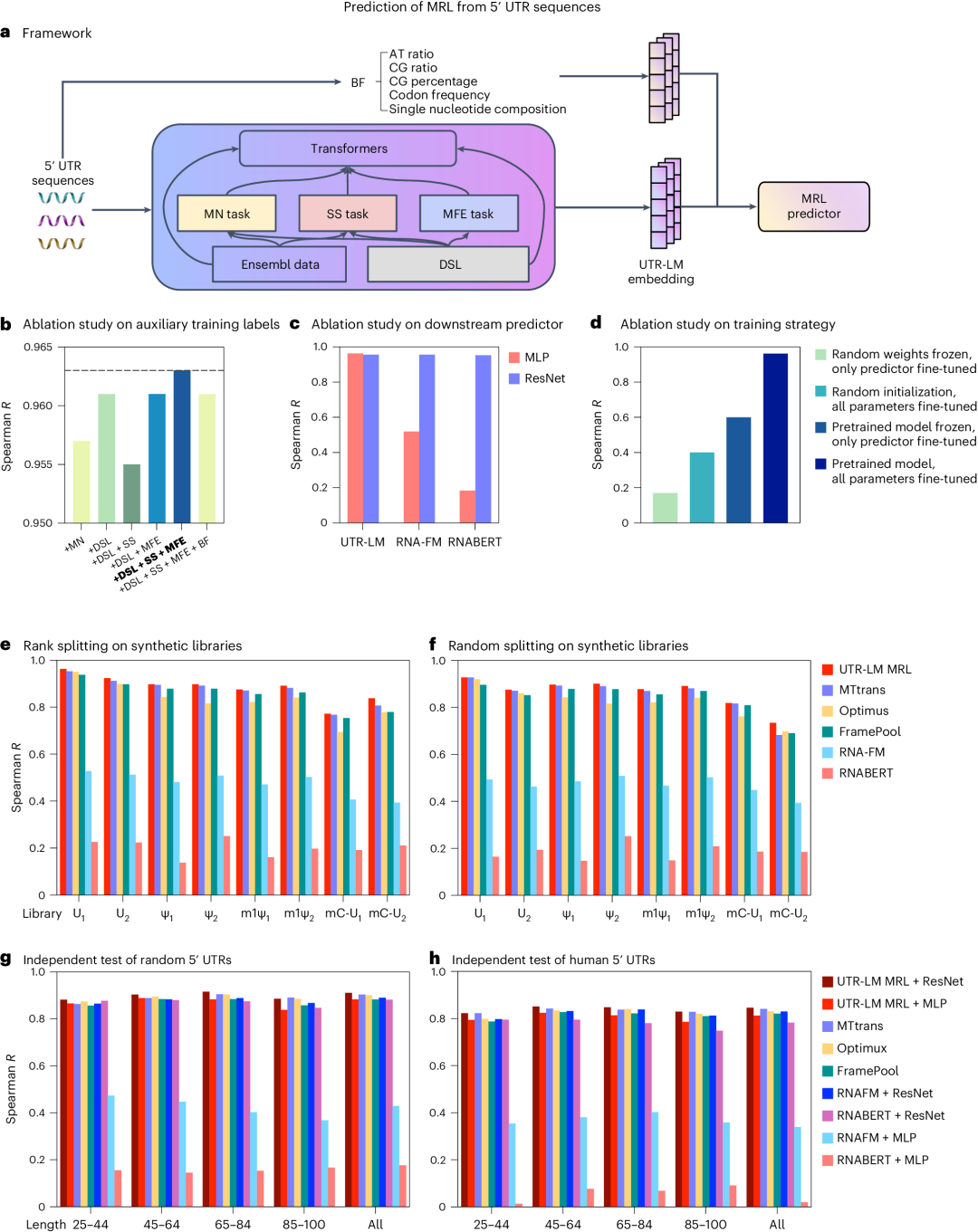 图2. a,UTR-LM 框架,包括在预训练期间集成下游库 (DSL)、二级结构(SS) 和最小自由能(MFE)以及手动提取的生物特征 (BF) 的变体。b,UTR-LM 超参数的消融研究。在后续实验中,使用了由 DSL、SS 和 MFE 增强的基线 UTR-LM,称为 UTR-LM MRL。c,预训练模型在结合简单MLP或复杂下游网络架构(ResNet)后对5′ UTR序列特征提取和功能预测能力的影响。d,评估不同训练策略对模型性能的影响,对比了预训练+微调策略与采用随机权重和/或固定权重的训练策略。e,f,对8个合成的50 bp核苷酸的5' UTR 的文库的各种方法的评估。g,h,使用独立测试评估各种方法。 mRNA表达水平(EL)和翻译效率(TE) EL通常指mRNA或蛋白质在细胞中的丰度,可以通过各种技术如RNA测序(RNA-seq)来量化,反映了基因转录后产物的累积效果。TE是指mRNA从核糖体翻译成蛋白质的速率,它通常通过比较mRNA分子上的核糖体占用情况(即核糖体足迹)与mRNA在细胞中的丰度来计算。UTR-LM模型准确预测了mRNA的这两项指标,这两个因素对于理解蛋白质生产至关重要。如图3所示,模型在这些任务上优于现有的所有基准方法。 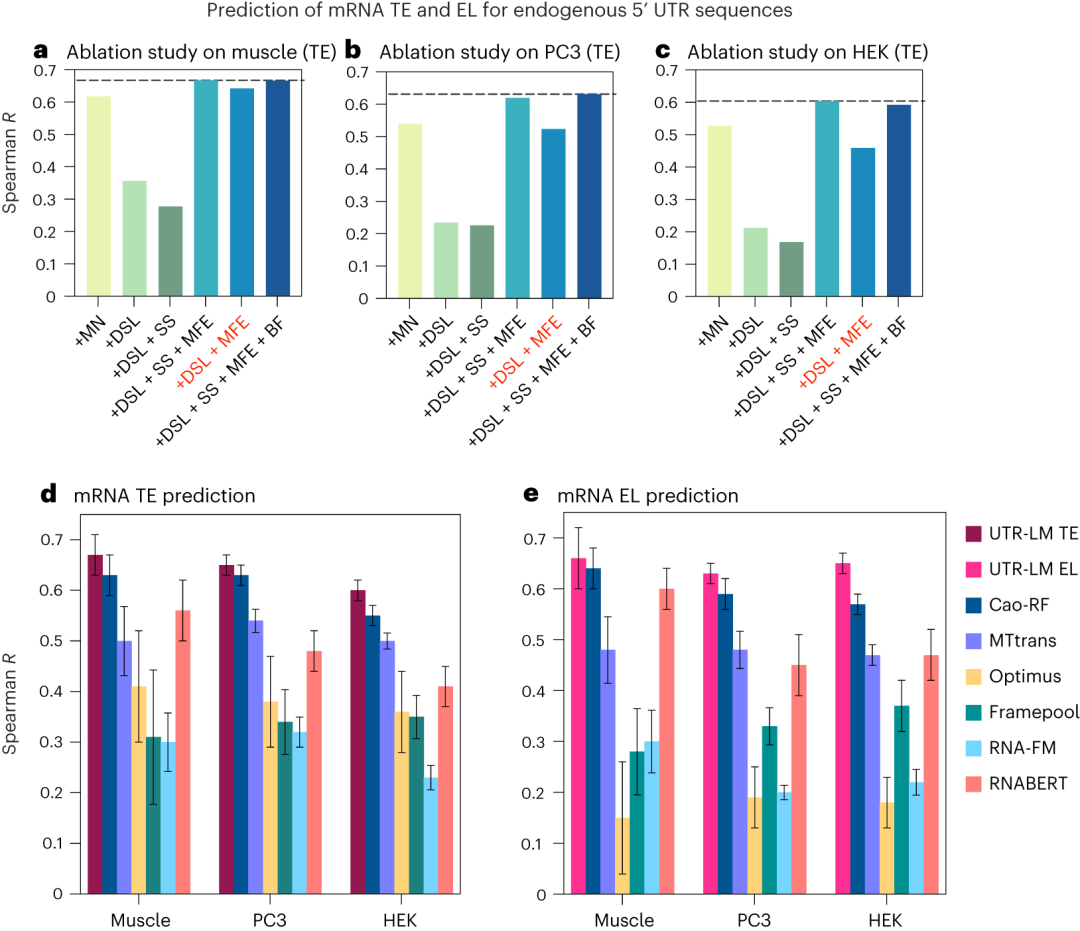 图3. 这些数据集的来源包括人体肌肉组织(Muscle)、PC3 和 HEK293T 细胞系。a-c,UTR-LM超参数在TE任务上的消融研究。在后续实验中,使用DSL和MFE增强的UTR-LM作为最终模型。d,对于 TE 预测,UTR-LM 模型优于 Cao-RF 高达 5%,并且在 Spearman R 方面优于 Optimus 高达 27%。e,对于 EL 预测,UTR-LM 模型优于 Cao-RF高达 8%,并且优于 Optimus 高达 47% 。配对 t 检验表明 UTR-LM 显著优于其他基准(P |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |