论文阅读 |
您所在的位置:网站首页 › 熵的出处 › 论文阅读 |
论文阅读
|
Loss odyssey in medical image segmentation github:https://github.com/JunMa11/SegLossOdyssey 这篇文章回顾了医学图像分割中的20种不同的损失函数,旨在回答:对于医学图像分割任务,我们应该选择哪种损失函数? 首先是一张各类分割函数的图谱:
介绍函数之前先定义字母符号的含义:
损失函数分为四类:即分布不匹配,区域、边界或它们的某种组合。 1. Distribution-based Loss 基于分布的损失函数旨在最小化两个分布之间的不相似性。以交叉熵cross entropy为代表。 1.1. Cross entropy
对于CNN模型,可以写为:
加权版——Weighted cross entropy (WCE)(2015):
1.2. TopK loss(2016)
t∈ (0, 1]是个阈值,也就是说,容易分类的像素点(概率>t)被忽略了,另一个实现版本:
本文实验中k=10% 1.3. Focal loss(2018)
通过减少已经分好类的样本的损失来关注困难样本,可以处理前景背景类别不平衡的情况。原始论文中给出γ=2表现最好。 1.4. Distance map penalized cross entropy loss (DPCE)
具体地,通过取GT的距离变换的逆来生成Dc。通过这种方式,可以为边界上的像素分配更大的权重。 DPCE损失通过从GT掩码导出的距离图来加权交叉熵。它旨在引导网络将重点放在难以分割的边界区域。 2. Region-based Loss 基于区域的损失函数旨在最小化GT和预测S之间的不匹配或最大化两者的重叠区域。最有代表性的是Dice loss。 2.1. Sensitivity-specificity loss(2015)
将特异性加权得更高来解决类别失衡问题。w控制敏感性和特异性的平衡。 2.2. Dice loss(2016) 有两个变体:
直接优化Dice Similarity Coefficient (DSC)。与加权交叉熵不同,Dice损失不需要对不平衡分割任务进行类重新加权。 2.3. IoU (Jaccard) loss(2016)
和Dice loss很相似,也是直接优化目标类别的分割指标。 2.4. Lovász loss 定义类c ∈ C的像素误差:
与IoU损失类似,Lovasz损失也是直接优化Jaccard指数,但它使用了不同的替代策略。特别地,IoU损失(也称为软Jaccard)简单地用softmax概率代替Jaccard索引中的分割,while Lovász loss uses a piecewise linear convex surrogate to the IoU loss based on the Lovász extension of submodular set functions。 2.5. Tversky loss
这个是改进的Dice loss,旨在得到更好的P、R的平衡,强调错误的负类样本。α,β是超参数,控制false negatives and false positives的平衡。 2.6. Generalized Dice loss
这个损失函数是多类别Dice loss的扩展,每个类别的权重与标签频率成反比。 2.7. Focal Tversky loss
γ∈[1, 3]。把focal loss用在Tversky loss上,使得困难样本概率低。 2.8. Asymmetric similarity loss
原始论文中β=1.5。当α+β=1时变为Tversky loss的一个特例。 Dice loss可以被视为准确度和召回率的调和平均值,它对假阳性(FP)和假阴性(FN)的权重相等。Asymmetric similarity loss的动机是通过引入加权参数β来更好地调整FPs和FNs的权重(并在精度和召回率之间实现更好的平衡)。 2.9. Penalty loss
3. Boundary-based Loss 基于边界的损失函数,相对比较新,旨在最小化预测S和GT之间的距离。 3.1. Boundary (BD) loss(2019,2021) 有两种不同的框架来计算两个边界之间的距离。一种是微分框架,它将边界曲线上每个点的运动计算为沿曲线法线的速度。另一种是积分框架,通过计算两个边界的失配区域之间的界面上的积分来近似距离。微分框架不能直接用作网络softmax输出的损失,因为它是不可微分的。为了以微分的方式计算两个边界之间的距离
3.2. Hausdorff Distance (HD) loss Hausdorff Distance (HD)距离是一种基于边界的度量,广泛用于评估分割方法。然而,在训练过程中直接最小化HD是难以解决的,并可能导致训练不稳定。为了解决这个问题,HD可以通过GT距离变换来近似。网络可以通过以下HD损失功能进行训练,以减少HD:
dG and dS分别是GT和预测分割的距离变换地图。距离变换计算了每个像素与对象边界之间的最短距离。 上面这两种边界损失用于训练神经网络时,应与基于区域的损失(例如Dice loss)相结合,以减少训练的不稳定性。 4. Compound Loss 混合损失是上面这些损失函数的加权。 4.1. Combo loss
4.2. Exponential Logarithmic loss (ELL)
对Dice损失和交叉熵损失进行指数和对数变换。通过这种方式,可以迫使网络在本质上更多地关注不太准确预测的结构。 4.3. Dice loss with focal loss
4.4. Dice loss with TopK loss
此外,文章还提到了有其他方法,一笔带过,未列出公式。 实验 3D U-Net+数据增强+Adam 三种损失函数在训练过程中需要额外的调度策略:Lova´sz loss, boundaries loss, and Hausdorff distance loss。对于 Lova´sz loss, 原论文作者建议先用交叉熵优化,然后用Lova´sz loss微调;对于 boundary loss 和 Hausdorff distance loss 应该和 Dice loss 结合使用:
α, β > 0。对于边界损失,(Kervadec et al.,2019)建议使用Dice损失来主导初始训练,从而稳定训练过程,快速获得合理的初始分割。具体来说,他们最初设置权重β=1−α和α=1,并在每个epoch后将α减少0.01,直到达到0.01的值。对于Hausdorff距离损失,(Karimi和Salcudean,2020)将α设置为基于HD的损失项的平均值与DSC损失项的均值之比,并且β=1。最近的一项实证研究(Ma et al.,2020)表明,实施细节会对绩效产生显著影响。在我们的实验中,我们首先用Dice损失对网络进行训练,然后用建议的调度策略对BD损失和HD损失进行微调,因为我们发现这种训练技巧可以获得稳健的训练过程,并给出最佳性能。所有其他17个损失函数都可以在训练期间以即插即用的方式使用,而无需任何特定的调度技巧。 在四个分割数据集评估,包括balanced and imbalanced foreground-background, binary and multi-class segmentation. 类别平衡的、不平衡的、二分类的多分类的都包括了。 数据集情况:
评估指标:Dice similarity coefficient 和 Normalized Surface Distance (NSD)
实验结果
1. Single segmentation task 1.1. Mildly imbalanced segmentation
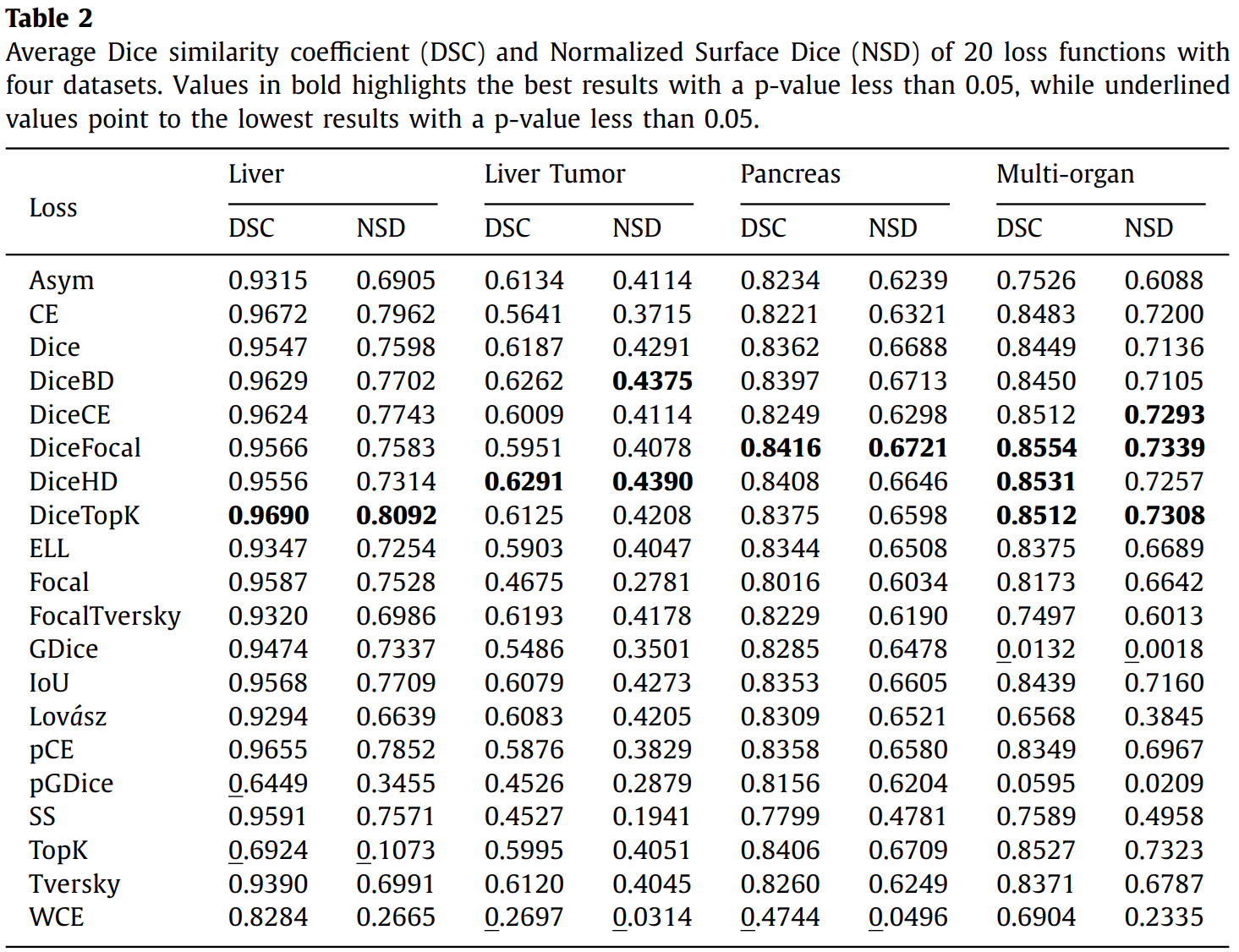
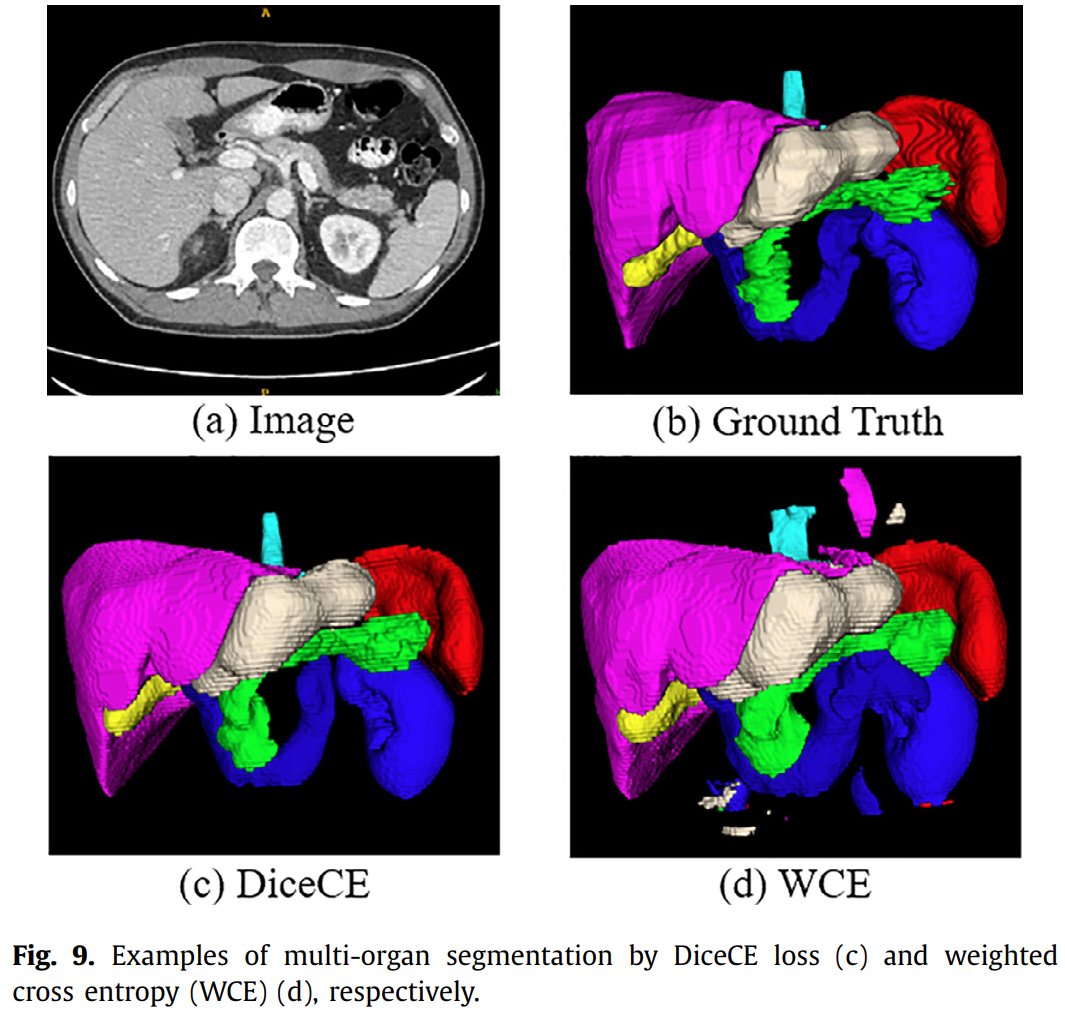
Mildly imbalanced segmentation结果只看liver数据集上的结果。 大多数损失函数(17/20)在DSC高于0.90的情况下获得高度准确的结果。 DiceTopK损失获得最佳DSC和NSD,而pGDice损失获得最低DSC,TopK损耗在DSC和NSD中都获得最低的性能。 图2显示TopK loss 和 pGDice loss方差比较大。图3是失败示例,显示TopK loss 和 pGDice loss倾向于过度分割。 1.2. Highly imbalanced tumor segmentation
看liver tumor数据集上的结果。DiceHD,DiceBD表现比较好。加权交叉熵表现不好。 1.3. Highly imbalanced organ segmentation
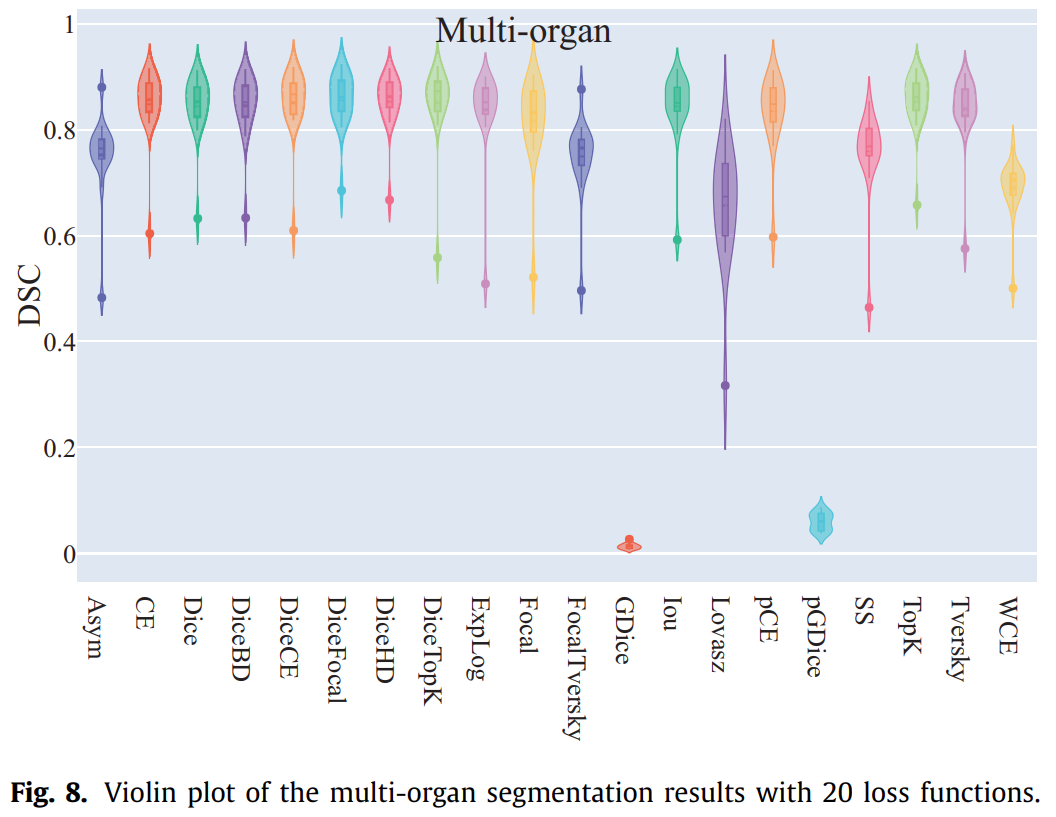
DiceFocal loss表现最好,交叉熵不好。 1.4. Multi-class segmentation with both mildly and highly imbalanced labels
研究包含轻度和高度不平衡标签的多类分割任务 DiceFocal loss, DiceHD loss, and DiceTopK loss表现好 2. Different variants of TopK loss
除了liver数据集,其他的k=10%效果比较好,但是liver数据集需要90%,作者分析的原因是liver数据集在训练期间仅使用10%的像素对于肝脏是不够的,因为肝脏非常大(最大的腹部器官)。然而,在这项工作中,我们主要关注标签不平衡的任务。因此,我们选择TopK-10%的损失作为默认的TopK损失,因为它在具有挑战性的分割任务中获得了更好的性能。 所以应该就是说,标签不平衡的比较严重的话,k小一些,否则就大一些。 3. Different variants of Dice loss
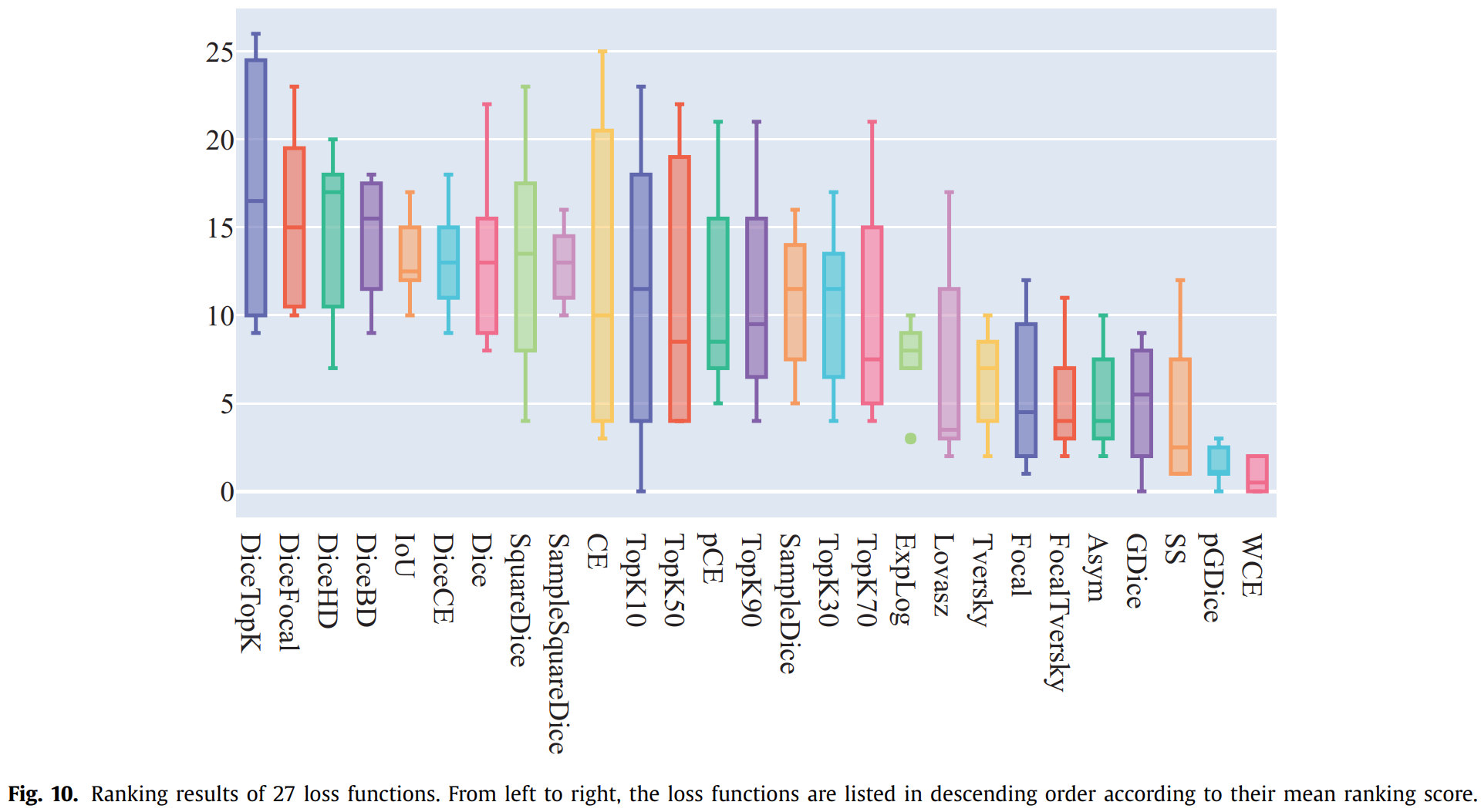
4. Rank Results 作者自己设计了一套排序规则(具体看原文吧),然后给这些指标排序:
|

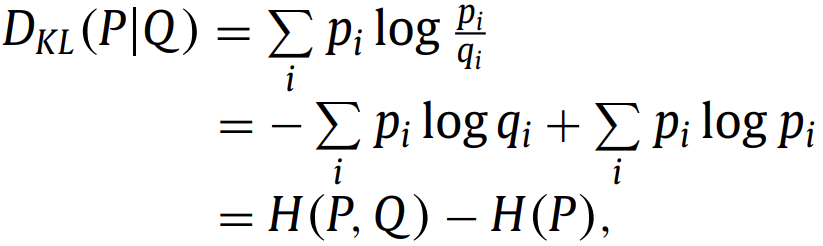
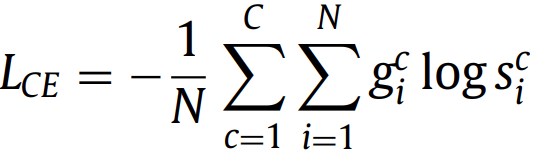
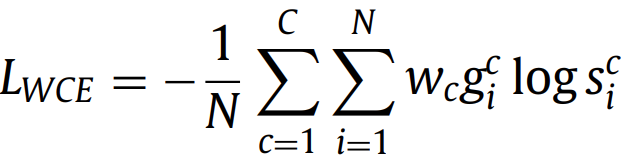
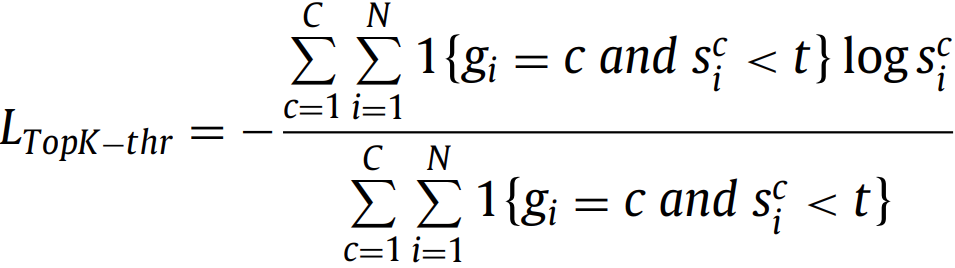
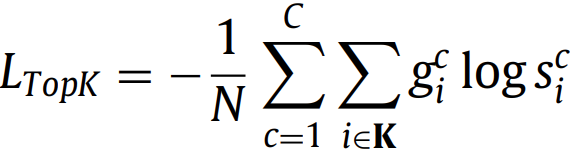

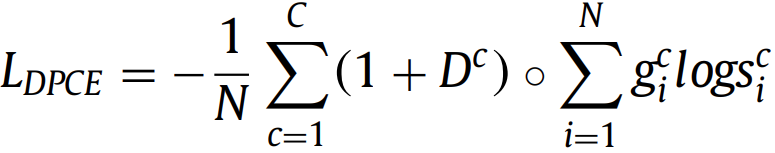

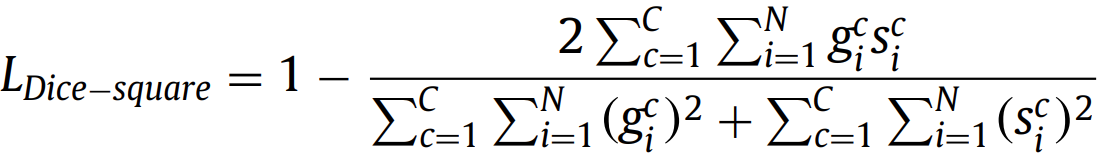
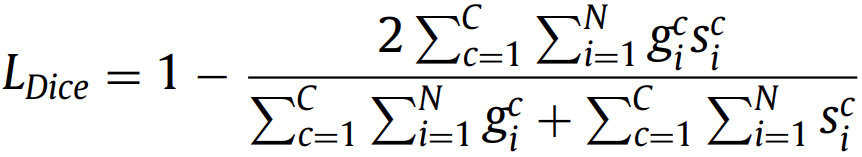
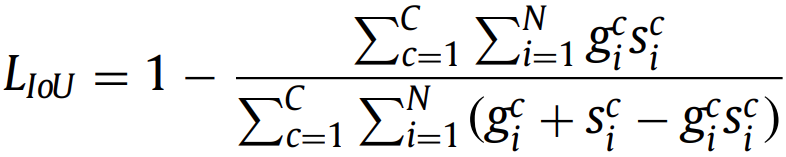


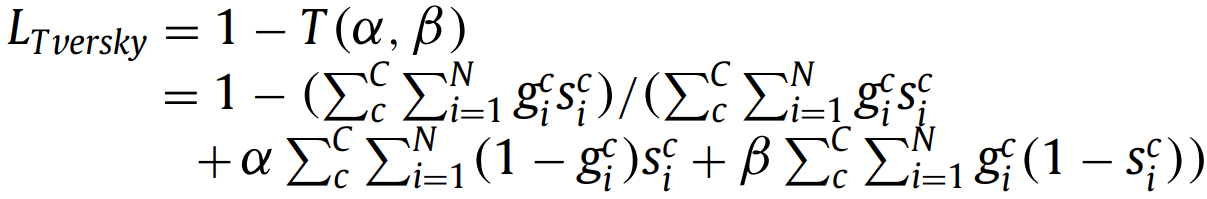
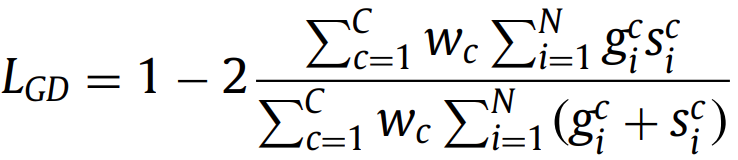
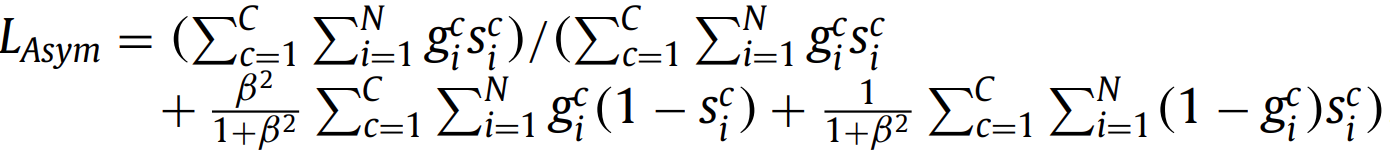











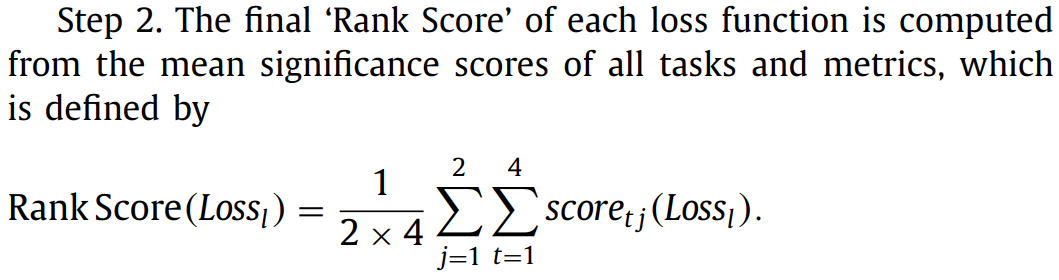
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |