爬取招聘数据进行数据分析及可视化 |
您所在的位置:网站首页 › 数据分析人员公司招聘信息 › 爬取招聘数据进行数据分析及可视化 |
爬取招聘数据进行数据分析及可视化
|
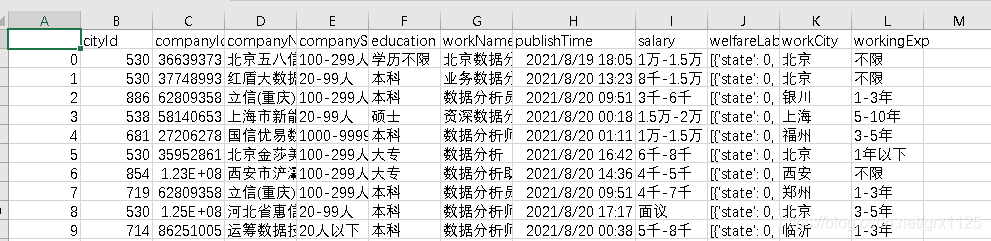
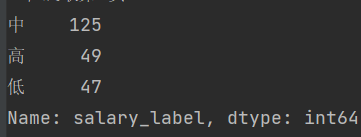
爬取招聘信息,对数据分析行业目前就业形式进行数据分析,大体流程如下: 1.通过requests模块获取指定的某招聘信息。 2.用pandas进行数据清洗。 3.用matplotlib进行数据的可视化。 导入需要用到的包: import requests import time import random import json import pandas as pd import matplotlib.pyplot as plt 第一部分 爬取该网址获取到第三页需要验证登录,需要获取大量数据的朋友可以添加个cookie验证。数据量变大也不影响后面进行数据分析。 访问是Ajax请求,需要用到post请求附带Request Payload信息才能拿到数据。通过断点,找到对应的js加密,分析数据加密方式,模拟加密即可~ # 获取的页数,获取前三页,更多获取需要cookie page_num_max = 3 class Recruitment_info(): """获取全国各地相应职业招聘信息""" def __init__(self): # 某招聘搜索网址,跳过登录 self.zhilian_url = 'https://m.zhaopin.com/api/sou/positionlist' def get_page(self,search_content,page_num): """获取网址,返回对应html。该网页是post请求""" # 拼接网址,自定义搜索内容 url = self.zhilian_url headers = {'user-agent':self.get_ua()} data = self.get_data(search_content,page_num) html = requests.post(url=url,headers=headers,data=data).text # 调试 # print(f"get_page successful,url:{url} \n html:{html}") return html # 根据断点,找到加密方式。 def get_data(self,search_content,page_num): """生成动态的Request Payload信息""" t = "0123456789abide" d = 'XXXXXXXX-XXXX-4XXX-XXXX-XXXXXXXXXXXX' for i in range(35): t_rd = random.choice(t) d = d.replace('X', t_rd, 1) data = { 'S_SOU_FULL_INDEX': search_content, 'S_SOU_WORK_CITY': "489", 'at': "", 'channel': "baidupcpz", 'd': d, # 每次请求都会变,动态加载。 'eventScenario': "msiteSeoSearchSouList", 'pageIndex': page_num, 'pageSize': 20, 'platform': 7, 'rt': "", 'utmsource': "baidupcpz", } return json.dumps(data) def get_ua(self): """user-agent池,返回随机ua""" ua_list = ['Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)', 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'] return random.choice(ua_list) def Data_cleaning(self,html): '''将收集到的js数据进行清洗''' resurt = json.loads(html) resurt = resurt['data']['list'] data_list = [] for per_info in resurt: data = { # 'cityDistrict' : per_info['cityDistrict'], # city 城市 'cityId' : per_info['cityId'], # cityid 城市id 'companyId' : per_info['companyId'], # companyId 公司id 'companyName' : per_info['companyName'], # 'companyName' 公司名称 'companySize' : per_info['companySize'], # 公司大小 'education' : per_info['education'], # 'education' 教育 'workName' : per_info['name'], # 'name' 公司性质 'publishTime' : per_info['publishTime'], # 'publishTime' 发布时间 'salary' : per_info['salary60'], # 'salary60' 薪资 'welfareLabel' : per_info['welfareLabel'], # 'welfareLabel' 工作福利 'workCity' : per_info['workCity'], # 'workCity' 工作地点(省) 'workingExp' : per_info['workingExp'] # 工作经验 } data_list.append(data) return data_list def save_data_csv(self,df): """将数据保存至本地的CSV""" df.to_csv(path_or_buf='./数据.csv', encoding='gbk') def run(self,*search_content): """控制整个代码运行""" # 收集3页数据 data_list = [] for content in search_content: print('正在获取',content) for num in range(page_num_max): # 获取网页源码 print('正在获取第%d页'%(num+1)) html = self.get_page(content,num+1) # 数据清洗 data_list.extend(self.Data_cleaning(html)) time.sleep(random.random()*5) # 休息时间 # 生成dataframe方便后续数据操作 else: df = pd.DataFrame(data_list) self.save_data_csv(df) return df # 获取并初步清洗 spider = Recruitment_info() df = spider.run('数据分析','数据运营','数据专员','数据') 以上代码执行完毕我们会得到一个 数据.csv,看起来还不错,我们进行下一个部分。 由于我们在获取阶段已经将数据保存至了CSV,所以直接用pandas中函数直接读取CSV即可。 pandas默认的列和宽度较少不便观看,通过set_option调整最大列数为10,整个列宽为200。 # 设置显示多列数据 pd.set_option('display.max_columns', 10) # 不限列数 pd.set_option('display.width',200) # 读取数据 df = pd.read_csv('./数据.csv',encoding='gbk') 数据清理获取的数据较乱,没有可以直接用来分析的数据,下面我们进行清理。 分列 薪资将会是一个重要指标,我们先进行清理,将salary列分成最低工资bottom和最高工资top,再进行平均计算。 # 定义一个进行数据清理的函数 def bottom_top(x, num=0): """将每行工资数据进行清理,将工资统一以K为单位。分割成两列 返回指定的列,num=0为最低列、num=1为最高列""" if len(x.split('-')) > 1 and x.find('天') == -1: x = x.split('-')[num] if x.find('千') != -1: x = float(x[0:x.find('千')]) elif x.find('万') != -1: x = float(x[0:x.find('万')]) * 10 return x else: return 0 # 用apply将函数应用到salary的每一行数据 df['bottom'] = df.salary.apply(lambda x : bottom_top(x,0)) df['top'] = df.salary.apply(lambda x : bottom_top(x,1)) # 增加平均值列 df['avg'] = (df['bottom']+df['top'])/2切片 这样我们就会得到三个新的列,我们再将工资划分成3个等级,以0-5k为“低”,5-10k为“中”,10k以上为“高”。 # 对薪资水平进行切片处理,划分为低、中、高作为新增一列salary_label df['salary_label'] = pd.cut(df.avg,bins=[0,5,10,max(df.avg)],labels=['低','中','高']) print(df.salary_label.value_counts()) # 中 134 高 56 低 38关于数据岗位的薪资还是不错的,结果如图:
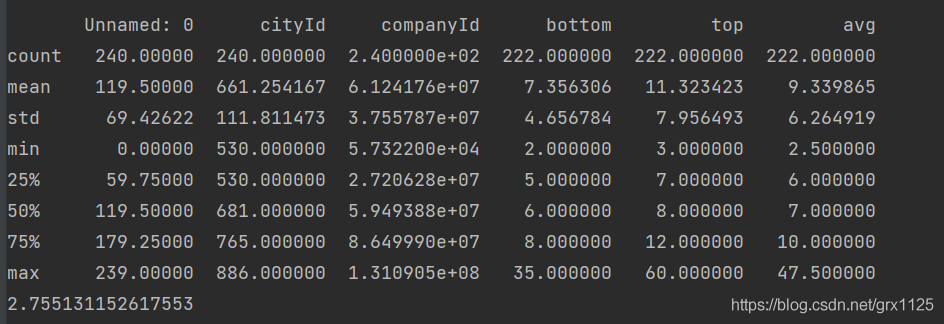
分析 再做一些简单的描述性数据分析 # 查看数据类型 print(df.info()) # 查看数据描述统计 print(df.describe()) # 查看偏度 print(df.avg.skew())其中describe和skew结果如下:
从初步的分析来看,全国对于数据分析行业,平均薪资为9.8k,中位数为7k,同时skew=2.8可以看出数据正偏(右偏)分布,说明有少部分工资很高的岗位拉高了平均值。 # 以城市进行分组 df_gb = df.groupby(['workCity']) # 招聘数据岗位最多的前五个城市 print('职位数量前五名:', df_gb.count().sort_values('cityId', ascending=False).head()['cityId'], sep='\n')结果如下:
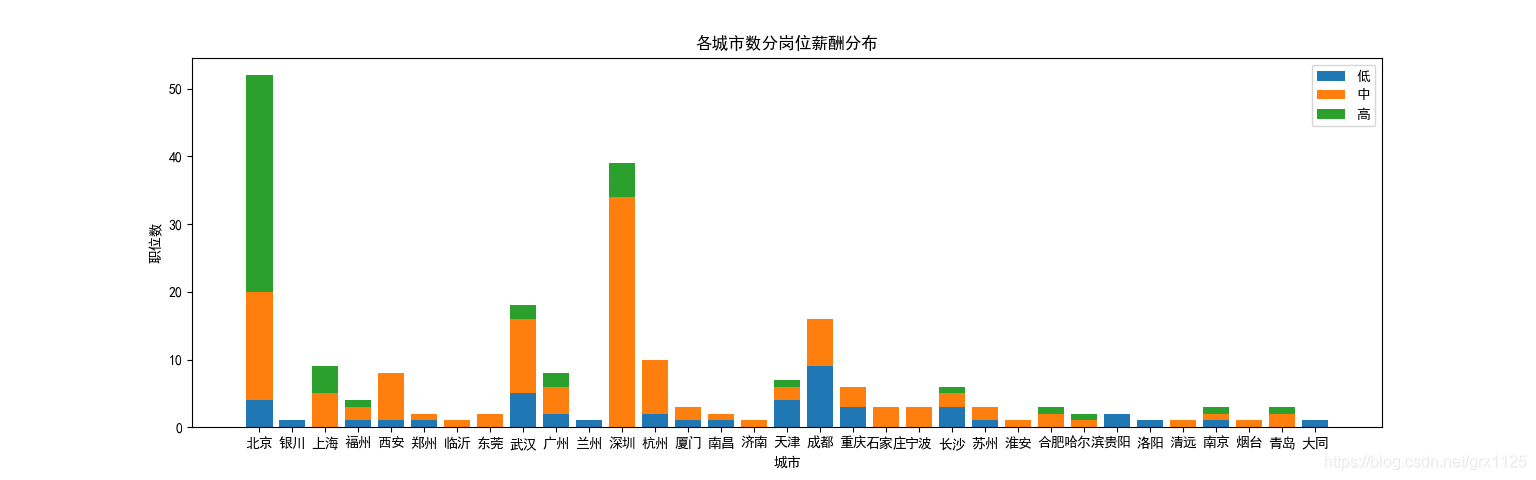
我们设置字体设置为黑体,不然会有乱码出现 # 下面开始用matplotlib作图 # 设置字体编码,防止乱码 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['font.serif'] = ['SimHei'] # 堆积柱状图以每个城市薪资低中高进行堆积 df_bar=df_gb.apply(lambda x: x.value_counts('salary_label')) # 将原表city去重 city_s = df.drop_duplicates('workCity')['workCity'] # 建立三个表的y值 有的城市低中高有缺失,只能以城市分组 li1 = [] li2 = [] li3 = [] # 用来做为堆积柱状图的bottom,避免柱状图显示出错 li12 = [] for city in city_s: li1.append(df_bar[city]['低']) li2.append(df_bar[city]['中']) li3.append(df_bar[city]['高']) li12.append(df_bar[city]['中']+df_bar[city]['低']) # 进行条形图的堆叠 plt.bar(x=city_s,height=li1,label = '低') plt.bar(x=city_s,height=li2,bottom=li1,label = '中') plt.bar(x=city_s,height=li3,bottom=li12,label = '高') # 设置坐标轴 plt.xlabel("城市") plt.ylabel("职位数") # 显示标签,标题 plt.legend() plt.title('各城市数分岗位薪酬分布') # 显示图表 plt.show()最后我们得出柱状图,显然一见对于数据岗位,北京、深圳、武汉、成都较为多,北京的高工资岗位相对来说最多。
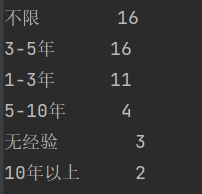
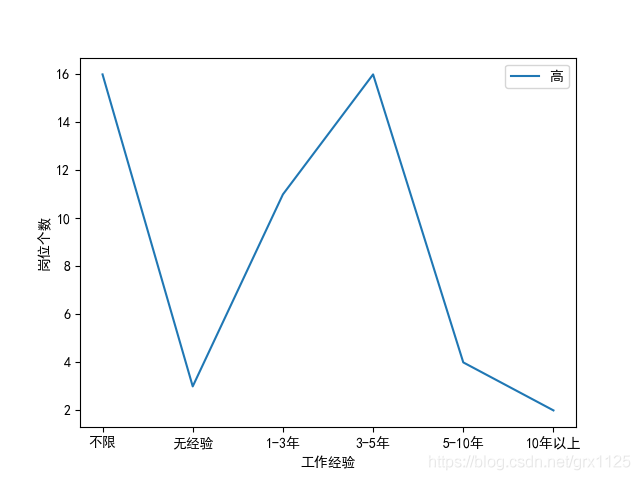
可以看出3-5年的数据岗位需求最大,如图:
我们进行排序和可视化 # 进行排序 df_plot = pd.DataFrame(data=df_plot) if df_plot.size == 6: df_plot['num'] = [0, 3, 2, 4, 1, 5] # 根据不限,无经验,1-3,3-5,5-10,10以上排序 df_plot = df_plot.sort_values('num') # 可视化 df_plot = df_plot.iloc[:,0].plot(label='高') plt.xlabel("工作经验") plt.ylabel("岗位个数") plt.legend() plt.show()可以判断出,数据岗位的工作年限黄金段在于3-5年 。
以上就是本章全部内容了,由于数据量太少,分析的很片面,有兴趣的朋友可以将数据源获取加大,结果更加准确~ 有问题的可以私信我~ |

【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |