手把手带你飞Python爬虫+数据清洗新手教程(一) |
您所在的位置:网站首页 › 爬虫收费标准 › 手把手带你飞Python爬虫+数据清洗新手教程(一) |
手把手带你飞Python爬虫+数据清洗新手教程(一)
|
本文共有2394字,读完大约需要10分钟。 目录 简介思考撸起袖子开始干1 获取网页源代码2 在网页源代码里找出所需信息的位置3 数据清洗4 完整代码5 优化后的代码 简介本文使用Anaconda3,没有安装Anaconda3的小朋友点击 此处 查看Anaconda + Pycharm 安装教程。 为了让初学者了解爬虫与数据清洗的原理,本文只使用了requests模块,用字符串替换、分片的方法清洗数据,中间使用了for循环,用到了字符、列表、int、元组、字典类型。 本文的实验目的是从89ip.cn网站获取第一页到第六页的表格数据,并处理成如下样式: {‘1’:[(‘’,'’,’*****’,),(),(),(),()],‘2’:[(),(),(),(),()]…} 怎么样,有思路了吗?怎么提取网页数据?怎么清洗数据? 1 首先爬取一个页面, 2 然后把获取到的网页源代码解码成人类可读的形式, 3 找到需要的信息,分析上下文的关键字符及干扰字符, 4 截取包含所需信息的片段 5 对截取的信息进行数据清洗 替换掉不需要的干扰信息 根据关键字符把长字符串分片成多个短字符串 整理字符串 6 对一个页面提取成功并清洗成功后,开始思考怎样自动提取多个页面的数据并对数据清洗呢? 撸起袖子开始干 1 获取网页源代码打开Jupyter Notebook,如下图: 在输入框中输入如下代码: import requests url = 'http://www.89ip.cn/index_1.html' headers ={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'} res = requests.get(url,headers=headers) res点击运行:
运行上面的代码就能获服务器返回的状态码200, 200(成功) 服务器已成功处理了请求。 headers里的内容是浏览器标识,模拟真实的浏览器,由于有些网站设置了反爬策略,如果不加上headers的内容,可能会失败。 光有状态码不行啊,我们要的是网页内容,怎样得到网页代码呢? 其实上面的res里已经包含了网页源代码,只是没有显示出来,运行如下一行代码,就能看到网页源代码了。 res.text这一行代码运行后,网页源代码就到手了,并且是人类可读的形式,如下图: 来看一下res.content的到的是什么: res.content
上面已经提到“content:返回bytes类型的数据也就是二进制数据”,既然是二进制,我们把它转换成文本类型不就可以了吗? .decode(‘期望的编码类型’),decode是解码的意思,将获取到的网页源代码的二进制数据解码为期望的编码类型。 运行下面一行代码: res.content.decode('utf-8')
如果熟悉Html标记语言,直接在源代码里找到,如下所示,找到标签 上面第1步中已经获取到网页源代码,上面第2步中讲了所需信息在网页源代码中的位置,现在从网页源代码中提取所需信息。 split()方法可以根据字符来把字符串分片,split(’’)[0]意思是找到字符串中的“”所在的位置,在这个位置把字符串分割开,“[0]”的意思是保留分片后的数段字符串中的第一段字符串,“[1]”的意思是保留分片后的数段字符串中的第二段字符串。 #得到tbody内容 stp2 = res.text.split('')[1].split('')[0] stp2运行: 上图中的结果是不是看起来干净了许多?但是其中有很多无用的“\n”、“\t”和空格,可以使用replace()方法来替换掉这些无用的字符。 输入如下代码: stp3 = stp2.replace('\n','').replace('\t','').replace(' ','').replace('','').replace('','') stp3运行: 如上图所示,这样就把无用的字符去掉了,下一步要把每行分割开来,想一想怎么分割呢? 第2步中已经讲了标签里的内容就是表格中每行的的内容,因此,可以根据标签来分割出每一行。 输入如下代码: stp4 = stp3.split('') stp4运行: 如上图所示,已经把字符串分割成行,但是第一行是空的,因为在没分行之前的字符串中第一个“”前面什么也没有,下一步的处理过程中可以把这个空行处理掉。 下一步要把每个单元格分割开,前面第2步中讲了“”标签中的内容就是表格中的单元格中的内容,因此,可以根据“”来分割字符串,但是上图中有不只一行字符串,要对多行字符串进行同样的处理就要用到for循环。 输入如下代码: body = [] #定义一个空列表,用来装每行字符串用 #for循环,循环处理每行字符串 for row in stp4: '''由于上一步的处理结果中第一行是空行,因此,这一步判断如果为非空行则继续进行处理''' if '.'in row : #根据“”分片 td = row.split('') #往列表body中追加每行字符串 body.append(td) body运行: pop()方法可以移除列表中的一个元素(默认最后一个元素)pop(0)意思是移除列表中的第一个元素。 我们要的结果是每行字符串为一个元组,使用tuple()方法可以将其他类型的数据转为元组类型。 把上面的代码修改为下面的代码: body = [] for row in stp4: if '.'in row: td = row.split('') td.pop(0) body.append(tuple(td)) body
下面是处理第一页表格的全部代码: import requests url = 'http://www.89ip.cn/index_1.html' headers ={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'} res = requests.get(url,headers=headers) stp1 = res.text stp2 = stp1.split('')[1].split('')[0] stp3 = stp2.replace('\n','').replace('\t','').replace(' ','').replace('','').replace('','') stp4 = stp3.split('') body = [] for row in stp4: if '.'in row : td = row.split('') td.pop(0) body.append(tuple(td)) body上面的代码的确可以解决我们的需求,但是不符合面向对象的编程思想,不利于维护,因此需要把它改变成如下形式: 5 优化后的代码 import requests #获取网页源代码 def get_source(): url = 'http://www.89ip.cn/index_1.html' headers ={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'} res = requests.get(url,headers=headers).text return res #清洗数据 def get_data(res): data = res.split('')[1].split('')[0].replace('\n','').replace('\t','').replace(' ','').replace('','').replace('','').split('') body = [] for row in data: if '.'in row : td = row.split('') td.pop(0) body.append(tuple(td)) return body #主函数 def main(): src = get_source() page = get_data(src) return page #调用主函数 main()上面的代码就具有模块化的样式了,方便调用和维护。 如下图所示,自上而下按顺序运行,就能得到结果,也可以把所有代码放到一个输入框里。 欲知后事如何,点击 此处 查看《手把手带你飞Python爬虫+数据清洗新手教程(二)》。 |
 下图是网站页面样式:
下图是网站页面样式: 
 首先弹出如下所示的窗口,不要关闭这个窗口,可以将其最小化:
首先弹出如下所示的窗口,不要关闭这个窗口,可以将其最小化: 然后弹出浏览器页面,如下图:
然后弹出浏览器页面,如下图:  点击“New”,点Python 3
点击“New”,点Python 3  出现如下页面,工具栏中的“+”是新建一个输入框:
出现如下页面,工具栏中的“+”是新建一个输入框: “Edit”中的“Delete Cells”是删除输入框:
“Edit”中的“Delete Cells”是删除输入框: 

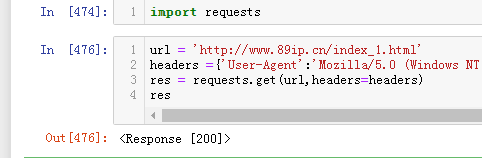
 小朋友,你是否有很多问号??? 为什么加上.text就能显示了呢? 这个问题涉及到requests模块中的content和text方法:
小朋友,你是否有很多问号??? 为什么加上.text就能显示了呢? 这个问题涉及到requests模块中的content和text方法: 看到上面这张图,小朋友,这是啥???这是人类语言吗??? 怎样才能把这非人类可读的语言编程人类可读语言呢???
看到上面这张图,小朋友,这是啥???这是人类语言吗??? 怎样才能把这非人类可读的语言编程人类可读语言呢??? 这样网页源代码就正确显示出来了,那我们是用text呢,还是用content.decode(‘utf-8’)呢? 由于本文使用text就能正确显示出来,所以本文使用text,其他用法本文不再具体讲述。
这样网页源代码就正确显示出来了,那我们是用text呢,还是用content.decode(‘utf-8’)呢? 由于本文使用text就能正确显示出来,所以本文使用text,其他用法本文不再具体讲述。 我们需要提取的是 标签里的内容
我们需要提取的是 标签里的内容  每个标签里的内容就是表格里每一行的内容
每个标签里的内容就是表格里每一行的内容  每个标签里的内容就是每个每个单元格的内容
每个标签里的内容就是每个每个单元格的内容 



 如上图所示,每行中的第一个单元格字符串为空,怎么办呢?
如上图所示,每行中的第一个单元格字符串为空,怎么办呢? 到这里,我们已经把第一页的表格处理完成。
到这里,我们已经把第一页的表格处理完成。
 第一页的表格提取并处理完成了,但是我们要的是第一页到第六页的表格数据,思考一下吧,接下来怎么办呢? 下次再续,晚安。
第一页的表格提取并处理完成了,但是我们要的是第一页到第六页的表格数据,思考一下吧,接下来怎么办呢? 下次再续,晚安。【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |