流式大处理的三种框架对比:Storm,Spark和Flink |
您所在的位置:网站首页 › 数据处理的主要目的 › 流式大处理的三种框架对比:Storm,Spark和Flink |
流式大处理的三种框架对比:Storm,Spark和Flink
|
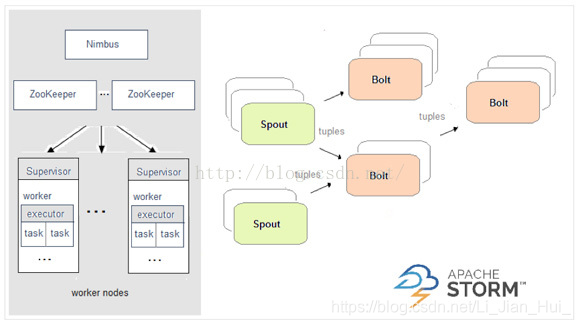
storm、spark streaming、flink都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,允许你在运行数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行,都提供了简单的API来简化底层实现的复杂程度。 Apache Storm在Storm中,先要设计一个用于实时计算的图状结构,我们称之为拓扑(topology)。这个拓扑将会被提交给集群,由集群中的主控节点(master node)分发代码,将任务分配给工作节点(worker node)执行。一个拓扑中包括spout和bolt两种角色,其中spout发送消息,负责将数据流以tuple元组的形式发送出去;而bolt则负责转换这些数据流,在bolt中可以完成计算、过滤等操作,bolt自身也可以随机将数据发送给其他bolt。由spout发射出的tuple是不可变数组,对应着固定的键值对。
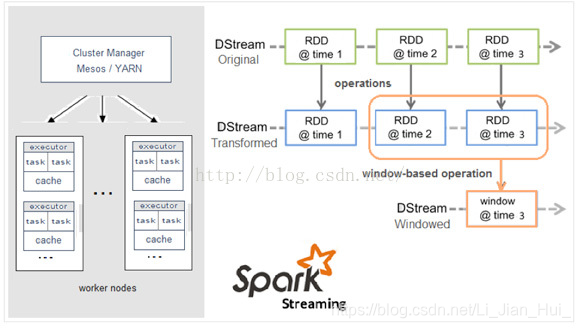
Spark Streaming是核心Spark API的一个扩展,它并不会像Storm那样一次一个地处理数据流,而是在处理前按时间间隔预先将其切分为一段一段的批处理作业。Spark针对持续性数据流的抽象称为DStream(DiscretizedStream),一个DStream是一个微批处理(micro-batching)的RDD(弹性分布式数据集);而RDD则是一种分布式数据集,能够以两种方式并行运作,分别是任意函数和滑动窗口数据的转换。
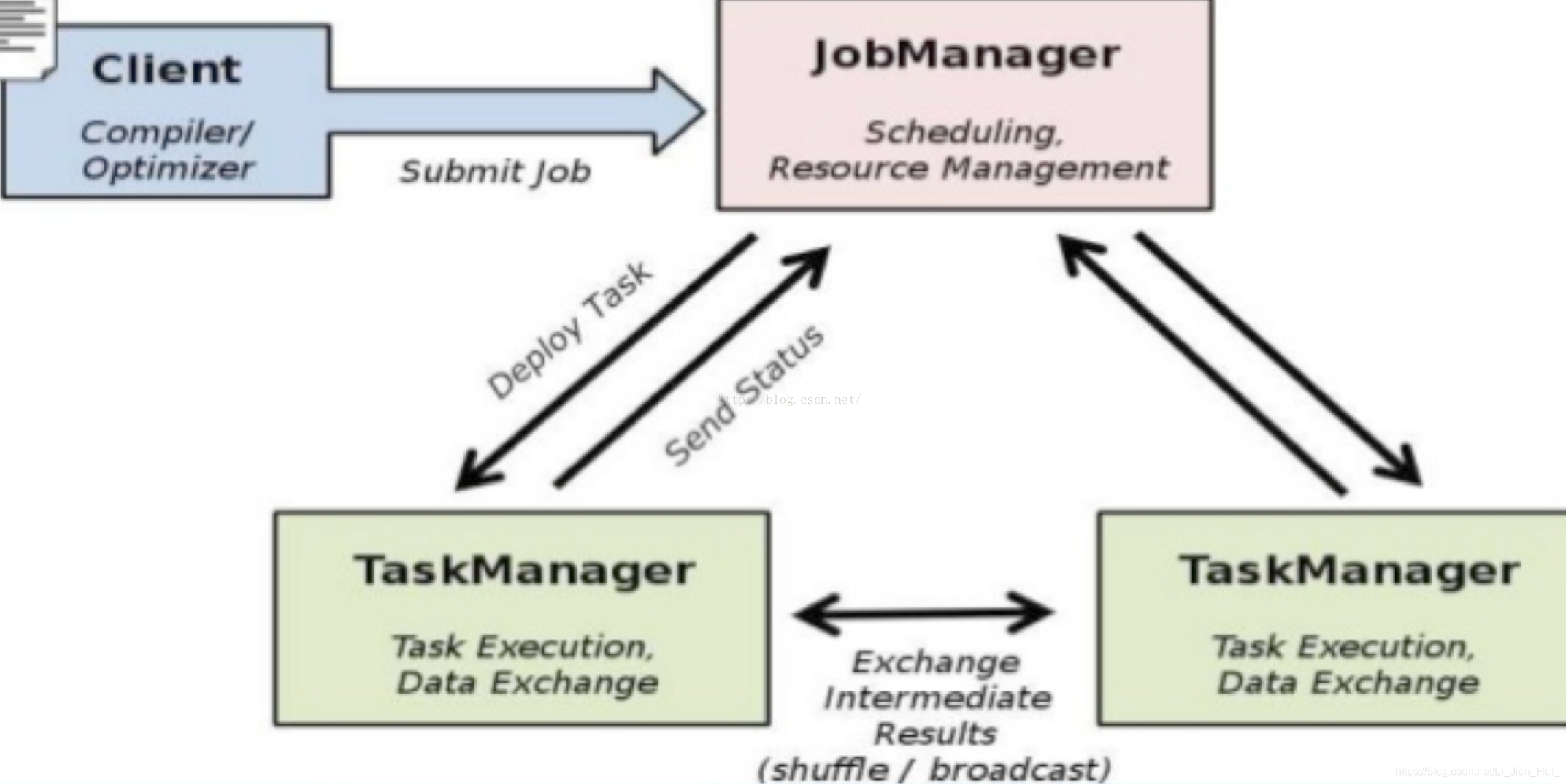
Flink 是一个针对流数据和批数据的分布式处理引擎。它主要是由 Java 代码实现。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。再换句话说,Flink 会把所有任务当成流来处理,这也是其最大的特点。Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。并且 Flink 可以定制化内存管理。在这点,如果要对比 Flink 和 Spark 的话,Flink 并没有将内存完全交给应用层。这也是为什么 Spark 相对于 Flink,更容易出现 OOM 的原因(out of memory)。就框架本身与应用场景来说,Flink 更相似与 Storm。 Flink 的架构图。 |
 对比图:
对比图: 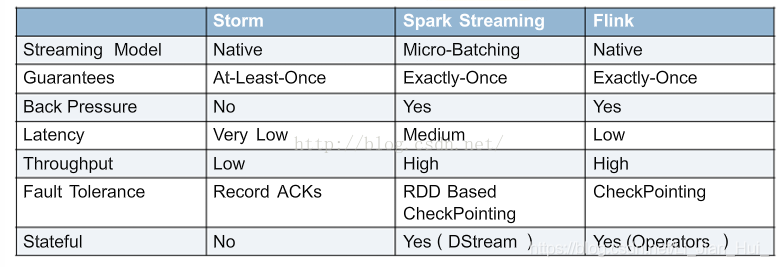 (比较源自大牛的PPT,现在新版storm有很多改进,比如自动反压机制之类,另外storm trident API也能提供有状态操作与批处理等)
(比较源自大牛的PPT,现在新版storm有很多改进,比如自动反压机制之类,另外storm trident API也能提供有状态操作与批处理等)【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |