(项目)爬取网易社会招聘网站的职位信息 |
您所在的位置:网站首页 › 网易招聘网址 › (项目)爬取网易社会招聘网站的职位信息 |
(项目)爬取网易社会招聘网站的职位信息
|
简介
打开网易社会招聘网站(https://hr.163.com/job-list.html),使用scrapy框架爬取职位信息。
思路
对于翻页:因为职位信息是不断更新变化的,所以不能使用for循环进行翻页,使用for循环只能爬取固定的页数。应该使用while true进行死循环,然后再进行判断是否到达了最后一页,如果到达了最后一页就终止死循环。 步骤 ①创建scrapy项目 在cmd命令行中输入:scrapy startproject wangyizhaopin ②明确爬取目标
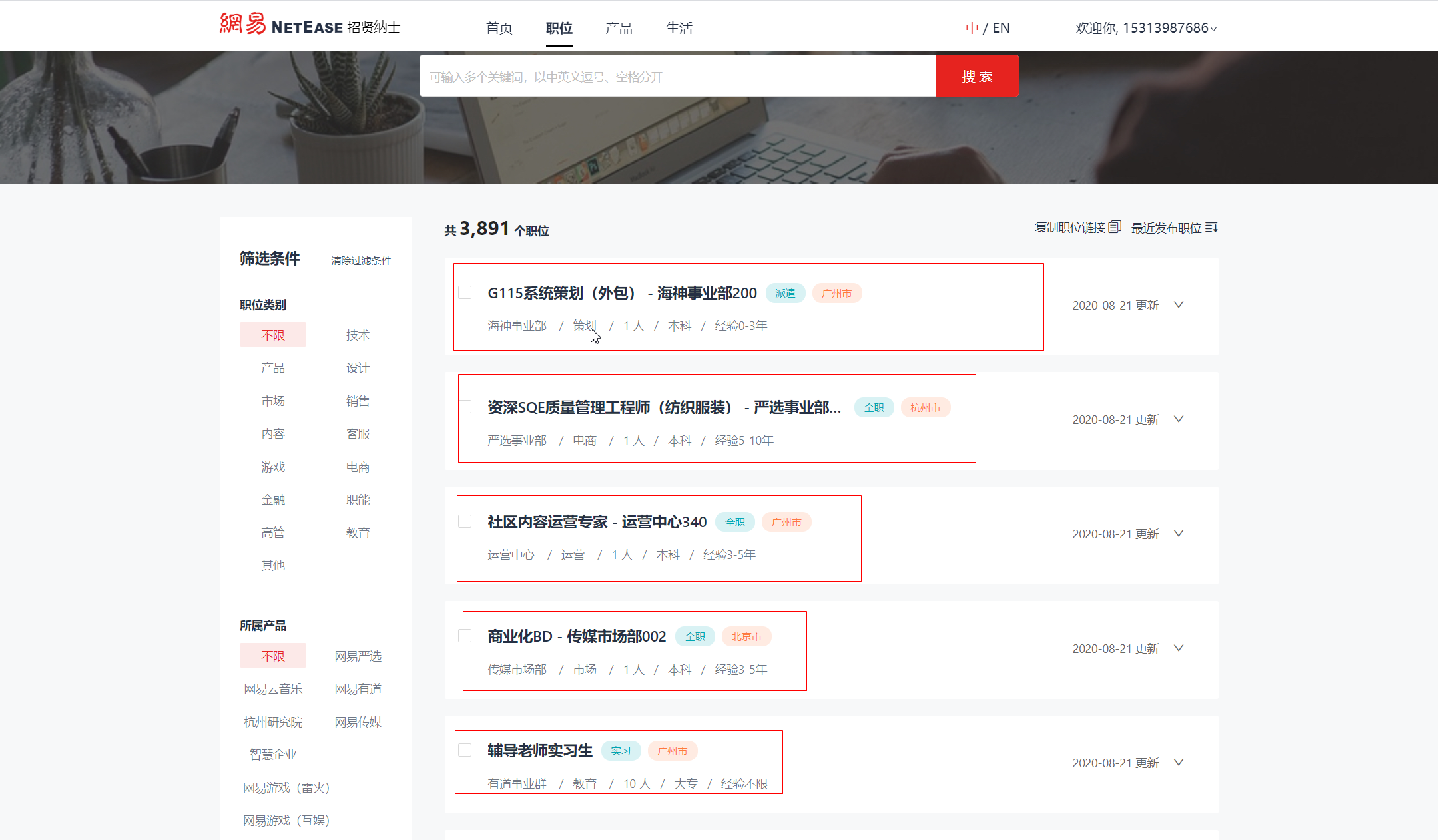
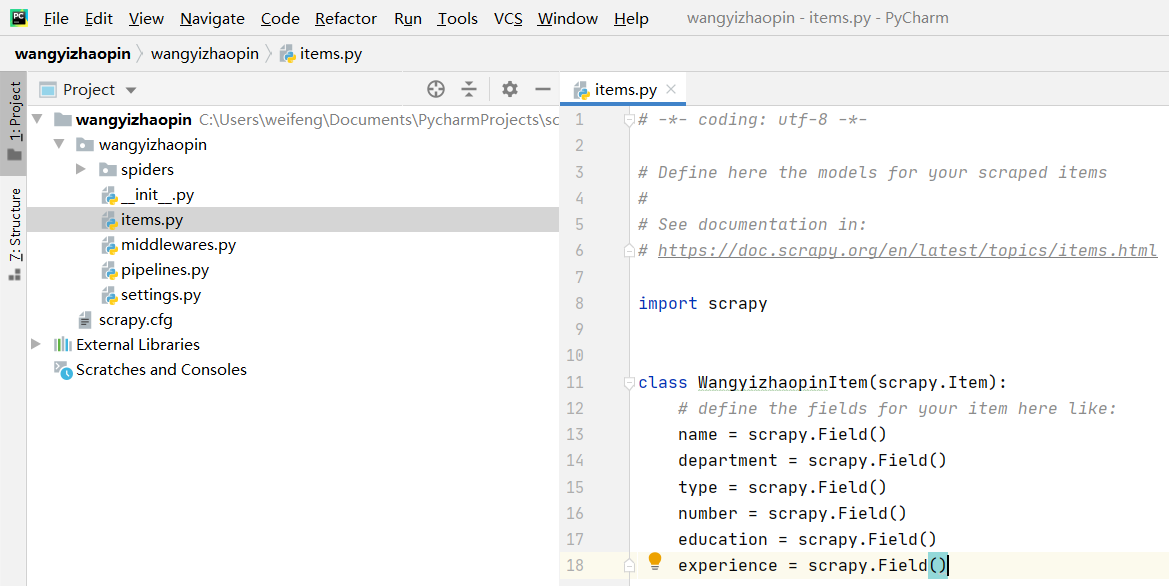
由图片可知,我们要爬取一个职位的信息包括它的名称、所属部门、职位类别、招聘人数、学历、工作年限。 因此,我们需要在items.py文件中进行数据建模(6个)。
③创建爬虫 在cmd命令行中输入:scrapy genspider job 163.com 注意:要在项目路径下创建爬虫。 ④完成爬虫
①修改起始url 把起始url改为 https://hr.163.com/job-list.html ②检查允许爬取的域名 163.com符合我们要爬取的网站的域名,所以不用修改。
③在parse方法中实现爬取逻辑
|


【本文地址】
公司简介
联系我们
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |