CBAM: 卷积注意力模块的学习、实现及其应用 |
您所在的位置:网站首页 › 注意怎么画 › CBAM: 卷积注意力模块的学习、实现及其应用 |
CBAM: 卷积注意力模块的学习、实现及其应用
|
简介
Convolutional Block Attention Module(CBAM), 卷积注意力模块。该论文发表在ECCV2018上(论文地址),这是一种用于前馈卷积神经网络的简单而有效的注意力模块。 CBAM融合了通道注意力(channel Attention)和空间注意力(Spatial Attention),同时该注意力模块非常轻量化,而且能够即插即用,可以用在现存的任何一个卷积神经网络中。
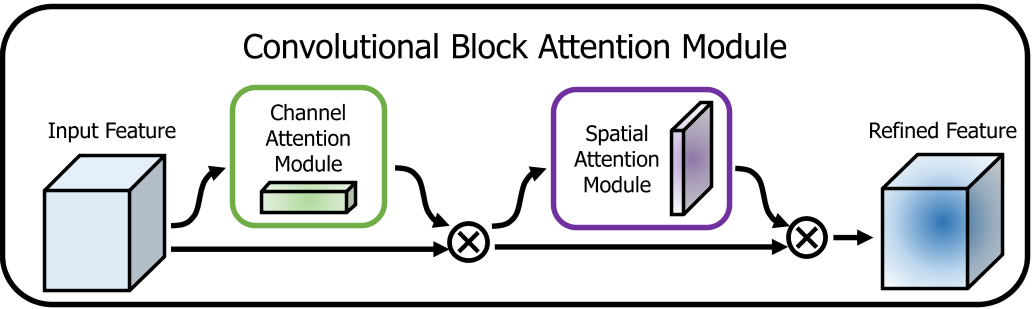
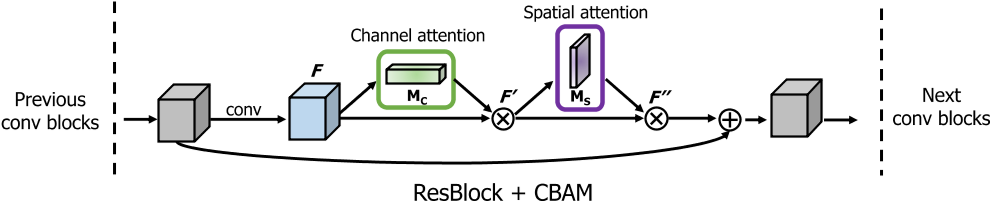
CBAM的流程如上图所示 首先,输入是一个中间特征图,将特征图输入至Channel Attention Module 获取通道注意力,然后将注意力权重作用于中间特征图。 然后,将施加通道注意力的特征图输入至Spatial Attention Module 获取空间注意力,然后将注意力权重作用到特征图上。 最终,经过这两个注意力模块的串行操作,最初的特征图就经过了通道和空间两个注意力机制的处理,自适应细化特征。
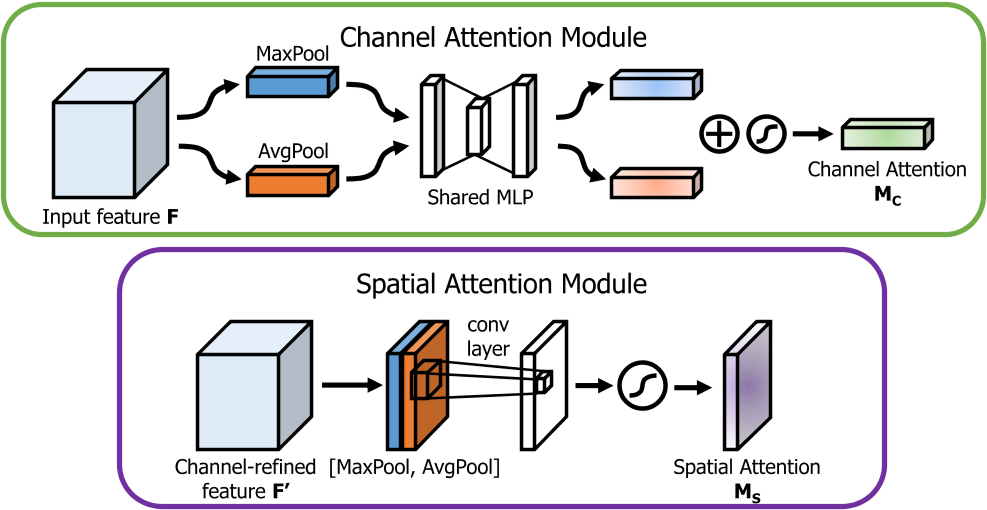
那么,CBAM的注意力到底如何计算如上图所示,我们将在下面进行讲解。 Channel Attention
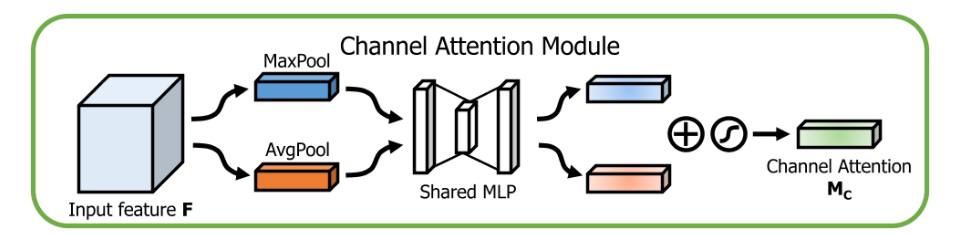
通道注意力,将特征图在空间维度池化,保留通道的特征信息。在CBAM中,我们可以看到,全局平均池化和全局最大值池化均有使用(SENet只使用了平均池化,而cbam认为最大值池化被可以捕捉突出特征,实验证明也确实是有效的)。 它的计算流程如下: 将输入的特征图分别进行全局最大池化和全局平均池化,将空间维度压缩为1,保留通道信息。 将两个池化后的特征送入共享的多层感知机(MLP)提取特征。 将经过MLP的池化特征相加,经过sigmoid激活得到最终的通道注意力权重。 Spatial Attention
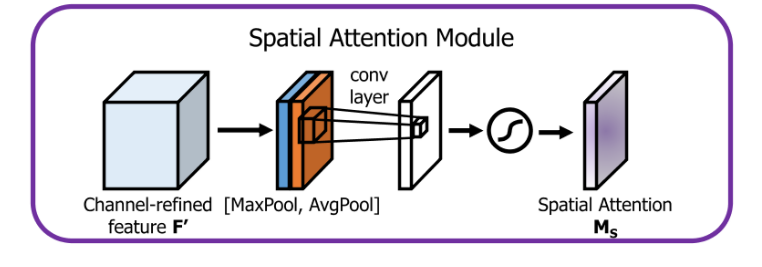
空间注意力,将特征图在通道维度池化,保留空间的特征信息。 它的计算流程如下: 将特征图(经过通道注意力计算后的)在通道维度分别进行最大值池化和平均池化,将通道维度压缩为1,保留空间信息。 将池化特征concatenate起来,经过一个卷积层提取特征,同时将通道维度降至1。 最终经过sigmoid激活,得到最终的空间注意力权重(包含进了通道注意力)。
在串行地进行完这两个步骤后,将空间注意力特征与原特征图相乘即可。从上述运算过程可以看出,CBAM作为独立的两个模块,可以直接添加在任何一个卷积神经网络中,带来的附加运算量开销也很小。 实现接下来,我们用Pytorch实现CBAM。 Channel Attention class ChannelAttention(nn.Module): def __init__(self, channels, reduction_radio=16): super().__init__() self.channels = channels self.inter_channels = self.channels // reduction_radio self.maxpool = nn.AdaptiveMaxPool2d((1, 1)) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.mlp = nn.Sequential( # 使用1x1卷积代替线性层,可以不用调整tensor的形状 nn.Conv2d(self.channels, self.inter_channels, kernel_size=1, stride=1, padding=0), nn.BatchNorm2d(self.inter_channels), nn.ReLU(), nn.Conv2d(self.inter_channels, self.channels, kernel_size=1, stride=1, padding=0), nn.BatchNorm2d(self.channels) ) self.sigmoid = nn.Sigmoid() def forward(self, x): # (b, c, h, w) maxout = self.maxpool(x) # (b, c, 1, 1) avgout = self.avgpool(x) # (b, c, 1, 1) maxout = self.mlp(maxout) # (b, c, 1, 1) avgout = self.mlp(avgout) # (b, c, 1, 1) attention = self.sigmoid(maxout + avgout) #(b, c, 1, 1) return attentionSpatial Attention class SpatialAttention(nn.Module): def __init__(self): super().__init__() self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3) self.sigmoid = nn.Sigmoid() def forward(self, x): # (b, c, h, w) maxpool = x.argmax(dim=1, keepdim=True) # (b, 1, h, w) avgpool = x.mean(dim=1, keepdim=True) # (b, 1, h, w) out = torch.cat([maxpool, avgpool], dim=1) # (b, 2, h, w) out = self.conv(out) # (b, 1, h, w) attention = self.sigmoid(out) #(b, 1, h, w) return attention 对于一个特征图X,CBAM的运算结果如下: ca = ChannelAttention(64) sa = SpatialAttention() x = torch.randn(3, 64, 56, 56) channel = ca(x) # (3, 64, 1, 1) x = channel * x # (3, 64, 56, 56) spatial = sa(x) # (3, 1, 56, 56) x = spatial * x # (3, 64, 56, 56)应用 在之前的一篇博客里,尝试使用Vision Transformer训练102种鲜花分类。但是因为从头训练Vision Transformer的效果不好,预训练权重又比较难获得,因此总体而言准确度较低。然后这次想用ResNet + CBAM重新试一下。最后也没太使劲调参,发现效果还不错。如何将CBAM插入到ResNet中如下图所示。
同时想尝试一下,将CBAM的注意力权重提取出来可视化观察一下效果,那么接下来就写一下ResNet + CBAM的实现(以ResNet34为例)。 代码主要参考了这个仓库,不过因为要可视化等等,还是进行了一些修改。github BasicBlock class BasicBlock(nn.Module): expansion = 1 # 通道升降维倍数 def __init__(self, in_channels, channels, stride=1, downsample=None, attention=None): super().__init__() self.conv1 = nn.Conv2d(in_channels, channels, kernel_size=3, stride=stride, padding=1) # 第一个卷积层,通过stride进行下采样 self.bn1 = nn.BatchNorm2d(channels) self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, stride=1, padding=1) # 第二个卷积层,不进行下采样 self.bn2 = nn.BatchNorm2d(channels) self.downsample = downsample self.attention = attention # CBAM模块 self.stride = stride self.relu = nn.ReLU(inplace=True) def forward(self, x): residual = x out = self.bn1(self.conv1(x)) out = self.relu(out) out = self.bn2(self.conv2(out)) if self.attention is not None: out = self.attention[0](out) * out # 先进行通道注意力 self.attention_weights = self.attention[1](out) # CBAM的注意力图 out = self.attention_weights * out # 然后进行空间注意力 else: self.attention_weights = None if self.downsample is not None: residual = self.downsample(x) # 通道数不变,1x1卷积层仅用于降采样 out += residual return self.relu(out)ResNet class ResNet(nn.Module): def __init__(self, block, layers, num_classes=1000): self.in_channels = 64 self.layers = layers super().__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = self._make_layer(block, 64, layers[0]) # 第一个残差层不进行下采样 self.layer2 = self._make_layer(block, 128, layers[1], stride=2) self.layer3 = self._make_layer(block, 256, layers[2], stride=2) self.layer4 = self._make_layer(block, 512, layers[3], stride=2) self.attention_layer = [self.layer3, self.layer4] # 仅在最后两个layer上添加注意力 self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.flatten = nn.Flatten() self.fc = nn.Linear(512 * block.expansion, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.xavier_normal_(m.weight, gain=1) elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() def _make_layer(self, block, channels, blocks, stride=1): # block:basicblock or bottleneck downsample = None if stride != 1 or self.in_channels != channels * block.expansion: # 需要下采样or要融合通道 downsample = nn.Sequential( nn.Conv2d(self.in_channels, channels * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(channels * block.expansion) ) layers = [] layers.append(block(self.in_channels, channels, stride, downsample)) # 第一个残差块 self.in_channels = channels * block.expansion for i in range(1, blocks): attention = None if i > 1: # 在第2层往后才添加cbam attention = nn.Sequential( ChannelAttention(self.in_channels), SpatialAttention()) layers.append(block(self.in_channels, channels, attention=attention)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) self._attention_weights = [None] * len(self.attention_layer) # 将带有注意力层的注意力权重拿出来 for i, layer in enumerate(self.attention_layer): for j, (name, blk) in enumerate(layer.named_children()): self._attention_weights[i] = blk.attention_weights # 覆盖,仅获取最后一个block的注意力 x = self.avgpool(x) x = self.flatten(x) x = self.fc(x) return x @property def attention_weights(self): return self._attention_weights ResNet34 with CBAM model_urls = { 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth', 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth', 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth', 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth', 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth', } def resnet34_cbam(pretrained=False, num_class=1000): model = ResNet(BasicBlock, [3, 4, 6, 3], num_class) if pretrained: pretrained_state_dict = model_zoo.load_url(model_urls['resnet34']) # 预训练resnet的权重字典 pretrained_state_dict = {k: v for k, v in pretrained_state_dict.items() # 除去全连接层的预训练权重 if (k in pretrained_state_dict and 'fc' not in k)} new_state_dict = model.state_dict() new_state_dict.update(pretrained_state_dict) # 将预训练权重通过dict的update方式更新 model.load_state_dict(new_state_dict) # 将更新的网络权重载入到注意力resnet中 return model 其他一些杂项 对于102种鲜花分类,只给了训练集和需要打标签的测试集。为了评估训练效果,最好从训练集中分出一部分来进行验证。本人就随机划分了10%的训练集用于验证,剩下的90%进行训练。 在训练的时候,从头开始训练相对来说容易过拟合。因此我们最好是迁移学习,使用自带的预训练权重,然后进行微调。然后把不带CBAM注意力模块的层的参数冻结(前面两层),让网络相对保持一个泛性(毕竟是在ImageNet上预训练的),不然相对而言还是比较容易过拟合。 在含有卷积注意力层的参数,使用较小的学习率进行微调。这样基本不用考虑太多其他的超参数,就可以得到一个很不错的效果(在这种方式下,第一次就得到了94.6%的准确率,比之前高了不少)。
整个训练代码以后应该会放在自己的github上,届时会在博客中贴出来。 可视化 因为添加了注意力,想尝试将注意力可视化出来观察一下效果。可视化的方法有很多,主要参考了这篇文章(知乎),将CBAM空间注意力的attention map(非特征图)可视化了出来,代码就不再放出来了。 在测试集中随机选取了一张图片,大体效果是这样的,感觉还凑合。红色感兴趣的部分竟然额能把几朵花的大部分都包含进去。  
可能以后再优化优化,用类别激活可视化(Class Activation Mapping,CAM)等方式将整个网络的特征图可视化一下。
若本文有错误的地方,欢迎大佬批评指正。 |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |