编译原理学习之:正则表达式(regular expression)和非正则语言(non |
您所在的位置:网站首页 › 联立方程组求解正则表达式怎么写的 › 编译原理学习之:正则表达式(regular expression)和非正则语言(non |
编译原理学习之:正则表达式(regular expression)和非正则语言(non
|
文章目录
回顾子集构造(NFA
→
\rightarrow
→DFA)正则语言的闭包结果正则语言的 Union 依然是正则语言正则语言的 concatenate
○
○
○ 操作依然是正则的正则语言的
k
l
e
e
n
e
s
t
a
r
kleene~ star
kleene star 依然是正则语言正则语言的其他闭包性质如何构造 DFA 的运算算法(构造 DFA 的交、并、补集)
如何构造最小的 DFA(指包括最少状态数的 DFA)构造最小化 DFA 举例
正则表达式正则表达式语法和语义正则表达式举例正则表达式和自动机(Regular Expression VS. Automata)构造单个起始状态的 NFA正则语言
→
\rightarrow
→ NFA 举例(单个起始状态):
(
a
∪
b
)
∗
b
c
(a ∪ b)^∗bc
(a∪b)∗bc
构造单个 accept 状态的 NFA(兴趣读物:国内课本的方法)通过正则语言构造 NFA正则语言
→
\rightarrow
→ NFA 举例
化简 “单个” 起始和 accept 状态的 NFA扩展
正则表达式的定理正则语言的局限性通过泵引理(Pumping Lemma)来验证正则语言泵引理反证法实例
回顾子集构造(NFA
→
\rightarrow
→DFA)
 正则语言的 concatenate
○
○
○ 操作依然是正则的
正则语言的 concatenate
○
○
○ 操作依然是正则的
 要构造最小的 DFA 要不断重复以下步骤
翻转 NFA确定化结果再翻转再次确定化结果 翻转 NFA 的方式也很简单:
那就是将所有的状态上的线调转方向将接受(accept)状态节点和初始节点(start)互换 要构造最小的 DFA 要不断重复以下步骤
翻转 NFA确定化结果再翻转再次确定化结果 翻转 NFA 的方式也很简单:
那就是将所有的状态上的线调转方向将接受(accept)状态节点和初始节点(start)互换  构造最小化 DFA 举例
构造最小化 DFA 举例
这是我们要最小化的 NFA, 我们在下面的步骤中通过它得到一个最小的 DFA 第一步: 翻转(1节点和 2 节点的功能互换,原本 1 是初始节点,2是accept 节点,现在调转一下 1 变成了 accept 节点,2 变成了初始节点) 第二步: 通过调转的 NFA 进行确定化得到当前状态下的 determinism 的结果 因为最终状态中 5 , 6 5,6 5,6 包含原来的 1 1 1 状态(即 accept 状态),因此, 5 , 6 5,6 5,6 应该被标定为出口 第三步 再次调转已经得到的 NFA ;
5
,
6
5,6
5,6 变成了起始状态;
4
4
4 变成了 accept 状态 第四步: 重复第二步的 determinism 得到最后的状态
 这个式子
δ
′
(
q
,
v
)
\delta^{'}(q,v)
δ′(q,v) 中,
q
i
q_i
qi 代表的就是原本的 多个起始状态
q
q
q 统一用
q
i
q_i
qi +
ϵ
\epsilon
ϵ 代替;而其他不是起始状态开始的节点则遵循原本的
δ
\delta
δ 转换状态。 这个式子
δ
′
(
q
,
v
)
\delta^{'}(q,v)
δ′(q,v) 中,
q
i
q_i
qi 代表的就是原本的 多个起始状态
q
q
q 统一用
q
i
q_i
qi +
ϵ
\epsilon
ϵ 代替;而其他不是起始状态开始的节点则遵循原本的
δ
\delta
δ 转换状态。  正则语言
→
\rightarrow
→ NFA 举例(单个起始状态):
(
a
∪
b
)
∗
b
c
(a ∪ b)^∗bc
(a∪b)∗bc
国外的书籍和课件 是按照这种方式进行构造和转换的
正则语言
→
\rightarrow
→ NFA 举例(单个起始状态):
(
a
∪
b
)
∗
b
c
(a ∪ b)^∗bc
(a∪b)∗bc
国外的书籍和课件 是按照这种方式进行构造和转换的  构造单个 accept 状态的 NFA
可以看到下图的
N
N
N 中有 3 个终止状态汇总起始状态和将初始状态分开都同样使用
ϵ
\epsilon
ϵ例如下图的例子:
构造单个 accept 状态的 NFA
可以看到下图的
N
N
N 中有 3 个终止状态汇总起始状态和将初始状态分开都同样使用
ϵ
\epsilon
ϵ例如下图的例子:  图中的
δ
′
(
q
,
v
)
\delta^{'}(q,v)
δ′(q,v) 代表的就是将状态转换函数分成了两类:
如果是原来 accept 状态,那么就添加一个新的状态
q
f
q_f
qf 并且把原来所有的 accept 状态都通过
ϵ
\epsilon
ϵ 连接过去原来的其他状态则不需要进行调整,维持原本的样子 所以我们看到下图中的三个原本的 accept 状态都通过
ϵ
\epsilon
ϵ 连到了新的 “唯一的 accpet” 状态
q
f
q_f
qf 图中的
δ
′
(
q
,
v
)
\delta^{'}(q,v)
δ′(q,v) 代表的就是将状态转换函数分成了两类:
如果是原来 accept 状态,那么就添加一个新的状态
q
f
q_f
qf 并且把原来所有的 accept 状态都通过
ϵ
\epsilon
ϵ 连接过去原来的其他状态则不需要进行调整,维持原本的样子 所以我们看到下图中的三个原本的 accept 状态都通过
ϵ
\epsilon
ϵ 连到了新的 “唯一的 accpet” 状态
q
f
q_f
qf  (兴趣读物:国内课本的方法)通过正则语言构造 NFA
当我们获得一个正则语言,我们如果要构造 NFA(单起始状态的),我们只需要不断重复下面 三个步骤 即可:(国内书籍版本)
将 concatenate 操作分成两个串联的部分将 union (|)操作分成两个并联的部分将闭包运算 * 分成第三种情况
(兴趣读物:国内课本的方法)通过正则语言构造 NFA
当我们获得一个正则语言,我们如果要构造 NFA(单起始状态的),我们只需要不断重复下面 三个步骤 即可:(国内书籍版本)
将 concatenate 操作分成两个串联的部分将 union (|)操作分成两个并联的部分将闭包运算 * 分成第三种情况  正则语言
→
\rightarrow
→ NFA 举例
正则语言
→
\rightarrow
→ NFA 举例
 通过下面例子来进行演示:假设化简的是下面的例子 通过下面例子来进行演示:假设化简的是下面的例子  首先先把上面的两个 accept 状态的图转换成一个 accept 状态,根据上面的知识 首先先把上面的两个 accept 状态的图转换成一个 accept 状态,根据上面的知识  通过正则表达式来替换线上的字符从而实现状态的化简: 通过正则表达式来替换线上的字符从而实现状态的化简: 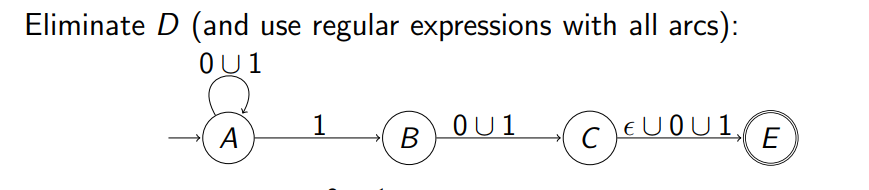 再次通过正则表达式来合并中间的步骤 再次通过正则表达式来合并中间的步骤 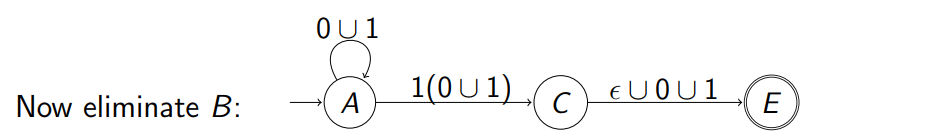 最终把中间状态逐渐换成正则表达式;得到了最简的 NFA 最终把中间状态逐渐换成正则表达式;得到了最简的 NFA 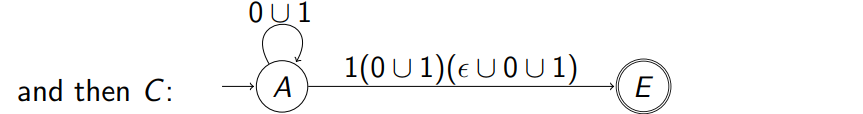 而上述的式子就相当于我们最开始引入的
(
R
1
∪
R
2
R
3
∗
R
4
)
∗
R
2
R
3
∗
(R_1 ∪ R_2R_3^∗R_4)^∗R_2R_3^∗
(R1∪R2R3∗R4)∗R2R3∗ 而上述的式子就相当于我们最开始引入的
(
R
1
∪
R
2
R
3
∗
R
4
)
∗
R
2
R
3
∗
(R_1 ∪ R_2R_3^∗R_4)^∗R_2R_3^∗
(R1∪R2R3∗R4)∗R2R3∗ 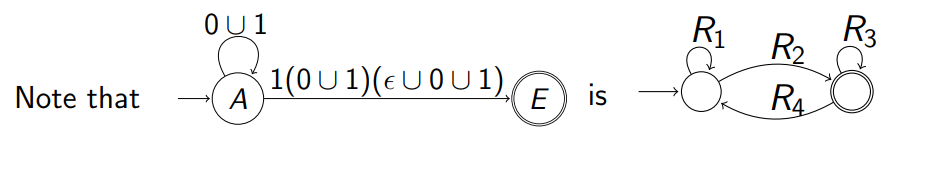 因此我们容易得到以下替换: 因此我们容易得到以下替换: 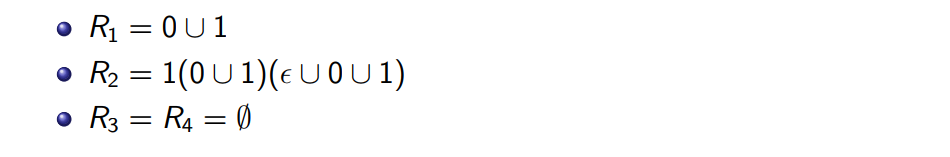 扩展
下图中表示的:一个进,一个出,一个循环的这种状态可以被固定的写成
R
1
R
2
∗
R
3
R_1R_2^∗R_3
R1R2∗R3
扩展
下图中表示的:一个进,一个出,一个循环的这种状态可以被固定的写成
R
1
R
2
∗
R
3
R_1R_2^∗R_3
R1R2∗R3
 正则表达式的定理
正则表达式的定理
{ 0 n 1 n ∣ n ≥ 0 } = { ϵ , 01 , 0011 , 000111 , . . . } \{0^n1^n | n ≥ 0\} = \{\epsilon, 01, 0011, 000111, . . .\} {0n1n∣n≥0}={ϵ,01,0011,000111,...} 对于上面的语言我们无法使用 DFA 来识别,即:他不是一个正则语言。 通过泵引理(Pumping Lemma)来验证正则语言
|











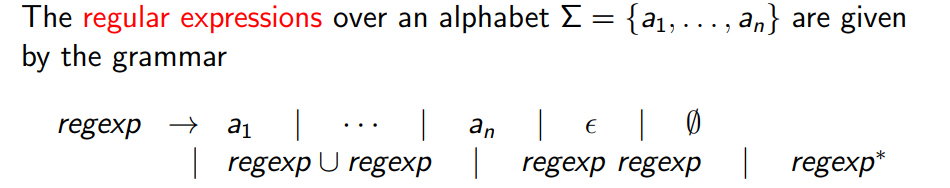














【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |