机器学习算法(十):线性回归之最小二乘法 |
您所在的位置:网站首页 › 最小二乘法表达式 › 机器学习算法(十):线性回归之最小二乘法 |
机器学习算法(十):线性回归之最小二乘法
|
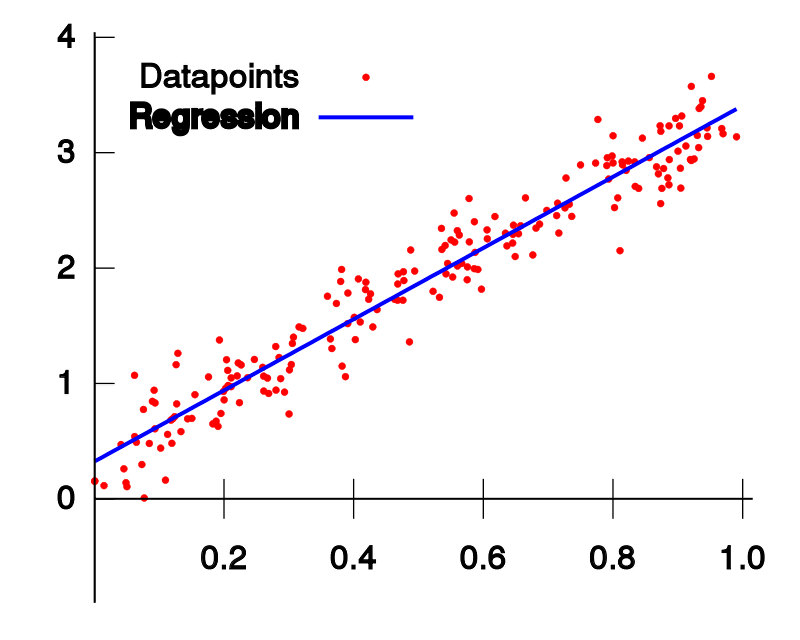
目录 1 线性回归 1.1 定义 1.2 目标函数(损失函数)的由来 2 最小二乘法 3 为什么线性回归要求假设因变量符合正态分布 4 python实现 1 线性回归 1.1 定义线性回归到底要干什么,顾名思义很简单,即在已有数据集上通过构建一个线性的模型来拟合该数据集特征向量的各个分量之间的关系,对于需要预测结果的新数据,我们利用已经拟合好的线性模型来预测其结果。关于线性回归的方法,现在使用得比较广泛的就是梯度下降和最小二乘法。 线性模型在二维空间中就是一条直线,在三维空间是一个平面,高维空间的线性模型不好去描述长什么样子;如果这个数据集能够用一个线性模型来拟合它的数据关系,不管是多少维的数据,我们构建线性模型的方法都是通用的。 吴恩达机器学习视频,第一节课讲的就是线性回归算法,课程里面提到了一个非常简单的案例:房屋估价系统。房屋估价系统问题就是当知道房屋面积、卧室个数与房屋价格的对应关系之后,在得知一个新的房屋信息后如何得到对应的新房屋价格,如果我们将房屋面积用x1表示,卧室个数用x2表示,即房屋价格h(x)可以被表示为房屋面积与卧室个数的一维线性方程: 这就是我们所说的线性模型,当然这个案例中只有房屋面积和卧室个数两个特征分量作,现实情况下我们要拟合的模型可能有相当多的特征分量,那么线性模型中对应的权重值θ也会有相同多的数量。为了方便表示我们使用矩阵和向量来表示这些数据: 向量θ(长度为n)中每一个分量都是估计表达式函数h(x)中一个参数,矩阵X(m*n)表示由数据集中每一个样本的特征向量所组成的矩阵。其实这样一个看起来很简单的式子,它的本质经常就是一个规模极其庞大的线性方程组。如果我们用向量Y(长度为m)来表示数据集的实际值,如果用实际值来建立一个方程组,参数向量θ中的每一个值就是我们要求的未知量;大多数情况下建立的是一个超定方程组(没有确定的解),这个时候我们只能求出超定方程组的最优解。 通过建立一个损失函数来衡量估计值和实际之间的误差的大小,我们将最小化损失函数作为一个约束条件来求出参数向量的最优解。 函数J(θ)即为损失函数,它计算出数据集中每一个样例的估计值和实际值的平方差并求取平均。然后就是我们的最小二乘法了,最小二乘法通过数学推导(后面给出证明)可以直接得到一个标准方程,这个标准方程的解就是最优的参数向量。 1.2 目标函数(损失函数)的由来先忽略什么是目标函数。对于上面的结论我们显然可以延展,对于n维的特征,如果用线性模型来求解的话,有: 而对于某个特征 i,其实际值与理论值肯定存在误差 此时,我们做第二个假设,我们假设每个特征值的误差都满足:独立、同分布。那么y可以写成: 由于我们假设了误差满足独立同分布,因此由 中心极限定理 可知误差之和必定能满足一个均值为0,误差为 把误差代入上述概率密度函数中,其结果就变成,在指定x下y关于 这样对于m个样本我们可以求它的似然函数L,经过一系列化简后得到 求似然函数的最大值,前一项为固定值,因此我们提取后一项,得到一个关于 我们定义观测结果 y 和预测结果 y' 之间的差别为Rss(和上文提到的J(θ)是一个意思): 设若参数的矩阵为θ,θ=(θ1,θ3……,θd,θ0)是一个((d+1)*1)的矩阵,θ0是常数参数。d代表样本由d个属性描述。 把数据集 D 表示一个 m*(d+1) 大小的矩阵 X。 则 h(X) = X * θ 那么 按照我们的定义,这个Rss的意思是y和y'之间的差,那么当Rss无限趋近于0的时候,则y≈y',即我们求得的预测结果就等于实际结果。 于是,令Rss等于某一极小值 对参数求导θ,得: 展开,得 进而就可以得到 于是我们就得到正规方程了。 附上机器学习西瓜书的讲解:
关于矩阵求导,详见:矩阵的求导_意念回复的博客-CSDN博客_前导不变后导转置 3 为什么线性回归要求假设因变量符合正态分布3指数分布族函数与广义线性模型(Generalized Linear Models,GLM)_意念回复的博客-CSDN博客_广义线性模型连接函数 4.3节。
广义线性模型不是一个模型,而是一类模型的总称,当一个模型属于指数分布族时,我们认为该模型是广义线性模型的一个特例,每一个特定的广义线性模型对应一个特定的分布,比如我们现在提到的线性回归模型,对应的是正态分布。 与之相似的,我们熟悉的逻辑斯蒂回归也是广义线性模型的特例,其对应的分布是伯努利分布。其他的还有泊松回归,对应泊松分布等。 广义线性模型中,每一个分布都对应存在一个正则联结函数(Canonical Link Function),这一函数的反函数可以将线性函数映射到该分布的期望。 举个例子,通过正态分布的正则联结函数的反函数,我们可以将线性模型映射到正态分布的期望值μ,这正是我们所熟悉的线性回归模型中所做的事情。 对于其他的模型,比如逻辑斯蒂回归,正是通过 sigmoid 函数将其映射到了伯努利分布的期望P其实说到这里,答案已经出来了,为什么线性回归要求假设因变量符合正态分布?这是因为线性回归对一个新的数据的预测值,其本身就是正态分布的期望,如果我们所使用的数据本身不符合正态分布,那么强行使用线性回归显然会得到一个很差的结果。 4 python实现使用sklearn上的boston房价预测数据集,对预测集进行预测,得到预测结果的评估结果RMSE。 # -*- coding: utf-8 -*- from sklearn import datasets from sklearn.model_selection import train_test_split import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt class LinearRegression: trained = False def __init__(self): pass def fit(self, feature, target): ''' 使用最小二乘法进行训练 ''' self.X = np.mat(feature) tem_max = np.ones((len(feature),1)) # 每个向量添加一个分量1,用来对应系数θ0 self.X = np.hstack((self.X, tem_max)) self.Y = np.mat(target).T print(np.shape(self.Y)) X_T = self.X.T # 计算X矩阵的转置矩阵 self.theta = (X_T * self.X).I * X_T * self.Y # 通过最小二乘法计算出参数向量 print(self.theta) self.trained = True def predict(self, feature): if not self.trained: print("You haven't finished the regression!") return pre_X = np.mat(feature) tem_max = np.ones((len(feature), 1)) pre_X = np.hstack((pre_X, tem_max)) predict_result = np.matmul(pre_X, self.theta) return predict_result def rmse(predict, test): MSE = np.sum(np.power((predict-test.reshape(-1, 1)), 2))/len(test) RMSE = np.sqrt(MSE) # MSE = np.sum(np.power((predict - test), 2)) / len(test) return RMSE def plot(test_feature, result): # 设置matplotlib 支持中文显示 mpl.rcParams['font.family'] = 'SimHei' # 设置字体为黑体 mpl.rcParams['axes.unicode_minus'] = False # 设置在中文字体是能够正常显示负号(“-”) plt.figure(figsize=(10,10)) # 绘制预测值 plt.plot(result, 'ro-', label="预测值") plt.plot(test_feature, 'go--', label="真实值") plt.xlabel("样本序号") plt.ylabel("房价") plt.title("线性回归预测-梯度下降法") plt.legend() plt.show() if __name__ == "__main__": # 加载数据 boston = datasets.load_boston() train_feature, test_feature, train_target, test_target = train_test_split(boston.data, boston.target, test_size=0.3, random_state=o) # print(train_feature, test_feature, train_target, test_target,sep="\n") # print(train_feature.shape, test_feature.shape, train_target.shape, test_target.shape, sep="\n") lr = LinearRegression() # 模型训练 lr.fit(train_feature, train_target) # 模型预测 predict_result = lr.predict(test_feature) # print(predict_result.shape, test_target.shape) # print(type(predict_result), type(test_target)) # rmse rmse_value = rmse(predict_result,test_target) print(rmse_value) plot(test_target, predict_result) |
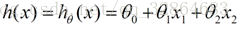
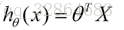
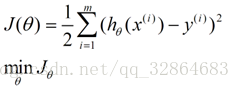
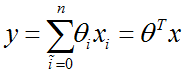
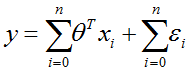

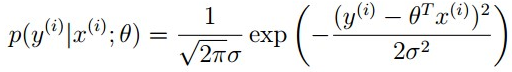
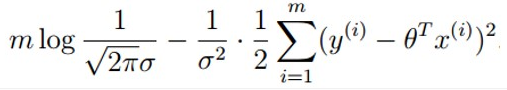
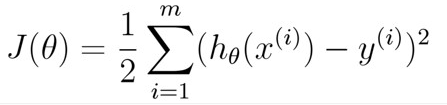
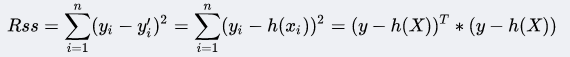
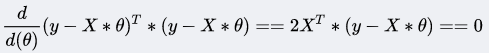



【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |