SPSS回归分析(线性:一元(简单)和多重;非线性logistic) |
您所在的位置:网站首页 › 简单相关分析的spss操作步骤 › SPSS回归分析(线性:一元(简单)和多重;非线性logistic) |
SPSS回归分析(线性:一元(简单)和多重;非线性logistic)
|
SPSS线性回归分析
回归分析回归分析的一般步骤一、线性模型(针对连续因变量,线性关系)(一)简单线性回归(一元线性回归)1、绘制散点图2、建立简单(一元)线性回归模型3、建立模型后,检查预测结果
(二)多重回归分析(看调整后的R方值)1、绘制矩阵分布散点图(论文专用你懂的)2、建立多重回归模型point 1:自变量加入方法:逐步(步进,向前)法point2:logistic回归方法的选择:输入、向前、向后与条件、LR、Wald
3、建立模型后,检查预测结果
二、非线性模型(将非线性问题转换为线性问题)1、logistic分析的回归模型1.1 建立回归模型1.2 利用回归模型进行预测
通过评价实验得到主观数据, 然后通过描述性分析和显著性分析对这些数据的显著作用和影响趋势进行了判断. 最后一步就是针对这些数据,建立起可描述变量同主观感知结果之间的模型。 这个模型除了能够表征我们的数据 规律,还能够对已知变量分布的数据进行有效的 预测。 !!!!!!敲黑板啦!!!!!!!!!!!!!! 如果大家写主观实验相关论文的话,能够拔高这篇论文的层次的一个重要方面,就是有没有通过数据建立起来的模型。 !!!!!!!!!!!!!!!!!!!!!!!!! 首先是: 回归分析从定义上说,回归分析是研究自变量与因变量之间数量变化关系的一种分析方法。 它主要是通过建立因变量Y与影响它的自变量Xi(i=1,2,3,…)之间的回归模型,衡量自变量Xi对于因变量Y的影响能力,进而可以用来预测因变量Y的发展趋势。 回归分析的一般步骤1)根据预测目标,确定自变量和因变量; 2)绘制散点图,确定回归模型类型; 3)估计模型参数,建立回归模型; 4)对回归模型进行检验; 5)利用回归模型进行预测 一、线性模型(针对连续因变量,线性关系) (一)简单线性回归(一元线性回归)简单线性回归,也称为:一元线性回归。 就是回归模型中只有一个自变量,和我们的单因素分析相对应,它主要用来处理一个自变量和一个因变量之间的线性关系。 但更多情况下,我们要研究的因变量会受到很多自变量影响,那时需要后面的多重回归分析(多重回归分析记得看:调整后的R2,不是下面单纯的R2)。 一元线性回归的公式非常简单,就是一条直线方程,求截距(常数项)和自变量的系数,就是建立这个模型的方法: 这里面具体的解法我们就不研究了,大家只要知道,采用的是最小二乘法的解法即可。 在统计学应用领域有很多进行线性回归解法的案例,我们分析主观感知数据也可以参考这些案例,除了目的不同外,思路和方法都是一样的。 1、绘制散点图举个例子,有一家超市连续3年的销售数据,包括:月份、季度、广告费用、客流量4个自变量和销售额1个因变量,共有36条记录。 下面我们从中 选择1个变量 进行一元线性回归的研究,这里可以选择广告费用,并绘制散点图进行观察。 Y轴是我们的因变量,销售额 X轴是我们想研究的广告费用,选择并按箭头导入 导入好数据后,点击确定,然后这个散点图就出现在输出窗口中啦
咱们这里是一元线性回归,所以看R方就可以。 但是,后面的多重回归分析要看调整后的R方值。 下一个表是方差分析结果,用于判断自变量的显著程度,sig就是p值,P(sig)<0.01,具有极其显著的统计学意义,表明进行方差分析是合理的,建立模型自然也可以: 接下来让我们检查一下预测的结果: 继续打开刚刚的线性回归主面板,其他参数是我们设置过的,都不变,点击保存: 多重回归要看调整后的R2值。 多重回归即:研究多个自变量如何影响待研究的因变量。 我们还用这个销售额的数据举例:将广告费用和客流量作为自变量,将销售额作为因变量,建立多重线性回归模型。 1、绘制矩阵分布散点图(论文专用你懂的)观察2个自变量和1个因变量之间是否存在线性关系。 同时,两个自变量之间也存在线性关系,即广告费用和客流量之间也存在线性关系。 这一点非常重要,可能会影响后面的结果分析: 接下来仍然是建立线性回归模型: 意思是:将自变量逐个引入模型并进行显著性检验,逐个剔除不显著的自变量,直至再也没有不显著的自变量从回归模型中剔除为止。 point 1:自变量加入方法:逐步(步进,向前)法逐步(步进)法,适用于有很多变量的回归模型,这里我们只考虑两个变量,所以还是选输入。 不要嫌我啰嗦!!这里插入一块细致地说一下: point2:logistic回归方法的选择:输入、向前、向后与条件、LR、Wald
挑选方法: 当自变量较少,且研究者希望考察所有自变量与因变量间关系时,可考虑使用Enter法,强迫所有自变量参与建模,而不考虑是否有显著影响。 当自变量较多,研究者希望软件帮助筛选对因变量有显著影响的自变量参与建模,此时,新手用户可选择【向前:LR】或【向前:条件】方式进行logistic逐步回归建模。 3、建立模型后,检查预测结果不再赘述。 二、非线性模型(将非线性问题转换为线性问题)以上的简单(一元)和多重回归模型,两者主要是针对连续因变量的线性模型。 但当现实中出现自变量和因变量——输入与输出之间是非线性的关系时,我们要通过对数型变换,将非线性问题转换为线性问题。 在这些非线性模型中,我们将跟大家介绍的是一个名叫logistic分析的回归模型。 1、logistic分析的回归模型logistic可以处理分类问题,我们这里也主要研究模型建立中比较常见的分类问题。 Logistic回归:针对因变量为分类变量而进行回归分析的一种统计方法。 属于概率型非线性回归(当因变量概论≥0.5,判断为1;小于0.5,判断为0)。 分类变量有两种情况(针对因变量!!): 二分类:例如0和1,表示无或有,比如顾客是否购买产品无序多分类:具有多个类别,比如1,2,3,4,5,例如顾客到底会购买哪一件产品有序多分类(也叫累积或序次logistic回归):比如购买的力度强弱,高、中、低等 logistic回归是一种将数据对数化处理后的分析方法,经过变换的logistic回归方程式如下: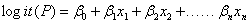
优点:应用广泛,掌握容易。 缺点:对回归系数的解释不直观,需要先做转换才能解释。(不过,如果是研究自变量对因变量的影响程度,可以直接对自变量之间的回归系数大小进行比较,不必再转换了。) 我们这里主要介绍并学习二分类(有或无)的回归方法。 举例分析: 1.1 建立回归模型
首先,从分析菜单进入,选择回归,选择二元logistic回归(这里的因变量只有两种情况,所以属于二分类,选择二元logistic,而不是看有几个自变量): 案例汇总这里是样本数量,使用了原始数据的1500条数据: 我们从块1开始看: 当然,这里的显著是和刚刚的块0——没有自变量的模型相比,非常显著,并不是自变量本身是否显著。 下面的模型汇总(此处的R2用于在多个模型间进行比较): 这个R2虽然很低,不要慌,因为这个不是用来直接读的数据,而是在多个模型之间进行比较的时候用的。 这里因为我们只有一个模型,所以这个R2值不看也可以。 如果有多个模型,多个R2值,就可以用来比较判断。 下面的分类表,我们看到的是模型的预测结果和观察结果的比较: 对于未续约的,我们的预测准确度是54.7%, 对于已续约的,模型的预测准确度是83.7%, 总体准确度73.1%, 说明模型的准确度整体还可以,对续约的预测的准确度更高: 接下来,模型建立起来了,我们可以像回归那样,进行预测。 在logistic回归的面板上选择保存,保存后才能出现预测值: Logistic公式一旦生成,还可以用于其他数据中,在刚刚的保存窗口中,可以将模型信息输出到XML文件。 然后,已知华北地区的商户信息,我们利用刚才保存的华南商户的公式来试验一下,打开华北商户.sav文件: 查看结果: 所以我们可以想办法,如果预测结果大于等于0.5,就令结果为1,如果小于0.5,就令结果为0,但是如何将很多小数点的数字转换为1和0呢? 此处只需要:在变量窗口将预测值的小数长度改为0即可—— |

 线性回归的解法是,求解最佳的a和b,令尽可能多的样本数据点(Xi,Yi)落在或者靠近这条拟合出来的直线上,我们一般用最小二乘法,令观察点和估计点的距离的平方和最小。
线性回归的解法是,求解最佳的a和b,令尽可能多的样本数据点(Xi,Yi)落在或者靠近这条拟合出来的直线上,我们一般用最小二乘法,令观察点和估计点的距离的平方和最小。
 然后在打开的对话框中,选择简单分布(默认),
然后在打开的对话框中,选择简单分布(默认), 
 这个数据的分布近似一条直线对,所以可以做一元线性回归分析,那接下来咱们就建立模型。
这个数据的分布近似一条直线对,所以可以做一元线性回归分析,那接下来咱们就建立模型。

 统计量窗口点开,主要确定回归系数和模型拟合度的前面有没有对勾。
统计量窗口点开,主要确定回归系数和模型拟合度的前面有没有对勾。  主要确保勾选在等式中包含常量。 然后点击继续,回到回归主面板。再次确定数据导入没有问题,执行step4,生成分析结果。
主要确保勾选在等式中包含常量。 然后点击继续,回到回归主面板。再次确定数据导入没有问题,执行step4,生成分析结果。 第一个表,是输入的变量,我们这里设置了一个变量,这个看看就行。 我们需要从下面这个模型汇总表格中判断这个线性模型的拟合程度:
第一个表,是输入的变量,我们这里设置了一个变量,这个看看就行。 我们需要从下面这个模型汇总表格中判断这个线性模型的拟合程度:  最后这个表格,我们要读出系数,常数项和系数项:
最后这个表格,我们要读出系数,常数项和系数项: 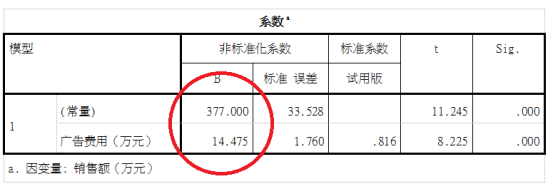 得到方程:
得到方程: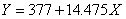 这个公式的拟合效果能达到0.666,等于模型已经建立起来了。
这个公式的拟合效果能达到0.666,等于模型已经建立起来了。 在弹出的保存窗口中,主要确保:预测值的第一项“未标准化”被勾选,然后选继续,返回主面板点击确定:
在弹出的保存窗口中,主要确保:预测值的第一项“未标准化”被勾选,然后选继续,返回主面板点击确定:  此时我们会在源数据右侧看到一列新生成的回归预测结果,通过看37行的pre值,就知道了2016年1月的预测销售额:
此时我们会在源数据右侧看到一列新生成的回归预测结果,通过看37行的pre值,就知道了2016年1月的预测销售额: 
 选择矩阵分布:
选择矩阵分布:  在弹出的散点图矩阵中,仅导入3个变量至矩阵变量中,其他选项保持默认设置:
在弹出的散点图矩阵中,仅导入3个变量至矩阵变量中,其他选项保持默认设置:  查看结果,从结果可直观判断存在线性相关关系。
查看结果,从结果可直观判断存在线性相关关系。 写论文的时候,可以借鉴这种散点图画法,就是装逼大法好。
写论文的时候,可以借鉴这种散点图画法,就是装逼大法好。 这次,在自变量窗口里面塞入新的变量,客流量:
这次,在自变量窗口里面塞入新的变量,客流量:  自变量加入方法可以选择:“逐步”(步进),
自变量加入方法可以选择:“逐步”(步进), 共7种方法。 实际上分为两大板块:
共7种方法。 实际上分为两大板块: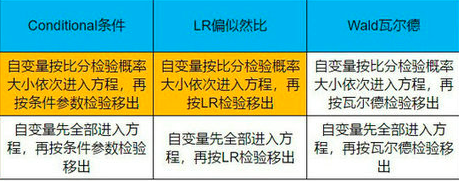
 以上是部分华南地区商户是否续约的数据,结果1代表续约,结果0代表不续约。
以上是部分华南地区商户是否续约的数据,结果1代表续约,结果0代表不续约。 在因变量窗口输入是否已经续约的结果,在协变量窗口导入三个因素:注册时长,营业收入和成本,导入方法还是选择进入,其他选项都按默认值来就可以:
在因变量窗口输入是否已经续约的结果,在协变量窗口导入三个因素:注册时长,营业收入和成本,导入方法还是选择进入,其他选项都按默认值来就可以:  结果分析:
结果分析: 这里和我们的理解一致,续约为1,未续约为0:
这里和我们的理解一致,续约为1,未续约为0: 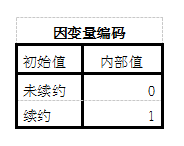 接下来从 块0:起始块 开始有3个表,可以无视,这部分是不包括自变量时候的模型拟合结果。
接下来从 块0:起始块 开始有3个表,可以无视,这部分是不包括自变量时候的模型拟合结果。 模型系数的综合检验,就是我们熟悉的p值,虽然不是F检验,但是判断方法是一致的,这里p(sig)<0.01,表示极其显著。
模型系数的综合检验,就是我们熟悉的p值,虽然不是F检验,但是判断方法是一致的,这里p(sig)<0.01,表示极其显著。 两个R方值和我们前面做回归的时候一样,是用来判断模型拟合程度的,依然是越接近1越好,用哪个值都可以,两个数据都看也可以。
两个R方值和我们前面做回归的时候一样,是用来判断模型拟合程度的,依然是越接近1越好,用哪个值都可以,两个数据都看也可以。 最后,看一下模型的样子——方程中的变量,这个表中的sig值才是变量的p值,从这个变量看,每个变量都显著影响:
最后,看一下模型的样子——方程中的变量,这个表中的sig值才是变量的p值,从这个变量看,每个变量都显著影响: 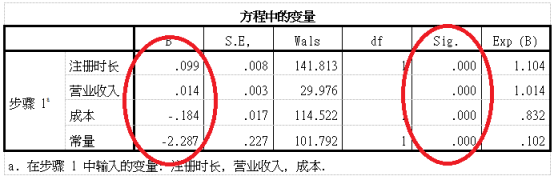 左边红圈是系数,写成公式为:
左边红圈是系数,写成公式为: 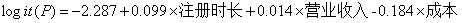 而我们刚刚说过,logistic回归的表达式不好解释,因为真正的原始表达式,把因变量值也放进去是这样的:
而我们刚刚说过,logistic回归的表达式不好解释,因为真正的原始表达式,把因变量值也放进去是这样的: 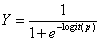 上面那串长长的公式都在分母的某个位置上,所以我们直接通过公式观测结果有点麻烦,但是如果有多个变量,我们还是可以通过它的系数大小来比较哪个自变量影响大。
上面那串长长的公式都在分母的某个位置上,所以我们直接通过公式观测结果有点麻烦,但是如果有多个变量,我们还是可以通过它的系数大小来比较哪个自变量影响大。 在保存的选项上,预测值的概率前面画勾,我们前面说过,logistic是个概率预测模型:
在保存的选项上,预测值的概率前面画勾,我们前面说过,logistic是个概率预测模型:  然后预测值就会出现在表格中啦
然后预测值就会出现在表格中啦 找到你的模型,点击下一步:
找到你的模型,点击下一步: 
 预测值画勾,选择完成:
预测值画勾,选择完成:  这样,华北商户的预测结果也有了。
这样,华北商户的预测结果也有了。 PRE—1列表示预测的概率,越接近1,表明是可以继续续约的,越接近0,表明不续约。
PRE—1列表示预测的概率,越接近1,表明是可以继续续约的,越接近0,表明不续约。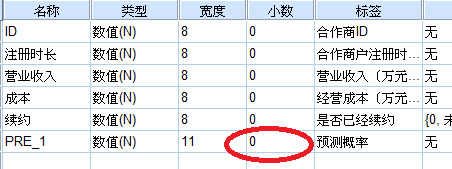 这样就是1和0啦:
这样就是1和0啦:  课后作业: 这里有一份西瓜数据集,也是机器学习的精典数据集之一,判断是好瓜还是不好的瓜,有很多标准,那么哪些标准更好用呢,用logistic分类和你今天学过的知识来试验一下吧。
课后作业: 这里有一份西瓜数据集,也是机器学习的精典数据集之一,判断是好瓜还是不好的瓜,有很多标准,那么哪些标准更好用呢,用logistic分类和你今天学过的知识来试验一下吧。【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |