Transformer神经网络学习笔记 |
您所在的位置:网站首页 › 神经网络输入输出长度不一致的原因 › Transformer神经网络学习笔记 |
Transformer神经网络学习笔记
|
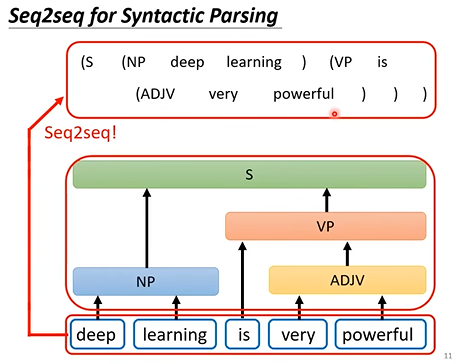
(笔记参考来源:强烈推荐!台大李宏毅自注意力机制和Transformer详解!_哔哩哔哩_bilibili) Transformer:一个Seq2Seq的模型,输入一段序列,输出一段序列,输出长度未知,由机器自己决定。常见的应用有语音识别(输出的文字长度不确定),机器翻译,语音翻译,语音合成,聊天机器人训练等。多数NLP(Nature Language Processing,自然语言处理)的问题可以通过seq2seq来解决。Transformer的泛用性很高,但往往一些为特定任务特制的模型能获得更好的结果。 Seq2Seq模型还可以处理树状结构:将树关系用括号来表示,转化为序列。
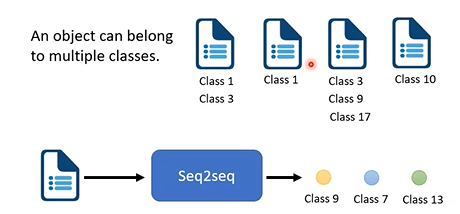
多标签分类也可以用Seq2Seq模型:对象可能同时拥有多个标签,即同时属于多个类;这种分类标签数目不确定的问题也可以用Seq2Seq解决。此外,图像中的对象识别也可以用Seq2Seq解决(有关对象识别可以参考之前的这篇笔记End-to-End Object Detection with Transformers 论文解读笔记_寒雪zhi冬的博客-CSDN博客)
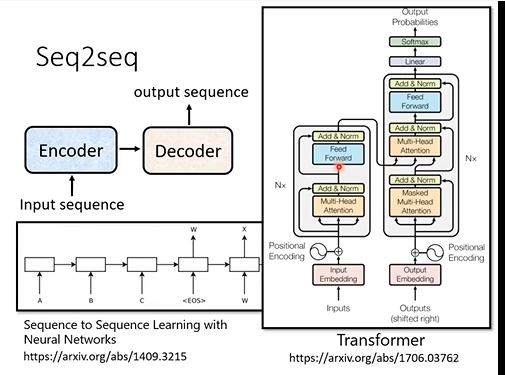
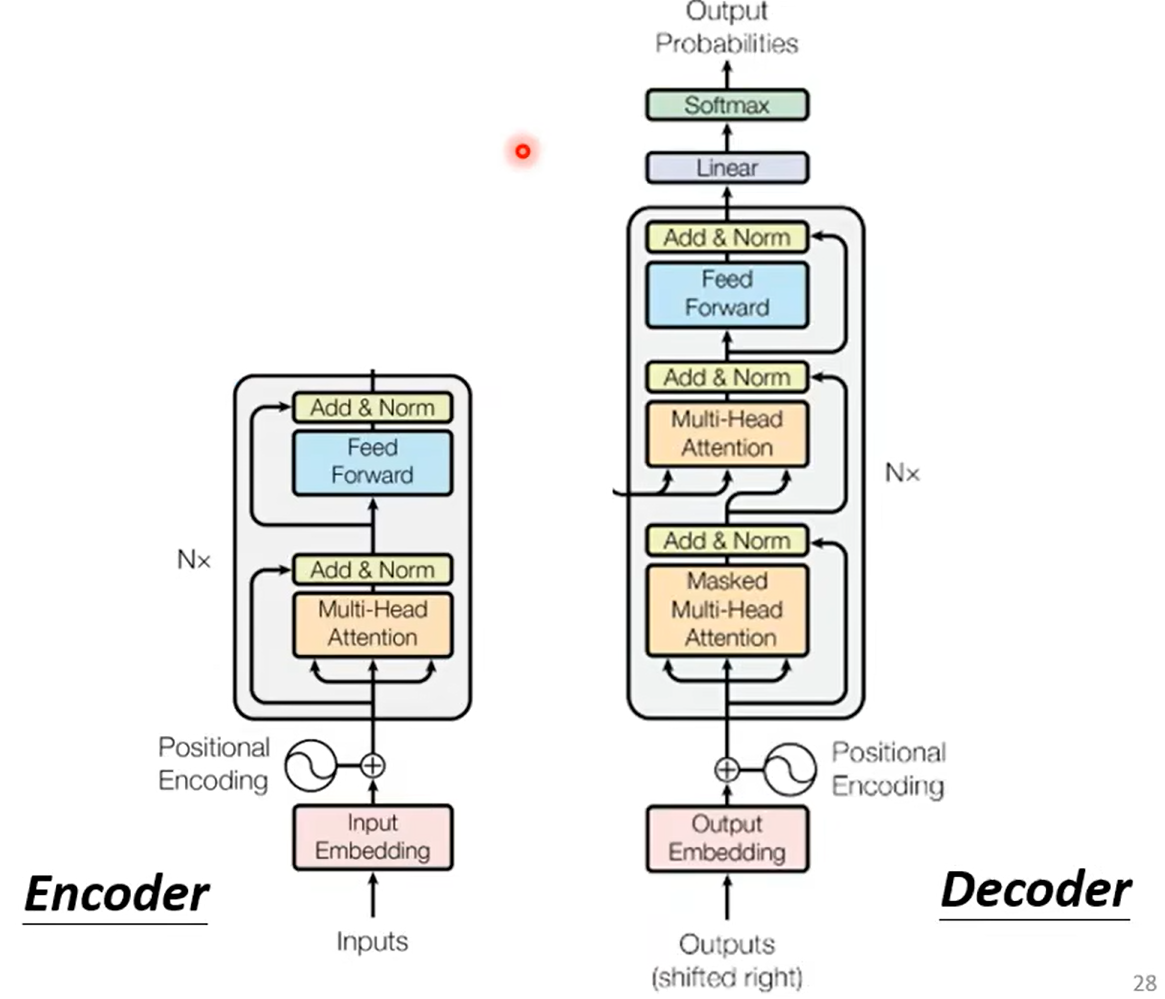
Seq2Seq模型:其主要结构是一个编码器-解码器结构。Transformer是其中比较有名的。
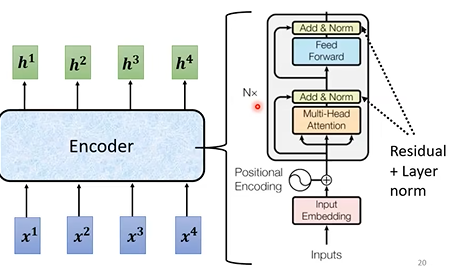
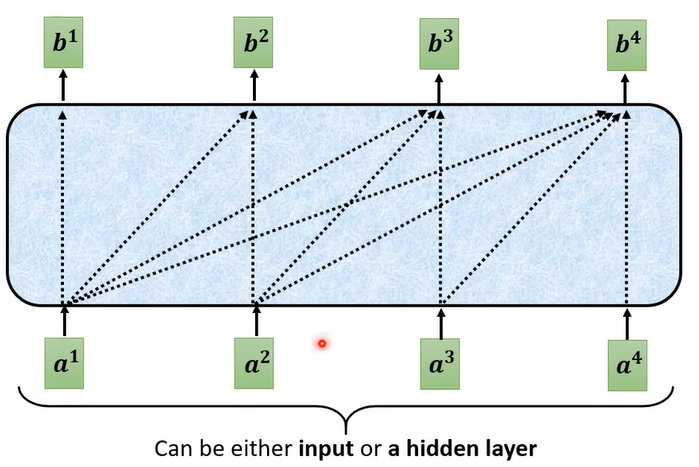
Encode的目标:输入一串向量序列,输出一串同样长度的向量序列。这有很多方法实现,如RNN和self-attention等。Transformer用的self-attention。
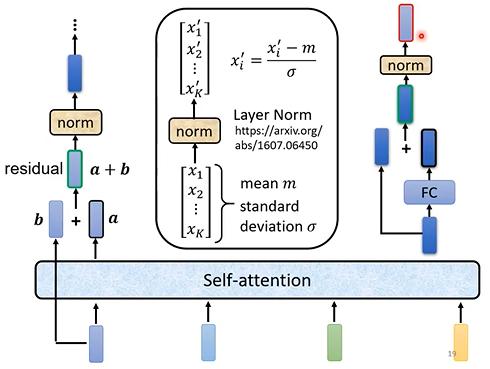
Decoder:由多个Block串联组成,同样输入一串向量输出一串向量,每个block其主要结构同样是self-attention,其结构如下图,它用到了residual connection,layer normalization和全连接层。大体顺序是Self-attention->residual connection->layer normalization->full connection->resudual connection->normalization
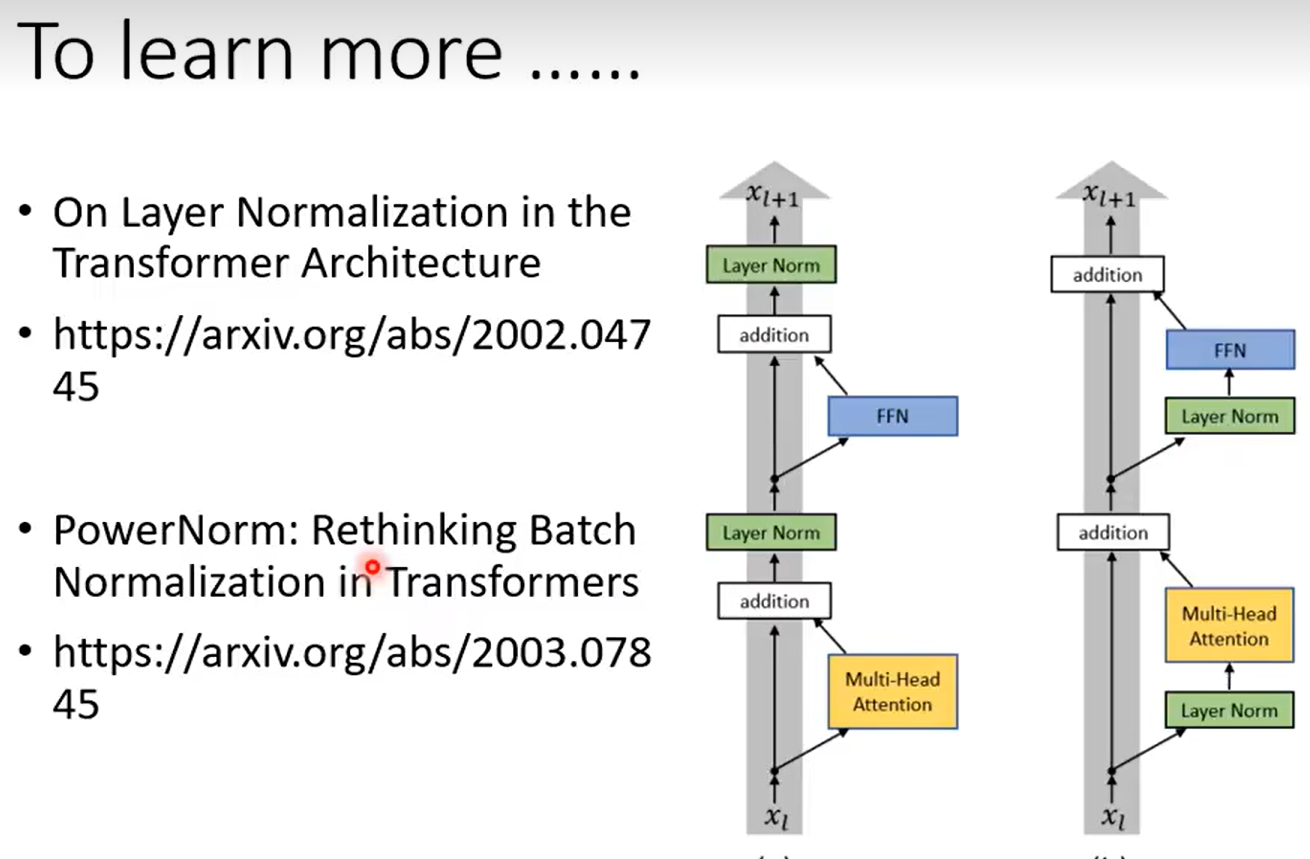
下面两篇文章第一篇提出了一种改进,而第二篇则提供了为什么不用batch normalization的原因(有关Layer Normalization和Batch Normalization的区别可以见这篇文章:详解Layer Normalization和Batch Normalization - 知乎)
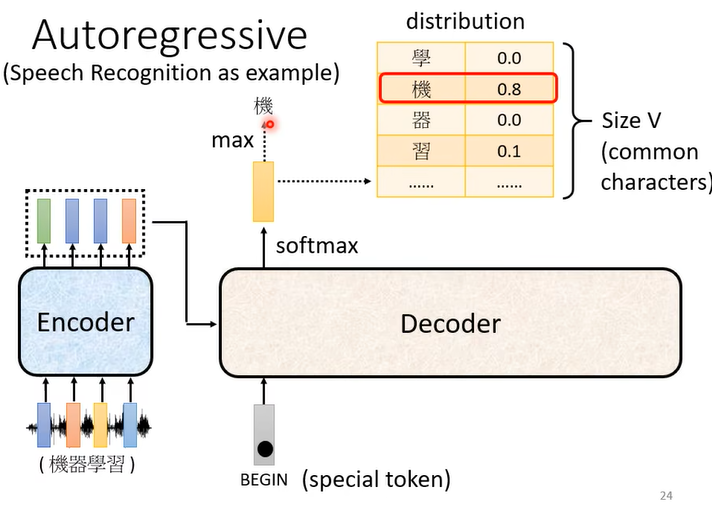
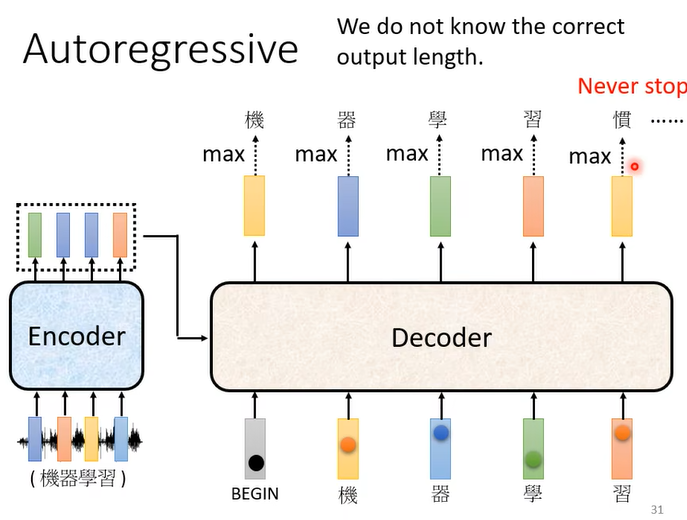
Autoregreessive decoder:以语音文字转化为例,通过Encoder将一段声音序列转化为一段向量序列。在decoder中,则是判断每个向量分属于文字表中不同文字的概率。
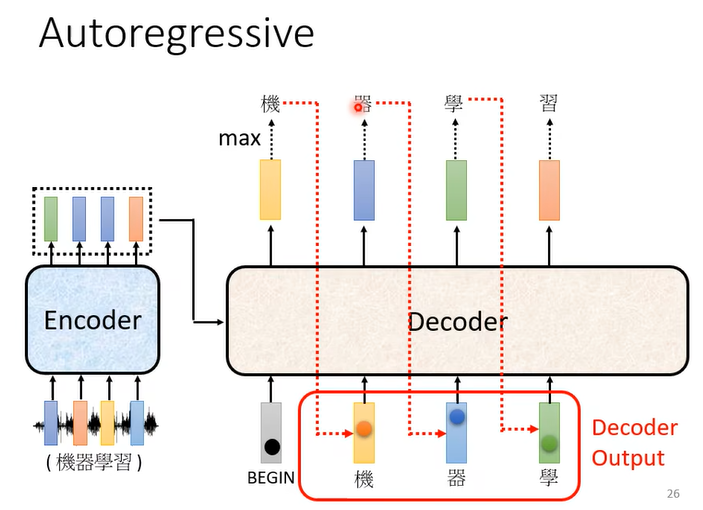
这种decoder会将上一位的输出和encoder的所有输出同时输入到decoder中以获得这一位的输出。其第一位输入是一个特殊符号begin。这种的问题就是上一位的输出可能是错误的,而这会导致接下来的输出连锁地出现错误,这也是autoregressive的缺点。
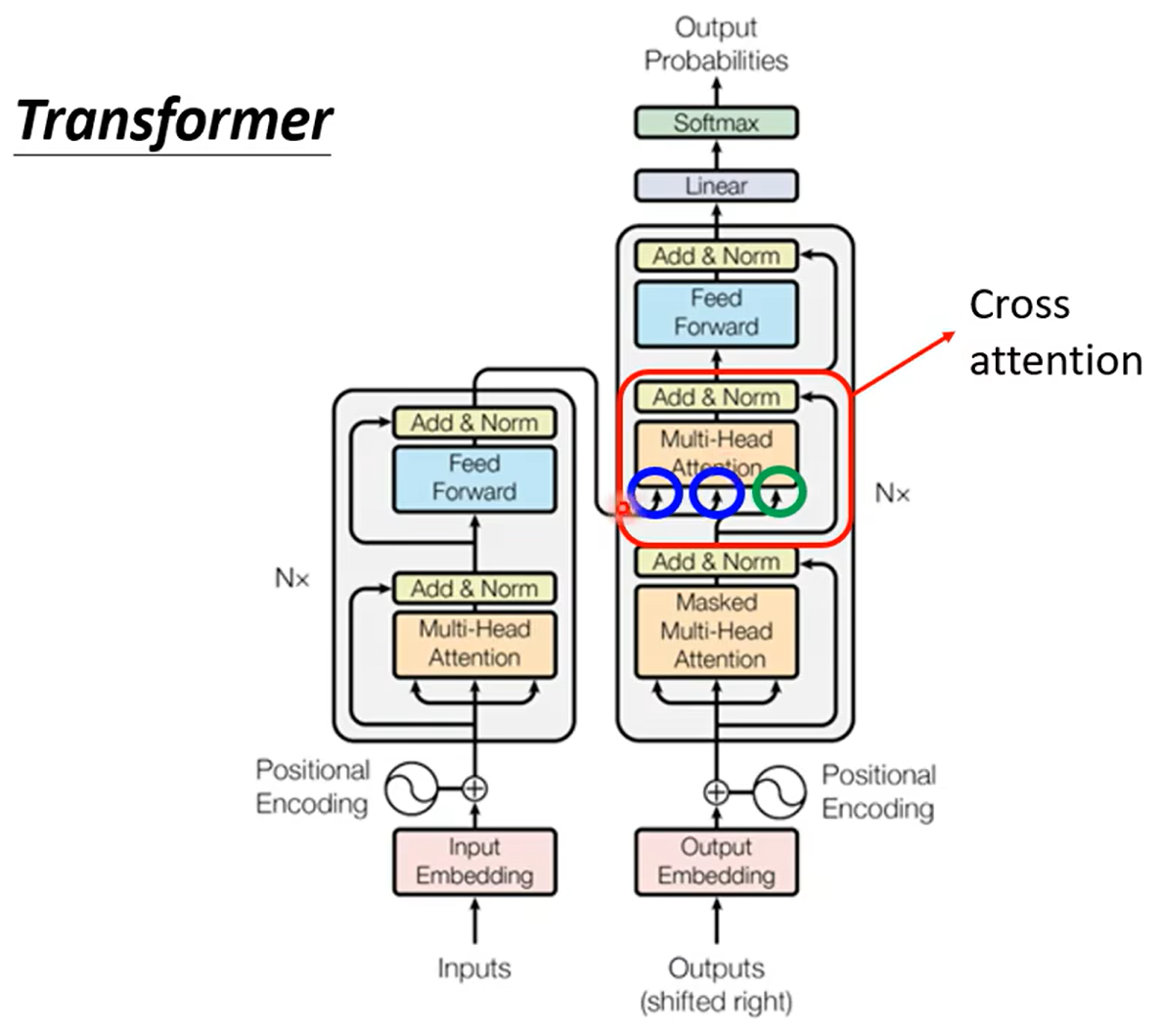
encoder和decoder的差异:decoder多出了一块多注意力输出。此外,decoder首先处理的方式是masked multi-head attention,它和传统的self-attention的区别是某一向量对应的输出只会考虑之前序列的输入。这是因为masked multi-head attention其本质是预测,即根据之前的输入和现在的数据预测输出的结果。而未来的数据虽然存在,但对decoder处理的当前时间点的数据来说是“不存在”的,而这种“预测”的输出模式这也是masked multi-head attention能输出长度不定的数据的基础。
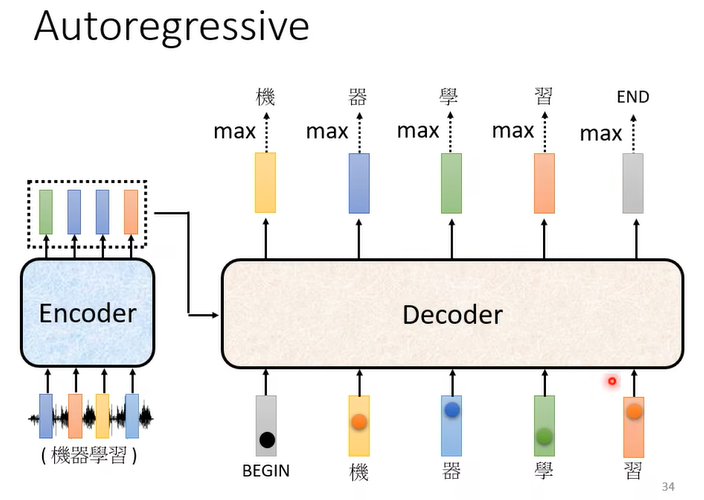
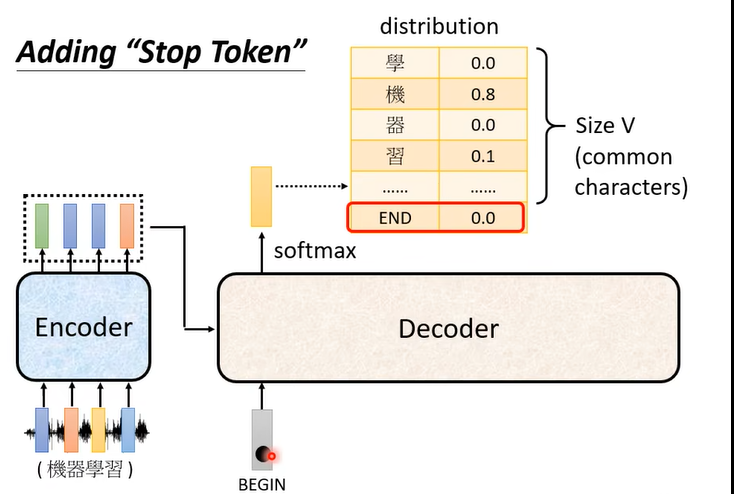
而这种decoder最大的问题就是:输出结果什么时候停止是不确定的。因此在文字表中,需要一个特殊的符号表示结束,当这个符号输出时表示停止输出。
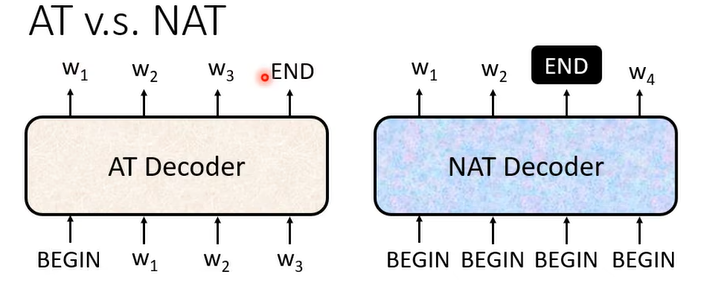
Non-autoregressive decoder:NAT会根据输入的begin项数(每个begin会包含不同的位置信息和语音片段)和编码器的输入一次产生整个输出结果。这种做法的问题是无法确定输出的长度,即输入多少个begin合适。一个解法是另开一个预测器来预测输出的长度。另一个做法是设定一个输出上限,而在输出end的后面的内容当做不存在。
NAT的好处是能并行计算,且输出长度是可控的。但目前NAT的表现效果比AT差。 Transformer:结构如下:
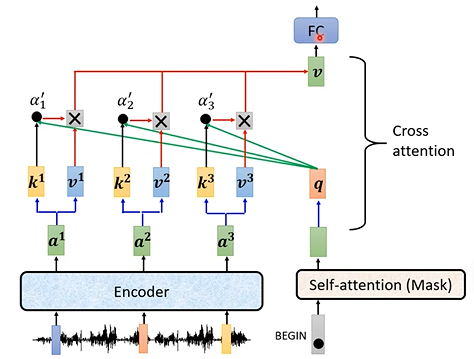
Cross attention的实现方式如下图:通过这种方式,机器可以查询到应当对输入中的哪个部分额外关注,从而输出正确的结果(有关cross attention详解:【科研】浅学Cross-attention?_cross attention_MengYa_DreamZ的博客-CSDN博客)。
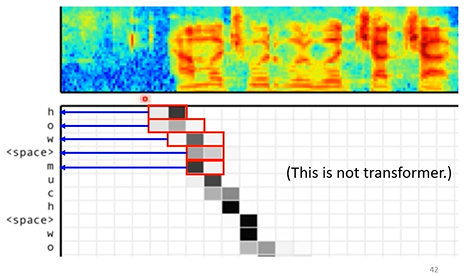
attention的可视化效果如下:上半部分为声音按时间轴分布的可视化,而下半部分为注意力的可视化,可以注意到随迭代次数增加,神经网络放在声音轴上的attention的重点也在不断前进(这还只是应用了cross attention而未用到transformer架构,这也证明了cross attention在AT Decoder里查询时间轴信息重点上的能力)。
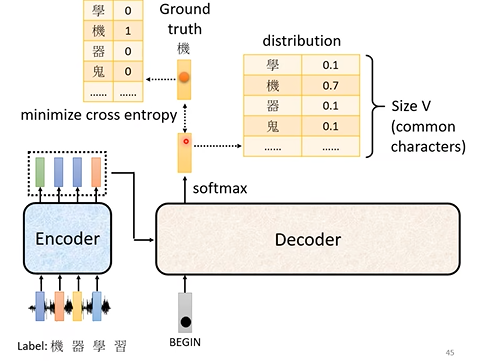
训练过程-以语音识别为例:语音识别需要语音及对应的文本。decoder的输出是一个文字表对应一个输入的机率的分布,而在groundtruth中,除了当前应当输出的文字概率为1外,其余都为0。而decoder的输出几率分布应当尽可能接近groundtruth的概率。这可以看做一个分类训练,因此可以通过最小化输出的cross entropy来训练。
注意:在训练过程中,decoder的输入是受控制的,即它每次迭代的输入并非来自上次迭代的结果,而是直接来自groundtruth。这种技术被称为Teacher Forcing。
一些实现细节:1.Copy Mechanism, 即当输入出现一些在训练过程中不常见或不存在的词时(如人名或术语等),机器要有能理解这些词性并复制整个词用于输出的能力。即在整个decoder的迭代过程中,其每次输出和输入并不一定是一个字或词,也可能是复制过来的句子中的一小段。这在Chat-bot或文章摘要提取等技术中非常常见。
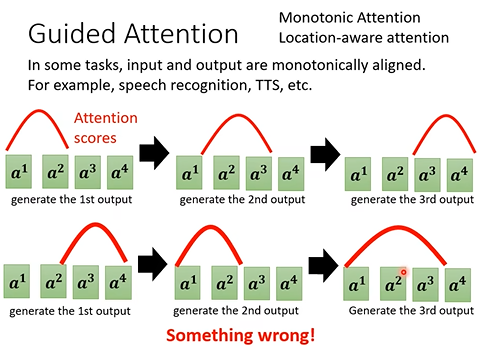
Guided Attention:输入到的一些内容由于注意力机制的问题并没有被机器学习到,这会导致输出出现问题。Guided Attention则是制定一些强制的限制使机器去有目的地学习(如强制规定attention的位置)。实现方式有Monotonic Attention,Location-aware attention等,这中技术常用于语音识别,TTS等领域。
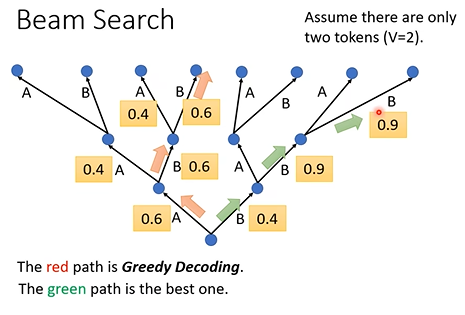
Beam Search:decoder的输出每次都是选择概率最大的一项,这种输出方式被称为Greedy Decoding。但这种局部选择方式在全局上看并不一定是最好的。而检测全部的选择路径也不现实。而Beam Search则是用于解决这个问题的。注意这项技术的效果并不稳定,一般用于答案非常明确的任务(如语音识别)。而一些涉及“创造力”的任务(如文章续写)加入随机性比使用beam search效果更好。
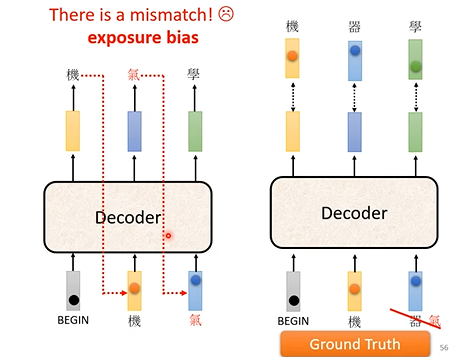
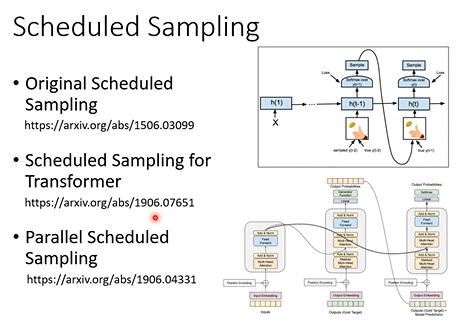
训练和测试方式不一致的问题(exposure bias):decoder在训练时只有正确输入,但在测试时却在一些迭代中会出现错误输入,这会连锁地影响decoder的输出。因此,在训练时有时有必要加入一些错误输入,这种训练技术被称为Scheduled Sampling。
|


【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |