机器学习 |
您所在的位置:网站首页 › 神经网络多元回归模型 › 机器学习 |
机器学习
|
之前写的线性回归,充斥了大量的公式,对于入门来说显得过于枯燥,所以打算重写这一部分,而了解了线性回归后,它又可以为我们解释深度学习的由来。 一、机器学习简述机器学习可以理解为计算机根据给定的问题及数据进行学习,并可根据学习结果解决同类型的问题。可以把机器学习比作一个函数,把我们已知的数据输入进去,预测出我们想要知道的信息:
接下来我们就从最简单的函数 — 线性函数开始。 (一)寻找合适的函数(模型)实际上,找函数的过程是较为主观的,因为它基于我们对当前任务是如何理解的。一般情况下,我们通常会根据数据分布的趋势决定函数类型。例如,从这样的一个数据集中,我们可以看出数据有沿右上方分布的趋势,所以可以用最简单的线性回归进行拟合:
在现实生活中,我们通常把预测值与实际值之间的差异叫做误差,这在机器学习中也同样适用。我们将使用模型计算出来的预测值 \(y\) 与实际值 \(\hat{y}\) 作比较,就可得到数据集中一个样本的误差。把所有样本的误差加总到一起,就得到了通过这个模型预测的总误差。在线性回归中,一般使用均方误差来统计总误差: \(\smash{L(w)} = \sum_{i=1}^{n}{(y_i - \hat{y_i})^2}\) 这个用来统计总误差的式子在机器学习中叫做损失函数,可以理解为通过这个模型预测,会在真实值的基础上损失多少。所以,损失值越小,代表这个模型的预测精度越高。
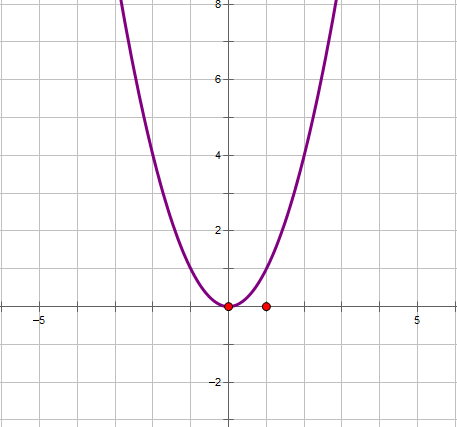
那如何求它的最小值呢?我们注意到,损失函数是一个二次函数,其图像是开口向上的,存在最小值。所以可以通过对损失函数求导求得最小值。
极值求出来后,就得到了可用于预测的模型,接下来要做的就是输入样本数据,得到样本的预测数据了。 (五)使用 sklearn 建立线性回归模型上面给出了求解最小值的数学公式,感兴趣的同学可自行编写代码实现。如果一看公式就头疼,也可以直接使用python封装好的 sklearn 包实现。通过调用该包,仅需几行代码就可实现。 1.绘制数据集样本首先我们画出数据集的样本分布情况: import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression # 样本特征数据 x = [10.0, 8.0, 13.0, 9.0, 11.0, 14.0, 6.0, 4.0, 12.0, 7.0, 5.0] # 样本标签 y = [8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68] # 转换成列向量 x = np.array(x).reshape(-1, 1) # 绘制散点图 plt.scatter(x, y, color='skyblue', marker='o', linewidth=1) plt.xlabel('X') plt.ylabel('Y')
在散点图的基础上,根据模型的训练结果,即可绘制出线性模型: # 画出原数据集散点图 plt.scatter(x, y, color='skyblue', marker='o', linewidth=1) # sklearn线性模型 regr_model = LinearRegression() # 训练模型 regr_model.fit(x, y) # 构造出一系列点,通过训练得出的斜率和截距画出拟合直线 xx = np.arange(4, 16) yy = regr_model.intercept_ + regr_model.coef_ * xx plt.plot(xx, yy, label='Linear Regression', color='red') # 设置label plt.xlabel('X') plt.ylabel('Y') plt.legend(loc=4)
有了模型,就可以对未知的数据进行预测了,我们分别对样本特征0, 1 进行预测: y_pred = regr_model.predict([[0], [1]]) print(y_pred) # 输出结果: [3.00009091 3.50018182]显然样本0的预测值就是直线在y轴上的截距。 二、线性模型能否模拟更复杂的图形?可以看出,线性回归非常直观且易于实现,同时也过于简单,只能适用于比较简单的模型,如果模型稍显复杂,则不能很好地反映数据的分布。
\(H(x) = \begin{cases} y_1, & x < {x_1}; \\ wx + b, & x_1 \le x \le{x_2}; \\ y_2, & x > x_2\\ \end{cases}\) 可以看出,当 \(x < {x_1}\) 或 \(x > x_2\) 时,函数值恒等于一个值,而当 \(x \in [x_1, x_2]\) 时,函数值则是呈线性变化的。该函数图像如下:
\(y = b + \sum_{i=1}^{3}H(w_i, b_i)\) 问题又来了,这种分段函数看着非常复杂,而且计算不方便,能否再使用一个近似的函数进行替换呢?于是这里又引入了 \(Sigmoid\) 函数:
\(y = b + \sum_{i=1}^{n}{c_iSigmoid(w_ix + b_i)}\) 这里 \(n\) 的大小,取决于我们要模拟多复杂的函数,n越大,意味着要模拟的函数越复杂。
对于我们的新模型 \(y = b + \sum_{i=1}^{n}{c_iSigmoid(w_ix + b_i)}\) 来说,可以看做是先进行线性计算,然后放入Sigmoid函数计算后,再加上常数b的过程。可用下图表示:
\( \bm{X} = \begin{pmatrix} x_1\\ x_2\\ x_3\\ \end{pmatrix} \quad \bm{W} = \begin{pmatrix} w_1\\ w_2\\ w_3\\ \end{pmatrix} \quad \bm{b} = \begin{pmatrix} b_1\\ b_2\\ b_3\\ \end{pmatrix} \quad \bm{C} = \begin{pmatrix} c_1\\ c_2\\ c_3\\ \end{pmatrix} \) 然后我们就可以用这些向量来表示模型的公式了: \(y = b + \bm{C}^T\sigma(\bm{W^T}\bm{X} + \bm{b})\) 使用这种表示方式,不仅显得更简洁,而且计算速度也非常快,特别是当样本非常多的情况下。 四、再次定义误差函数我们观察一下这个式子,其中只有\(\bm{X}\) 和 \(y\) 是已知的(数据集样本和标签),其他的参数都是未知的。我们的目标就是使用这个模型进行预测,所以要求出一组参数 \(\{b, \bm{C}, \bm{W^T}, \bm{b}\}\) ,使得模型总体的误差最小。感觉是不是很熟悉,这不就是之前线性回归里的套路吗?所以到了这里,就自然而然的想到了去求误差函数 \(L(\theta)\)。 因为模型的原型还是 \(y=ax+b\),所以这里就继续使用均方误差作为损失函数了(如果是逻辑回归,使用交叉熵会更加合适): \(L(b, \bm{C}, \bm{W^T}, \bm{b}) = \sum_{i=1}^{n}(y_i - \hat{y_i})^2\) 因为这些参数都是未知的,所以为了方便表示,就用一个参数 \(\theta\) 来统一表示: \(L(\bm{\theta}) = \sum_{i=1}^{n}(y_i - \hat{y_i})^2 \quad (\bm{\theta} = \begin{pmatrix} b\\ \bm{C}\\ \bm{W^T}\\ \bm{b} \end{pmatrix})\) 接下来又到了求解损失函数 \(L(\bm{\theta})\) 极值的环节了。 五、非线性函数的极值求解 - 梯度下降法线性函数由于模型简单,可直接通过令一阶导数为0求出最优解。但是 \(Sigmoid\) 函数从图像上就可以看出不是线性函数,直接通过求导计算将变得非常复杂。所以这里使用一种工程上常用的一种近似方法 — 梯度下降法进行近似求解。
首先要声明的是,函数必须属于凸函数,才能使用梯度下降法(有关凸函数的证明,可以参考之前的这篇文章)。凸函数图像是开口向上的,所以总能找到最优解:
\(\bm{\theta_1} = \bm{\theta_0} - \nabla L(\bm{\theta_0})\) 其中,\(\nabla L(\theta_0)\) 表示损失函数在 \(\theta_0\) 处的梯度。又因为梯度为函数在该点的一阶导数,所以也可以写为: \(\bm{\theta_1} = \bm{\theta_0} - \frac{\partial{L(\bm{\theta_0})}}{\partial{\bm{\theta_0}}}\) 为了让整个过程可控,同时可处理一些极端情况(例如类似倒三角的图像,斜率很大,很有可能错过最低点),所以在此基础上加入了超参数 \(\eta\) (就是可人为设置的参数): \(\bm{\theta_{n+1}} = \bm{\theta_n} - \eta\frac{\partial{L(\bm{\theta_n})}}{\partial{\bm{\theta_n}}}\) 所以,对 \(\bm{\theta}\) 进行足够多次的更新,就能让误差接近最小值,从而得到模型。更新多少次,取决于当前可用的资源。 六、总结我们从最简单的线性回归开始,为了模拟更加复杂的情形,构造了一系列的函数及参数,最终把我们领向了深度学习中的神经网络。至此,我们发现,机器学习有着明显的“套路”:首先需要找到一个能够描述数据集的模型;然后再找到一个能够描述误差的式子;最后对整个误差的式子求极值即可。所以,机器学习看起来也不是那么难,有时候只是缺一个通俗易懂的解释。 注:本文引用了《李宏毅机器学习》里Lecture 1 里的部分内容,对此感兴趣的同学有时间的话还是建议看一看,讲得很生动,也很有激情(B站链接在此)。 |
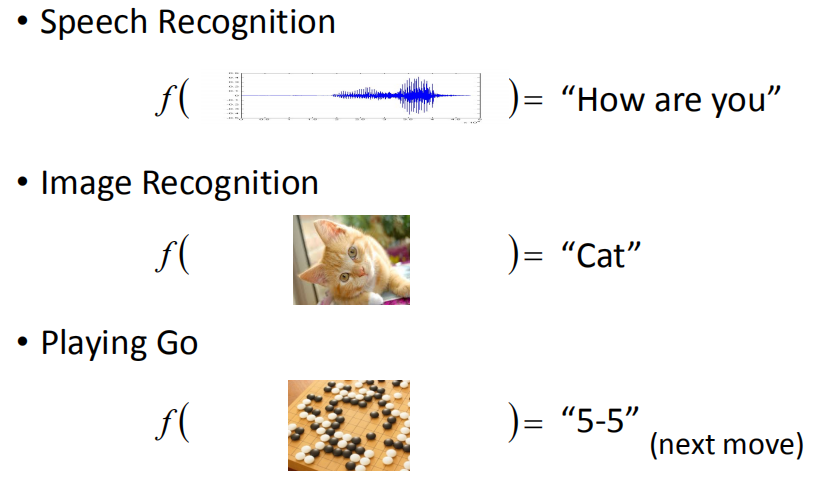 其中,我们把特定的问题叫做任务,输入的数据叫做数据集(数据集内部又分为样本和标签),学习结果叫做函数(或者模型)。
所以,我们的任务就是要找到一个这样的函数,能够在特定的场景下尽可能准确地预测,从而指导我们的决策。
其中,我们把特定的问题叫做任务,输入的数据叫做数据集(数据集内部又分为样本和标签),学习结果叫做函数(或者模型)。
所以,我们的任务就是要找到一个这样的函数,能够在特定的场景下尽可能准确地预测,从而指导我们的决策。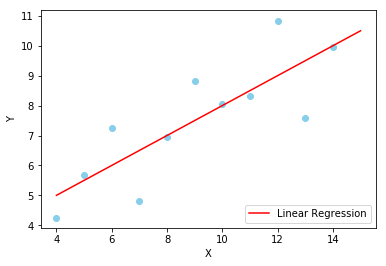 在这种情况下,函数为一元二次,可令:\(y = wx + b\) ,其中 \(x\) 为数据集样本,\(y\) 为对应的样本标签。
但是,我们也可以选择其他函数进行拟合,假如我觉得曲线函数能更好地描述数据分布,那么也可以用曲线函数进行拟合:
在这种情况下,函数为一元二次,可令:\(y = wx + b\) ,其中 \(x\) 为数据集样本,\(y\) 为对应的样本标签。
但是,我们也可以选择其他函数进行拟合,假如我觉得曲线函数能更好地描述数据分布,那么也可以用曲线函数进行拟合:
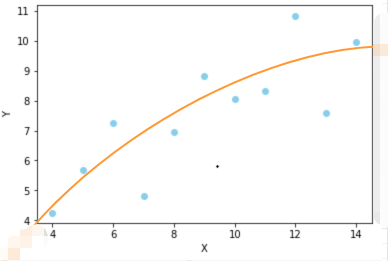 但是,无论我们使用哪个函数,都是对已知数据的拟合,而我们的目标是为了能够尽可能准地预测未知的数据,所以需要有一个标准来衡量所选函数的性能(函数在机器学习中也叫做模型)。
但是,无论我们使用哪个函数,都是对已知数据的拟合,而我们的目标是为了能够尽可能准地预测未知的数据,所以需要有一个标准来衡量所选函数的性能(函数在机器学习中也叫做模型)。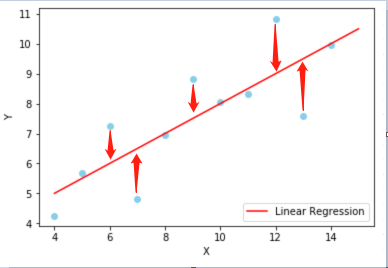
 \(\begin{align*}
\frac{\partial{L(w)}}{\partial{w}} &= 2\sum_{i=1}^{n}{(y_i - \hat{y_i})\frac{\partial{y_i}}{\partial{w}}}\\
&= 2\sum_{i=1}^{n}{(y_i - \hat{y_i})x_i}\\
&= 2\sum_{i=1}^{n}{(wx_i + b - \hat{y_i})x_i}
\end{align*}\)
\(\begin{align*}
\frac{\partial{L(w)}}{\partial{w}} &= 2\sum_{i=1}^{n}{(y_i - \hat{y_i})\frac{\partial{y_i}}{\partial{w}}}\\
&= 2\sum_{i=1}^{n}{(y_i - \hat{y_i})x_i}\\
&= 2\sum_{i=1}^{n}{(wx_i + b - \hat{y_i})x_i}
\end{align*}\)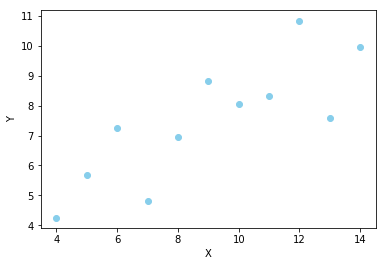
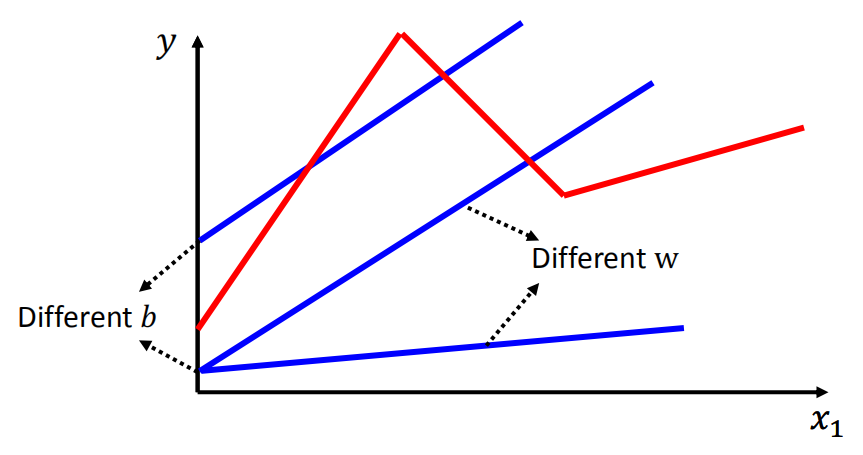 例如在该图中,红色线段为我们想要拟合的图形,蓝色线段为我们的线性回归模型,无论怎样调整斜率 \(w\) 或截距 \(b\),都无法与红色较好地匹配。说明在此例中,线性函数模型过于简单,我们需要一个稍微复杂一些的模型。这里我们引入一个分段函数作为模型:
例如在该图中,红色线段为我们想要拟合的图形,蓝色线段为我们的线性回归模型,无论怎样调整斜率 \(w\) 或截距 \(b\),都无法与红色较好地匹配。说明在此例中,线性函数模型过于简单,我们需要一个稍微复杂一些的模型。这里我们引入一个分段函数作为模型: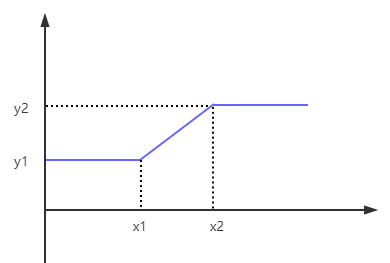 所以如果用这个分段函数来模拟上面的红色线段的话,可以采用下面几个步骤:
所以如果用这个分段函数来模拟上面的红色线段的话,可以采用下面几个步骤:
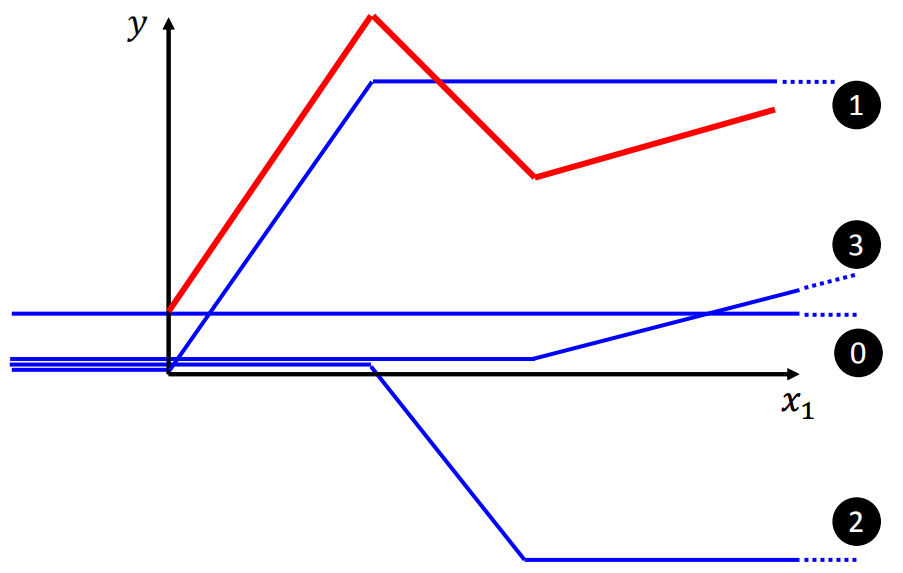 step 0:取常数 \(b\) 作为红色线段在 \(y\) 轴上的截距;
step 1:令分段函数中间部分的斜率和长度与红色线段第一部分相同(\(w_1, b_1\));
step 2:令分段函数中间部分的斜率和长度与红色线段第二部分相同(\(w_2, b_2\));
step 3:令分段函数中间部分的斜率和长度与红色线段第三部分相同(\(w_3, b_3\))。
所以红色线段可用几个不同的蓝色线段表示为:
step 0:取常数 \(b\) 作为红色线段在 \(y\) 轴上的截距;
step 1:令分段函数中间部分的斜率和长度与红色线段第一部分相同(\(w_1, b_1\));
step 2:令分段函数中间部分的斜率和长度与红色线段第二部分相同(\(w_2, b_2\));
step 3:令分段函数中间部分的斜率和长度与红色线段第三部分相同(\(w_3, b_3\))。
所以红色线段可用几个不同的蓝色线段表示为: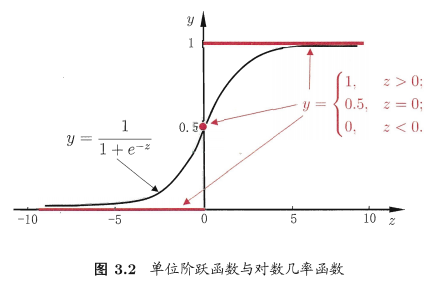 \(Sigmoid\) 函数可以很好的表现上面的蓝色线段,而且是非线性的,没有线性的那么直(或者说hard),所以也把上面蓝色的图形叫做hard sigmoid。
于是,我们的模型又等价于:
\(Sigmoid\) 函数可以很好的表现上面的蓝色线段,而且是非线性的,没有线性的那么直(或者说hard),所以也把上面蓝色的图形叫做hard sigmoid。
于是,我们的模型又等价于: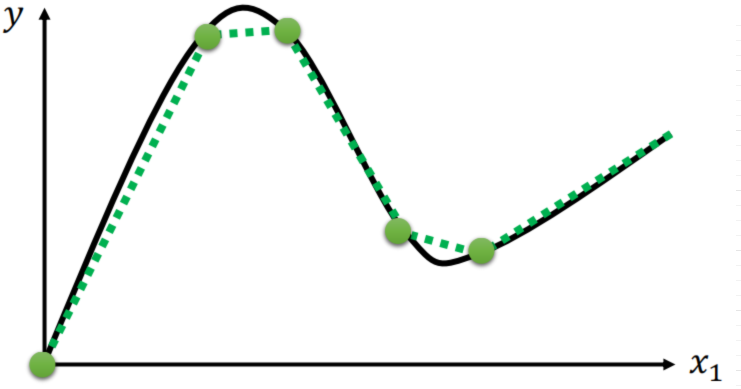
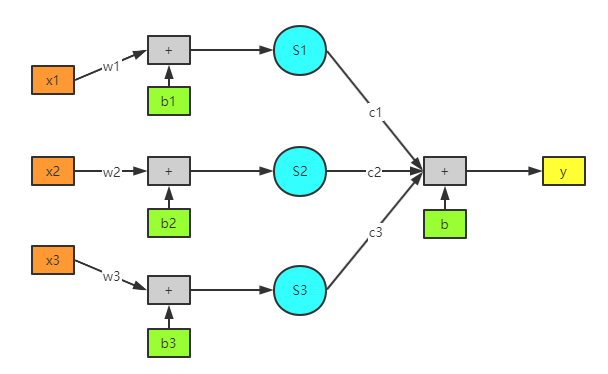 如此一来,原本稍显繁琐的公式一下子就显得直观了不少。而且整个图看起来与神经网络非常相似,线性函数 \(wx+b\) 为输入层,\(Sigmoid\) 可看做隐藏层,加总后的y可看做输出层。如果让模型变得更复杂点,就更像了:
如此一来,原本稍显繁琐的公式一下子就显得直观了不少。而且整个图看起来与神经网络非常相似,线性函数 \(wx+b\) 为输入层,\(Sigmoid\) 可看做隐藏层,加总后的y可看做输出层。如果让模型变得更复杂点,就更像了:
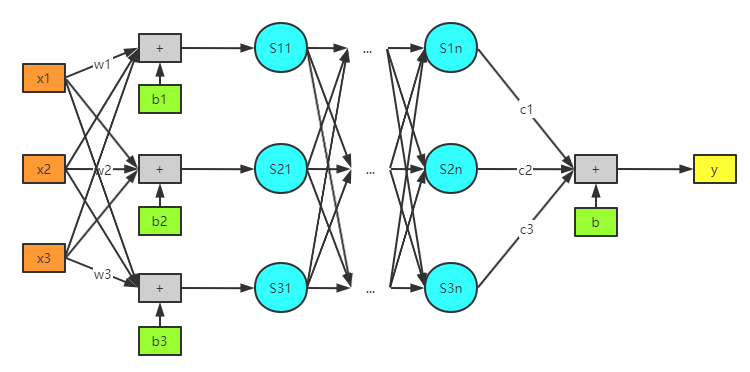 这里,我们增加了输入样本的复杂度(由单一连接变成了全连接),并且增加了多层 \(Sigmoid\) 函数,虽然模型整体更加复杂,但本质上还是没有变。所以我们完全可以从一个简单的线性模型过渡到一个复杂的神经网络。
再来看公式,看到这个加总符号 \(\sum\),就说明里面进行的都是一系列相似的计算,所以用向量替换比较合适。
如果先约定好,统一使用列向量来表示数据,并使用 \(\sigma(x)\) 表示 \(sigmoid\) 函数,则以上数据及参数可表示为:
这里,我们增加了输入样本的复杂度(由单一连接变成了全连接),并且增加了多层 \(Sigmoid\) 函数,虽然模型整体更加复杂,但本质上还是没有变。所以我们完全可以从一个简单的线性模型过渡到一个复杂的神经网络。
再来看公式,看到这个加总符号 \(\sum\),就说明里面进行的都是一系列相似的计算,所以用向量替换比较合适。
如果先约定好,统一使用列向量来表示数据,并使用 \(\sigma(x)\) 表示 \(sigmoid\) 函数,则以上数据及参数可表示为: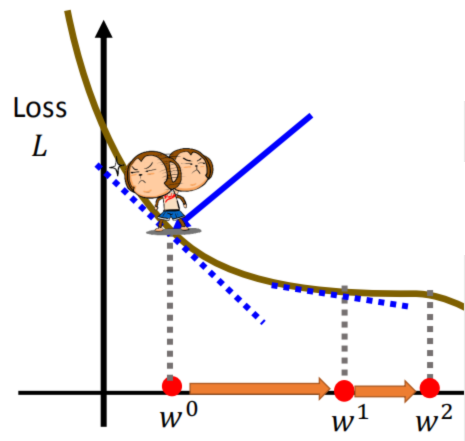 可以稍做想象,有个小人站在这个凸函数的任意一个点上,他的目标是到达这个函数的最低点位置,所以在他每走一步之前,都会先左右环顾,观察一下当前位置的情况,然后沿下降的方向迈出一步。然后如此循环,直到他找到最低点,或者与最低点的距离足够近时,才会停止。这里的关键就是小人如何判断出这个下降的方向呢?
我们都知道,函数在某一点的斜率表示函数在该点函数值的变化情况,所以只要沿着这个斜率方向,并且能使函数值减小的方向移动即可。这个方向叫做梯度方向的反方向。所以通常会有这么一种说法,沿梯度的相反方向,函数值下降的速度最快。个人认为,梯度只是斜率在多维空间中的升级版,只要理解了斜率的意义,再将其扩展到多维空间即可。
除此之外,还有一个问题,就是这一步跨多大呢?跨的太小,可能会影响效率,迟迟到不了最低点;但是如果跨的太大,又有错过最低点的风险。如果我们观察小人的移动轨迹,可以发现,随着小人的不断移动,斜率是逐渐变小的,最低点位置的斜率为0。所以我们可以使用梯度进行判断,如果梯度较大,说明离最低点的位置还较远,可以跨的大一点;如果梯度较小,说明离最低点可能已经不远了,需要跨的小一点。所以可使用梯度对参数进行更新:
可以稍做想象,有个小人站在这个凸函数的任意一个点上,他的目标是到达这个函数的最低点位置,所以在他每走一步之前,都会先左右环顾,观察一下当前位置的情况,然后沿下降的方向迈出一步。然后如此循环,直到他找到最低点,或者与最低点的距离足够近时,才会停止。这里的关键就是小人如何判断出这个下降的方向呢?
我们都知道,函数在某一点的斜率表示函数在该点函数值的变化情况,所以只要沿着这个斜率方向,并且能使函数值减小的方向移动即可。这个方向叫做梯度方向的反方向。所以通常会有这么一种说法,沿梯度的相反方向,函数值下降的速度最快。个人认为,梯度只是斜率在多维空间中的升级版,只要理解了斜率的意义,再将其扩展到多维空间即可。
除此之外,还有一个问题,就是这一步跨多大呢?跨的太小,可能会影响效率,迟迟到不了最低点;但是如果跨的太大,又有错过最低点的风险。如果我们观察小人的移动轨迹,可以发现,随着小人的不断移动,斜率是逐渐变小的,最低点位置的斜率为0。所以我们可以使用梯度进行判断,如果梯度较大,说明离最低点的位置还较远,可以跨的大一点;如果梯度较小,说明离最低点可能已经不远了,需要跨的小一点。所以可使用梯度对参数进行更新:【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |