Python数据分析与应用 |
您所在的位置:网站首页 › 民航数据分析python › Python数据分析与应用 |
Python数据分析与应用
|
Python数据分析与应用----航空公司客户价值分析
目录:
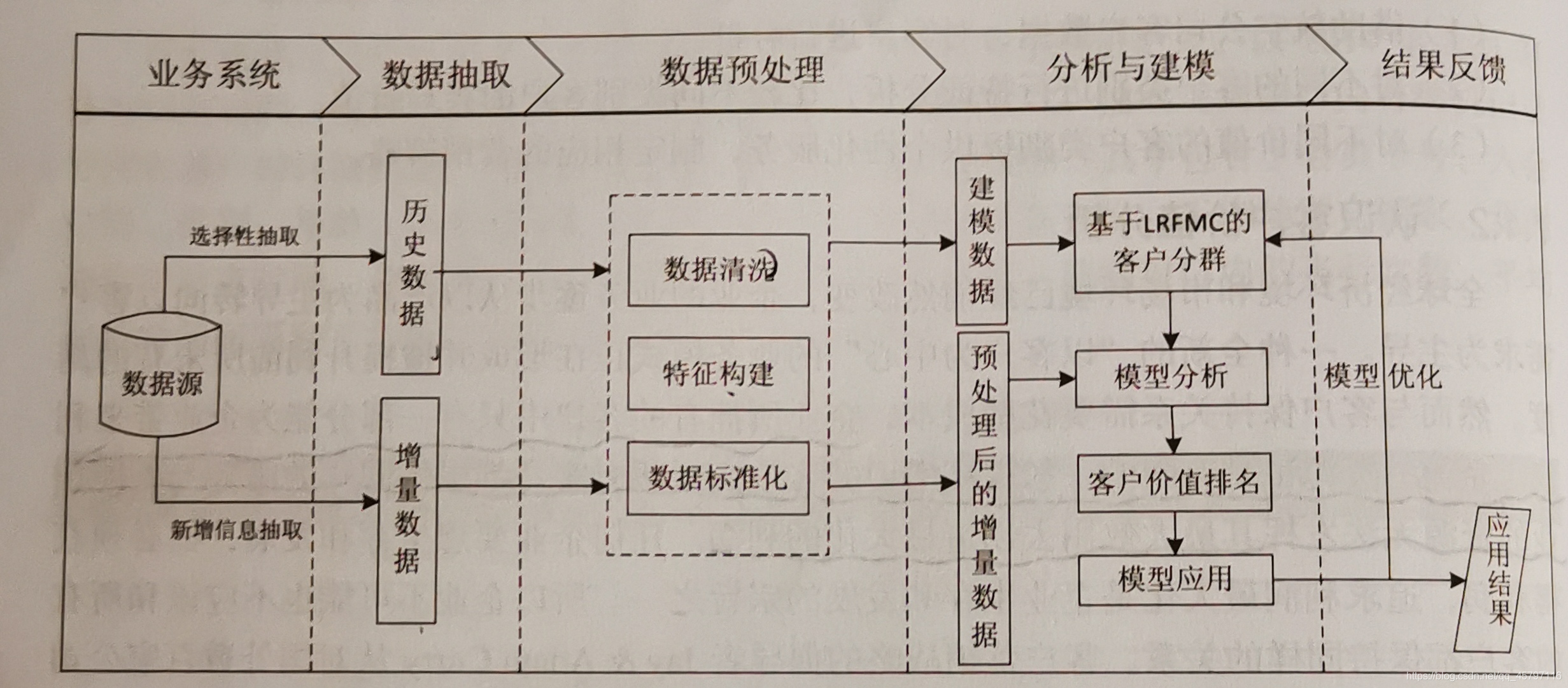
一、RFM模型 二、依据RFM模型预处理航空客户数据 1.数据清洗 2.特征构建 3.数据标准化 三、使用K-Means算法进行客户分群 四、聚类结果可视化 1.方法一 2.方法二 3.方法三 4.方法解析 某航空公司现状:以2014年3月31日为结束时间,选取宽度为两年的时间段作为分析窗口,抽取观测窗口内有乘机记录的所有客户的详细数据,形成历史数据62988条。 现进行对客户数据分析,将客户分类并比较不同类别客户的客户价值,以便提供个性化服务,制定相应的营销策略,具体流程如下: R(Recency)是指用户的最近一次消费时间与截止时间的间隔,用最通俗的话说就是,用户最后一次下单时间距今天有多长时间了,这个指标与用户流失和复购直接相关,关系到公司最近的走向。 F(Frequency)是指用户下单频率,就是用户在固定的时间段内消费了几次。这个指标反映了用户的消费活跃度。 M(Monetary)是指用户消费金额,其实就是用户在固定的周期内在平台上花了多少钱,直接反映了用户对公司贡献的价值。 本案例要求分类客户并对其价值分析评价,而识别客户价值应用最广泛的模型就是RFM模型。RFM模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱三项指标,来描述该客户的价值状况。 2、RFM模型有什么作用RFM模型可以对客户的终生价值做一个合理的预估,基于一个理想的客户特征来衡量现实中客户价值的高低,通过此类分析,定位最有可能成为品牌忠诚客户的群体,让我们把主要精力放在最有价值的用户身上。 返回顶部 二、依据RFM模型预处理航空客户数据依据流程图,我们对航空客户数据依次进行数据清洗、特征构建以及数据标准化处理。 1.数据清洗 import numpy as np import pandas as pd # 读取数据 airline_data = pd.read_csv('data/air_data.csv',encoding='gb18030') print('原始数据的形状为:',airline_data.shape) //原始数据的形状为: (62988, 44)利用notnull()方法取出非空数据,&—合并条件保留完整数据记录,loc切片保留最终非空数据。 # 取出票价为空值的数据 exp1 = airline_data['SUM_YR_1'].notnull() exp2 = airline_data['SUM_YR_2'].notnull() exp = exp1 & exp2 airline_notnull = airline_data.loc[exp,:] print('删除缺失记录后的数据形状为:',airline_notnull.shape) //删除缺失记录后的数据形状为: (62299, 44)既然分析有价值客户,就必须得有数据,对于那些虽然非空但是为0的数据也需要清理掉。注意:这里在SUM_YR_1、SUM_YR_2的0值去除时使用的是(index1|index2),本身这两个特征代表的是观测窗口票价收入,个人理解是这里的1、2代表了两个窗口,也就是说一个人在这两个窗口的记录均为0时,才表示该客户从来没有乘坐过飞机,数据异常。 # 只保留票价非0的,或者平均折扣率不为0的且总飞行千米数大于0的 index1 = airline_notnull['SUM_YR_1'] != 0 //保留观测窗口1不为零的数据 index2 = airline_notnull['SUM_YR_2'] != 0 //保留观测窗口2不为零的数据 index3 = (airline_notnull['avg_discount'] !=0) & (airline_notnull['SEG_KM_SUM']>0) airline = airline_notnull[(index1|index2) & index3] print('删除异常记录后的数据形状为:',airline.shape) //删除异常记录后的数据形状为: (62044, 44)返回顶部 2.特征构建基于RFM模型,我们需要能表示时间间隔的、表示单位时间内购买产品频率的以及单位时间内购买产品总资金的特征。但是由于航空票价受到运输距离和舱位等级的影响,同样的消费金额的不同旅客对于航空公司的价值是不同的。比如:短航线高等仓的客户就比长航线低等舱的客户价值更高些,所以此处借一段时间内的飞行里程(M)与舱位对应折扣系数的均值(C)来代替消费金额。另外,航空公司会员入会时间的长短在一定程度上也能够影响客户价值,所以在原来模型上添加客户关系长度(L),作为区分客户的另一特征。 模型LRFMC航空公司LRFMC模型会员入会时间距观测窗口结束的月数客户最近一次乘坐飞机距观测窗口结束的月数客户在观测窗口内乘坐飞机的次数客户在观测窗口累计的飞行里程客户在观测窗口内乘坐舱位对应折扣系数的均值R = LAST_TO_END F = FLIGHT_COUNTM = SEG_KM_SUM C = AVG_DISCOUNT对比模型与实际数据供应,我们发现在客户基本信息列中仅有表示客户入会员时间列,此时特征 L 需要我们自行构建。 L = LOAD_TIME - FFP_DATE # 选取构建 LRFMC 的特征 airline_selection = airline[['FFP_DATE','LOAD_TIME','FLIGHT_COUNT','LAST_TO_END','avg_discount','SEG_KM_SUM']] # 构建 L 特征 L = pd.to_datetime(airline_selection['LOAD_TIME']) - pd.to_datetime(airline_selection['FFP_DATE']) # 计算时间差---天数 L = L.astype('str').str.split().str[0] # 转换为数值类型,方便计算月数 L = L.astype('int')/30 # 计算月数 # 合并特征 airline_features = pd.concat([L,airline_selection.iloc[:,2:]],axis=1) print(airline_features) 0 FLIGHT_COUNT LAST_TO_END avg_discount SEG_KM_SUM 0 90.200000 210 1 0.961639 580717 1 86.566667 140 7 1.252314 293678 2 87.166667 135 11 1.254676 283712 3 68.233333 23 97 1.090870 281336 4 60.533333 152 5 0.970658 309928 ... ... ... ... ... ... 62974 108.300000 2 89 0.710000 368 62975 65.366667 2 121 0.670000 368 62976 45.400000 2 39 0.225000 1062 62977 15.533333 2 464 0.250000 904 62978 36.066667 2 282 0.280000 760 [62044 rows x 5 columns]返回顶部 3.数据标准化数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。 在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。 # 标准差标准化数据 from sklearn.preprocessing import StandardScaler data = StandardScaler().fit_transform(airline_features) np.savez('tmp/airline_scale.npz',data) print('标准化后 LRFMC 模型的5个特征为:\n',data) 标准化后 LRFMC 模型的5个特征为: [[ 1.43571897 14.03412875 -0.94495516 1.29555058 26.76136996] [ 1.30716214 9.07328567 -0.9119018 2.86819902 13.1269701 ] [ 1.32839171 8.71893974 -0.88986623 2.88097321 12.65358345] ... [-0.14942206 -0.70666211 -0.73561725 -2.68990622 -0.77233818] [-1.20618274 -0.70666211 1.6056619 -2.55464809 -0.77984321] [-0.47965977 -0.70666211 0.60304353 -2.39233833 -0.78668323]]返回顶部 三、使用K-Means算法进行客户分群K-Means算法是一种基于质心的划分方法,给定聚类个数K,以及包含n个数据对象的数据库,输出满足误差平方和最小标准的k个聚类,算法步骤如下: 1.从n个样本数据中随机选取k个对象作为初始的聚类中心2.分别计算出每个样本到各个聚类质心的距离,将样本分配到距离最近的那个聚类中心类别中3.所有样本分配完后,再重新计算k个聚类的中心4.与前一次计算得到的k个聚类中心比较,若聚类中心变化,返回步骤2,继续;否则转到55.当质心不发生变化时停止并输出聚类结果。聚类的结果依赖于初始聚类中心的随机选择。在实践中,为了得到好的效果,通常以不同的初始聚类中心多次运行K-Means算法。在所有的样本分配后,重新计算k个聚类的中心时,对于连续的数据,聚类中心取该簇的均值。
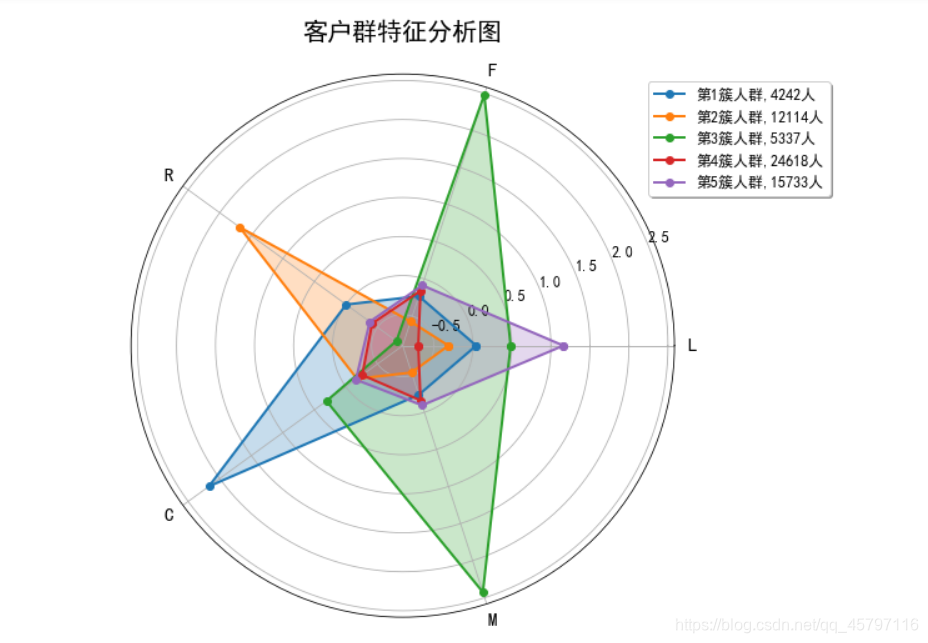
上面将ariline_scale保存时以单个数组形式保存,非关键字参数传递的数组自动取名为arr_0,所以在读取提出数据时要添加列名。 import pandas as pd import numpy as np from sklearn.cluster import KMeans //将多个数组保存到一个文件中的话,可以使用numpy.savez函数。savez函数的第一个参数是文件名,其后的参数都是需要保存的数组,也可以使用关键字参数 //为数组起一个名字,非关键字参数传递的数组会自动起名为arr_0, arr_1, …。savez函数输出的是一个压缩文件(扩展名为npz),其中每个文件都是一个 //save函数保存的npy文件,文件名对应于数组名。load函数自动识别npz文件,并且返回一个类似于字典的对象,可以通过数组名作为关键字获取数组的内容. ariline_scale = np.load('tmp/airline_scale.npz')['arr_0'] // 确定聚类中心数 k = 5 // 构建模型 kmeans_model = KMeans(n_clusters=k,n_jobs=4,random_state = 123) // 训练模型 fit_kmeans = kmeans_model.fit(ariline_scale) // 查看聚类中心 kmeans_model.cluster_centers_ array([[ 0.04240079, -0.23143046, -0.00322862, 2.17190116, -0.23585705], [-0.31316114, -0.57390748, 1.68689725, -0.17497219, -0.53673986], [ 0.48366129, 2.48319491, -0.79940665, 0.30924046, 2.42447899], [-0.70029836, -0.16066112, -0.41507386, -0.25783497, -0.16039479], [ 1.16094184, -0.08663559, -0.37743838, -0.15689301, -0.09454205]]) // 查看聚类样本的分类标签 kmeans_model.labels_ array([2, 2, 2, ..., 3, 1, 1]) // 统计不同类别的样本数目 r1 = pd.Series(kmeans_model.labels_).value_counts() print('最终分类每个样本的数目为:\n',r1) 最终分类每个样本的数目为: 3 24618 4 15733 1 12114 2 5337 0 4242 dtype: int64 四、聚类结果可视化 1.方法一:整理数据: import numpy as np import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = 'SimHei' plt.rcParams['font.size'] = 12.0 plt.rcParams['axes.unicode_minus'] = False # 统计不同类别的样本数目 r1 = pd.Series(kmeans_model.labels_).value_counts() # 找出聚类中心 r2 = pd.DataFrame(kmeans_model.cluster_centers_ ) r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目 r.columns = list(pd.DataFrame(ariline_scale).columns) + [u'类别数目'] #重命名表头 print(r) 0 1 2 3 4 类别数目 0 0.042401 -0.231430 -0.003229 2.171901 -0.235857 4242 1 -0.313161 -0.573907 1.686897 -0.174972 -0.536740 12114 2 0.483661 2.483195 -0.799407 0.309240 2.424479 5337 3 -0.700298 -0.160661 -0.415074 -0.257835 -0.160395 24618 4 1.160942 -0.086636 -0.377438 -0.156893 -0.094542 15733 center_num = r.values print(center_num) //[[ 4.24007883e-02 -2.31430460e-01 -3.22861506e-03 2.17190116e+00 // -2.35857054e-01 4.24200000e+03] // [-3.13161141e-01 -5.73907480e-01 1.68689725e+00 -1.74972187e-01 // -5.36739860e-01 1.21140000e+04] // [ 4.83661293e-01 2.48319491e+00 -7.99406654e-01 3.09240458e-01 // 2.42447899e+00 5.33700000e+03] // [-7.00298357e-01 -1.60661116e-01 -4.15073856e-01 -2.57834972e-01 // -1.60394792e-01 2.46180000e+04] // [ 1.16094184e+00 -8.66355853e-02 -3.77438378e-01 -1.56893014e-01 // -9.45420456e-02 1.57330000e+04]]绘图: fig=plt.figure(figsize=(10, 8)) ax = fig.add_subplot(111, polar=True) feature = ["入会时间", "飞行次数", "时间间隔差值", "平均折扣率", "总里程"] N =len(feature) for i, v in enumerate(center_num): // # 设置雷达图的角度,用于平分切开一个圆面 angles=np.linspace(0, 2*np.pi, N, endpoint=False) # 为了使雷达图一圈封闭起来,需要下面的步骤 center = np.concatenate((v[:-1],[v[0]])) angles = np.concatenate((angles,[angles[0]])) # 绘制折线图 ax.plot(angles, center, 'o-', linewidth=2, label = "第%d簇人群,%d人"% (i+1,v[-1])) # 填充颜色 ax.fill(angles, center, alpha=0.25) # 添加每个特征的标签 ax.set_thetagrids(angles * 180/np.pi, feature, fontsize=15) # 设置雷达图的范围 ax.set_ylim(min-0.1, max+0.1) # 添加标题 plt.title('客户群特征分析图', fontsize=20) # 添加网格线 ax.grid(True) # 设置图例 plt.legend(loc='upper right', bbox_to_anchor=(1.3,1.0),ncol=1,fancybox=True,shadow=True) # 显示图形 plt.show()
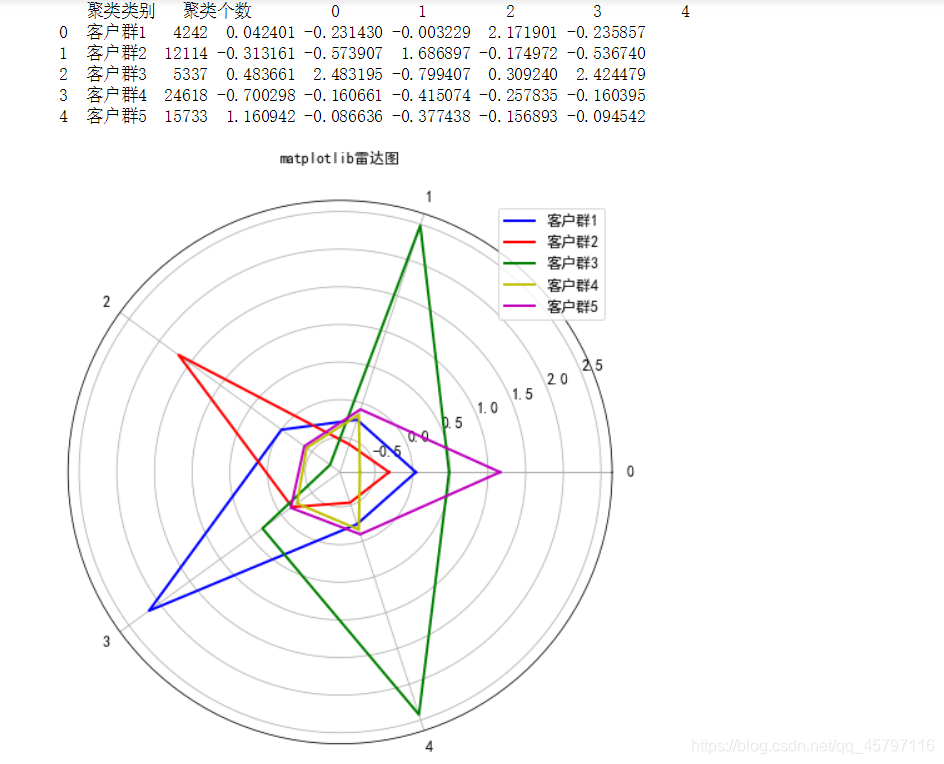
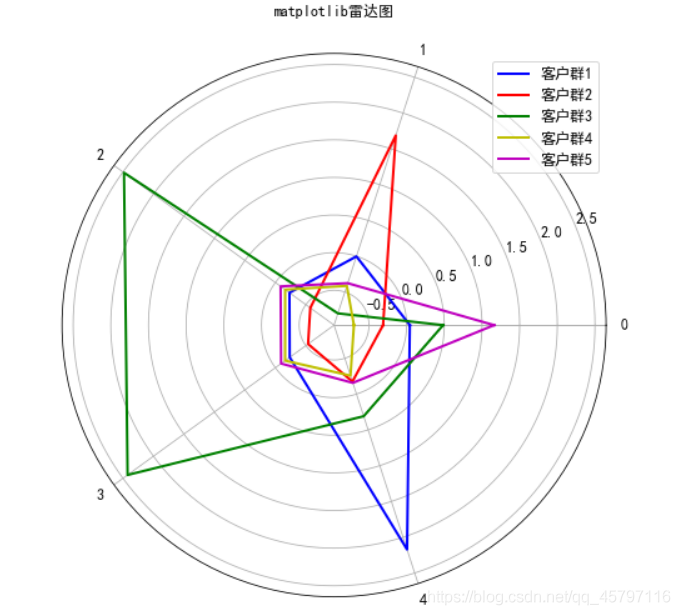
enumerate()枚举:设置变量时第二个变量代表所要枚举数据中的第i个值。 b=[1,2,3,4,5,6] for i,item in enumerate(b): print (i, item) Output: 0 1 1 2 2 3 3 4 4 5 5 6返回顶部 2.方法二:整理数据: r1=pd.Series(kmeans_model.labels_).value_counts() r2=pd.DataFrame(kmeans_model.cluster_centers_) r3=pd.Series(['客户群1','客户群2','客户群3','客户群4','客户群5',]) r=pd.concat([r3,r1,r2],axis=1) r.columns=['聚类类别','聚类个数']+list(pd.DataFrame(data).columns) print(r) 聚类类别 聚类个数 0 1 2 3 4 0 客户群1 4242 0.042401 -0.231430 -0.003229 2.171901 -0.235857 1 客户群2 12114 -0.313161 -0.573907 1.686897 -0.174972 -0.536740 2 客户群3 5337 0.483661 2.483195 -0.799407 0.309240 2.424479 3 客户群4 24618 -0.700298 -0.160661 -0.415074 -0.257835 -0.160395 4 客户群5 15733 1.160942 -0.086636 -0.377438 -0.156893 -0.094542 //转置 r4=r2.T r4.columns=list(pd.DataFrame(data).columns) y=[] for x in list(pd.DataFrame(data).columns): dt= r4[x] dt=np.concatenate((dt,[dt[0]])) y.append(dt)绘制图形: #绘制雷达图 // 设置中文 plt.rcParams['font.sans-serif']=['SimHei'] // 设置画布大小 fig = plt.figure(figsize=(10,8)) //标签 labels = np.array(list(pd.DataFrame(data).columns)) //数据个数 dataLenth = 5 //设置子图 ax = fig.add_subplot(111, polar=True) angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False) angles = np.concatenate((angles, [angles[0]])) ax.plot(angles, y[0], 'b-', linewidth=2) ax.plot(angles, y[1], 'r-', linewidth=2) ax.plot(angles, y[2], 'g-', linewidth=2) ax.plot(angles, y[3], 'y-', linewidth=2) ax.plot(angles, y[4], 'm-', linewidth=2) ax.legend(r3,loc=1) ax.set_thetagrids(angles * 180/np.pi, labels, fontproperties="SimHei") ax.set_title("matplotlib雷达图", va='bottom', fontproperties="SimHei") ax.grid(True) plt.show()
返回顶部 3.方法三: //做可视化: plt.figure(figsize=(6,6)) L=5 angles = np.linspace(0, 2*np.pi, L, endpoint=False) labels = ['L', 'F', 'R', 'C', 'M'] data = kmeans_model.cluster_centers_ //闭合曲线: angles = np.concatenate((angles, [angles[0]])) //为了形成闭合,把二维数组每一行下标为0的数拼接到列, // 二维数组与二维数组拼接, //所以reshape成二维的,且变成五列一行 data = np.concatenate((data, data[:,0].reshape(5,1)),axis=1).T // print('angles',angles) print('data:\n',data) //绘图: plt.polar(angles, data) plt.xticks(angles, labels) plt.show()
返回顶部 4.方法解析:其实说到底,要绘制这样的雷达图我们只需要两样东西:数据和绘图方法。绘图方法在matplotlib库中已经提供了,接下来就是我们找到数据,并加以处理,使之能够应用到绘图方法中去。 就拿第二种方法为例:(解析时为了方便代码会有所改动) 数据处理: r1=pd.Series(kmeans_model.labels_).value_counts() r2=pd.DataFrame(kmeans_model.cluster_centers_) r3=pd.Series(['客户群1','客户群2','客户群3','客户群4','客户群5',]) r=pd.concat([r3,r1,r2],axis=1) r.columns=['聚类类别','聚类个数']+list(pd.DataFrame(data).columns) print(r) 聚类类别 聚类个数 0 1 2 3 4 0 客户群1 4242 0.042401 -0.231430 -0.003229 2.171901 -0.235857 1 客户群2 12114 -0.313161 -0.573907 1.686897 -0.174972 -0.536740 2 客户群3 5337 0.483661 2.483195 -0.799407 0.309240 2.424479 3 客户群4 24618 -0.700298 -0.160661 -0.415074 -0.257835 -0.160395 4 客户群5 15733 1.160942 -0.086636 -0.377438 -0.156893 -0.094542 //转置 r4=r2.T r4.columns=list(pd.DataFrame(data).columns) y=[] for x in list(pd.DataFrame(data).columns): dt= r4[x] dt=np.concatenate((dt,[dt[0]])) y.append(dt)为了清洗方便的处理在得到聚类中心转为DataFrame时,直接设置了索引和列名,方便看出转置后的变化。 r1 = pd.Series(kmeans_model.labels_).value_counts() r2 = pd.DataFrame(kmeans_model.cluster_centers_,columns=['L', 'F', 'R', 'C', 'M'],index=['客户群1','客户群2','客户群3','客户群4','客户群5']) print('r2:\n',r2)
这一步至关重要,这幅图关键就是以闭合、多方位的形式展现数据。该步骤就是对每一列数据进行收尾闭合。numpy.concatenate() 方法能够解决闭合问题! y=[] for x in list(pd.DataFrame(data).columns): dt= r4[x] dt=np.concatenate((dt,[dt[0]])) y.append(dt) print(y)
1.matplotlib.pyplot.polar() 关于极区图 / 极坐标图 / 雷达图的绘制 2.matplotlib.pyplot.thetagrids() : matplotlib.pyplot.thetagrids() 方法用于获取并设置当前极区图上的极轴。 基本语法:matplotlib.pyplot.thetagrids(angles, labels=None, fmt=None, **kwargs) 参数描述angles网格线的角度,浮点数、度数组成的元组labels每个极轴要使用的文本标签,字符串组成的元组fmt格式化 angles 参数,如 ‘%1.2f’ 保留两位小数,注意,将使用以弧度为单位的角度**kwargs其他关键字参数,参见官方文档  3.np.linspace():
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None) 3.np.linspace():
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
在规定的时间内,返回固定间隔的数据。他将返回“num”个等间距的样本,在区间[start, stop]中。其中,区间的结束端点可以被排除在外。 属性说明start队列的开始值stop队列的结束值num要生成的样本数,非负数,默认是50endpoint若为True,“stop”是最后的样本;否则“stop”将不会被包含。默认为Trueretstep若为False,返回等差数列;否则返回array([samples, step])。默认为False、返回顶部 说明:会有人疑惑这里的图与教材上的图形不同,那是肯定的,按照教材上的代码画出来并非教材原图,因为教材给出的图是按照 LFRMC模型的顺序做的,可给出的源码实例并不是那个顺序。所以只需要在选择特征时把顺序改过来就好了,至于其他图形信息自行设置即可。 返回顶部 本文相关源码下载:https://download.csdn.net/download/qq_45797116/74466893 |
 依据上述RFM模型,在已知的数据特征中我们后期可以选取必要的特征进行分析。
依据上述RFM模型,在已知的数据特征中我们后期可以选取必要的特征进行分析。
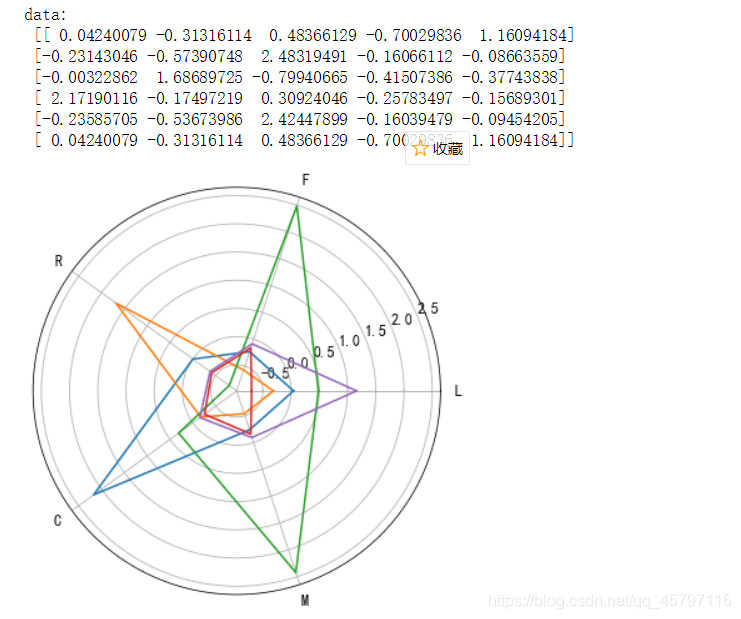
 利用转置,将数据行列互换位置,一列表示某一客户群的LFRCM模型数据
利用转置,将数据行列互换位置,一列表示某一客户群的LFRCM模型数据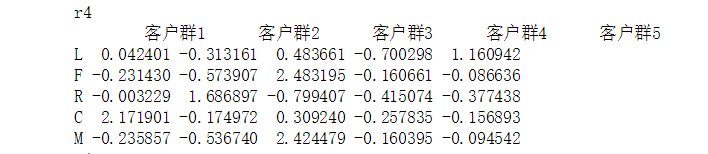 将数据表的列转换为数值型,否则下面循环时dt = r4[x]会报错,因为不该为数值型,在遍历匹配时,字符型不相匹配。还有一点就是,data在读取数据后类型为naddery不能直接赋.columns,需要将其转为DataFrame类型才可以。
将数据表的列转换为数值型,否则下面循环时dt = r4[x]会报错,因为不该为数值型,在遍历匹配时,字符型不相匹配。还有一点就是,data在读取数据后类型为naddery不能直接赋.columns,需要将其转为DataFrame类型才可以。
 反观方法一与方法三,在数据处理是都有这方面的考虑,只是三种方法考虑问题的先后。 所谓先后就是整体的流程: 1.找到数据,把数据处理好了,再去画图 2.在画图的同时,遍历处理当下对应的数据
反观方法一与方法三,在数据处理是都有这方面的考虑,只是三种方法考虑问题的先后。 所谓先后就是整体的流程: 1.找到数据,把数据处理好了,再去画图 2.在画图的同时,遍历处理当下对应的数据
 绘图: 在绘图这方面就是采用matplotlib库提供的绘图方法:
绘图: 在绘图这方面就是采用matplotlib库提供的绘图方法:
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |