时间序列回归模型(Forecasting: Principles and practice第六章) |
您所在的位置:网站首页 › 最小二乘法β表达式 › 时间序列回归模型(Forecasting: Principles and practice第六章) |
时间序列回归模型(Forecasting: Principles and practice第六章)
|
6.1 the linear model 简单线性回归 最简单回归模型是预测变量y和单一预测因子x存在线性关系 多重线性回归(multiple linear regression) 当有两个或以上的自变量时,模型被称为多重回归模型,它的公式一般为: 假设 当使用线性回归模型时,我们隐式的对上面的多元线性回归公式中变量进行了一些假设: 首先,我们假设模型是对现实的合理近似;即预测变量与自变量间的关系满足该线性方程式 其次,我们对误差有以下假设 对于误差服从正态分布且有恒定的方差 线性回归模型的另一个假设是每个自变量都不是随机变量。如果我们在实验室中进行对照试验,我们可控制每个实验的值x(因为它们不是随机的),并观察结果值y。而在观测数据中(包括商业和经济学中大多数数据),我们就不能控制x的值,只能观察一下。所以在线性回归模型里,我们将每个自变量都不是随机变量看做是假设。 6.2 least squares estimation 实际上,我们有一系列观察值,但我们不确定它们的系数 Beta的标准误差(standard error):通过在相似的数据集上反复的估算beta所得到的关于beta的标准差。标准误差表示估计的beta系数里的不确定性。 t value(t值):它是估计的beta系数与其标准误差的比值 p-value:如果y值与相对应的变量x无相关性,那么估计出的该beta的最大概率值 拟合值 Y的预测可通过使用回归方程中估计系数并将误差项设为0来得到。一般如下式: 拟合优度 总结线性回归模型对数据的拟合程度方法是通过决定系数,或者说R^2.这可计算观测值和预测值相关性的平方,公式为: 回归方程的标准误差 另一种测量模型拟合数据效果的是用残差的标准差,通常称为残差的标准误差,公式如下: 6.3 evaluating the regression model 残差:观测到的y值与模型拟合的y值差异 在选择回归变量并拟合回归模型后,我们需要绘制残差图来检查是否满足模型的假设。 在选择回归变量并拟合回归模型后,我们需要绘制残差图来检查是否满足模型的假设。 ACF残差图 对于时间序列,在当前时间段观察到的变量的值很可能与之前时间段的值相似;因此,在将回归模型拟合到时间序列数据时,通常会在残差中找到自相关;这样就违背了误差中不存在自相关的假设。故为了获得更好的假设,模型应考虑这些残差中的剩余信息。具有自相关误差的模型预测仍然是无偏的(即残差平均值为0),故它也不是‘错误的’,但是它们通常会导致更大的预测间隔(或者说预测波动),所以我们需要查看残差的ACF图。 残差直方图 画直方图是看残差是否符合正态分布的好办法。 针对预测变量的残差图 我们期望的残差是随机分散而不显示任何系统模式;一种快捷的检查方法时针对每个预测变量检查残差的散点图。如果这些散点图显示了一种模式,则该关系可能是非线性的,故需要修改模型。另外,我们还需要针对模型中未包含的任何预测变量来绘制残差,如果其中任何一个显示了模式,那么我们可能需要将相应的预测变量添加到模型中。 Ex: 下图针对每个预测变量绘制的用于预测美国消费的多元回归模型的残差似乎是随机分散的。 因此,在这种情况下,我们对此感到满意。 异常值的来源之一是错误的数据输入;简单的描述性统计可识别不合理的最小值和最大值。如果发现了异常值,应该及时纠正或将其从样本中抽出。 当某些观察结果完全不同时,也可能出现异常值;但是,此时删除异常值并不明智。如果发现某个观测值是可能的异常值,则我们要对其进行研究并分析背后的可能原因。删除或保留观测值是一项具有挑战的决定,故明智的做法是在删除和不删除此类观察结果情况下报告结果(删除和不删除下进行对比)。 虚假回归(spurious regression) 时间序列数据通常是‘非平稳的’,即时间序列的值不会围绕恒定的平均值或恒定的方差波动,故我们需要解决非平稳数据对回归模型的影响。 Ex: 下图澳大利亚航空旅客对几内亚大米产量的回归就是虚假回归 如果类别多于两个,则可使用几个虚拟变量(比类别总数少一个)对变量进行编码。 季节性虚拟变量 假设以一周某天作为预测变量,则可创建以下虚拟变量。 干预变量(intervention variable) 通常要对影响预测的变量的干预措施(外生变量?)进行建模。如广告支出,产业行为等 当其影响仅持续一个时期时,我们用‘峰值’变量来表示。这也是个虚拟变量,在干预期间取值为1,其他期间取值为0.峰值变量等价于用于处理异常值得虚拟变量。 其他干预措施有立即的和永久的的效果;如干预导致水平移动(即该序列的值从干预之时起突然且永久改变),则我们用‘step’变量(步骤变量)。 Step变量(步骤变量):在干预之前取值为0,从干预开始取值为1. 永久效应另一种形式为斜率的变化;故干预是用分段线性趋势进行处理的;在干预时它的趋势是弯曲的,故它是非线性的。 Trading days(交易日) 一个月中交易日可能会相差很大,并可能对销售数据产生很大影响,所以我们将每个月的交易日作为预测指标。 另一种替代的方法是考虑每月里对应不同天的影响来构建变量: Distributed lags(分布滞后) 将广告支出作为预测指标通常很有用,但由于广告效果超出实际广告活动,故需要包含广告支出的滞后值。 复活节 对于复活节与大部分假期不同,它不在每年的同一天举行,故其影响可能会持续几天。此时,可以使用一个虚拟变量,其值为1(假日在特定时间内下降),否则为0. 用月度数据时,如果复活节在3月下降,那么虚拟变量在3月取值1,若在4月下降,则虚拟变量在4月取值为1;若复活节在三月开始且在四月结束,那么虚拟变量将按比例分配在月份间。(?难道在三月取值为0.3,四月取值为0.7进行拆分虚拟变量) 傅里叶级数 除用季节性虚拟变量,还可用傅里叶项;傅里叶证明选择一系列正弦和余弦项的正确频率可近似任何周期函数,我们可用于季节性模式。 若m为季节,则前几个傅里叶表示: 6.5 selecting predictors 当有许多可能的预测变量时,我们需要策略来选择回归模型中的最佳自变量。 不推荐对每个自变量和预测变量之间进行画图,因为有时候很难看出它们之间的相关关系,虽然这种方法很常用。 另一种无效的方法是对所有的自变量进行多元线性回归,而忽略有的自变量的p-value大于0.05. 因此,在这里我们可以用预测准确性度量,且将介绍5种此类方法。 1) adjusted R^2 为什么不用R^2 通常计算机会给出回归的R2,但R2不是一个很好的度量,因为R2不允许自由度,添加任何变量都会增加R2,即使该变量无关紧要。基于此,预测者不应使用R^2来确定模型是否会给出好的预测,因为这会导致过拟合。 一个等效的方法是选出给出最小平方误差和(SSE)的模型 2) cross validation 对于回归模型,也可用经典的留一交叉验证来选择自变量。它的步骤如下: i. 从数据集中移除观测值t,再用剩余的数据来拟合模型。再将观测值t代入模型得到yhat(t),计算得到误差e(t)=y(t)-yhat(t)。 ii. 对t=1,2,…, T,重复第i步 iii. 从e*(1), e*(2),…,e*(T)中计算得到MSE,我们称为CV。 3) Akaike’s information criterion 一个类似的方法是Akaike’s information criterion,它的定义是:
4) Corrected Akaike’s information criterion 对于观测值很少的T值,AIC往往会倾向于选择自变量很多的模型,故这里开发了一个AIC偏差纠正版: 5) Schwarz’s Bayesian information criterion Schwarz的贝叶斯信息准则被简写为BIC,或SBIC或SC,其公式为: 我们应该用哪种方法? 尽管R^2被广泛应用,且比其他方法应用了更长时间,但是其选择过多预测变量的趋势使其不太适合于预测。 许多统计人员喜欢用BIC,因为当如果存在真正的基础模型,则BIC将在给定足够数据情况下选择该模型;但是实际上,很少有真正的基础模型,且即使存在真正的基础模型,选择该模型也不一定给出最佳预测(因为参数估计可能不准确)。 因此,我们推荐使用AICc,AIC或者CV,它们每个都以预测为目标。如果T值足够大的话,它们都会推荐出相同的模型,故本书中大多数实例都用AICc值来选择预测模型。 最佳子集回归 在可能情况下,应拟合所有潜在的回归模型,并根据上面讨论的方法选择最佳模型;这称为“最佳子集回归”或“所有可能的子集”回归 逐步回归 如果有大量预测变量,则不可能拟合所有可能的模型,故需要一种策略来限制要探索的模型的数量。 一种很好的方法是向后逐步回归: 从包含所有潜在自变量的模型开始 一次删除一个自变量,如果可改善预测准确性的度量,则保留该自变量 迭代到一直没有进一步改善 如果潜在预测变量数量太大,则向后逐步回归不起作用,那么可以使用前向逐步回归。此过程从包含截距的模型开始,一次添加一个预测变量,而最能提高预测准确性的度量变量则保留在模型中,重复该过程,直到无法实现进一步的改进为止。 替代性地,对于后向或前向,起始模型可以使包括潜在预测子集的模型;此时,需要一个额外的步骤。对于后退过程,我们还应考虑在每个步骤添加一个自变量,对于前向过程,我们还可在每一步丢弃一个自变量,这个被称作混合过程。 需要注意的是,不能保证任何逐步的方法都能得出最佳的模型,但是几乎总能得出好的模型。 6.6 forecasting with regression 事前预测与事后预测 事前预测:仅使用预先提供的信息进行的预测。 事后预测:使用之后的预测器信息进行的预测 不应使用来自预测期的数据来估计产生事后预测的模型;事后预测可假定我们了解自变量(x变量),但不应假设要预测的数据(y变量)。 对事前预测和事后预测比较评估可帮助区分预测不确定性的来源,这显示是否是预测器的预测不佳或由于预测模型不佳而出现了预测错误。 建立预测回归模型 回归模型最大优势在于它们用于捕获感兴趣的自变量和因变量间重要关系。但一个挑战是为了生成事前预测,该模型需要每个预测变量的未来值。 一种表达方式是将其滞后值作为预测自变量,假设有h步的预测: 预测间隔 假设回归误差成正态分布,则与该预测相关的大约95%的预测间隔为: 最小二乘估计 通过最小化表达式来进行最小二乘估计: 预测和预测间隔 x*是包含自变量值的行向量,因此对于预测值可以得到: 6.8 nonlinear regression 有时候我们会用到非线性回归;为了使此部分简单,我们先假设我们只有一个预测自变量x。 建立非线性关系最简单的方法是在估算回归模型前,先对预测变量y和自变量x进行转换。尽管这提供了非线性函数的形式,但模型的参数是线性的,最常用的变换是(自然)对数。 Log-log(y-x都被转换为log)功能形式可指定为: 为了对变量进行对数转换,其所有观察值必须大于0,故如果x中包含0,那么我们可以通过log(x+1)进行转换,也就是说我们将变量增加1,然后再对其取对数,这和取对数有相似的效果,且避免了0的问题。它在原始比例上依然有0的作用,而在变换比例上仍为0. 某些情况下,仅转换数据是不够的,还需要更一般的规范,故我们可以修改为: 在标准(线性)回归中, 混杂的预测因素 一个相关问题涉及混淆变量。 Ex: 假设用2000-2011年的数据预测公司2012年的月度销售额;而2008年1月,一个新的竞争对手进入了市场,并占有了一定的市场份额。与此同时,经济开始下滑,在预测模型中,我们既要包括竞争对手的活动,也要包括经济状况。由于这两个预测变量的影响是相关的,故我们很难将其分开。我们说当两个变量对预测变量影响无法分开时,它们是混杂的。任何一对相关的预测变量都有某种程度的混淆,但除非它们的相关程度相对较高,否则我们通常不会将它们描述为混淆的。 混杂并不是预测的真正问题,因为我们仍可以计算预测而无需分离预测因素的影响。但是,由于方案应考虑预测变量间的关系,故方案预测成为一个问题。如果需要对各种预测变量的贡献进行一些历史分析,这也是个问题。 多重共线性和预测 一个与之相关的问题是多重共线性,当多重回归中两个或多个预测变量提供相似信息时,就会发生多重共线性。 当两个预测变量彼此高度相关(即它们的相关系数接近1或-1)时,就会发生这种情况。此时,知道其中一个变量的值就会得到很多关于另一个变量的值,因为它们正在提供相似的信息。 Ex:用脚的尺寸来预测身高,但在同一模型中包括左右脚的尺寸不能使预测变得更好,尽管也不会使它们变差。 之前讨论过的伪变量陷阱,假设季度数据有四个虚拟变量d1,d2,d3,d4.那么d4=1-d1-d2-d3,所以d4和d1+d2+d3有完全相关性。在完全相关的情况下,我们是无法估计回归模型的(因为回归矩阵中的x没有逆矩阵)。 如果存在高相关性(接近但不等于1或-1),那么回归系数的估计在估算上会很困难。而一些软件也会给出非常不准确的系数估计。 当存在多重共线性时,与各个回归系数相关的不确定性会很大,这是因为它很难估计。因此,对于回归系数的统计检验(如t检验)将不可靠。 此外,当多重共线性存在时,预测变量的未来值有可能会远远超出历史值的范围。 |
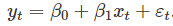 Beta0和beta1分别表示截距和斜率。Beta0表示当x=0时,预测值y;beta1表示平均预测变化y是由于x增加1个单位引起的。
Beta0和beta1分别表示截距和斜率。Beta0表示当x=0时,预测值y;beta1表示平均预测变化y是由于x增加1个单位引起的。  在这里,除非强制要求回归线穿过‘原点’,否则它应该始终包含在截距,即使当x=0时,截距与y的关系似乎不make sense。
在这里,除非强制要求回归线穿过‘原点’,否则它应该始终包含在截距,即使当x=0时,截距与y的关系似乎不make sense。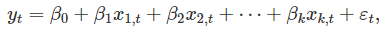 这里的每个自变量都必须是数字;而系数
这里的每个自变量都必须是数字;而系数 测量的是考虑了模型其他自变量后,每个自变量的影响。因此,这些系数从测量的也是自变量的边际效应。 Ex:
测量的是考虑了模型其他自变量后,每个自变量的影响。因此,这些系数从测量的也是自变量的边际效应。 Ex:  图6.5是五个变量的散点图矩阵。 第一列显示了预测变量(消耗量)与每个预测变量之间的关系。 散点图显示与收入和工业生产的正相关关系,与储蓄和失业的负相关关系。 这些关系的强度由第一行的相关系数表示。 其余的散点图和相关系数显示了预测变量之间的关系。
图6.5是五个变量的散点图矩阵。 第一列显示了预测变量(消耗量)与每个预测变量之间的关系。 散点图显示与收入和工业生产的正相关关系,与储蓄和失业的负相关关系。 这些关系的强度由第一行的相关系数表示。 其余的散点图和相关系数显示了预测变量之间的关系。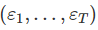 : 它们的均值为0;否则预测的结果是有偏的 它们不会自相关;否则预测将变得效率低下,因为数据中有更多的信息可以被挖掘。 (?这是不是意味着误差如果存在自相关,那么还有有效的信息没有被挖掘) 自变量彼此间不相关;否则应该在模型的系统部分中包含更多的信息
: 它们的均值为0;否则预测的结果是有偏的 它们不会自相关;否则预测将变得效率低下,因为数据中有更多的信息可以被挖掘。 (?这是不是意味着误差如果存在自相关,那么还有有效的信息没有被挖掘) 自变量彼此间不相关;否则应该在模型的系统部分中包含更多的信息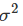 ,就容易产生预测间隔。
,就容易产生预测间隔。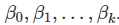 ,故我们需要从数据中估计他们。 最小二乘原理提供了一种通过最小化平方误差和来有效选择系数的方法。即我们选择
,故我们需要从数据中估计他们。 最小二乘原理提供了一种通过最小化平方误差和来有效选择系数的方法。即我们选择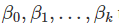 来最小化
来最小化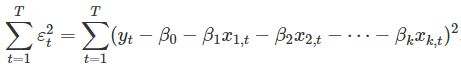 。 这被称为最小二乘估计,因为它为平方误差的和给出了最小值。找到系数的最佳估计值被称为使模型适合数据,或被称为训练模型。 当我们参考估计系数时,我们将用
。 这被称为最小二乘估计,因为它为平方误差的和给出了最小值。找到系数的最佳估计值被称为使模型适合数据,或被称为训练模型。 当我们参考估计系数时,我们将用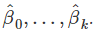 来表示。
来表示。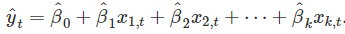 插入值
插入值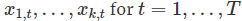 能够返回训练样本里的预测值yt,它也被称为拟合值。注意这些用于估算模型的数据预测,不是对未来价值的真实预测y。
能够返回训练样本里的预测值yt,它也被称为拟合值。注意这些用于估算模型的数据预测,不是对未来价值的真实预测y。 
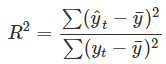 ,其中求和是贯穿所有观测值的求和,故它反映了回归模型所占的预测变量中变化的比例。
,其中求和是贯穿所有观测值的求和,故它反映了回归模型所占的预测变量中变化的比例。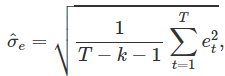 这里的k表示x变量的数量;注意到我们用T-k-1去除,这是因为我们估计了k+1个参数(截距及每个变量对应的系数)。 标准误差与模型产生的平均误差大小有关;我们可将此误差与样本均值进行比较或是和y的标准偏差进行比较,从而对模型准确性有更进一步了解。 在生成预测区间时将使用标准误差。
这里的k表示x变量的数量;注意到我们用T-k-1去除,这是因为我们估计了k+1个参数(截距及每个变量对应的系数)。 标准误差与模型产生的平均误差大小有关;我们可将此误差与样本均值进行比较或是和y的标准偏差进行比较,从而对模型准确性有更进一步了解。 在生成预测区间时将使用标准误差。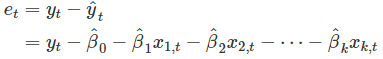 每个残差都是对应的观测值中不可预测的部分,而这些残差都包含了一些有效的属性:
每个残差都是对应的观测值中不可预测的部分,而这些残差都包含了一些有效的属性: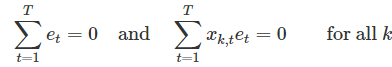 。 很明显,残差的平均值为0,且残差与变量的观测值的相关性也等于0(即残差与变量不相关).
。 很明显,残差的平均值为0,且残差与变量的观测值的相关性也等于0(即残差与变量不相关). 残差和拟合值 残差和拟合值也不应显示任何模式,如果观察到了模式,则残差中可能存在‘异方差性’,即残差的方差可能是不恒定的。如果出现该问题,则需要对预测变量y(如对数或平方根)进行转换。简言之,出现残差的异方差性需要变换y值。 Ex: 下图显示了针对拟合值绘制的残差。 随机散点图表明误差是同方差的。
残差和拟合值 残差和拟合值也不应显示任何模式,如果观察到了模式,则残差中可能存在‘异方差性’,即残差的方差可能是不恒定的。如果出现该问题,则需要对预测变量y(如对数或平方根)进行转换。简言之,出现残差的异方差性需要变换y值。 Ex: 下图显示了针对拟合值绘制的残差。 随机散点图表明误差是同方差的。  离群值和有影响的观察 相比大多数数据,采用极值的观测值称为离群值。对回归模型估计系数有很大影响的观察值称为有影响的观察值。通常,有影响力的观察值也是离群值。
离群值和有影响的观察 相比大多数数据,采用极值的观测值称为离群值。对回归模型估计系数有很大影响的观察值称为有影响的观察值。通常,有影响力的观察值也是离群值。 回归非平稳时间序列会导致虚假回归,高R^2和高残差自相关可能是虚假回归的迹象;虚假回归似乎能给出合理的短期预测,但通常不会在未来继续发挥作用。
回归非平稳时间序列会导致虚假回归,高R^2和高残差自相关可能是虚假回归的迹象;虚假回归似乎能给出合理的短期预测,但通常不会在未来继续发挥作用。  6.4 some useful predictors 趋势 时间序列呈趋势性很常见;线性趋势可以通过
6.4 some useful predictors 趋势 时间序列呈趋势性很常见;线性趋势可以通过 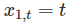 作为预测量,
作为预测量,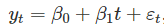 虚拟变量(dummy variable) 当预测变量仅包含两个值(是或否)的分类变量时,可通过创建虚拟变量(0和1)来表示;1表示是,0表示否,故虚拟变量也被称为“指标变量”。 虚拟变量也可用于说明数据中异常值,。但虚拟变量不会忽略异常值,而是会消除其影响。此时,虚拟变量观测值为1,其他所有值为0. Ex: 预测到巴西旅游人数时,需要考虑2016巴西夏季奥运会影响。
虚拟变量(dummy variable) 当预测变量仅包含两个值(是或否)的分类变量时,可通过创建虚拟变量(0和1)来表示;1表示是,0表示否,故虚拟变量也被称为“指标变量”。 虚拟变量也可用于说明数据中异常值,。但虚拟变量不会忽略异常值,而是会消除其影响。此时,虚拟变量观测值为1,其他所有值为0. Ex: 预测到巴西旅游人数时,需要考虑2016巴西夏季奥运会影响。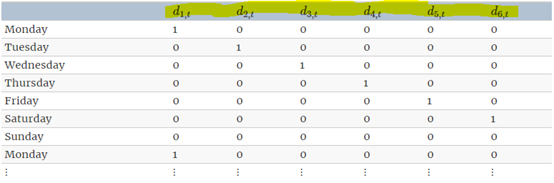 注意:只需要六个伪变量就能对7个类别进行编码,这是由于第7类(本例中‘星期天’)是由截距获得,且在虚拟变量都设置为0时指定。 与虚拟变量关联的每个系数解释是:它是该类别相对于省略类别的影响的度量。上例中与星期一相关联的系数
注意:只需要六个伪变量就能对7个类别进行编码,这是由于第7类(本例中‘星期天’)是由截距获得,且在虚拟变量都设置为0时指定。 与虚拟变量关联的每个系数解释是:它是该类别相对于省略类别的影响的度量。上例中与星期一相关联的系数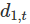 将衡量相对于周日,周一对因变量Y的影响。
将衡量相对于周日,周一对因变量Y的影响。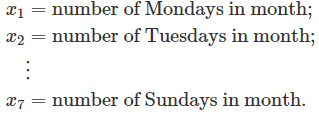 注意:这里之所以要构建7个变量,是因为考虑每月天数是不固定的,所以它是将每月的天数做进一步拆分到从周一到周日的天数。
注意:这里之所以要构建7个变量,是因为考虑每月天数是不固定的,所以它是将每月的天数做进一步拆分到从周一到周日的天数。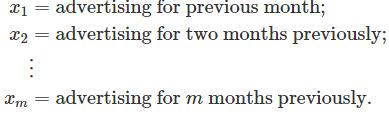 通常会要求随着滞后的增加而降低系数。
通常会要求随着滞后的增加而降低系数。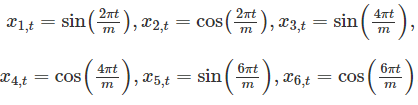 若有每月的季节性,且有这些预测变量的前11个,则我们将获得与使用11个虚拟变量完全相同的预测(?不是很理解)。 与虚拟变量相比,傅里叶项通常需要更少的自变量,尤其是当m很大时(要求频率更高),比如m=52对应一年。对于短的季节性时段,使用傅里叶项相比季节性虚拟变量几乎没有优势。 通常包含傅里叶项的回归模型被称为谐波回归(harmonic regression),因为连续的傅里叶项表示前两个傅里叶项的谐波(?不是很明白)。
若有每月的季节性,且有这些预测变量的前11个,则我们将获得与使用11个虚拟变量完全相同的预测(?不是很理解)。 与虚拟变量相比,傅里叶项通常需要更少的自变量,尤其是当m很大时(要求频率更高),比如m=52对应一年。对于短的季节性时段,使用傅里叶项相比季节性虚拟变量几乎没有优势。 通常包含傅里叶项的回归模型被称为谐波回归(harmonic regression),因为连续的傅里叶项表示前两个傅里叶项的谐波(?不是很明白)。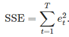 一种替代的方法是使用adjusted R^2。
一种替代的方法是使用adjusted R^2。 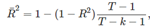 这里的T是观测值,k是自变量个数;这是对R^2的改进,因为它将不会随着自变量增多而增大。故adjusted R^2最大的模型将是最好的模型,它也等价于最小化其调整后的standard error。
这里的T是观测值,k是自变量个数;这是对R^2的改进,因为它将不会随着自变量增多而增大。故adjusted R^2最大的模型将是最好的模型,它也等价于最小化其调整后的standard error。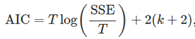 这里的T是观测值的数量,k是模型中预测变量的数量。不同的软件包中可能对AIC的定义略有不同,但它们都会通过AIC选择出最好的模型。等式中的k+2表示模型中有k+2个参数(k个自变量,以及一个截距和一个因变量y)。这里是用需要估计的参数数量来惩罚模型(SSE)的拟合度。 模型中有最小的AIC通常是最好的预测模型。对于很大的T值,最小化AIC等价于最小化CV值。
这里的T是观测值的数量,k是模型中预测变量的数量。不同的软件包中可能对AIC的定义略有不同,但它们都会通过AIC选择出最好的模型。等式中的k+2表示模型中有k+2个参数(k个自变量,以及一个截距和一个因变量y)。这里是用需要估计的参数数量来惩罚模型(SSE)的拟合度。 模型中有最小的AIC通常是最好的预测模型。对于很大的T值,最小化AIC等价于最小化CV值。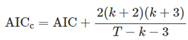 和AIC类似,这里的最小化的corrected AIC也是最优的模型。
和AIC类似,这里的最小化的corrected AIC也是最优的模型。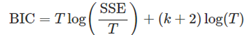 与AIC一样,最小化BIC也是为了提供最佳的模型;BIC选中的模型要么和AIC一样,要么会有更少的自变量,这是因为相比AIC,BIC对于参数数量增加有着更大的惩罚项。对于较大的T值,最小化BIC类似于留出v值进行交叉验证,当v=T[1-1/(log(T)-1)].
与AIC一样,最小化BIC也是为了提供最佳的模型;BIC选中的模型要么和AIC一样,要么会有更少的自变量,这是因为相比AIC,BIC对于参数数量增加有着更大的惩罚项。对于较大的T值,最小化BIC类似于留出v值进行交叉验证,当v=T[1-1/(log(T)-1)].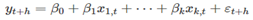 包含预测变量的滞后值不仅使模型易于操作以轻松生成预测,且还使其直观地吸引人。
包含预测变量的滞后值不仅使模型易于操作以轻松生成预测,且还使其直观地吸引人。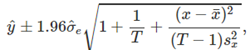 6.7 matrix formulation 多重回归可以写为:
6.7 matrix formulation 多重回归可以写为: 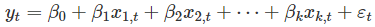 其中
其中 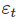 的均值为0,方差为
的均值为0,方差为 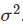 它可以被写为矩阵形式:
它可以被写为矩阵形式: 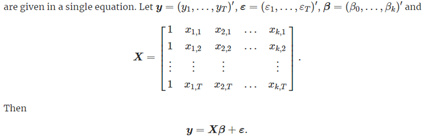 这里
这里 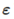 满足均值为0,方差为
满足均值为0,方差为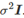 ;其中X矩阵有T行反映出有T个观测值,而k+1列则反映出有k个自变量和一个截距项。
;其中X矩阵有T行反映出有T个观测值,而k+1列则反映出有k个自变量和一个截距项。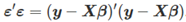 这里最小化beta值可以表示为:
这里最小化beta值可以表示为: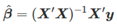 它也被称作“正态方程”。对于估计系数需要矩阵求逆得到
它也被称作“正态方程”。对于估计系数需要矩阵求逆得到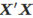 ;如果X不是全列矩阵,那么
;如果X不是全列矩阵,那么 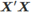 是奇异的,且模型不能被估计。 对于余项的方差可以被估计为:
是奇异的,且模型不能被估计。 对于余项的方差可以被估计为: 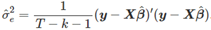 拟合值和交叉验证 正常的方程表明,拟合值可被表示为:
拟合值和交叉验证 正常的方程表明,拟合值可被表示为: 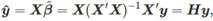 这里
这里 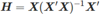 ,其中H被称为‘hat-matrix’,这是因为它被用来计算‘y-hat’。 如果对角线值H用来表示
,其中H被称为‘hat-matrix’,这是因为它被用来计算‘y-hat’。 如果对角线值H用来表示 ,则交叉验证可被计算为:
,则交叉验证可被计算为: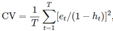 ,这里的et是计算所有T个观察值后的余项。
,这里的et是计算所有T个观察值后的余项。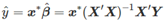 这里它的估计方差是
这里它的估计方差是 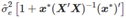 。 其中,95%的预测间隔可以被计算为(假设误差满足正态分布):
。 其中,95%的预测间隔可以被计算为(假设误差满足正态分布): 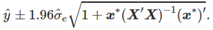 这考虑了由于误差项引起的不确定性ε,以及系数估算的不确定性?。但它忽略了x∗,故如果预测变量的未来值不确定,那么用此表达式计算的预测间隔将太窄。
这考虑了由于误差项引起的不确定性ε,以及系数估算的不确定性?。但它忽略了x∗,故如果预测变量的未来值不确定,那么用此表达式计算的预测间隔将太窄。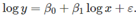 该模型中,斜率Beta1可被解释为弹性的,beta1含义是x增加1%,对应的y平均变化百分比。 Log-linear形式是只对预测因变量y进行log转换; Linear-log形式是通过对自变量x进行log转换。
该模型中,斜率Beta1可被解释为弹性的,beta1含义是x增加1%,对应的y平均变化百分比。 Log-linear形式是只对预测因变量y进行log转换; Linear-log形式是通过对自变量x进行log转换。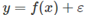 在这里f可以是非线性函数。
在这里f可以是非线性函数。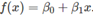 而在非线性回归规范中,我们可以让f成为更灵活的非线性函数x,而不是简单的对数或其他的转换。 最简单的变换之一是对f进行线性分段,而分段点可被称为节点。举例如下:
而在非线性回归规范中,我们可以让f成为更灵活的非线性函数x,而不是简单的对数或其他的转换。 最简单的变换之一是对f进行线性分段,而分段点可被称为节点。举例如下: 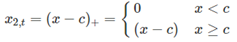 预测非线性趋势 对于非线性趋势预测,最简单的方式是使用二次或高次项:
预测非线性趋势 对于非线性趋势预测,最简单的方式是使用二次或高次项: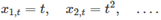 ,但是不建议在预测中使用二次或更高阶趋势,因为在对其进行推断时,得出的预测通常是不现实的。 更好的方法还是使用上面介绍的分段法,并拟合在某个时间点弯曲的分段线性趋势,我们可以将其视为由线性块构成的非线性趋势。
,但是不建议在预测中使用二次或更高阶趋势,因为在对其进行推断时,得出的预测通常是不现实的。 更好的方法还是使用上面介绍的分段法,并拟合在某个时间点弯曲的分段线性趋势,我们可以将其视为由线性块构成的非线性趋势。  6.9 correlation, causation and forecasting 相关性不是因果关系 一个变量x可能对预测因变量y有用,但并不意味着x造成y;它可能是x造成了y,但也可能是y造成了x,或者说它们之间的关系比简单的因果关系更为复杂。 需要注意的是,即使两个变量之间没有因果关系,或者相关性与模型的方向相反,相关性对于预测也很有用。
6.9 correlation, causation and forecasting 相关性不是因果关系 一个变量x可能对预测因变量y有用,但并不意味着x造成y;它可能是x造成了y,但也可能是y造成了x,或者说它们之间的关系比简单的因果关系更为复杂。 需要注意的是,即使两个变量之间没有因果关系,或者相关性与模型的方向相反,相关性对于预测也很有用。【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |