面试必问系列 |
您所在的位置:网站首页 › 深拷贝浅拷贝面试题 › 面试必问系列 |
面试必问系列
|
🐴 面试必问系列—深浅拷贝✔️
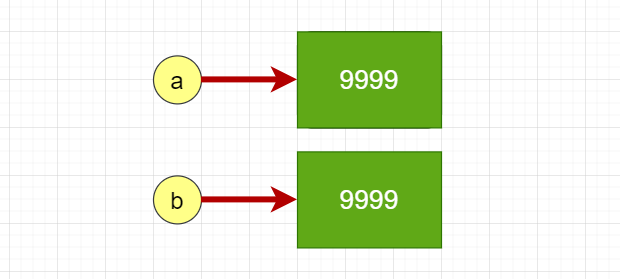
正值毕业季,大部分人会遇到走向社会的第一个难题—找工作面试,当你经历的面试多了,就会发现会有一些面试官经常问到的问题,比如: 问:你为什么会选择我们公司? 答:你们公司不是招人嘛😂 那么,我会在这个系列里讲讲那些经常被问到的面试题 现在先让我们一起来了解一下深浅拷贝 🎉 赋值在Python中,赋值其实就是对象的引用。 a = 9999 b = a print(a) #ouput:9999 print(b) #ouput:9999 print(id(a)) #ouput:1869259054928 print(id(b)) #ouput:1869259054928
这样赋值后,b和a不仅在值上相等,而且是同一个对象,也就是说在堆内存中只有一个数据对象9999,这两个变量都指向这一个数据对象。从数据对象的角度上看,这个数据对象有两个引用,只有这两个引用都没了的时候,堆内存中的数据对象9999才会等待垃圾回收器回收。 需要注意的是,它和下面的赋值过程是不等价的: a = 9999 b = 9999 print(id(a)) #ouput:1869266158672 print(id(b)) #ouput:1869266158768
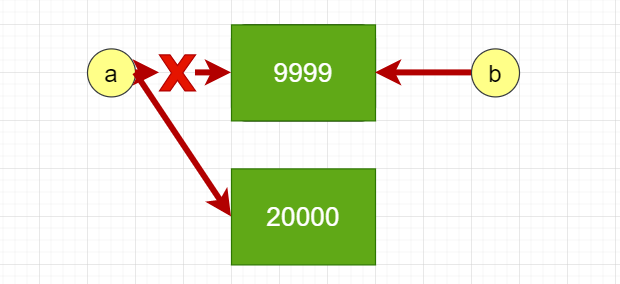
虽然a和b的值相等,但他们不是同一个对象,这时候在堆内存中有两个数据对象,只不过这两个数据对象的值相等。 不可变对象对于不可变对象,修改变量的值意味着在内存中要新创建一个数据对象 >>> a = 9999 >>> b = a >>> id(a) 2625562451792 >>> id(b) 2625562451792 >>> a = 20000 >>> id(a) 2625564836944 >>> id(b) 2625562451792
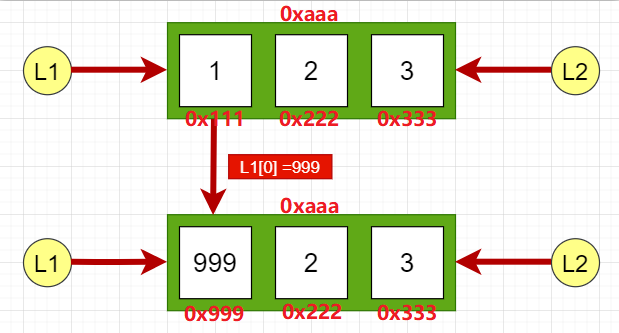
在a重新赋值之前,b和a都指向堆内存中的同一个数据对象9999,但a重新赋值后,因为数值类型9999是不可变对象,不能在原始内存块中直接修改数据,所以会新创建一个数据对象保存20000,最后a将指向这个20000对象。这时候b仍然指向9999,而a则指向20000。 可变对象对于可变对象,比如列表,它是在"原处修改"数据对象的。比如修改列表中的某个元素,列表的地址不会变,还是原来的那个内存对象,所以称之为"原处修改"。例如: >>> L1 = [1,2,3] >>> L2 = L1 >>> L1[0] = 999 >>> L1,L2 ([999, 2, 3], [999, 2, 3]) >>> id(L1) 2625562620872 >>> id(L2) 2625562620872
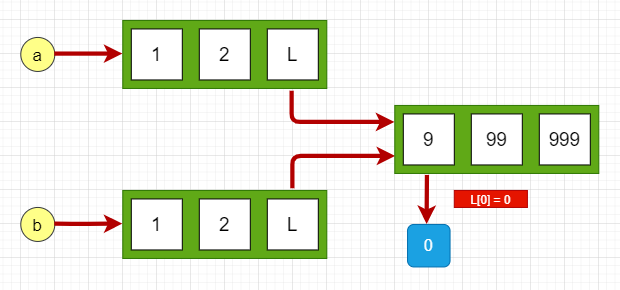
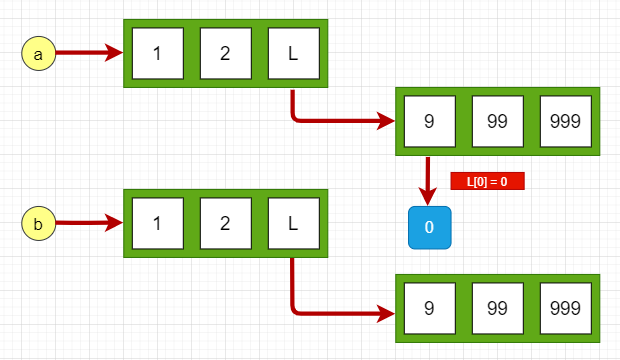
在L1[0]赋值的前后,数据对象[1,2,3]的地址一直都没有改变,但是这个列表的第二个元素的值已经改变了。因为L1和L2都指向这个列表,所以L1修改第一个元素后,L2的值也相应地到影响。也就是说,L1和L2仍然是同一个列表对象。 PS: 为啥一直在用9999这个数? 答:1. 9是我的幸运数字😂 2. 因为9999不是小整数(移步文章末尾) 为什么在Pycharm内的输出结果和上面内容不一致? 答:首先 Python给[-5,256]以内值分配了空间, 超出的就需要重新分配。 而Pycharm不遵循这个,因为 Pycharm是放到脚本里面编译的,而不是在解释器里面,脚本编译是一次性编译的会产生编译文件,所以内存地址会复用,所以输出的id效果不一致。 浅拷贝浅拷贝: 只拷贝第一层的数据。 在python中赋值操作或copy模块的copy()就是浅拷贝 怎么理解拷贝第一层的数据,先来看一个嵌套的数据结构: L1 = [1,2,3] L2 = [1,2,[3,33,333]]L1只有一层深度,L2有两层深度, 浅拷贝时只拷贝第一层的数据作为副本,深拷贝递归拷贝所有层次的数据作为副本。 例如: >>> import copy >>> L = [9,99,999] >>> a = [1,2,L] >>> b = copy.copy(a) >>> a,b ([1, 2, [9, 99, 999]], [1, 2, [9, 99, 999]]) >>> id(a),id(b) # 不相等 (2625565288456, 2625565288776) >>> id(a[2]) 2625565288328 >>> id(b[2]) # 相等 2625565288328 >>> L[0] = 0 >>> a,b ([1, 2, [0, 99, 999]], [1, 2, [0, 99, 999]])
a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。 深拷贝深拷贝:递归拷贝所有层次的数据 Python中copy模块的deepcopy()是深拷贝 ,比如: >>> L = [9,99,999] >>> a = [1,2,L] >>> b = copy.deepcopy(a) >>> a,b ([1, 2, [9, 99, 999]], [1, 2, [9, 99, 999]]) >>> id(a),id(b) # 不相等 (2625565169224, 2625565169288) >>> id(a[2]) 2625565169480 >>> id(b[2]) # 不相等 2625565169416 >>> L[0] = 0 >>> a,b ([1, 2, [0, 99, 999]], [1, 2, [9, 99, 999]])
深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。 一般来说,浅拷贝或者引用赋值就是我们所经常用的操作,只有少数情况下( 数据序列化、要传输、要持久化 ),才需要深拷贝操作,但是这些操作一般都内置在对应函数中,无需手动去深拷贝。 总结: 浅拷贝:内存地址深拷贝:数据内容 早已存在的小整数数值对象是不可变对象,理论上每个数值都会创建新对象。 但实际上并不是这样,对于 [-5,256]这个区间内的小整数,因为Python内部引用过多,这些整数在python运行的时候就事先创建好并编译好对象了。所以,a=2, b=2, c=2根本不会在内存中新创建数据对象2,而是引用早已创建好的初始化数值2。 >>> a=2 >>> b=2 >>> a is b True对于超出小整数范围的数值,每一次使用数值对象都创建一个新数据对象。例如: >>> a=9999 >>> b=9999 >>> a is b False但是也有特殊的情况: >>> a=9999;b=9999 >>> a is b True >>> a,b=9999,9999 >>> a is b True为什么会这样呢? 原因是 Python解析代码的方式是按行解释的,读一行解释一行,创建了第一个9999时发现本行后面还要使用一个9999,于是b也会使用这个9999,所以它返回True。而前面的换行赋值的方式,在解释完一行后就会立即忘记之前已经创建过9999的数据对象,于是会为b创建另一个9999,所以它返回False。 如果在Python的文件中执行,则在同一作用域内,a is b是一直会是True的,这和代码块作用域有关: 整个py文件是一个模块作用域 ,可以看我之前的内容 a = 9999 b = 9999 print(a is b) # True def func(): c = 9999 d = 9999 print(c is d) # True print(a is c) # False func()这也是为什么相同的代码在pycharm和cmd输出的结果会不一致的原因。 如果觉得文章不错,不妨给个赞 |

 ,也欢迎大家在评论区讨论!
,也欢迎大家在评论区讨论!【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |