机器学习:回归预测连续与离散的深度剖析 |
您所在的位置:网站首页 › 离散节点的种类 › 机器学习:回归预测连续与离散的深度剖析 |
机器学习:回归预测连续与离散的深度剖析
|
文章目录
回归的预测完整过程前提:1.线性回归与非线性回归概念(1):什么是回归(regression)?(2):什么是线性(linear)?
一:建立回归方程1.简单回归---多项式回归---非线性回归简单回归多项式回归非线性回归
二:检验回归方程代价函数:1.最小二乘法----均方误差函数(Mean Squared Error)2.极大似然估计法----交叉熵代价函数(Cross Entry)
代价函数的极值:1.梯度下降法梯度下降优点:梯度下降缺点:2.正规方程
PS:正规方程和过拟合下次写把,未完待续。
回归的预测完整过程
前提:
1.线性回归与非线性回归概念
要解释线性回归和非线性回归首先我们要理解这两个词 (1):什么是回归(regression)?由于是外国人命名的,我们找其根源只能从英文单词开始入手,regression的词根有重复的意思 统计学家在很久以前对于一些混乱的,看似无规律的,复杂的家族之间身高的数据中,不断统计提取,发现了一些规律,父亲身高高的,孩子的身高趋于下降,父亲身高矮的,孩子的身高趋于上升,最终发现个人的身高往往趋近于整个种群的身高平均值,仿佛自然有种约束力,将一切数值回归于某一个值。我们把那个平均值认为是无序数据之间遵循的一种规律。 这是被称之为回归的原因。 而回归的目的就是要在看似无规律的数据中找到其相互变量之间的约束规则的过程。 因此我们把关注点放在如何找到无序数据的均值上,找到均值意味着就找到了规律。 根据小学知识,我们很明白,均值的求法即为对每个变量求和再除以变量的个数 即:(x1+x2+x3+……+xn)/n--------得到均值y。 但是现实生活中。往往各个变量或者说各个影响结果的特征因素的权重是不一样的 因此我们将公式改写为:y = w0 + w1x1 + w2x2 + w3x3 + w4x4 + w5x5 + w6x6 使变量之间的权重系数各不一样以此来模拟现实。 这就是多元回归方程。 显然,若是只有一个x1特征,那么就是一元回归。 (2):什么是线性(linear)?我查了维基,线性这个词对于线性回归方程来说,不是指的特征,而是指的参数theta。 所以y = ax + b 和 y = ax^2 + b 对于这两个方程来说都为线性回归方程。 原因很简单,多项式的特征也可以写成y = w0 + w1x1之类的形式,本质是一样的 而那什么是非线性的呢, 非线性不是由简单的加法和乘法组成,类似之后要讲的 logistic回归(sigmoid函数): f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1
一般来说,回归问题会通常会用以上3种方式来建立模型,前两者属于线性回归 简单回归当问题比较简单时,我们通过多元一次项线性回归来拟合数据规律,根据特征个数不同其结果可能是一条直线,一个平面,一个超平面。 然而有的时候数据并不是我们想象的那样单纯且简单,它可能和特征的平方或者三次方的关系更为密切,为了更好的拟合数据,我们需要的是曲线或者曲面或者超曲面。
我们从泰勒公式可知:低阶决定形状,高阶决定细节,理论上来讲任何函数都可以通过多项式来进行拟合,只需要不断增加高次项,增加其细节。 但是有些很明显,高次项太多就会使特征值不断增加,导致最后模型异常复杂甚至出现了过拟合的现象(结尾给出解释),如果像一些傅里叶函数本身就有特殊的非线性关系,此时我们需要用非线性回归来建立模型。 二:检验回归方程以上我们了解了当我们对数据进行规律寻找时,需要建立回归方程的模型以此来拟合数据。 显然,我们也需要一套用来检验模型是否能准确预测和评判模型与模型之间的好坏的标准。 通常我们的代价函数,最常用的有两种 均方误差代价函数(Mean Squared Error) 交叉熵代价函数(Cross Entry) 代价函数: 1.最小二乘法----均方误差函数(Mean Squared Error)统计学最常用的权衡标准均方误差是回归模型中最常用的性能度量。用真实值与预测值之差的平方和来判别,显然均方误差越小,其模型就越准确。 此方法类似于欧式距离法,几何意义的角度为:计算所有样本到直线上的欧式距离之和达到最小。 以最简单的一元线性回归:y = bx + a为例 函数表达式: M S E = 1 N ∑ i = 1 N ( y ( i ) − f ( x ( i ) ) ) 2 MSE=\frac{1}{N}\sum_{i=1}^N(y^{(i)}-f(x^{(i)}))^2 MSE=N1i=1∑N(y(i)−f(x(i)))2 我们将这类通过计算所有样本误差最小值来检验模型的函数称为叫代价函数 当MSE值损失最低,则模型最准确。 我们需要挑选使MSE值降为最低的模型来作为我们的最佳线性回归模型。 PS:仅作为理解,事实上并不是最低就是最佳模型,之后的篇幅还需要考虑过过拟合的情况 2.极大似然估计法----交叉熵代价函数(Cross Entry)我们之所以会换方法是因为均方误差函数往往是一个非凸函数,对于求解全局最小值很麻烦, 而交叉熵代价函数是一个凸函数。所以这是一个非凸转化为凸函数的问题。 此方法用于神经网络深度学习和logistic回归中。 这里我们暂时不讲对数回归,在之后的篇幅里我们再细讲。我们先记住它的公式 梯度下降法的原理异常简单: 即对代价函数这个多元函数对其每个特征求偏导以此得到当前状态的该特征方向的梯度值,即最大下降值,并对该值乘以一个步长,即学习率,并将每个特征值同步更新后完成了一次迭代,当不断的迭代之后,就可以获得局部或者全局极小值。 说人话就是,当你在山上下山时,每走一步判断此时下山的斜率是不是达到了最大,达到则走一步,不断走之后便会以最快的速度达到山脚下。 我们当这一次迭代值与上一次做差来确定一个阈值,小于阈值就可以结束迭代了。 牛顿法则是通过二阶收敛来求解目标函数一阶导为零的参数值,方法是目标函数的Hessian矩阵的逆矩阵,这个我们之后的篇幅细讲。 梯度下降优点:当特征值n的规模很大时,梯度下降仍能很好的运行。 梯度下降缺点:当你选择的步长太长时,你很有可能会错过最小值,而你步长选的太短时又会迭代速度慢,导致以很慢的速度求到最小值。 极端点说就是你的步子太大,一下山头走到了另一个山头,步子太小,你走一年才能走到山下。 2.正规方程公式: θ = ( X T X ) − 1 X T y ⃗ θ=(X^TX)^{-1}X^Ty\vec{} θ=(XTX)−1XTy PS:正规方程和过拟合下次写把,未完待续。 |
 傅里叶函数:
θ
1
∗
c
o
s
(
X
+
θ
4
)
+
θ
2
×
c
o
s
(
2
∗
X
+
θ
4
)
+
θ
3
θ_1 * cos(X + θ_4) + θ_2 \times cos(2 * X + θ_4) + θ_3
θ1∗cos(X+θ4)+θ2×cos(2∗X+θ4)+θ3
傅里叶函数:
θ
1
∗
c
o
s
(
X
+
θ
4
)
+
θ
2
×
c
o
s
(
2
∗
X
+
θ
4
)
+
θ
3
θ_1 * cos(X + θ_4) + θ_2 \times cos(2 * X + θ_4) + θ_3
θ1∗cos(X+θ4)+θ2×cos(2∗X+θ4)+θ3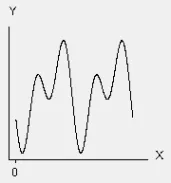 此些都为非线性回归方程。区分也非常简单,只要你记住了线性方程的结构,其他均是非线性,反推即可。
此些都为非线性回归方程。区分也非常简单,只要你记住了线性方程的结构,其他均是非线性,反推即可。



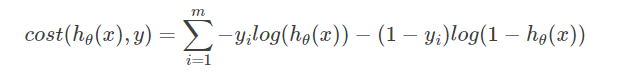 是通过概率满足伯努利分布,列似然函数,求极大似然值,对其对数=0 求导方程得出结果。 之后讲logistic回归时我们会细细推导。
是通过概率满足伯努利分布,列似然函数,求极大似然值,对其对数=0 求导方程得出结果。 之后讲logistic回归时我们会细细推导。 迭代的公式:
θ
j
=
θ
j
−
α
ð
ð
θ
j
J
(
θ
0
,
θ
1
)
θ_j=θ_j-α\frac{ð}{ðθ_j}J(θ_0,θ_1)
θj=θj−αðθjðJ(θ0,θ1)
迭代的公式:
θ
j
=
θ
j
−
α
ð
ð
θ
j
J
(
θ
0
,
θ
1
)
θ_j=θ_j-α\frac{ð}{ðθ_j}J(θ_0,θ_1)
θj=θj−αðθjðJ(θ0,θ1)【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |