一文看懂自编码器、堆叠自编码器、稀疏自编码器、降噪自编码器 |
您所在的位置:网站首页 › 自动编码机 › 一文看懂自编码器、堆叠自编码器、稀疏自编码器、降噪自编码器 |
一文看懂自编码器、堆叠自编码器、稀疏自编码器、降噪自编码器
我的小程序:
 待办计划:给自己立个小目标吧!
待办计划:给自己立个小目标吧!
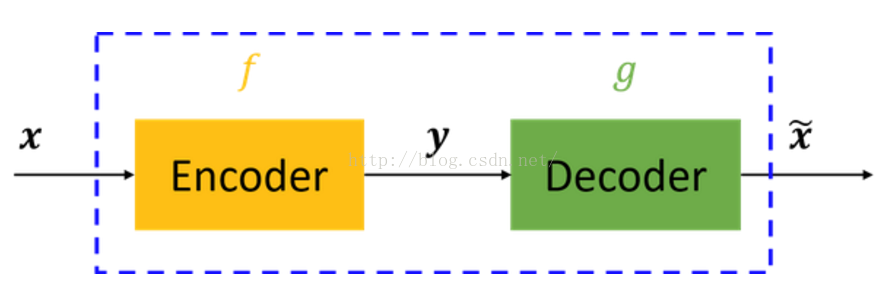
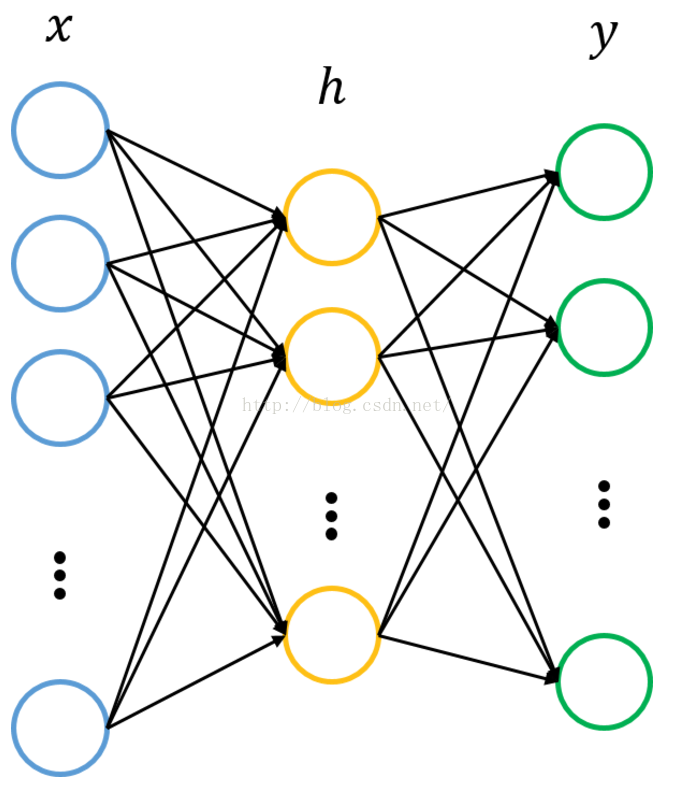
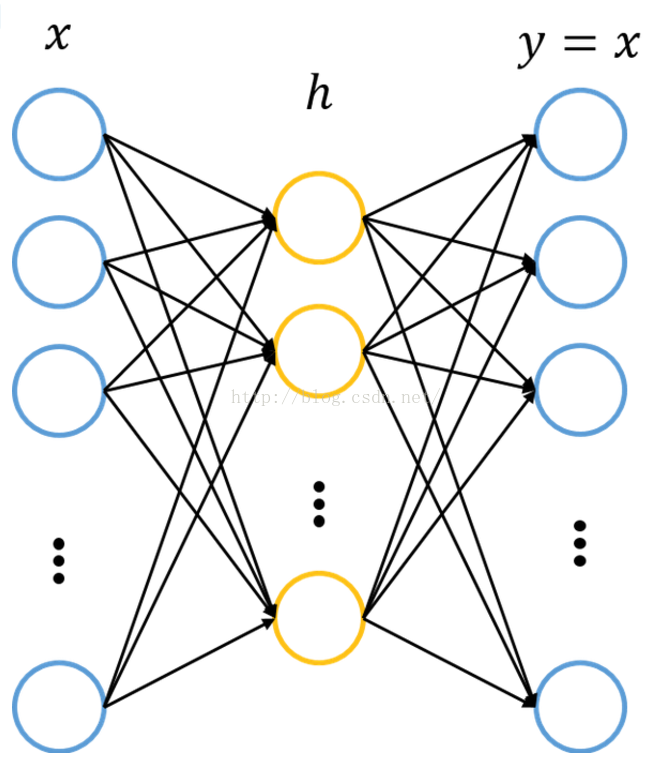
自从Hinton 2006年的工作之后,越来越多的研究者开始关注各种自编码器模型相应的堆叠模型。实际上,自编码器(Auto-Encoder)是一个较早的概念了,比如Hinton等人在1986, 1989年的工作。(说来说去都是这些人呐。。。) 自编码器简介 先暂且不谈神经网络、深度学习,仅是自编码器的话,其原理很简单。自编码器可以理解为一个试图去还原其原始输入的系统。如下图所示: 图中,虚线蓝色框内就是一个自编码器模型,它由编码器(Encoder)和解码器(Decoder)两部分组成,本质上都是对输入信号做某种变换。编码器将输入信号x变换成编码信号y,而解码器将编码y转换成输出信号 而自编码器的目的是,让输出 这里强调一点,对于自编码器,我们往往并不关系输出是啥(反正只是复现输入),我们真正关心的是中间层的编码,或者说是从输入到编码的映射。可以这么想,在我们强迫编码y和输入x不同的情况下,系统还能够去复原原始信号x,那么说明编码y已经承载了原始数据的所有信息,但以一种不同的形式!这就是特征提取啊,而且是自动学出来的!实际上,自动学习原始数据的特征表达也是神经网络和深度学习的核心目的之一。 为了更好的理解自编码器,下面结合神经网络加以介绍。 自编码器与神经网络 神经网络的知识不再详细介绍,相信了解自编码器的读者或多或少会了解一些。简单来讲,神经网络就是在对原始信号逐层地做非线性变换,如下图所示: 该网络把输入层数据x∈Rn转换到中间层(隐层)h∈Rp,再转换到输出层y∈Rm。图中的每个节点代表数据的一个维度(偏置项图中未标出)。每两层之间的变换都是“线性变化”+“非线性激活”,用公式表示即为: h=f(W(1)x+b(1)) y=f(W(2)h+b(2)) 神经网络往往用于分类,其目的是去逼近从输入层到输出层的变换函数。因此,我们会定义一个目标函数来衡量当前的输出和真实结果的差异,利用该函数去逐步调整(如梯度下降)系统的参数(W(1),b(1),W(2),b(2)),以使得整个网络尽可能去拟合训练数据。如果有正则约束的话,还同时要求模型尽量简单(防止过拟合)。 那么,自编码器怎么表示呢?前面已说过,自编码器试图复现其原始输入,因此,在训练中,网络中的输出应与输入相同,即y=x,因此,一个自编码器的输入、输出应有相同的结构,即: 我们利用训练数据训练这个网络,等训练结束后,这个网络即学习出了x→h→x的能力。对我们来说,此时的h是至关重要的,因为它是在尽量不损失信息量的情况下,对原始数据的另一种表达。结合神经网络的惯例,我们再将自编码器的公式表示如下:(假设激活函数是sigmoid,用s表示) 其中,L表示损失函数,结合数据的不同形式,可以是二次误差(squared error loss)或交叉熵误差(cross entropy loss)。如果 为了尽量学到有意义的表达,我们会给隐层加入一定的约束。从数据维度来看,常见以下两种情况: n>p,即隐层维度小于输入数据维度。也就是说从x→h的变换是一种降维的操作,网络试图以更小的维度去描述原始数据而尽量不损失数据信息。实际上,当每两层之间的变换均为线性,且监督训练的误差是二次型误差时,该网络等价于PCA!没反应过来的童鞋可以反思下PCA是在做什么事情。 n |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |