一种基于误差优化自动编码器模型的空气质量异常检测方法 |
您所在的位置:网站首页 › 自动编码机异常监测 › 一种基于误差优化自动编码器模型的空气质量异常检测方法 |
一种基于误差优化自动编码器模型的空气质量异常检测方法
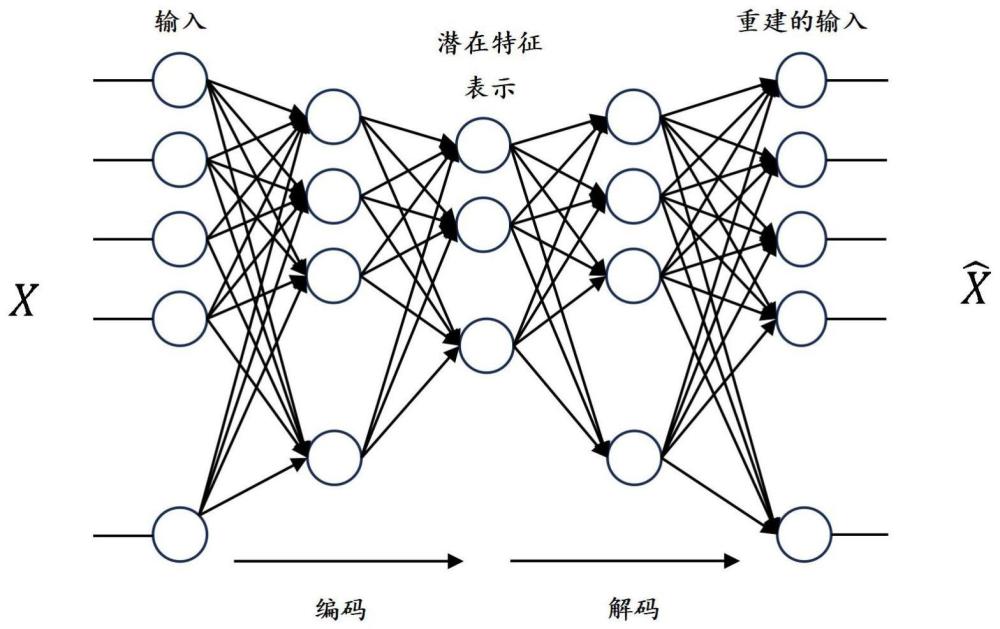 本发明涉及空气质量异常检测技术、密度峰值聚类(density peak clustering,dpc)、自组织映射(self organizing map,som),具体涉及一种基于误差优化自动编码器模型(error-optimized autoencoder model,eoa)的空气质量异常检测方法。 背景技术: 1、现有的研究发现了各种异常值的检测方法,例如基于聚类的技术、基于最近邻的方法和基于深度学习的模型等。基于聚类的离群点检测技术利用相似性或相似模式对数据实例进行分组,不属于任何类的数据实例被视为异常数据。常见的利用聚类方法来检测异常值和噪声点的方法包括:一种基于密度的空间聚类算法(density-based spatialclustering of applications with noise,dbscan),它可以用于噪声鲁棒的数据集,可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇;一种基于密度的聚类算法(ordering points to identify the clustering structure,optics),它可以在大规模数据中发现任意形状的聚类簇,并且对噪声点有较好的鲁棒性;一种基于聚类的局部离群因子检测法(cluster-based local outlier factor,cblof),它采用局部离群因子检测法的思想,基于聚类的方法来检测异常值。基于聚类的方法的核心目标是识别聚类的结构,因此,这类方法会遗漏异常值实例。基于最近邻的异常检测方法分为两类:基于距离和基于密度的检测方法。基于距离的方法通过计算异常实例与正常实例的距离来实现异常检测;在基于密度的技术将每个数据实例的估计密度与其近邻实例进行比较,具有较低估计密度的实例被认为是离群值。breunig等人引入了一种局部离群因子(local outlierfactor,lof)方法,该方法计算给定的数据实例的相对隔离度,然而,对于分散的数据集,该方法的性能是非常差的。此外,当离群数据点密度接近其邻域密度和边界实例时,算法性能会降低。为了进一步增强这种方法的效率,研究者对该方法进行改进,提出了例如基于连接性的离群因子(connectivity-based outlier factor,cof)、影响异常(influence-basedlocal outlier factor,inflo)、基于局部距离的离群因子(label driven outlierfactor,ldof)、局部相关积分(local correlation-based intensity,loci)等。深度学习模型是目前离群点检测领域的有效技术,基于深度学习的模型已经应用于监督、半监督以及无监督模式。在监督模式下,模型通过使用正常实例进行训练,训练后的模型用于异常检测,这种模式的关键问题是获得各个域中的内点和离群点类的精确标签。在用于异常检测的半监督模式中,类别标签仅可用于内部点。 2、无监督模式因可以处理未标记的数据集而被广泛适用。在这种模式下,基于深度学习的网络尝试在输出端重构输入,测量重构误差以对数据集中所有实例的离群值进行排名。许多深度学习技术,例如自适应共振理论(adaptive resonance theory,art)、生成对抗网络(generative adversarial networks,gan)和限制玻尔兹曼机(restrictedboltzmann machines,rbm)等已经应用于异常检测领域。除了上述网络之外,还可以使用循环神经网络(recurrent neural network,rnn)、自动编码器集合(randomized neighbornetwork,randnet),基于boosting的自动编码器集成(bayesian autoencoder,bae)等方法都非常受欢迎。hawkins等人介绍了一种使用循环神经网络进行离群值检测的方法,在该模型中,使用样本数据集训练网络,并使用它来基于重建误差找到实例的离群因子。后来,hadzic和dillon引入了一种基于自组织映射(som)的技术。som通常被称为kohonen网络或kohonen地图,是一个无监督的神经网络,常用于高维数据的聚类和可视化。som也被用作聚类方法,olszewski介绍了一种欺诈检测方法,该方法使用自组织映射来可视化用户配置文件。一类svm(one-class support vector machine,ocsvm)方法也被广泛用于异常检测,该方法是svm的一个特例,其中围绕大多数数据实例构建了一个光滑的超平面。无监督深度学习模型的核心方法是自动编码器。autoencoder是一个对称的人工神经网络,我们可以在无监督的方式训练层。它从数据中发现重要的属性,并构造尽可能接近输入神经元的学习编码表示的输入数据。因此,自动编码器的输出神经元是输入神经元的重构。图1描述了自动编码器的基本架构。自动编码器的机制主要分为3层:编码器、压缩(隐藏)和解码器。在编码器阶段,自动编码器压缩数据以找到有用的信息(压缩层);解码器的工作原理与编码器的工作原理相反,它尽可能接近地重建输入特征。最小化重构误差是自动编码器的主要目标。自动编码器可以应用于多种目的,包括异常检测、图像去噪、数据压缩器(降维)等。在离群点检测过程中,异常实例与正常实例相比具有更高的重构误差。an和cho介绍了一种使用变分自动编码器进行异常检测的方法,在基于变分自动编码器的模型中,重构概率被用来检测离群实例。后来,chalapathy、menon和chawla提出了一种基于自动编码器的鲁棒、深度和感应模型,用于检测离群值。它学习获得大多数实例的非线性子空间。zongetal.利用具有高斯混合的深度自动编码器模型进行离群值检测的无监督模式。首先,他们找到每个数据实例的重建误差,并将其输入高斯混合模型。已经引入了各种基于集成的自动编码器网络来检测离群值实例。chenetal.提出了一种流行的自动编码器集成模型,用于离群值检测,名为randnet。在这种基于集成的网络中,randnet作为全连接网络的替代方案,它使用节点之间的随机连接。sarvari等人开发了一种无监督离群值检测模型,该模型是基于增强的自动编码器集合。为了减少训练数据集中的离群值,他们对数据实例应用了加权采样。后来,du等人介绍了一种无监督的离群点检测方法,即基于图自动编码器的方法。在该方法中,欧几里德结构化数据集被转换成图,并且该图被用于图自动编码器的训练,异常值的确定基于输出层处的实例的重构。 3、总之,自动编码器已经被用于离群值检测。然而,基于自动编码器的模型的重建过程包括整个数据集(正常和异常实例)。因此,对于正常实例,重建误差被高估,而对于异常实例,重建误差被低估。因此,本发明希望提出可以计算重建误差的其它技术来实现有效地检测空气质量异常数据。 技术实现思路 1、本发明解决的问题是:提出了一种基于误差优化自动编码器(error-optimizedautoencodermodel,eoa)模型的空气质量异常检测方法,该方法通过应用智能聚类技术识别空气质量异常检测数据集中的离群点,即空气质量异常数据,实现空气质量异常检测。本发明第一阶段首先进行误差优化训练,本发明使用两种智能聚类技术——密度峰值聚类(densitypeakclustering,dpc)和自组织映射(self organizingmap,som),获得空气质量异常检测数据集的无监督聚类;其次,使用不同策略从空气质量异常检测数据集的无监督聚类中挑选可能的离群值实例,并构建空气质量正常数据集;最后,在空气质量正常数据集上应用深度自动编码器模型(deepautoencoder model)以优化其重建误差。第二阶段,本发明构建一种基于eoa模型的空气质量异常检测方法,使用空气质量异常检测数据集对该模型进行训练和验证。其具体步骤如下: 2、(1)数据准备:根据空气质量检测站点采集到的空气质量监测数据建立空气质量异常检测数据集,对其进行存储和初步预处理。 3、(2)数据预处理:为保证分析和建模的准确性,首先对挑选出的空气质量异常数据进行数据清洗,具体包括对缺失值和异常值的处理。对于时间跨度较小的缺失值,采用线性插值或者二次插值来填充缺失值;对于长时间跨度的缺失值的情况,使用临近日期内相同时间段的数据进行填充;对出现明显异常的数据进行替换或删除。对部分数据类型进行转换,将数值信息进行日期转换,方便后续处理。 4、(3)使用不同策略从每个聚类中挑选可能的离群值实例,具体包括: 5、(a)在一个集群cj中,我们计算一个点的两个重要特征,即密度和与密度较高的实例的距离,这两个特点用于从每个聚类中识别可能的离群实例。其中,数据点i的密度可以表示为: 6、 7、其中dik是实例i到集群cj内除实例i以外的所有其它实例的距离。是依赖于集群cj内实例的均值和标准差的截止距离(cutoff distance),并且x(d)=1,ifd<0,x(d)=0。对于数据点i,其邻域内的样本数为δ(i),则与密度较高的数据点i的距离可以表示为: 8、 9、它是到集群cj中密度较高的点的最近距离。基于这两个特征,将密度低但距离密集区域很近的点和距离密集区域很远的点作为可能的离群点。 10、(b)使用不同的策略从每个聚类中获得可能的离群值实例。 11、在第一个策略中,为了找到密度低但距离密集区域很近的点,首先通过将每个点的密度乘以聚类内的距离来计算每个点的概率离群值得分pos(1),可以注意到,离群值较小的值表示更有可能成为离群点。 12、pos(1)(i)=density(i)*distance(i) (3) 13、在找到聚类中每个数据点的概率离群值得分pos(1)后,按其升序对数据实例进行排序,并选择前n个数据实例作为集群cj中可能的离群数据,并表示为probable_outlier_point(1)。 14、在第二个策略中,为了识别密度低且距离密集区域非常远的实例,首先计算离群值时将密度乘以聚类内每个点的距离的倒数,并表示为概率离群值得分pos(2): 15、 16、在找到聚类中每个数据点的概率离群值得分pos(2)后,按其升序对数据实例进行排序,并选择前n个数据实例作为集群cj中可能的离群数据,并表示为probable_outlier_point(2)。我们将列表probable_outlier_point(1)和probable_outlier_point(2)的选定实例组合起来,并表示为: 17、probable_outlier_point 18、=probable_outlier_point(1)∪probable_outlier_point(2) (5) 19、通过使用以上两种策略,我们能够获得具有低密度并且与密集区域非常远或非常接近的异常实例。然而,这也可能会错过非常接近密集区域的真正离群值实例。 20、在第三个策略中,为了找到非常接近密集区域的真正离群值实例,利用特征距离的高斯分布函数,首先得到概率离群值得分pos,表示为: 21、pos(i)=density(i)*f(distance(i)) (6) 22、其中σ和μ是正态分布的参数,分别表示标准差和平均值。在找到聚类中每个数据点的概率离群值得分pos后,按其升序对数据实例进行排序,并选择前n个数据实例作为集群cj中可能的离群数据,并表示为probable_outlier_point。 23、(4)创建空气质量正常数据集并用其训练深度自动编码器模型,具体包括: 24、(a)设是d未标记的数据集,p是检测到的可能的离群点probable_outlier_point,即空气质量异常数据。 25、(b)在检测到可能的空气质量异常数据之后,需要从空气质量异常检测数据集中排除这些实例,并且数据集中的其余点(d-p)被认为是“正常点”,即空气质量正常数据集。 26、(c)使用空气质量正常数据集计算深度自动编码器模型的重建误差,其中重建误差使用均方误差(mse)来计算,mse测量如: 27、 28、其中,xi表示输入,表示输出(重建的输入),n是数据集的大小。 29、(d)使用整流线性单位(relu)和双曲正切(tanh)作为模型的激活函数。 30、relu:f(x)=max{0,x} (8) 31、 32、其中x表示输入向量。 33、(e)为了提高模型性能,使用l1正则化,对于损失优化使用适应性矩估计(adaptive moment estimation,adam)优化,简称adam优化器。 34、(5)构建一种基于误差优化自动编码器(eoa)模型,具体包括: 35、(a)使用空气质量异常检测数据集训练eoa模型,输出每个实例的重建误差,其中重建误差使用mse来计算。 36、(b)与权利要求4中(4-5)步骤相同。 37、(c)根据计算出的实例的重建误差,按其升序对数据实例进行排序,将前n个数据实例判断为离群点,即空气质量异常数据。 38、(6)采用交叉验证方法对基于eoa模型的空气质量异常检测方法进行验证,具体包括: 39、(a)将空气质量异常检测数据集按8:2划分训练集和测试集,采用10折交叉验证(10-fold cross-validation)来测试eoa模型的准确性。 40、(b)利用precision@n、recall、和接收器操作特性曲线下面积(auc_roc)作为实验的评估指标。 41、 42、 43、其中,tp和fn分别代表真正例(truepositive)和假负例(false negative),tp是指预测为正,实际也为正的样本数量;fn是指预测为负,实际也为负的样本数量。top_n表示数据实例按概率离群值得分升序排序后的前n个数据实例输入,即被判断为空气质量异常的实例。auc_roc值表示roc曲线下的面积,用于衡量分类器性能,其中roc曲线是一种描绘分类器性能的图形工具,它显示了在不同阈值下分类器的真阳性率(truepositiverate,tpr)和假阳性率(false positiverate,fpr)之间的关系。 |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |