中文文本拼写检查错误纠正方案整理 |
您所在的位置:网站首页 › 整理的正确拼音 › 中文文本拼写检查错误纠正方案整理 |
中文文本拼写检查错误纠正方案整理
|
说明: 该文档主要考察平安文本纠错项目和爱奇艺文本纠错项目整理而来。 1. 常见的中文错误类型发音错误, 特点:音近,发音不标准, 原因:地方发音,语言转化。 - 灰机 拼写错误:特点: 正确词语错误使用, 原因: 输入法导致-拼音、五笔、手写 - 眼睛蛇 语法,知识错误: 特点:逻辑错误,多字、少字,乱序 - 女性患病前列腺炎 2. 研究现状 2.1 通用纠错项目https://github.com/shibing624/pycorrector 错误检测 常用字典匹配: 切词后不再常用字典中认为有错统计语言模型:某个字的似然概率低于句子的平均值混淆字典匹配:example - 国藉 -> 国籍候选召回 近音字替换(拼音): 藉\ji -> 籍, 集, 寄。。。近形字替换(五笔): 藉 -> 籍,藕,箱候选排序 语言模型计算句子概率,取概率超过原句子切最大的 P(患者1天前体检发现脾动脉瘤) P(患者1天前体检发现皮动脉瘤) P(患者1天前体检发现劈动脉瘤) 2.2 学术界进展基于序列标注的纠错 《 Alibaba at IJCNLP-2017 Task 1: Embedding Grammatical Features into LSTMs for Chinese Grammatical Error Diagnosis Task 》 利用序列标注模型 + 人工提取特征进行错误位置的标注 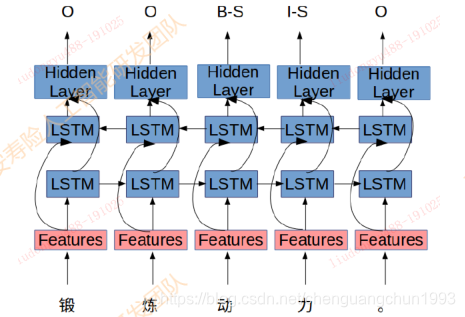 2017年IJCNLP举办的CGED比赛中阿里团队提出的Top1方案 成绩: P:0.36, R: 0.21, F1:0.27基于NMT的纠错 《 Youdao’s Winning Solution to the NLPCC-2018 Task 2 Challenge: A Neural Machine Translation Approach to Chinese Grammatical Error Correction 》 利用模型将错误语句翻译成正确语句,利用transformer模型完成端到端的纠错过程
过纠率 / 误报率 F A R = 正 确 句 子 被 纠 错 的 个 数 正 确 句 子 的 个 数 FAR = \frac{正确句子被纠错的个数}{正确句子的个数} FAR=正确句子的个数正确句子被纠错的个数 召回率 R = 错 误 句 子 被 改 正 的 句 子 数 错 误 的 句 子 总 数 R = \frac{错误句子被改正的句子数}{错误的句子总数} R=错误的句子总数错误句子被改正的句子数 纠错目标 被改正的句子数 >> 被改错的句子数 K ∗ R > > ( 1 − K ) ∗ F A R K * R >> (1 - K) * FAR K∗R>>(1−K)∗FAR 目标在于尽可能的提高召回率R。 2.4 存在的问题 公司目前纠错现状,还存在一下问题。 缺乏标注语料,难以展开基于深度学习的监督学习纠错强调实时性,对内存和实效性要求很高,线上纠错不得超过10ms/句,导致大规模字典和复杂模型无法线上使用纠错要求高准确性,宁愿牺牲召回也必须保证高准确度,防止过纠(把正确的词改错),过纠率不得高于0.2%结合电子病历,绝大部分错误都是替换错误,同音字,同行字等。 3. 平安文本纠错方案 平安人寿问答纠错模块结构如下图所示。其基本流程包括错误检测、候选召回、候选排序、候选筛选。 基于规则的错误检测 拼音匹配: 适合实体错误检测,比如疾病,药品等实体,需要维护拼音-实体隐射字典
拼音编辑距离:1. 检测所有编辑距离小于阈值的路径 2. 最优路径选取(最小拼音编辑距离, 最长字符匹配)3. 语言模型 + 规则联合筛选 单双向2gram检测 当前词与上下文组成的2gram词频很低,认为有错 基于假设: 正确表述发生的频次要远远大于错误表述发生的次数
基于神经网络语言模型的错误检测 核心思想: 通过完形填空的方式预测候选字的概率分布如果原字的概率不在topK或者top1比值操作阈值则认为有错改进措施: 传统的语言模型从左到右,单向,只利用上文,改为双向模型,利用上下文信息。 传统的语言模型把预测字MASK,没有预测字的信息,可以改为引入当前字的混淆字信息(如:相似的字音和字形字)。 传统语言模型会直接预测字表,比如字表大小是3800,预测结果会直接得到3800个字的概率分布,其中大多是无用信息,且容易引发维度灾问题。可以通过将预测字约束在近音、近形和混淆字表里,提高效率和正确字与错误中字的区分度。
基于word2vec-cbow改造的音字混合受限字表示语言模型检测算法 基于CSLM的中文拼写检测:《Chinese Spelling Errors Detection Based on CSLM,2015》 主要特征: 带入预测字及上下文拼音、五笔特征去掉前后鼻音和翘舌音,并利用混淆音集映射的方式来提高模型对谐音错误的识别性能。预测字表受限于近音字、近形字和混淆字表中。
近音字候选召回 选择近音字作为候选字,构造一个近音字字典。大规模的基础字典,使得在存储和读取速度方面收到了极大的调整。 字典存储构架如下:
关键技术: 减低存储空间: 利用Trie树降低信息冗余利用经典结合CSR压缩稀疏矩阵使用词典间的关联信息回复2gram同音字典提高读取速度:Trie树、CSR技术的高效索引。 字、音编辑距离召回 使用编辑距离作为是否召回的依据。 混淆词集 疾病口语词 3.3 候选排序 针对候选词的排序主要由二级排序来实现。 一级排序 模型:逻辑回归LR 作用:二级排序比较耗时,通过一级排序初筛出TopK进入下一级 要求:正类召回率高,运行速度快 特征: 频次比值:候选频次越高分数越高编辑距离:编辑距离越小分数越高拼音jaccard距离:拼音相近分数越高4gram-LM概率差值:候选替换后橘子越通顺分数越高一级排序大致流程如下:
例如:甲状腺姐姐该怎么治疗? ->结节 0.99 频次: 55 -> 94 编辑距离:2 拼音jaccard距离:0 语言模型概率:-21.9 -> -8.6 二级排序 模型:xgboost 作用:分数超过设定阈值且是Top1作为最终候选 要求:正类准确率高 特征: 局部特征 切词变化:短语个数、含错别字片段长度等PMI变化:最小值、最值频次变化:频次变化、2gram频次变化4gram语言模型变化形音变化:拼音韵母变化、jccard距离、五笔变化其他:停用词\错别字位置、候选来源等等 全局特征 Cbow-LMLSTM-Attention-LMBERT-LM
例子:红癍狼仓常见症状有哪些? 红斑狼疮 频次 :20 -> 1688切词:红\癍\狼疮 (1\1\2) -> 红斑狼疮 (4)nn语言模型:癍 ( 斑 (0.979)4gram语言模型:-19.2 -> -10.6PMI:红癍(0.33) ->红斑(9.7) 3.4 整体架构
特性: pipline串联,热插拔 子模块均遵循检测-召回-排序流程 规则+模型混用 离线+在线 在线方案: 低延迟、低复杂度高速1ms-3ms/句用于线上实时预测离线方案: 大规模、复杂模型低速200ms-500ms/句用于构造在线模型,训练数据 3.5 总结与改进 优点: 无监督,方便将该方法迁移到其他垂直领域,只需要重新无监督挖掘数据系统架构方便插拔特殊编写纠错子模块 缺点: 很难迁移到通用领域Pipline导致错误逐级传递Pipline链越长,耗时越长 改进思路 强化上下文/全局的语义理解训练预料去噪处理端到端算法,如NMT(神经机器翻译)语法错误(多字少字乱序) 4. 爱奇艺文本纠错方案《FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm》 4.1 背景 大部分的中文拼写检查模型都使用用一个范式,即讲每个汉字的固定相似字符集(混淆集或困惑集)作为候选项,然后使用过滤器选择最佳候选项作为错字的替换字符。这种设计面临着两个主要瓶颈: 稀疏的中文拼写检查数据上的过拟合问题。 由于中文拼写检查数据需要乏味繁冗的专业人力工作,因为一直资源不足。为了防止模型的过拟合, Wang等人(2018)提出了一种自动方法来生成伪拼写检查数据。 但是,当生成的数据达到40k句子时,其拼写检查模型的精度不再提高。 Zhao等人(2017)使用了大量的语言学规则来过滤候选项,但结果却比我们的表现差,尽管我们的模型没有利用任何语言学知识。 困惑集的使用带来的汉字字符相似度利用上的不灵活性和不充分性问题。 困惑集因为是固定的,因此并非在任何语境、场景下都能包含正确候选项(一个比较极端的例子是,如果困惑集按照繁体中文制定,那么繁体中文的 “體”和“休”肯定不在困惑集的同一组相似字符中,但是在简体中文中对应的“体”和“休”缺是相似字符,如果错误文本中是把“休”写成了“体”,那么繁体中文困惑集下就无法检出,必须专门再制定一个简体困惑集才可以),这会极大降低检测的召回率(不灵活性问题);另外,困惑集中的字符的相似性的信息有损失,没有得到充分利用,因为一个字符在困惑集中相似字符是无差别对待的,然而事实上每两个字符间的相似度明显是有差别的,因此会影响检测的精确率(不充分性)。 4.2 设计 FASPell提出通过设计中文拼写检查范式来避免传统模型的两个瓶颈。FASPell利用seq2seq的思想,包括去噪自编码器(DAE)和解码器。 编码器DAE DAE通过利用无监督预训练方法(BERT),减少了监督学习中所需的中文拼写检查数据量( |
 成绩: P: 0.34, R:0.18, F0.5: 0.29
成绩: P: 0.34, R:0.18, F0.5: 0.29








【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |